meshgpt pytorch
1.8.1
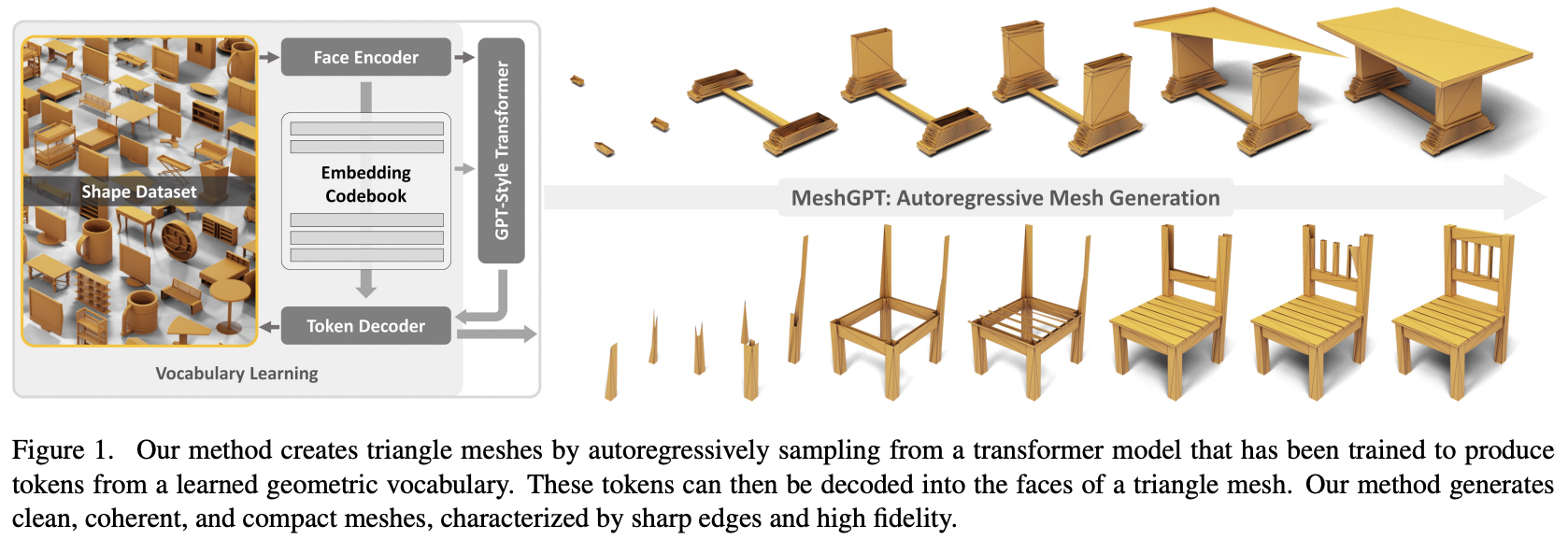
Pytorch에서 Attention을 사용하여 MeshGPT, SOTA Mesh 생성 구현
또한 최종 텍스트를 3D 자산으로 변환하기 위해 텍스트 조건을 추가합니다.
이 작업을 복제하기 위해 다른 사람들과 협력하는 데 관심이 있다면 가입하세요.
업데이트: Marcus는 작업 모델을 교육하고 ? 포옹하는 얼굴!
StabilityAI, A16Z 오픈 소스 AI 보조금 프로그램, 그리고? 현재 인공 지능 연구를 오픈 소스로 독립시킬 수 있도록 아낌없는 후원과 다른 후원자들에게 포옹을 전합니다.
내 삶을 편리하게 해주는 EINOPS
초기 코드 검토(몇 가지 누락된 파생 기능 지적) 및 첫 번째 성공적인 엔드투엔드 실험 실행을 위한 Marcus
라벨에 따라 조절된 모양 모음을 처음으로 성공적으로 훈련한 Marcus
자동 EOS 처리로 수많은 버그를 찾아주신 Quexi Ma
공간 레이블 스무딩을 위한 위치의 가우스 블러링과 관련된 버그를 찾아주신 Yingtian
Marcus는 시스템을 삼각형에서 사각형으로 확장하는 것이 가능하다는 것을 검증하기 위해 실험을 실행했습니다.
