datmo
1.0.0

| OS | master 에서 CI 테스트 |
|---|---|
Datmo 는 데이터 과학자를 위한 오픈 소스 생산 모델 관리 도구입니다. datmo init 사용하여 모든 저장소를 추적 가능한 실험 기록으로 전환하세요. 자신의 클라우드를 사용하여 동기화하세요.
참고 : Datmo의 현재 버전은 알파 릴리스입니다. 이는 명령이 변경될 수 있으며 더 많은 기능이 추가될 것임을 의미합니다. 버그를 발견한 경우 기여자가 문제를 해결할 수 있도록 문제를 추가하여 자유롭게 기여해 주세요.
단일 명령 환경 설정 (언어, 프레임워크, 패키지 등)
모델 구성 및 결과 추적 및 로깅
프로젝트 버전 관리 (모델 상태 추적)
실험 재현성 (작업 재실행)
실험 기록 시각화 + 내보내기
(출시 예정) 실험을 시각화하는 대시보드
| 특징 | 명령 |
|---|---|
| 프로젝트 초기화 | $ datmo init |
| 새로운 환경 설정 | $ datmo environment setup |
| 실험 실행 | $ datmo run "python filename.py" |
| 이전 실험 재현 | $ datmo ls (원하는 아이디 찾기)$ datmo rerun EXPERIMENT_ID |
| 작업공간 열기 | $ datmo notebook (주피터 노트북)$ datmo jupyterlab (JupyterLab)$ datmo rstudio (RStudio)$ datmo terminal (터미널) |
| 프로젝트 상태 기록 (파일, 코드, 환경, 구성, 통계) | $ datmo snapshot create -m "My first snapshot!" |
| 이전 프로젝트 상태로 전환 | $ datmo snapshot ls (원하는 ID 찾기)$ datmo snapshot checkout SNAPSHOT_ID |
| 프로젝트 엔터티 시각화 | $ datmo ls (실험)$ datmo snapshot ls (스냅샷)$ datmo environment ls (환경) |
요구사항
설치
안녕하세요 세계
예
선적 서류 비치
현재 프로젝트 변환
공유
Datmo에 기여
docker(시작하기 전에 설치 및 실행 중) : Ubuntu, MacOS, Windows에 대한 지침
$ pip install datmo
Hello World 가이드에는 환경 설정 및 변경은 물론 실험 재현성을 보여주는 내용이 포함되어 있습니다. 여기 문서에서 확인할 수 있습니다.
/examples 폴더에는 datmo에 대한 느낌을 얻기 위해 실행할 수 있는 몇 가지 스크립트가 있습니다. 예제로 이동하여 예제를 실행하고 자신의 프로젝트를 시작하는 방법에 대해 자세히 알아볼 수 있습니다.
더 많은 고급 튜토리얼을 보려면 여기에서 전용 튜토리얼 저장소를 확인하세요.
datmo에서는 환경 설정이 매우 쉽습니다. 초기화 중 환경 설정을 묻는 질문에 y 로 응답하거나 언제든지 datmo environment setup 사용하세요. 그런 다음 결과 프롬프트를 따르십시오.
