nano neuron
1.0.0
기계가 실제로 어떻게 "학습"할 수 있는지 느끼게 해주는 7가지 간단한 JavaScript 함수입니다.
다른 언어: Русский, Português
당신은 또한에 관심이 있을 수도 있습니다? 대화형 기계 학습 실험
NanoNeuron은 Neural Networks의 Neuron 개념을 지나치게 단순화한 버전입니다. NanoNeuron은 온도 값을 섭씨에서 화씨로 변환하도록 훈련되었습니다.
NanoNeuron.js 코드 예제에는 기계가 실제로 어떻게 "학습"할 수 있는지에 대한 느낌을 주는 7가지 간단한 JavaScript 함수(모델 예측, 비용 계산, 정방향/역방향 전파 및 교육 관련)가 포함되어 있습니다. 타사 라이브러리도 없고 외부 데이터 세트나 종속성도 없으며 순수하고 간단한 JavaScript 기능만 있습니다.
☝?이러한 기능은 결코 기계 학습에 대한 완전한 가이드가 아닙니다 . 많은 기계 학습 개념이 건너뛰고 지나치게 단순화되었습니다! 이러한 단순화는 독자에게 기계가 어떻게 학습할 수 있는지에 대한 기본적인 이해와 느낌을 제공하고 궁극적으로 독자가 "기계 학습 MAGIC"이 아니라 "기계 학습 MATH"임을 인식할 수 있도록 하기 위해 의도적으로 수행되었습니다.
아마도 신경망이라는 맥락에서 뉴런에 대해 들어보셨을 것입니다. NanoNeuron은 그저 그렇지만 더 간단하므로 처음부터 구현해 보겠습니다. 단순화를 위해 우리는 NanoNeurons에 네트워크를 구축하지도 않을 것입니다. 우리는 모든 것이 스스로 작동하도록 하여 우리를 위해 몇 가지 마법적인 예측을 수행할 것입니다. 즉, 우리는 이 단일 NanoNeuron에게 온도를 섭씨에서 화씨로 변환(예측)하도록 가르칠 것입니다.
그런데 섭씨를 화씨로 변환하는 공식은 다음과 같습니다.
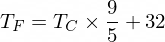
하지만 현재로서는 NanoNeuron이 이에 대해 알지 못합니다...
NanoNeuron 모델 기능을 구현해 보겠습니다. 이는 y = w * x + b 처럼 보이는 x 와 y 사이의 기본 선형 종속성을 구현합니다. 간단히 말해서 우리의 NanoNeuron은 XY 좌표에서 직선을 그리는 법을 가르치는 "학교"의 "어린이"입니다.
변수 w , b 모델의 매개변수입니다. NanoNeuron은 선형 함수의 이 두 가지 매개변수만 알고 있습니다. 이러한 매개변수는 NanoNeuron이 훈련 과정 중에 "학습"하게 될 것입니다.
NanoNeuron이 할 수 있는 유일한 일은 선형 종속성을 모방하는 것입니다. predict() 메서드에서는 일부 입력 x 받아들이고 출력 y 를 예측합니다. 여기에는 마법이 없습니다.
function NanoNeuron ( w , b ) {
this . w = w ;
this . b = b ;
this . predict = ( x ) => {
return x * this . w + this . b ;
}
}(...잠깐... 선형 회귀가 당신인가요?) ?
섭씨 온도 값은 다음 공식을 사용하여 화씨로 변환할 수 있습니다: f = 1.8 * c + 32 , 여기서 c 는 섭씨 온도이고 f 계산된 화씨 온도입니다.
function celsiusToFahrenheit ( c ) {
const w = 1.8 ;
const b = 32 ;
const f = c * w + b ;
return f ;
} ; 궁극적으로 우리는 이러한 매개변수를 미리 알지 못한 채 NanoNeuron에게 이 기능을 모방하도록 가르치고 싶습니다( w = 1.8 및 b = 32 임을 학습).
섭씨에서 화씨로의 변환 기능은 다음과 같습니다.
훈련 전에 celsiusToFahrenheit() 함수를 기반으로 훈련 및 테스트 데이터 세트를 생성해야 합니다. 데이터 세트는 입력 값과 올바르게 레이블이 지정된 출력 값의 쌍으로 구성됩니다.
