FLASH pytorch
0.1.9
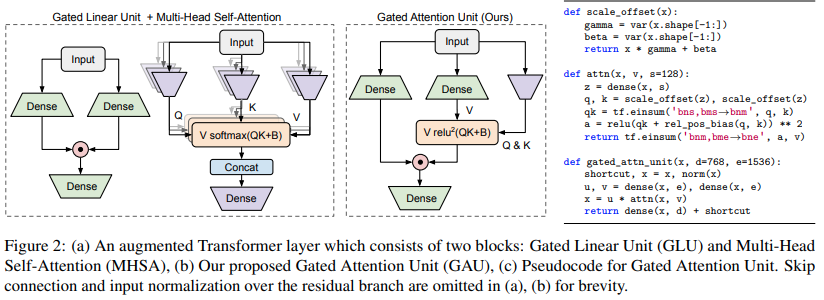
선형 시간의 Transformer Quality 논문에서 제안된 Transformer 변형 구현
$ pip install FLASH-pytorch이 논문의 주요 신규 회로는 "Gated Attention Unit"으로, 여러 방향의 주의를 단 하나의 머리로 줄이면서 이를 대체할 수 있다고 주장합니다.
Softmax 대신 relu 제곱 활성화를 사용합니다. 활성화는 Primer 논문에서 처음으로 확인되었으며 ReLA Transformer에서는 ReLU를 사용합니다. 게이팅 스타일은 대부분 gMLP에서 영감을 얻은 것 같습니다.
import torch
from flash_pytorch import GAU
gau = GAU (
dim = 512 ,
query_key_dim = 128 , # query / key dimension
causal = True , # autoregressive or not
expansion_factor = 2 , # hidden dimension = dim * expansion_factor
laplace_attn_fn = True # new Mega paper claims this is more stable than relu squared as attention function
)
x = torch . randn ( 1 , 1024 , 512 )
out = gau ( x ) # (1, 1024, 512) 그런 다음 저자는 자동회귀 선형 주의로 알려진 문제를 극복하기 위해 시퀀스 그룹화를 사용하여 GAU 와 Katharopoulos 선형 주의를 결합합니다.
FLASH라는 이름의 그룹화된 선형 주의와 2차 게이트 주의 단위의 조합
이것도 아주 쉽게 사용할 수 있어요
import torch
from flash_pytorch import FLASH
flash = FLASH (
dim = 512 ,
group_size = 256 , # group size
causal = True , # autoregressive or not
query_key_dim = 128 , # query / key dimension
expansion_factor = 2. , # hidden dimension = dim * expansion_factor
laplace_attn_fn = True # new Mega paper claims this is more stable than relu squared as attention function
)
x = torch . randn ( 1 , 1111 , 512 ) # sequence will be auto-padded to nearest group size
out = flash ( x ) # (1, 1111, 512)마지막으로 백서에서 언급한 대로 전체 FLASH 변환기를 사용할 수 있습니다. 여기에는 논문에서 언급된 모든 위치 임베딩이 포함됩니다. 절대 위치 임베딩은 스케일링된 정현파를 사용합니다. GAU 2차 주의는 단방향 T5 상대 위치 편향을 얻습니다. 무엇보다도 GAU Attention과 Linear Attention은 모두 RoPE(Rotary Embedded)가 됩니다.
import torch
from flash_pytorch import FLASHTransformer
model = FLASHTransformer (
num_tokens = 20000 , # number of tokens
dim = 512 , # model dimension
depth = 12 , # depth
causal = True , # autoregressive or not
group_size = 256 , # size of the groups
query_key_dim = 128 , # dimension of queries / keys
expansion_factor = 2. , # hidden dimension = dim * expansion_factor
norm_type = 'scalenorm' , # in the paper, they claimed scalenorm led to faster training at no performance hit. the other option is 'layernorm' (also default)
shift_tokens = True # discovered by an independent researcher in Shenzhen @BlinkDL, this simply shifts half of the feature space forward one step along the sequence dimension - greatly improved convergence even more in my local experiments
)
x = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
logits = model ( x ) # (1, 1024, 20000) $ python train.py @article { Hua2022TransformerQI ,
title = { Transformer Quality in Linear Time } ,
author = { Weizhe Hua and Zihang Dai and Hanxiao Liu and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2202.10447 }
} @software { peng_bo_2021_5196578 ,
author = { PENG Bo } ,
title = { BlinkDL/RWKV-LM: 0.01 } ,
month = { aug } ,
year = { 2021 } ,
publisher = { Zenodo } ,
version = { 0.01 } ,
doi = { 10.5281/zenodo.5196578 } ,
url = { https://doi.org/10.5281/zenodo.5196578 }
} @inproceedings { Ma2022MegaMA ,
title = { Mega: Moving Average Equipped Gated Attention } ,
author = { Xuezhe Ma and Chunting Zhou and Xiang Kong and Junxian He and Liangke Gui and Graham Neubig and Jonathan May and Luke Zettlemoyer } ,
year = { 2022 }
}

