video diffusion pytorch
0.7.0
이 불꽃놀이는 존재하지 않아요
텍스트를 비디오로, 그것이 일어나고 있습니다! 공식 프로젝트 페이지
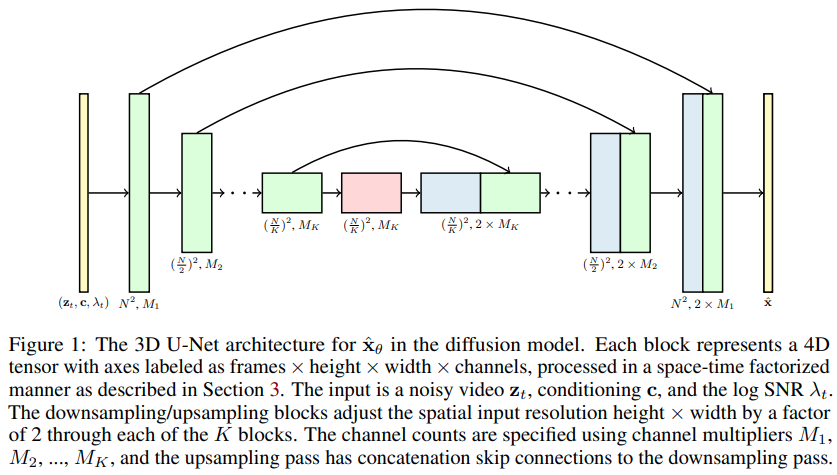
비디오 확산 모델 구현(Pytorch에서 DDPM을 비디오 생성으로 확장하는 Jonathan Ho의 새 논문) 특별한 시공간 인수 U-net을 사용하여 2D 이미지에서 3D 비디오로 생성을 확장합니다.
이동이 어려운 mnist의 경우 14k(NUWA보다 훨씬 빠르고 더 나은 수렴) - wip

위의 실험은 Stability.ai에서 제공하는 리소스가 있어야만 가능합니다.
텍스트-비디오 합성을 위한 모든 새로운 개발은 Imagen-pytorch에 집중됩니다.
$ pip install video-diffusion-pytorch import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 1 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width) - normalized from -1 to +1
loss = diffusion ( videos )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( batch_size = 4 )
sampled_videos . shape # (4, 3, 5, 32, 32)텍스트를 조건화하기 위해 먼저 BERT-large를 통해 토큰화된 텍스트를 전달하여 텍스트 임베딩을 파생했습니다. 그럼 그렇게 훈련하면 돼
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
cond_dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 2 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = torch . randn ( 2 , 64 ) # assume output of BERT-large has dimension of 64
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text )
sampled_videos . shape # (2, 3, 5, 32, 32)텍스트 조절을 위해 BERT 기반을 사용할 계획이라면 비디오 설명을 문자열로 직접 전달할 수도 있습니다.
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
use_bert_text_cond = True , # this must be set to True to auto-use the bert model dimensions
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 , # height and width of frames
num_frames = 5 , # number of video frames
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 3 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
]
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text , cond_scale = 2 )
sampled_videos . shape # (3, 3, 5, 32, 32) 이 저장소에는 gifs 폴더 교육을 위한 편리한 Trainer 클래스도 포함되어 있습니다. 각 gif 크기는 image_size 및 num_frames 이어야 합니다.
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion , Trainer
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 64 ,
num_frames = 10 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
). cuda ()
trainer = Trainer (
diffusion ,
'./data' , # this folder path needs to contain all your training data, as .gif files, of correct image size and number of frames
train_batch_size = 32 ,
train_lr = 1e-4 ,
save_and_sample_every = 1000 ,
train_num_steps = 700000 , # total training steps
gradient_accumulate_every = 2 , # gradient accumulation steps
ema_decay = 0.995 , # exponential moving average decay
amp = True # turn on mixed precision
)
trainer . train () 샘플 비디오( gif 파일)는 확산 모델 매개변수와 마찬가지로 주기적으로 ./results 에 저장됩니다.
논문의 주장 중 하나는 팩터링된 시공간 주의를 수행함으로써 네트워크가 이미지와 비디오를 함께 훈련하기 위해 현재에 집중하도록 강제하여 더 나은 결과를 얻을 수 있다는 것입니다.
그들이 어떻게 이것을 달성했는지는 확실하지 않지만 나는 추측을 더 발전시켰습니다.
특정 비율의 배치 비디오 샘플에 대해 현재 순간에 주의를 집중시키려면 확산 순방향 방법에 prob_focus_present = <prob> 전달하면 됩니다.
loss = diffusion ( videos , cond = text , prob_focus_present = 0.5 ) # for 50% of videos, focus on the present during training
loss . backward ()이것이 어떻게 수행되는지 더 나은 아이디어가 있다면 github 이슈를 열어보세요.
@misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Saharia2022 ,
title = { Imagen: unprecedented photorealism × deep level of language understanding } ,
author = { Chitwan Saharia*, William Chan*, Saurabh Saxena†, Lala Li†, Jay Whang†, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho†, David Fleet†, Mohammad Norouzi* } ,
year = { 2022 }
}