실제 생활에서는 대부분의 경우 이 데이터가 생성되기보다는 수집됩니다. 예를 들어, 손으로 그린 숫자 이미지 세트와 각 그림에 어떤 숫자가 쓰여 있는지 설명하는 해당 숫자 세트가 있을 수 있습니다.
TRAINING 예제 데이터를 사용하여 NanoNeuron을 교육하겠습니다. NanoNeuron이 성장하여 스스로 결정을 내릴 수 있으려면 훈련 예제를 사용하여 무엇이 옳고 무엇이 그른지 가르쳐야 합니다.
테스트 예제를 사용하여 NanoNeuron이 훈련 중에 확인하지 못한 데이터에 대해 얼마나 잘 수행되는지 평가할 것입니다. 이는 우리의 '아이'가 성장했고 스스로 결정을 내릴 수 있게 되었음을 알 수 있는 지점이다.
function generateDataSets ( ) {
// xTrain -> [0, 1, 2, ...],
// yTrain -> [32, 33.8, 35.6, ...]
const xTrain = [ ] ;
const yTrain = [ ] ;
for ( let x = 0 ; x < 100 ; x += 1 ) {
const y = celsiusToFahrenheit ( x ) ;
xTrain . push ( x ) ;
yTrain . push ( y ) ;
}
// xTest -> [0.5, 1.5, 2.5, ...]
// yTest -> [32.9, 34.7, 36.5, ...]
const xTest = [ ] ;
const yTest = [ ] ;
// By starting from 0.5 and using the same step of 1 as we have used for training set
// we make sure that test set has different data comparing to training set.
for ( let x = 0.5 ; x < 100 ; x += 1 ) {
const y = celsiusToFahrenheit ( x ) ;
xTest . push ( x ) ;
yTest . push ( y ) ;
}
return [ xTrain , yTrain , xTest , yTest ] ;
} 모델의 예측이 값 수정에 얼마나 가까운지 보여주는 몇 가지 측정항목이 필요합니다. NanoNeuron이 생성한 y 의 올바른 출력 값과 prediction 사이의 비용(실수) 계산은 다음 공식을 사용하여 수행됩니다.
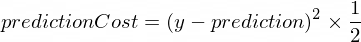
이는 두 값 사이의 단순한 차이입니다. 값이 서로 가까울수록 차이가 작아집니다. 여기서는 (1 - 2) ^ 2 가 (2 - 1) ^ 2 와 같도록 음수를 제거하기 위해 2 의 거듭제곱을 사용하고 있습니다. 2 로 나누는 것은 역전파 공식을 더욱 단순화하기 위해 발생합니다(아래 참조).
이 경우 비용 함수는 다음과 같이 간단합니다.
function predictionCost ( y , prediction ) {
return ( y - prediction ) ** 2 / 2 ; // i.e. -> 235.6
} 순방향 전파를 수행한다는 것은 xTrain 및 yTrain 데이터 세트의 모든 훈련 예제에 대해 예측을 수행하고 그 과정에서 해당 예측의 평균 비용을 계산하는 것을 의미합니다.
이 시점에서는 NanoNeuron이 온도를 변환하는 방법을 추측할 수 있도록 함으로써 자신의 의견을 말하도록 할 뿐입니다. 여기서는 어리석게도 틀렸을 수도 있습니다. 평균 비용은 현재 모델이 얼마나 잘못되었는지를 보여줍니다. NanoNeuron 매개변수 w 및 b 변경하고 순방향 전파를 다시 수행하므로 이 비용 값은 매우 중요합니다. 이러한 매개변수가 변경된 후에 NanoNeuron이 더 똑똑해졌는지 여부를 평가할 수 있습니다.
평균 비용은 다음 공식을 사용하여 계산됩니다.
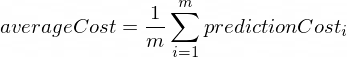
여기서 m 학습 예제의 수입니다(이 경우: 100 ).
