q transformer
0.3.0
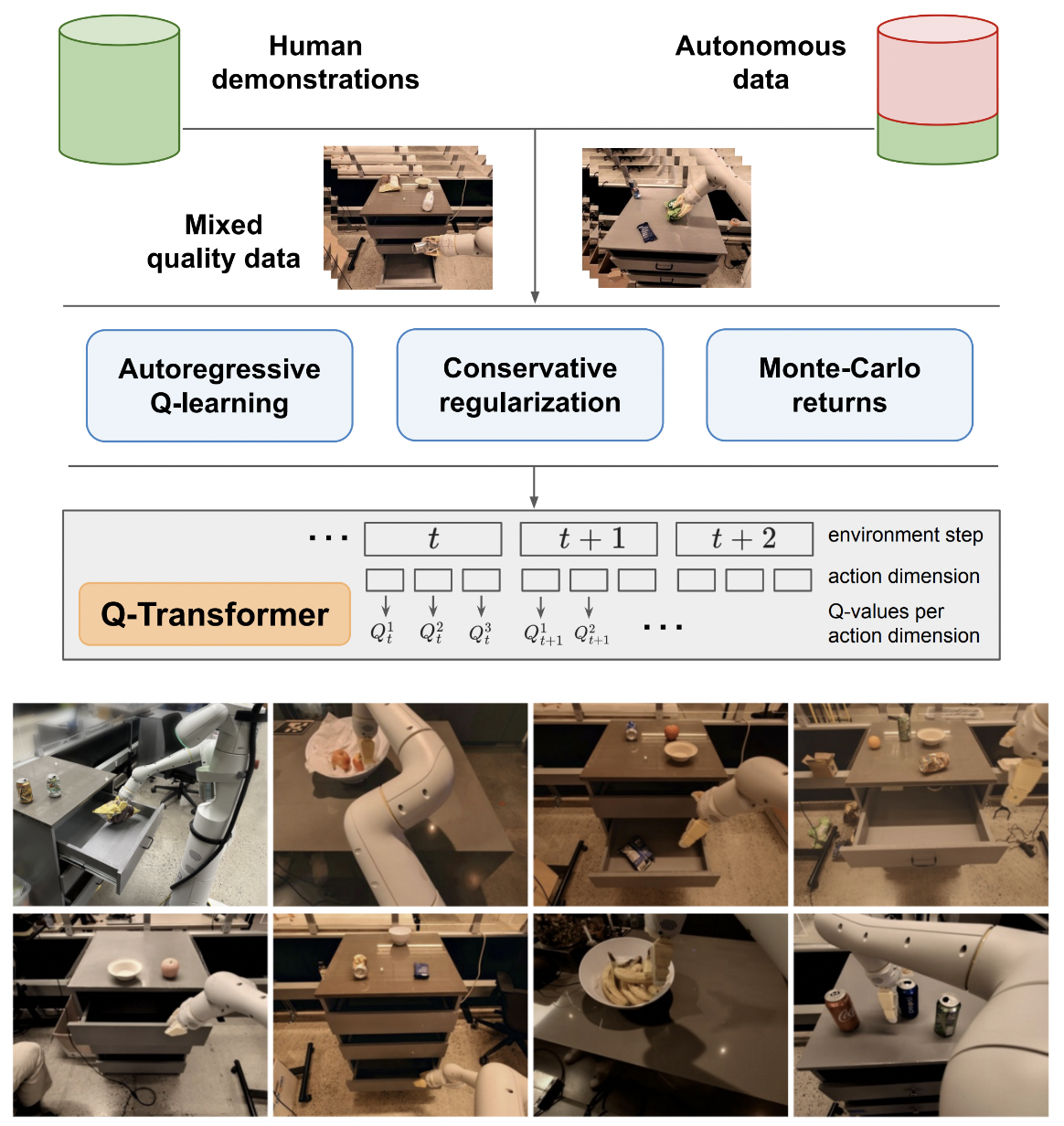
Google Deepmind의 자동회귀 Q-함수를 통한 확장 가능한 오프라인 강화 학습인 Q-Transformer 구현
제안된 다중 작업에 대한 자동 회귀 Q-학습과의 최종 비교를 위해 단일 작업에 대한 Q-학습 논리를 계속 다루겠습니다. 또한 나 자신과 대중을 위한 교육의 역할도 합니다.
자기회귀 Q-학습 공식은 Kotb et al.에 의해 재현되었습니다.