CPU 요청/드라이버를 사용하여 Python 2.7 TensorFlow를 설정하는 한 가지 예가 아래에 나와 있습니다. 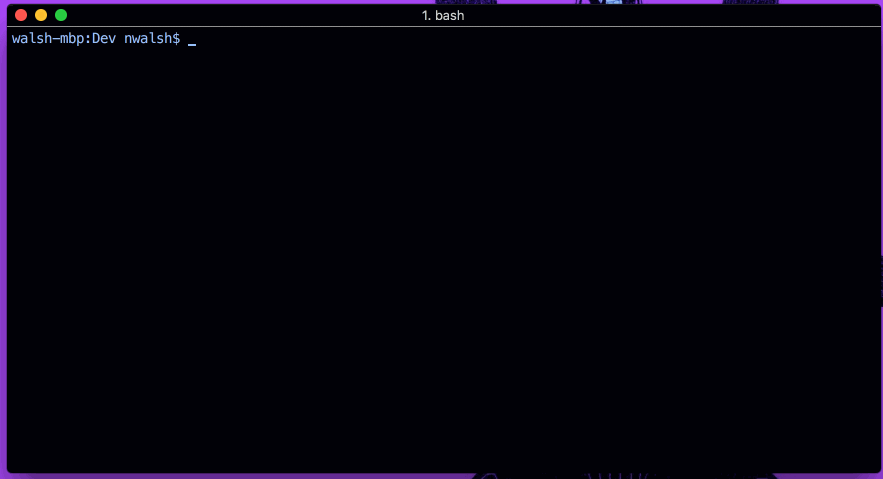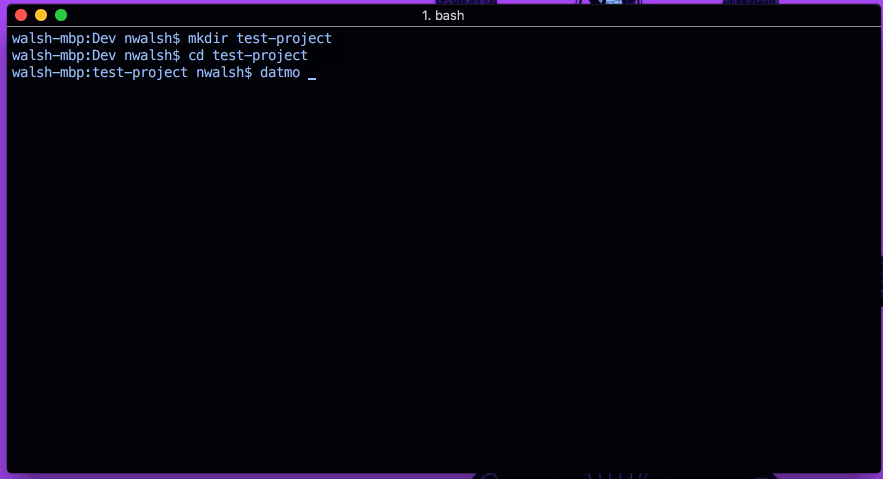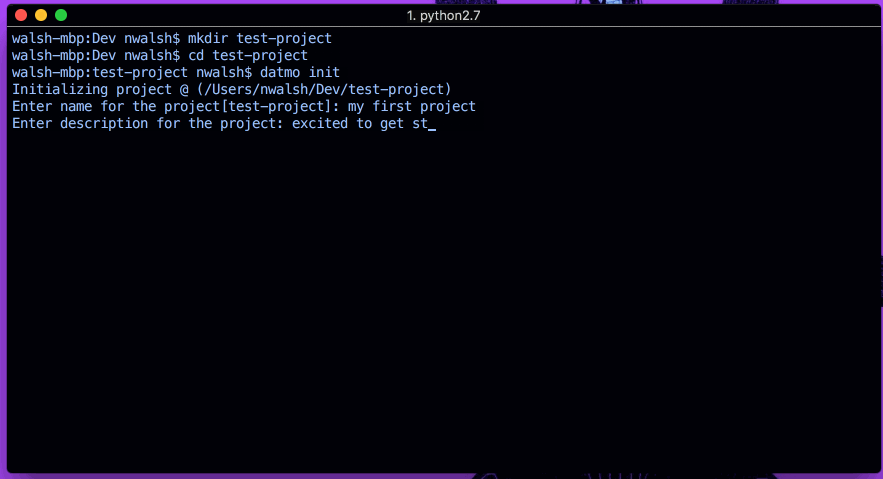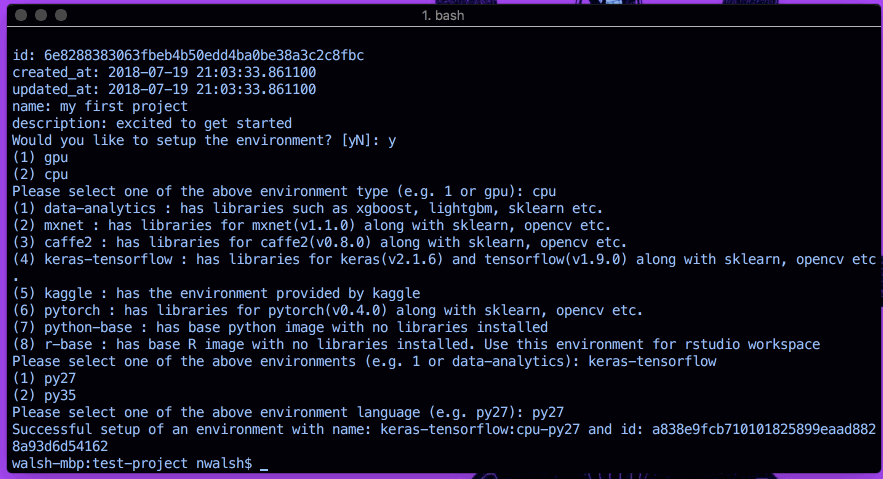
datmo를 사용하여 환경을 설정하는 방법에 대한 전체 가이드는 여기에 있는 설명서의 이 페이지를 참조하세요.
환경을 설정한 후 대부분의 데이터 과학자는 작업 공간(IDE 또는 노트북 프로그래밍 환경)이라고 부르는 것을 열고 싶어합니다.