코드로 구현하는 방법은 다음과 같습니다.
function forwardPropagation ( model , xTrain , yTrain ) {
const m = xTrain . length ;
const predictions = [ ] ;
let cost = 0 ;
for ( let i = 0 ; i < m ; i += 1 ) {
const prediction = nanoNeuron . predict ( xTrain [ i ] ) ;
cost += predictionCost ( yTrain [ i ] , prediction ) ;
predictions . push ( prediction ) ;
}
// We are interested in average cost.
cost /= m ;
return [ predictions , cost ] ;
}NanoNeuron의 예측이 (이 시점의 평균 비용을 기준으로) 얼마나 옳고 그른지 알면 예측을 더 정확하게 만들기 위해 무엇을 해야 합니까?
역전파는 이 질문에 대한 답을 제공합니다. 역방향 전파는 예측 비용을 평가하고 다음 및 미래 예측이 더 정확하도록 NanoNeuron의 매개변수 w 및 b 조정하는 프로세스입니다.
이곳은 머신러닝이 마술처럼 보이는 곳인가요?♂️. 여기서 핵심 개념은 비용 함수 최소값에 가까워지기 위해 취해야 할 단계를 보여주는 미분 입니다.
비용 함수의 최소값을 찾는 것이 훈련 과정의 궁극적인 목표라는 것을 기억하십시오. 평균 비용 함수가 작아지는 w 및 b 값을 찾으면 NanoNeuron 모델이 정말 훌륭하고 정확한 예측을 수행한다는 의미입니다.
파생상품은 이 글에서 다루지 않을 크고 별개의 주제입니다. MathIsFun은 이에 대한 기본적인 이해를 얻을 수 있는 좋은 리소스입니다.
역방향 전파가 어떻게 작동하는지 이해하는 데 도움이 되는 도함수에 대한 한 가지 사실은 도함수는 그 의미에 따라 함수 최소값의 방향을 가리키는 함수 곡선의 접선이라는 것입니다.
이미지 출처: MathIsFun
예를 들어, 위의 플롯에서 우리가 (x=2, y=4) 지점에 있다면 기울기는 함수 최소값에 도달하기 위해 left 과 down 이동하라고 지시하는 것을 볼 수 있습니다. 또한 기울기가 클수록 최소값으로 더 빠르게 이동해야 합니다.
매개변수 w 와 b 에 대한 averageCost 함수의 미분은 다음과 같습니다.
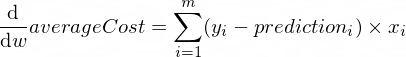
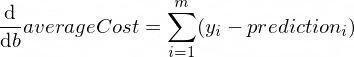
여기서 m 학습 예제의 수입니다(이 경우: 100 ).
여기에서 파생 규칙과 복잡한 함수의 파생을 얻는 방법에 대해 자세히 알아볼 수 있습니다.
function backwardPropagation ( predictions , xTrain , yTrain ) {
const m = xTrain . length ;
// At the beginning we don't know in which way our parameters 'w' and 'b' need to be changed.
// Therefore we're setting up the changing steps for each parameters to 0.
let dW = 0 ;
let dB = 0 ;
for ( let i = 0 ; i < m ; i += 1 ) {
dW += ( yTrain [ i ] - predictions [ i ] ) * xTrain [ i ] ;
dB += yTrain [ i ] - predictions [ i ] ;
}
// We're interested in average deltas for each params.
dW /= m ;
dB /= m ;
return [ dW , dB ] ;
} 이제 우리는 모든 훈련 세트 예시에 대한 모델의 정확성을 평가하는 방법을 알았습니다( 순방향 전파 ). 또한 NanoNeuron 모델의 매개변수 w 와 b 약간 조정하는 방법도 알고 있습니다( 역전파 ). 그러나 문제는 순방향 전파와 역방향 전파를 한 번만 실행하면 모델이 훈련 데이터에서 법칙/추세를 학습하는 것만으로는 충분하지 않다는 것입니다. 아이가 초등학교에 하루 다니는 것과 비교할 수 있습니다. 그/그녀는 무언가를 배우기 위해 한 번만 학교에 가는 것이 아니라 날마다, 해마다 학교에 가야 합니다.