$ pip install q-transformer import torch
from q_transformer import (
QRoboticTransformer ,
QLearner ,
Agent ,
ReplayMemoryDataset
)
# the attention model
model = QRoboticTransformer (
vit = dict (
num_classes = 1000 ,
dim_conv_stem = 64 ,
dim = 64 ,
dim_head = 64 ,
depth = ( 2 , 2 , 5 , 2 ),
window_size = 7 ,
mbconv_expansion_rate = 4 ,
mbconv_shrinkage_rate = 0.25 ,
dropout = 0.1
),
num_actions = 8 ,
action_bins = 256 ,
depth = 1 ,
heads = 8 ,
dim_head = 64 ,
cond_drop_prob = 0.2 ,
dueling = True
)
# you need to supply your own environment, by overriding BaseEnvironment
from q_transformer . mocks import MockEnvironment
env = MockEnvironment (
state_shape = ( 3 , 6 , 224 , 224 ),
text_embed_shape = ( 768 ,)
)
# env.init() should return instructions and initial state: Tuple[str, Tensor[*state_shape]]
# env(actions) should return rewards, next state, and done flag: Tuple[Tensor[()], Tensor[*state_shape], Tensor[()]]
# agent is a class that allows the q-model to interact with the environment to generate a replay memory dataset for learning
agent = Agent (
model ,
environment = env ,
num_episodes = 1000 ,
max_num_steps_per_episode = 100 ,
)
agent ()
# Q learning on the replay memory dataset on the model
q_learner = QLearner (
model ,
dataset = ReplayMemoryDataset (),
num_train_steps = 10000 ,
learning_rate = 3e-4 ,
batch_size = 4 ,
grad_accum_every = 16 ,
)
q_learner ()
# after much learning
# your robot should be better at selecting optimal actions
video = torch . randn ( 2 , 3 , 6 , 224 , 224 )
instructions = [
'bring me that apple sitting on the table' ,
'please pass the butter'
]
actions = model . get_optimal_actions ( video , instructions )단일 작업 지원을 위한 첫 번째 작업 방식
SOTA 날씨 모델 metnet3에서 수행된 것처럼 maxvit의 배치 표준이 없는 변형을 제공합니다.
선택적인 심층 결투 아키텍처 추가
n단계 Q 학습 추가
보수적인 정규화 구축
주요 제안을 종이에 작성(마지막 작업까지 자동 회귀 개별 작업, 마지막에만 보상 제공)
프레임 + 학습된 토큰 단계에서 이전 작업을 연결하는 대신 디코더 헤드 변형을 즉석에서 만듭니다. 즉, 클래식 인코더 - 디코더를 사용하십시오.
아무 것도 신경 쓰지 않기 위해 축 회전 임베딩 + 시그모이드 게이팅을 사용하여 maxvit을 다시 실행하세요. 이 변경으로 maxvit에 대한 플래시 주의를 활성화합니다.
간단한 데이터세트 생성자 클래스를 구축하여 환경과 모델을 취하고 ReplayDataset 에서 허용할 수 있는 폴더를 반환합니다.
ReplayDataset 여러 명령을 올바르게 처리
다른 모든 저장소와 동일한 스타일로 간단한 엔드투엔드 예제를 보여줍니다.
명령어를 처리하지 않고 CFG 라이브러리에서 널 컨디셔너를 활용합니다.
액션 디코딩을 위한 캐시 kv
탐색을 위해 한 번에 모든 작업이 아닌 작업의 하위 집합을 정밀하게 무작위로 지정할 수 있습니다.
일부 RL 전문가와 상담하여 망상적 편견을 해결하는 데 새로운 진전이 있는지 알아보세요.
무작위 작업 순서로 훈련할 수 있는지 알아보세요. 순서는 주의 레이어 전에 연결되거나 합산되는 조건으로 전송될 수 있습니다.
최적의 조치를 위한 간단한 빔 검색 기능
과거 작업 및 시간 단계 상태에 대한 즉석 교차 주의, Transformer-xl 패션(구조화된 메모리 드롭아웃 포함)
이 문서의 주요 아이디어가 언어 모델에 적용 가능한지 여기에서 확인하세요.
@inproceedings { qtransformer ,
title = { Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions } ,
authors = { Yevgen Chebotar and Quan Vuong and Alex Irpan and Karol Hausman and Fei Xia and Yao Lu and Aviral Kumar and Tianhe Yu and Alexander Herzog and Karl Pertsch and Keerthana Gopalakrishnan and Julian Ibarz and Ofir Nachum and Sumedh Sontakke and Grecia Salazar and Huong T Tran and Jodilyn Peralta and Clayton Tan and Deeksha Manjunath and Jaspiar Singht and Brianna Zitkovich and Tomas Jackson and Kanishka Rao and Chelsea Finn and Sergey Levine } ,
booktitle = { 7th Annual Conference on Robot Learning } ,
year = { 2023 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Kumar2023MaintainingPI ,
title = { Maintaining Plasticity in Continual Learning via Regenerative Regularization } ,
author = { Saurabh Kumar and Henrik Marklund and Benjamin Van Roy } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:261076021 }
}