Jupyter Notebook을 빠르게 열고 TensorFlow 가져오기가 의도한 대로 작동하는 것을 보여주는 한 가지 예가 아래에 나와 있습니다. 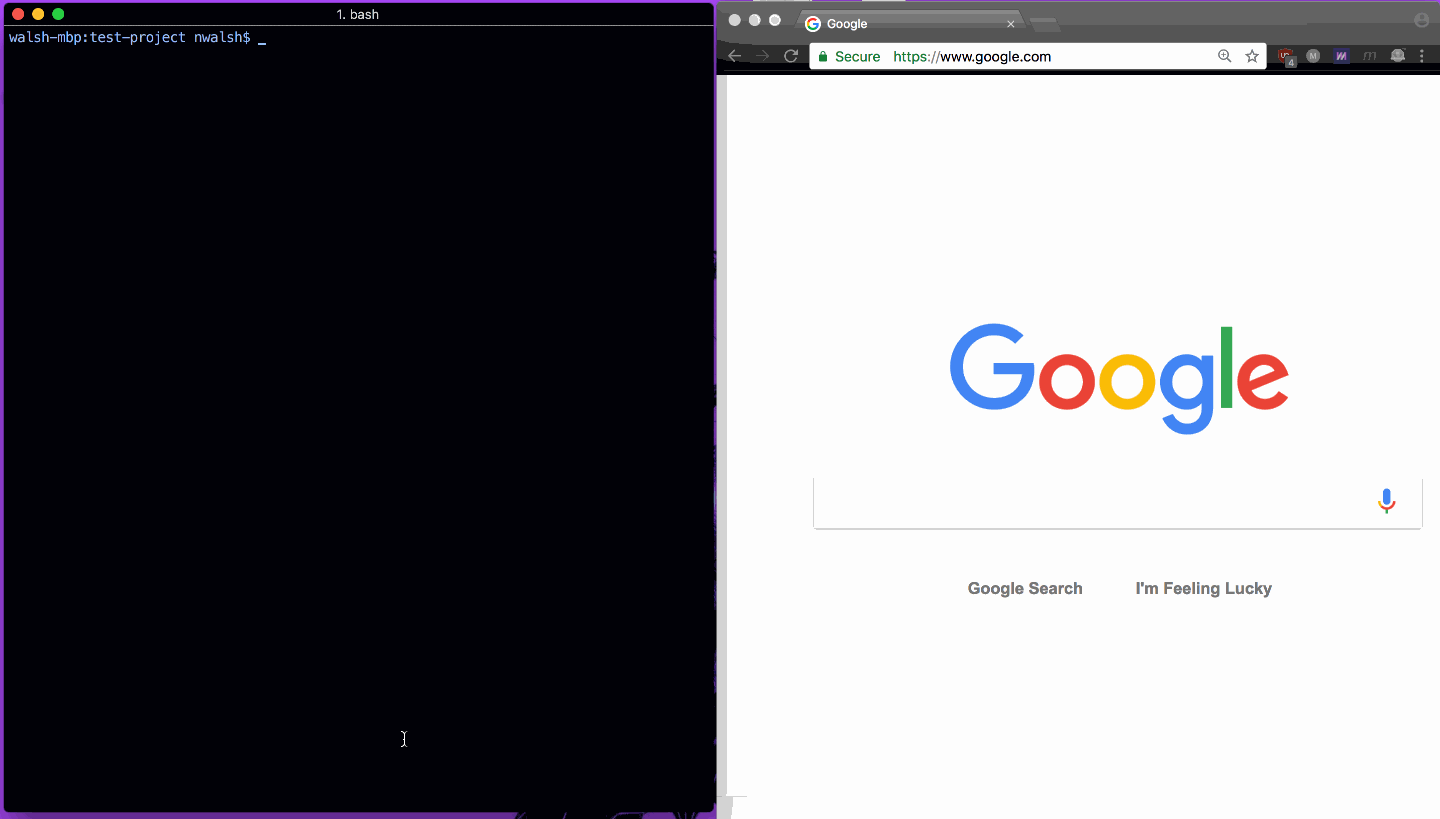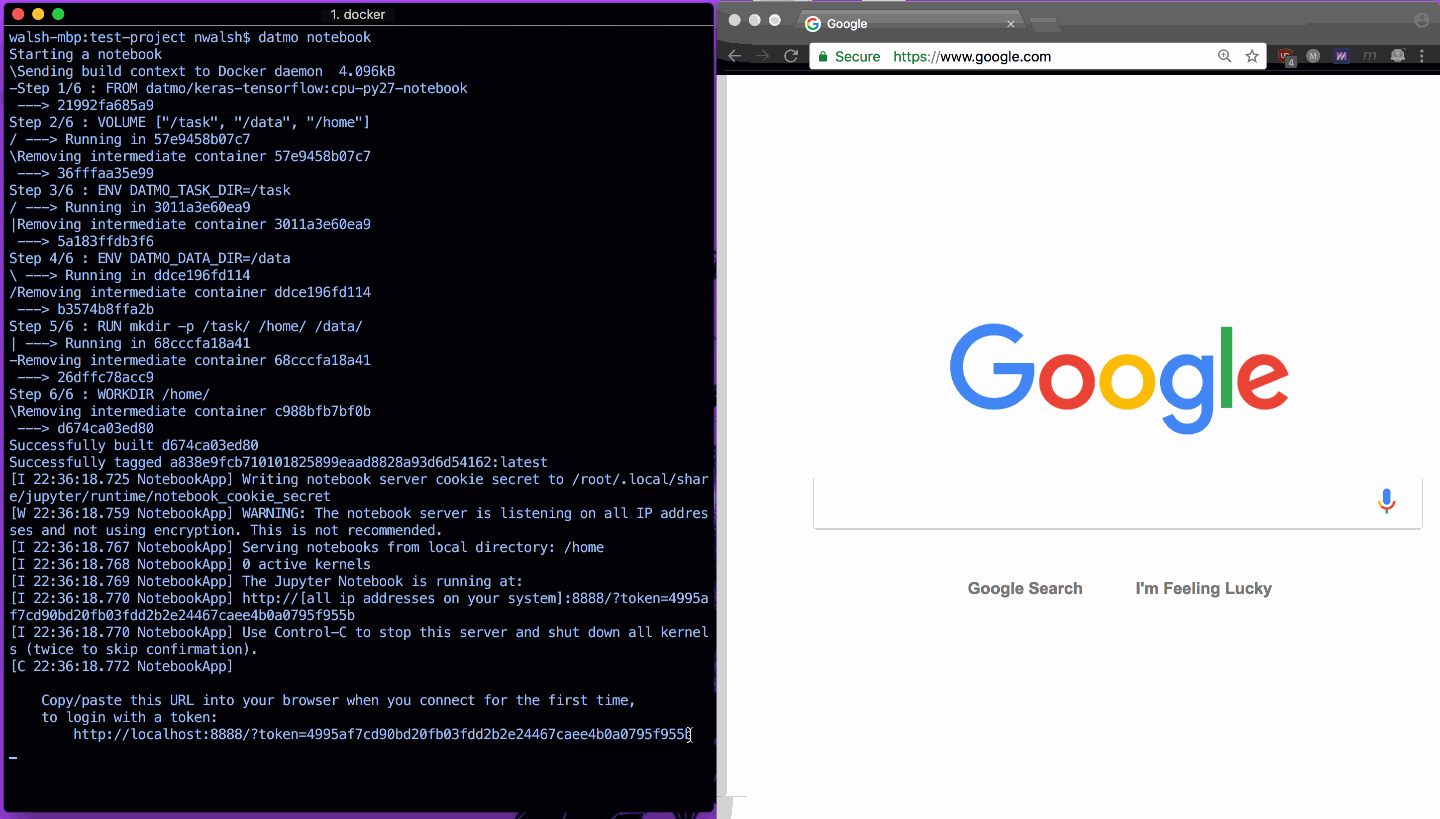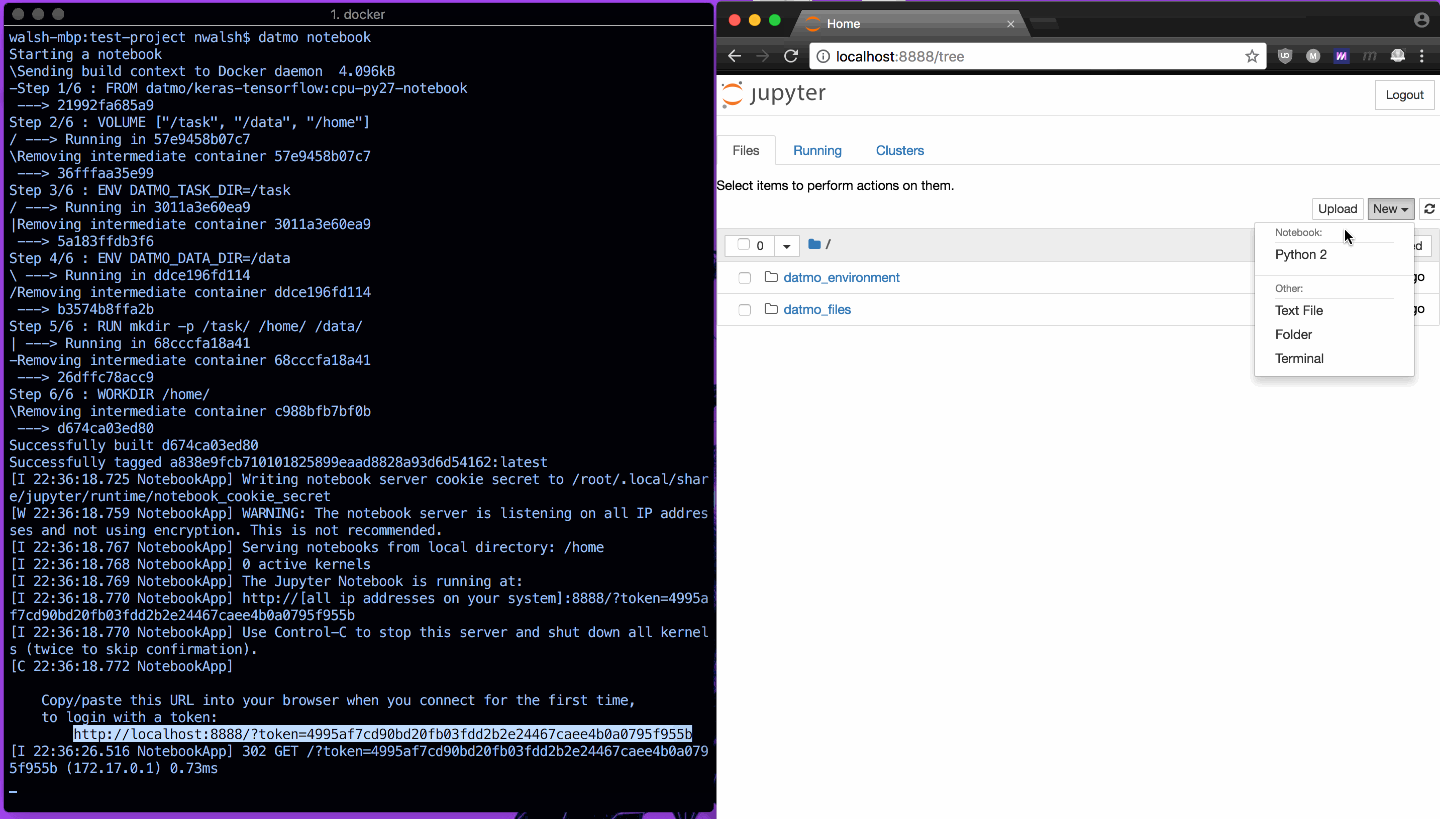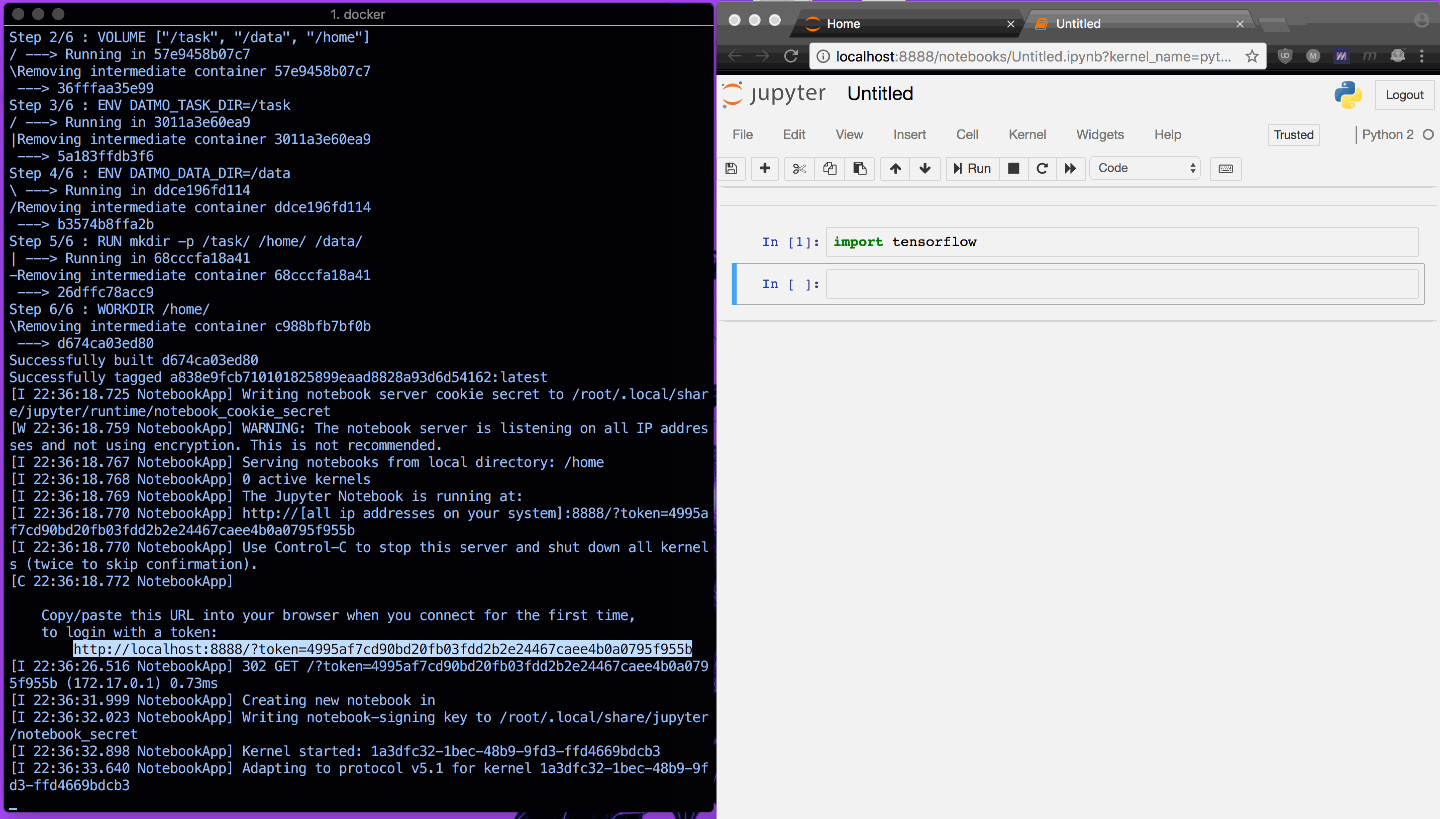
다음은 Datmo를 활용하는 모델과 일반적인 로지스틱 회귀 모델을 비교한 것입니다.
| 일반 스크립트 | 닷모와 함께 |
|---|---|
# train.py#from sklearn 가져오기 데이터 세트from sklearn import