따라서 모델에 대해 순방향 및 역방향 전파를 여러 번 반복해야 합니다. 이것이 바로 trainModel() 함수가 수행하는 작업입니다. 이는 NanoNeuron 모델의 "교사"와 같습니다.
epochs )을 보내고 모델을 훈련/가르치려고 할 것입니다.xTrain 및 yTrain 데이터 세트)을 사용합니다.alpha 사용하여 우리 아이가 더 열심히(더 빠르게) 배우도록 유도할 것입니다. 학습률 alpha 에 대한 몇 마디입니다. 이는 역방향 전파 중에 계산한 dW 및 dB 값의 승수일 뿐입니다. 따라서 도함수는 비용 함수( dW 및 dB 부호)의 최소값을 찾기 위해 취해야 할 방향을 알려주었고 해당 방향( dW 및 dB 의 절대값)으로 얼마나 빨리 가야 하는지도 보여주었습니다. 이제 움직임을 최소한으로 더 빠르거나 느리게 조정하기 위해 해당 단계 크기를 alpha 로 곱해야 합니다. 때때로 alpha 에 큰 값을 사용하면 최소값을 뛰어넘어 절대 찾지 못할 수도 있습니다.
교사와의 비유는 선생님이 우리 "나노 아이"를 더 세게 밀수록 "나노 아이"가 더 빨리 배울 것이라는 것입니다. 그러나 교사가 너무 세게 밀면 "아이"는 신경 쇠약에 걸리고 학습을 하지 못할 것입니다. 아무것도 배울 수 없나요?.
모델의 w 및 b 매개변수를 업데이트하는 방법은 다음과 같습니다.
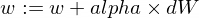
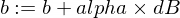
트레이너 기능은 다음과 같습니다.
function trainModel ( { model , epochs , alpha , xTrain , yTrain } ) {
// The is the history array of how NanoNeuron learns.
const costHistory = [ ] ;
// Let's start counting epochs.
for ( let epoch = 0 ; epoch < epochs ; epoch += 1 ) {
// Forward propagation.
const [ predictions , cost ] = forwardPropagation ( model , xTrain , yTrain ) ;
costHistory . push ( cost ) ;
// Backward propagation.
const [ dW , dB ] = backwardPropagation ( predictions , xTrain , yTrain ) ;
// Adjust our NanoNeuron parameters to increase accuracy of our model predictions.
nanoNeuron . w += alpha * dW ;
nanoNeuron . b += alpha * dB ;
}
return costHistory ;
}이제 위에서 만든 함수를 사용해 보겠습니다.
NanoNeuron 모델 인스턴스를 만들어 보겠습니다. 현재 NanoNeuron은 w 및 b 매개변수에 어떤 값을 설정해야 하는지 알 수 없습니다. 그럼 w 와 b 무작위로 설정해보자.
const w = Math . random ( ) ; // i.e. -> 0.9492
const b = Math . random ( ) ; // i.e. -> 0.4570
const nanoNeuron = new NanoNeuron ( w , b ) ;교육 및 테스트 데이터 세트를 생성합니다.
const [ xTrain , yTrain , xTest , yTest ] = generateDataSets ( ) ; 70000 epoch 동안 작은 증분( 0.0005 ) 단계로 모델을 훈련해 보겠습니다. 경험적으로 정의되는 이러한 매개변수를 가지고 놀 수 있습니다.
const epochs = 70000 ;
const alpha = 0.0005 ;
const trainingCostHistory = trainModel ( { model : nanoNeuron , epochs , alpha , xTrain , yTrain } ) ;훈련 중에 비용 함수가 어떻게 변했는지 확인해 보겠습니다. 교육 후 비용은 이전보다 훨씬 낮아질 것으로 예상됩니다. 이는 NanoNeuron이 더 똑똑해졌음을 의미합니다. 그 반대도 가능합니다.
console . log ( 'Cost before the training:' , trainingCostHistory [ 0 ] ) ; // i.e. -> 4694.3335043
console . log ( 'Cost after the training:' , trainingCostHistory [ epochs - 1 ] ) ; // i.e. -> 0.0000024 이것이 시대에 따라 훈련 비용이 변하는 방식입니다. x 축에는 에포크 번호 x1000이 있습니다.
