block recurrent transformer pytorch
0.4.4
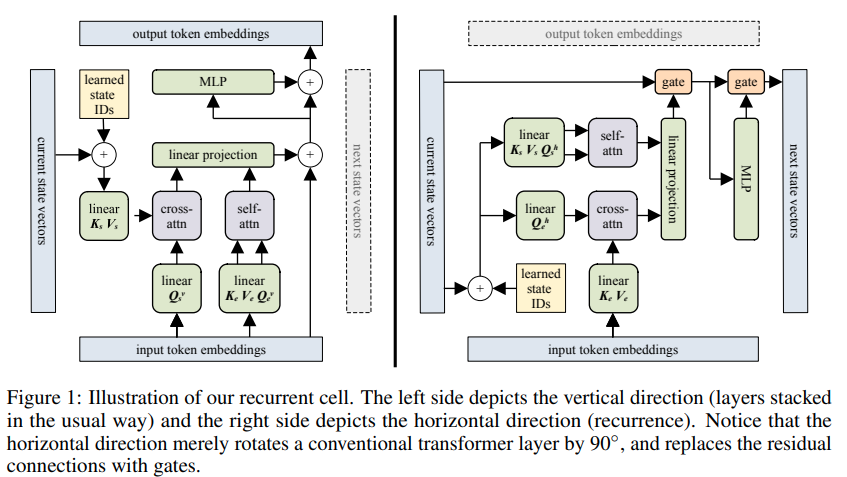
블록 순환 변환기 구현 - Pytorch. 이 논문의 하이라이트는 최대 60,000개의 토큰까지 기억할 수 있는 능력이 보고되었다는 것입니다.
이 디자인은 순환 변압기 연구 라인을 위한 SOTA입니다.
또한 이 백서의 아이디어를 사용하여 최대 250,000개의 토큰에 대한 라우팅된 메모리와 플래시 주의가 포함됩니다.
$ pip install block-recurrent-transformer-pytorch import torch
from block_recurrent_transformer_pytorch import BlockRecurrentTransformer
model = BlockRecurrentTransformer (
num_tokens = 20000 , # vocab size
dim = 512 , # model dimensions
depth = 6 , # depth
dim_head = 64 , # attention head dimensions
heads = 8 , # number of attention heads
max_seq_len = 1024 , # the total receptive field of the transformer, in the paper this was 2 * block size
block_width = 512 , # block size - total receptive field is max_seq_len, 2 * block size in paper. the block furthest forwards becomes the new cached xl memories, which is a block size of 1 (please open an issue if i am wrong)
num_state_vectors = 512 , # number of state vectors, i believe this was a single block size in the paper, but can be any amount
recurrent_layers = ( 4 ,), # where to place the recurrent layer(s) for states with fixed simple gating
use_compressed_mem = False , # whether to use compressed memories of a single block width, from https://arxiv.org/abs/1911.05507
compressed_mem_factor = 4 , # compression factor of compressed memories
use_flash_attn = True # use flash attention, if on pytorch 2.0
)
seq = torch . randint ( 0 , 2000 , ( 1 , 1024 ))
out , mems1 , states1 = model ( seq )
out , mems2 , states2 = model ( seq , xl_memories = mems1 , states = states1 )
out , mems3 , states3 = model ( seq , xl_memories = mems2 , states = states2 ) 먼저 pip install -r requirements.txt 다음
$ python train.py동적 위치 바이어스 사용
강화된 반복 추가
논문에서와 같이 지역 주의 블록을 설정합니다.
훈련용 래퍼 변환기 클래스
RecurrentTrainWrapper 에서 반복으로 생성을 처리합니다.
훈련 중 각 세그먼트 단계에서 전체 메모리 및 상태를 드롭아웃하는 기능을 추가합니다.
enwik8에서 로컬로 전체 시스템을 테스트하고 상태와 메모리를 제거하고 효과를 직접 확인하세요.
단일 헤드 키/값에도 주의를 기울이십시오.
일반 변압기에서 고정 게이팅에 대한 몇 가지 실험을 실행 - 작동하지 않음
플래시 주의를 통합하다
캐시 주의 마스크 + 회전 임베딩
압축된 추억 추가
memformer를 다시 방문하세요
좌표 하강을 사용하여 최대 250k의 장거리 메모리 라우팅을 시도합니다(Wright et al.)
@article { Hutchins2022BlockRecurrentT ,
title = { Block-Recurrent Transformers } ,
author = { DeLesley S. Hutchins and Imanol Schlag and Yuhuai Wu and Ethan Dyer and Behnam Neyshabur } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2203.07852 }
} @article { Shazeer2019FastTD ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam M. Shazeer } ,
journal = { ArXiv } ,
year = { 2019 } ,
volume = { abs/1911.02150 }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Ainslie2023CoLT5FL ,
title = { CoLT5: Faster Long-Range Transformers with Conditional Computation } ,
author = { Joshua Ainslie and Tao Lei and Michiel de Jong and Santiago Ontan'on and Siddhartha Brahma and Yury Zemlyanskiy and David Uthus and Mandy Guo and James Lee-Thorp and Yi Tay and Yun-Hsuan Sung and Sumit Sanghai } ,
year = { 2023 }
}기억은 시간을 통한 주의이다 - 알렉스 그레이브스