Linear_model as lmfrom sklearn import model_selection as msfrom sklearn import externals as ex######iris_dataset = 데이터 세트.load_iris()X = iris_dataset.datay = iris_dataset.targetdata = ms.train_test_split (X, y)X_train, X_test, y_train, y_test = data#model = lm.LogisticRegression(solver="newton-cg")model.fit(X_train, y_train)ex.joblib.dump(model, 'model.pkl')#train_acc = model.score(X_train, y_train)test_acc = 모델.점수(X_test, y_test)#print(train_acc)print(test_acc)######### | # train.py#from sklearn 가져오기 데이터 세트from sklearn import Linear_model as lmfrom sklearn import model_selection as msfrom sklearn import externals as eximport datmo # extra line#config = {"solver": "newton-cg"} # 추가 line#iris_dataset = 데이터 세트. load_iris()X = iris_dataset.datay = iris_dataset.targetdata = ms.train_test_split(X, y)X_train, X_test, y_train, y_test = data#model = lm.LogisticRegression(**config)model.fit(X_train, y_train)ex.joblib.dump(model, "model.pkl") #train_acc = model.score(X_train, y_train)test_acc = model.score(X_test, y_test)#stats = {"train_accuracy": train_acc,"test_accuracy": test_acc} # 추가 라인#datmo.snapshot.create(message="my first snapshot",filepaths=["model.pkl"],config=config, stats=stats) # 추가 줄 |
위 코드를 실행하려면 다음을 수행하면 됩니다.
프로젝트가 있는 디렉터리로 이동
$ mkdir MY_PROJECT $ cd MY_PROJECT
datmo 프로젝트 초기화
$ datmo init
위의 datmo 코드를 MY_PROJECT 디렉터리의 train.py 파일에 복사하세요.
Python에서 평소처럼 스크립트를 실행하세요.
$ python train.py
축하해요! 방금 첫 번째 스냅샷을 생성했습니다. :) 이제 스냅샷에 대해 ls 명령을 실행하여 첫 번째 스냅샷을 확인하세요.
