rtdl revisiting models
1.0.0
중요한
새로운 테이블 형식 DL 모델인 TabM을 확인하세요.
arXiv ? Python 패키지 기타 테이블 형식 DL 프로젝트
이는 "표 형식 데이터에 대한 딥러닝 모델 재검토" 논문의 공식 구현입니다.
한 문장으로 말하자면, MLP와 유사한 모델은 여전히 좋은 기준이며, FT-Transformer는 표 형식 데이터 문제에 대한 Transformer 아키텍처의 새롭고 강력한 적용입니다.
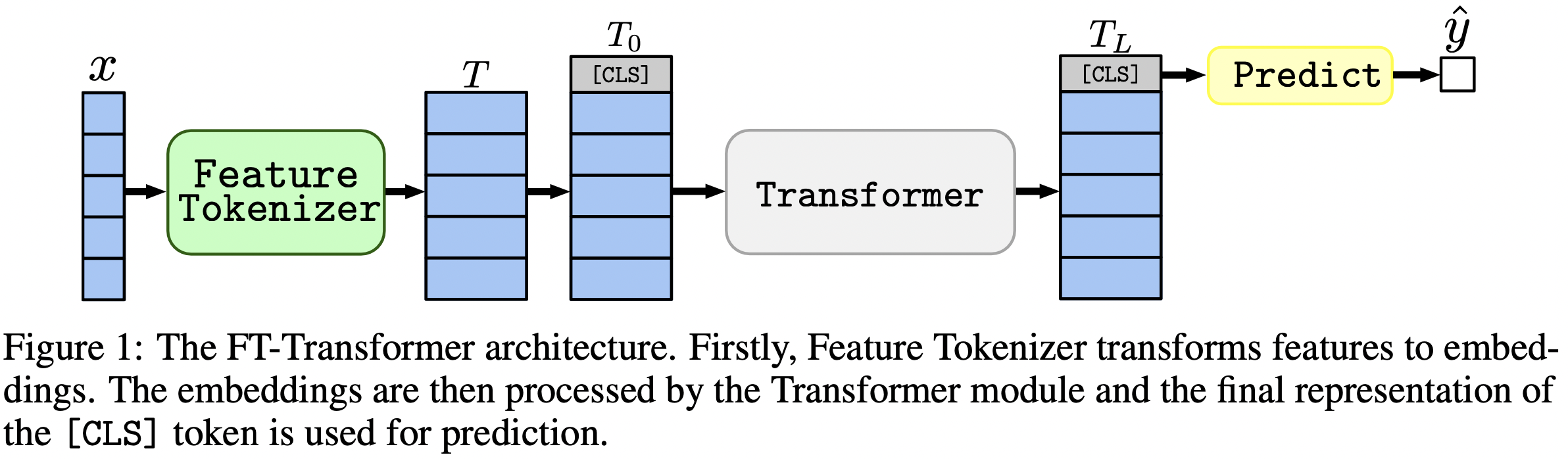
이 문서에서는 표 형식 데이터 문제에 대한 아키텍처에 중점을 둡니다. 결과:
package/ 디렉토리에 있는 Python 패키지는 실제 및 향후 작업에 논문을 사용하는 데 권장되는 방법입니다.
문서의 나머지 부분 :
output/ 디렉토리에는 논문에 사용된 다양한 모델 및 데이터 세트에 대한 수많은 결과와 (조정된) 하이퍼 매개변수가 포함되어 있습니다.
예를 들어 MLP 모델의 측정항목을 살펴보겠습니다. 먼저 보고서( stats.json 파일)를 로드해 보겠습니다.
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'output' ). glob ( '*/mlp/tuned/*/stats.json' )
])이제 각 데이터 세트에 대해 모든 무작위 시드에 대한 평균 테스트 점수를 계산해 보겠습니다.
print ( df . groupby ( 'dataset' )[ 'metrics.test.score' ]. mean (). round ( 3 ))출력은 논문의 표 2와 정확히 일치합니다.
dataset
adult 0.852
aloi 0.954
california_housing -0.499
covtype 0.962
epsilon 0.898
helena 0.383
higgs_small 0.723
jannis 0.719
microsoft -0.747
yahoo -0.757
year -8.853
Name: metrics.test.score, dtype: float64
위의 접근 방식은 하이퍼파라미터를 탐색하여 다양한 알고리즘의 일반적인 하이퍼파라미터 값에 대한 직관을 얻는 데에도 사용할 수 있습니다. 예를 들어, MLP 모델의 조정된 학습률 중앙값을 계산하는 방법은 다음과 같습니다.