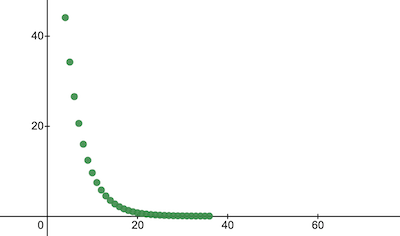
NanoNeuron 매개변수를 살펴보고 무엇을 학습했는지 살펴보겠습니다. NanoNeuron 매개변수 w 및 b NanoNeuron이 이를 모방하려고 시도했기 때문에 celsiusToFahrenheit() 함수( w = 1.8 및 b = 32 )에 있는 매개변수와 유사할 것으로 예상합니다.
console . log ( 'NanoNeuron parameters:' , { w : nanoNeuron . w , b : nanoNeuron . b } ) ; // i.e. -> {w: 1.8, b: 31.99}테스트 데이터 세트의 모델 정확도를 평가하여 NanoNeuron이 알려지지 않은 새로운 데이터 예측을 얼마나 잘 처리하는지 확인하세요. 테스트 세트에 대한 예측 비용은 훈련 비용과 비슷할 것으로 예상됩니다. 이는 NanoNeuron이 알려진 데이터와 알려지지 않은 데이터에 대해 잘 작동한다는 것을 의미합니다.
[ testPredictions , testCost ] = forwardPropagation ( nanoNeuron , xTest , yTest ) ;
console . log ( 'Cost on new testing data:' , testCost ) ; // i.e. -> 0.0000023이제 NanoNeuron "아이"가 훈련 중에 "학교"에서 좋은 성적을 거두었고, 아직 보지 못한 데이터에 대해서도 섭씨 온도를 화씨 온도로 올바르게 변환할 수 있다는 것을 알았으므로 이를 "스마트"라고 부를 수 있습니다. 그리고 그에게 몇 가지 질문을 해보세요. 이것이 전체 훈련 과정의 궁극적인 목표였습니다.
const tempInCelsius = 70 ;
const customPrediction = nanoNeuron . predict ( tempInCelsius ) ;
console . log ( `NanoNeuron "thinks" that ${ tempInCelsius } °C in Fahrenheit is:` , customPrediction ) ; // -> 158.0002
console . log ( 'Correct answer is:' , celsiusToFahrenheit ( tempInCelsius ) ) ; // -> 158너무 가까워요! 우리 모두 인간으로서 NanoNeuron은 훌륭하지만 이상적이지는 않습니다 :)
당신에게 행복한 학습!
저장소를 복제하고 로컬에서 실행할 수 있습니다.
git clone https://github.com/trekhleb/nano-neuron.git
cd nano-neuronnode ./NanoNeuron.js설명의 단순화를 위해 다음 기계 학습 개념을 건너뛰고 단순화했습니다.
학습/테스트 데이터 세트 분할
일반적으로 하나의 큰 데이터 세트가 있습니다. 해당 세트의 예제 수에 따라 학습/테스트 세트에 대해 70/30의 비율로 분할할 수 있습니다. 세트의 데이터는 분할 전에 무작위로 섞여야 합니다. 예제 수가 큰 경우(예: 수백만 개) 학습/테스트 데이터 세트에 대해 90/10 또는 95/5에 가까운 비율로 분할이 발생할 수 있습니다.
네트워크가 힘을 가져온다
일반적으로 하나의 독립형 뉴런만 사용되는 것을 눈치채지 못할 것입니다. 힘은 그러한 뉴런의 네트워크에 있습니다. 네트워크는 훨씬 더 복잡한 기능을 학습할 수 있습니다. NanoNeuron만으로는 신경망보다 단순한 선형 회귀에 더 가깝습니다.
입력 정규화
학습 전에 입력값을 정규화하는 것이 좋습니다.
벡터화된 구현
네트워크의 경우 벡터화된(행렬) 계산이 for 루프보다 훨씬 빠르게 작동합니다. 일반적으로 정방향/역방향 전파는 벡터화된 형식으로 구현되고 Numpy Python 라이브러리 등을 사용하여 계산되는 경우 훨씬 빠르게 작동합니다.
비용 함수의 최소값
이 예에서 사용한 비용 함수는 지나치게 단순화되었습니다. 로그 구성 요소가 있어야 합니다. 비용 함수를 변경하면 파생 상품도 변경되므로 역전파 단계에서도 다른 공식을 사용하게 됩니다.
활성화 기능
일반적으로 뉴런의 출력은 Sigmoid, ReLU 등과 같은 활성화 함수를 통해 전달되어야 합니다.