텍스트 조건화 문제를 식별하고 문제 해결을 위한 모든 실험을 실행한 Marcus
$ pip install meshgpt-pytorch import torch
from meshgpt_pytorch import (
MeshAutoencoder ,
MeshTransformer
)
# autoencoder
autoencoder = MeshAutoencoder (
num_discrete_coors = 128
)
# mock inputs
vertices = torch . randn (( 2 , 121 , 3 )) # (batch, num vertices, coor (3))
faces = torch . randint ( 0 , 121 , ( 2 , 64 , 3 )) # (batch, num faces, vertices (3))
# make sure faces are padded with `-1` for variable lengthed meshes
# forward in the faces
loss = autoencoder (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training...
# you can pass in the raw face data above to train a transformer to model this sequence of face vertices
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768
)
loss = transformer (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets
faces_coordinates , face_mask = transformer . generate ()
# (batch, num faces, vertices (3), coordinates (3)), (batch, num faces)
# now post process for the generated 3d asset 텍스트 조건이 적용된 3D 모양 합성의 경우 MeshTransformer 에서 condition_on_text = True 로 설정한 다음 설명 목록을 texts 키워드 인수로 전달하면 됩니다.
전.
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768 ,
condition_on_text = True
)
loss = transformer (
vertices = vertices ,
faces = faces ,
texts = [ 'a high chair' , 'a small teapot' ],
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets conditioned on text
faces_coordinates , face_mask = transformer . generate (
texts = [ 'a long table' ],
cond_scale = 8. , # a cond_scale > 1. will enable classifier free guidance - can be placed anywhere from 3. - 10.
remove_parallel_component = True # from https://arxiv.org/abs/2410.02416
) 멀티모달 변환기에서 사용하기 위해 메시를 토큰화하려면 자동 인코더에서 .tokenize 호출하기만 하면 됩니다(또는 지수적으로 평활화된 모델의 경우 자동 인코더 트레이너 인스턴스에서 동일한 방법).
mesh_token_ids = autoencoder . tokenize (
vertices = vertices ,
faces = faces
)
# (batch, num face vertices, residual quantized layer) 프로젝트 루트에서 다음을 실행합니다.
$ cp .env.sample .env오토인코더
face_edges 자동 파생하는 방법을 알아보세요. 변신 로봇
HF 가속 기능이 있는 트레이너 래퍼
자체 CFG 라이브러리를 사용한 텍스트 조절
계층적 변환기(RQ 변환기 사용)
다른 저장소의 단순 게이트 루프 레이어에서 캐싱 수정
지역적 관심
2단계 계층적 변환기에 대한 kv 캐싱 수정 - 이제 7배 더 빠르고 원래의 비계층적 변환기보다 빠릅니다.
게이트루프 레이어에 대한 캐싱 수정
미세한 주의 네트워크와 거친 주의 네트워크의 모델 차원을 사용자 정의할 수 있습니다.
오토인코더가 정말 필요한지 알아보세요 - 필요합니다. 절제에 관한 내용은 논문에 나와 있습니다.
변압기를 효율적으로 만들다
추측적 디코딩 옵션
문서 작성에 하루를 보내다
@inproceedings { Siddiqui2023MeshGPTGT ,
title = { MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers } ,
author = { Yawar Siddiqui and Antonio Alliegro and Alexey Artemov and Tatiana Tommasi and Daniele Sirigatti and Vladislav Rosov and Angela Dai and Matthias Nie{ss}ner } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265457242 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Leviathan2022FastIF ,
title = { Fast Inference from Transformers via Speculative Decoding } ,
author = { Yaniv Leviathan and Matan Kalman and Y. Matias } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:254096365 }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Lee2022AutoregressiveIG ,
title = { Autoregressive Image Generation using Residual Quantization } ,
author = { Doyup Lee and Chiheon Kim and Saehoon Kim and Minsu Cho and Wook-Shin Han } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11513-11522 } ,
url = { https://api.semanticscholar.org/CorpusID:247244535 }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
}