메모
일부 알고리즘(예: MLP)의 경우 최신 프로젝트에서는 유사한 방식으로 탐색할 수 있는 더 많은 결과를 제공합니다. 예를 들어 TabR에 대한 이 문서를 참조하세요.
경고
이 접근 방식은 주의해서 사용하세요. 초매개변수 값을 연구할 때:
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002161505605899536메모
이 섹션은 깁니다. 이 섹션의 개요를 보려면 텍스트 편집기에서 GitHub의 "개요" 기능을 사용하세요 .
코드는 다음과 같이 구성됩니다.
bin :ensemble.py 앙상블을 수행합니다.tune.py 하이퍼파라미터 튜닝을 수행합니다.analysis_gbdt_vs_nn.py 실험을 실행합니다.create_synthetic_data_plots.py 플롯을 작성합니다.lib 에는 bin 의 프로그램에서 사용하는 일반적인 도구가 포함되어 있습니다.output 구성 파일( bin 의 프로그램에 대한 입력)과 결과(메트릭, 조정된 구성 등)가 포함됩니다.package 이 문서의 Python 패키지가 포함되어 있습니다. 콘다 설치
export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/revisiting-models
git clone https://github.com/yandex-research/tabular-dl-revisiting-models $PROJECT_DIR
cd $PROJECT_DIR
conda create -n revisiting-models python=3.8.8
conda activate revisiting-models
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=10.1.243 numpy=1.19.2 -c pytorch -y
conda install cudnn=7.6.5 -c anaconda -y
pip install -r requirements.txt
conda install nodejs -y
jupyter labextension install @jupyter-widgets/jupyterlab-manager
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
conda env config vars set LD_LIBRARY_PATH= ${CONDA_PREFIX} /lib: ${LD_LIBRARY_PATH}
conda env config vars set CUDA_HOME= ${CONDA_PREFIX}
conda env config vars set CUDA_ROOT= ${CONDA_PREFIX}
conda deactivate
conda activate revisiting-models이 환경은 TabNet을 실험하는 데에만 필요합니다. 다른 모든 경우에는 PyTorch 환경을 사용하십시오.
지침은 PyTorch 환경(PyTorch 설치 포함!)과 동일하지만 다음과 같습니다.
python=3.7.10cudatoolkit=10.0pip install -r requirements.txt 직전에 다음을 수행하십시오.pip install tensorflow-gpu==1.14requirements.txt 에서 tensorboard 주석 처리하세요.라이센스 : 데이터 세트를 다운로드하면 모든 구성 요소에 대한 라이센스에 동의하게 됩니다. 우리는 해당 라이선스 외에 새로운 제한 사항을 부과하지 않습니다. 우리 논문의 "참고자료" 섹션에서 출처 목록을 찾을 수 있습니다.
wget https://www.dropbox.com/s/o53umyg6mn3zhxy/data.tar.gz?dl=1 -O revisiting_models_data.tar.gzmv revisiting_models_data.tar.gz $PROJECT_DIRcd $PROJECT_DIRtar -xvf revisiting_models_data.tar.gz 이 섹션에서는 설명이 거의 없는 특정 명령만 제공합니다. 튜토리얼을 완료한 후 저장소 작업 방법을 더 잘 이해하려면 다음 섹션을 확인하는 것이 좋습니다. 또한 튜토리얼을 더 잘 이해하는 데에도 도움이 됩니다.
이 튜토리얼에서는 캘리포니아 주택 데이터 세트의 MLP 결과를 재현합니다. 우리는 다음을 다룰 것입니다:
정확히 동일한 결과를 얻을 가능성은 다소 낮지만 우리와 크게 다르지 않아야 합니다. 무엇이든 실행하기 전에 저장소의 루트로 이동하여 CUDA_VISIBLE_DEVICES 명시적으로 설정하십시오(GPU를 사용하려는 경우).
cd $PROJECT_DIR
export CUDA_VISIBLE_DEVICES=0시작하기 전에 환경이 성공적으로 구성되었는지 확인해 보겠습니다. 다음 명령은 캘리포니아 주택 데이터 세트에서 하나의 MLP를 훈련해야 합니다.
mkdir draft
cp output/california_housing/mlp/tuned/0.toml draft/check_environment.toml
python bin/mlp.py draft/check_environment.toml 결과는 draft/check_environment 디렉토리에 있어야 합니다. 지금은 결과의 내용이 중요하지 않습니다.
캘리포니아 주택 데이터 세트에서 MLP를 조정하기 위한 구성은 output/california_housing/mlp/tuning/0.toml 에 있습니다. 튜닝을 재현하려면 구성을 복사하고 튜닝을 실행하십시오.