$ datmo snapshot ls
datmo init 실행할 때 Datmo는 재생 중인 다양한 엔터티를 모두 추적하는 숨겨진 .datmo 디렉터리를 추가합니다. 이는 datmo가 활성화된 저장소를 렌더링하는 데 필요합니다.
datmo에서 움직이는 부품이 어떻게 함께 작동하는지 보려면 문서의 개념 페이지를 참조하세요.
전체 문서는 여기에서 호스팅됩니다. 문서(여기 /docs 에 있는 소스 코드)에 기여하려면 CONTRIBUTING.md 에 설명된 절차를 따르세요.
다음 명령을 사용하여 기존 저장소를 datmo 지원 저장소로 변환할 수 있습니다.
$ datmo init
언제든지 datmo를 제거하려면 저장소에서 .datmo 디렉터리를 제거하거나 다음 명령을 실행할 수 있습니다.
$ datmo cleanup
면책 조항: 이는 현재 공식적으로 지원되는 옵션이 아니며 datmo 프로젝트를 공유하기 위한 해결 방법으로 파일 기반 저장소 계층(구성에 설정된 대로)에서만 작동합니다.
datmo는 로컬에서 변경 사항을 추적하도록 만들어졌지만 다음을 수행하여 원격 서버에 푸시하여 프로젝트를 공유할 수 있습니다(이는 git에만 표시되며 다른 SCM 추적 도구를 사용하는 경우 비슷한 작업을 수행할 수 있습니다). 파일이 너무 크거나 SCM에 추가할 수 없는 경우 이 방법이 적합하지 않을 수 있습니다.
아래 내용은 BASH 터미널에서만 테스트되었습니다. 다른 터미널을 사용하는 경우 일부 오류가 발생할 수 있습니다.
$ git add -f .datmo/* # add in .datmo to your scm $ git commit -m "adding .datmo to tracking" # commit it to your scm $ git push # push to remote $ git push origin +refs/datmo/*:refs/datmo/* # push datmo refs to remote
위의 기능을 사용하면 datmo 결과 및 엔터티를 자신이나 다른 컴퓨터의 다른 사람과 공유할 수 있습니다. 참고: 다른 시스템이나 다른 위치에서 datmo 사용을 시작하려면 추적에서 .datmo/를 제거해야 합니다. 다른 위치에 복제하는 방법을 보려면 아래 지침을 참조하세요.
$ git clone YOUR_REMOTE_URL $ cd YOUR_REPO $ echo '.datmo/*' > .git/info/exclude # include .datmo into your .git exclude $ git rm -r --cached .datmo # remove cached versions of .datmo from scm $ git commit -m "removed .datmo from tracking" # clean up your scm so datmo can work $ git pull origin +refs/datmo/*:refs/datmo/* # pull datmo refs from remote $ datmo init # This enables datmo in the new location. If you enter blanks, no project information will be updated
datmo 프로토콜을 사용하여 공유하는 데 관심이 있으시면 Datmo 웹사이트를 방문하세요.
Q: datmo stop --all 작동하지 않고 포트 재할당으로 인해 새 컨테이너를 시작할 수 없는 경우 어떻게 해야 합니까?
A: 이는 다른 datmo 프로젝트나 다른 컨테이너에서 실행되는 고스트 컨테이너로 인해 발생할 수 있습니다. 특정 포트 할당(8888 제외)으로 도커 이미지를 생성하고, 도커 이미지를 찾아 중지하고, docker ps --all 및 docker conntainer stop <ID> 및 docker container rm <ID> 사용하여 제거할 수 있습니다. 또는 머신에서 실행 중인 모든 이미지를 중지하고 제거할 수 있습니다. [참고: 이는 머신의 다른 docker 프로세스에 영향을 미칠 수 있으므로 주의해서 진행하세요] docker container stop $(docker ps -a -q) 및 docker container rm $(docker ps -a -q)