# you can choose any other name instead of "reproduced.toml"; it is better to keep this
# name while completing the tutorial
cp output/california_housing/mlp/tuning/0.toml output/california_housing/mlp/tuning/reproduced.toml
# let's reduce the number of tuning iterations to make tuning fast (and ineffective)
python -c "
from pathlib import Path
p = Path('output/california_housing/mlp/tuning/reproduced.toml')
p.write_text(p.read_text().replace('n_trials = 100', 'n_trials = 5'))
"
python bin/tune.py output/california_housing/mlp/tuning/reproduced.toml 튜닝 결과는 output/california_housing/mlp/tuning/reproduced 에 있으며 이를 우리의 결과( output/california_housing/mlp/tuning/0 와 비교할 수 있습니다. best.toml 파일에는 다음 섹션에서 평가할 최상의 구성이 포함되어 있습니다.
이제 우리는 15개의 서로 다른 무작위 시드로 조정된 구성을 평가해야 합니다.
# create a directory for evaluation
mkdir -p output/california_housing/mlp/tuned_reproduced
# clone the best config from the tuning stage with 15 different random seeds
python -c "
for seed in range(15):
open(f'output/california_housing/mlp/tuned_reproduced/{seed}.toml', 'w').write(
open('output/california_housing/mlp/tuning/reproduced/best.toml').read().replace('seed = 0', f'seed = {seed}')
)
"
# train MLP with all 15 configs
for seed in {0..14}
do
python bin/mlp.py output/california_housing/mlp/tuned_reproduced/ ${seed} .toml
done 평가 결과가 포함된 디렉토리는 귀하의 디렉토리 바로 옆에 있습니다( output/california_housing/mlp/tuned ).
# just run this single command
python bin/ensemble.py mlp output/california_housing/mlp/tuned_reproduced 결과는 output/california_housing/mlp/tuned_reproduced_ensemble 에 있으며, 우리의 결과( output/california_housing/mlp/tuned_ensemble 와 비교할 수 있습니다.
수행된 실험의 결과를 요약하려면 여기에 설명된 접근 방식을 사용하십시오(따라서 .glob(...) 의 경로 필터를 수정하십시오: tuned -> tuned_reproduced ).
모든 모델과 데이터 세트에 대해 유사한 단계를 수행할 수 있습니다. 그리드 검색의 경우 튜닝 프로세스가 약간 다릅니다. 원하는 구성을 모두 실행하고 검증 성능에 따라 가장 적합한 구성을 수동으로 선택해야 합니다. 예를 들어, output/epsilon/ft_transformer 참조하십시오.
저장소 루트에서 Python 스크립트를 실행해야 합니다. 대부분의 프로그램은 구성 파일을 유일한 인수로 기대합니다. 출력은 구성과 이름은 동일하지만 확장자는 없는 디렉터리입니다. 구성은 TOML로 작성됩니다. 프로그램에 대해 가능한 인수 목록은 제공되지 않으며 스크립트에서 추론해야 합니다(일반적으로 구성은 스크립트의 args 변수로 표시됩니다). CUDA를 사용하려면 CUDA_VISIBLE_DEVICES 환경 변수를 명시적으로 설정해야 합니다. 예를 들어:
# The result will be at "path/to/my_experiment"
CUDA_VISIBLE_DEVICES=0 python bin/mlp.py path/to/my_experiment.toml
# The following example will run WITHOUT CUDA
python bin/mlp.py path/to/my_experiment.tomlCUDA를 항상 사용하려는 경우 Conda 환경에 환경 변수를 저장할 수 있습니다.
conda env config vars set CUDA_VISIBLE_DEVICES= " 0 " -f ( --force ) 옵션은 기존 결과를 제거하고 스크립트를 처음부터 실행합니다.
python bin/whatever.py path/to/config.toml -f # rewrites path/to/config bin/tune.py 연속성을 지원합니다.
python bin/tune.py path/to/config.toml --continuestats.json 및 기타 결과 모든 스크립트에서 stats.json 출력의 가장 중요한 부분입니다. 프로그램마다 내용이 다릅니다. 여기에는 다음이 포함될 수 있습니다.
학습, 검증 및 테스트 세트에 대한 예측도 일반적으로 저장됩니다.
이제 모든 결과를 재현하고 필요에 따라 이 저장소를 확장하는 데 필요한 모든 것을 알게 되었습니다. 이제 튜토리얼도 더욱 명확해졌습니다. 자유롭게 문제를 열고 질문하세요.
@inproceedings{gorishniy2021revisiting,
title={Revisiting Deep Learning Models for Tabular Data},
author={Yury Gorishniy and Ivan Rubachev and Valentin Khrulkov and Artem Babenko},
booktitle={{NeurIPS}},
year={2021},
}


