algebraic nnhw
1.0.0
이 저장소에는 동일한 출력을 생성하면서도 값싼 낮은 비트폭 추가를 위해 곱셈의 거의 절반을 교환하는 대체 내부 곱 알고리즘을 실행하여 동일한 성능을 달성하기 위해 거의 절반의 곱셈기 단위가 필요한 ML 하드웨어 아키텍처용 소스 코드가 포함되어 있습니다. 기존의 내부 제품으로. 이는 ML 가속기의 이론적 처리량 및 컴퓨팅 효율성 한계를 증가시킵니다. 자세한 내용은 다음 저널 간행물을 참조하세요.
TE Pogue 및 N. Nicolici, "심층 신경망 가속기를 위한 빠른 내적 알고리즘 및 아키텍처", IEEE Transactions on Computers, vol. 73, 아니. 2, pp. 495-509, 2024년 2월, doi: 10.1109/TC.2023.3334140.
기사 URL: https://ieeeexplore.ieee.org/document/10323219
오픈 액세스 버전: https://arxiv.org/abs/2311.12224
개요: 우리는 1968년 Winograd가 제안한 아직 탐구되지 않은 빠른 내적 알고리즘(FIP)을 개선하는 Free-pipeline Fast Inner Product(FFIP)라는 새로운 알고리즘과 해당 하드웨어 아키텍처를 소개합니다. 컨벌루션 계층인 FIP는 완전 연결 계층, 컨볼루셔널 계층, 순환 계층, 주의/변환기 계층을 포함하여 주로 행렬 곱셈으로 분해될 수 있는 모든 기계 학습(ML) 모델 계층에 적용 가능합니다. 우리는 ML 가속기에서 처음으로 FIP를 구현한 다음 FIP의 클록 주파수를 본질적으로 향상시키고 결과적으로 유사한 하드웨어 비용에 대한 처리량을 향상시키는 FFIP 알고리즘과 일반화된 아키텍처를 제시합니다. 마지막으로 FIP 및 FFIP 알고리즘과 아키텍처에 대한 ML 관련 최적화에 기여합니다. 우리는 FFIP가 기존 고정 소수점 수축기 배열 ML 가속기에 원활하게 통합되어 MAC(곱셈 누산) 장치 수의 절반으로 동일한 처리량을 달성하거나 장치에 맞는 최대 수축기 배열 크기를 두 배로 늘릴 수 있음을 보여줍니다. 고정된 하드웨어 예산. 8~16비트 고정 소수점 입력을 사용하는 비희소 ML 모델에 대한 FFIP 구현은 동일한 유형의 컴퓨팅 플랫폼에서 동급 최고의 이전 솔루션보다 더 높은 처리량과 컴퓨팅 효율성을 달성합니다.
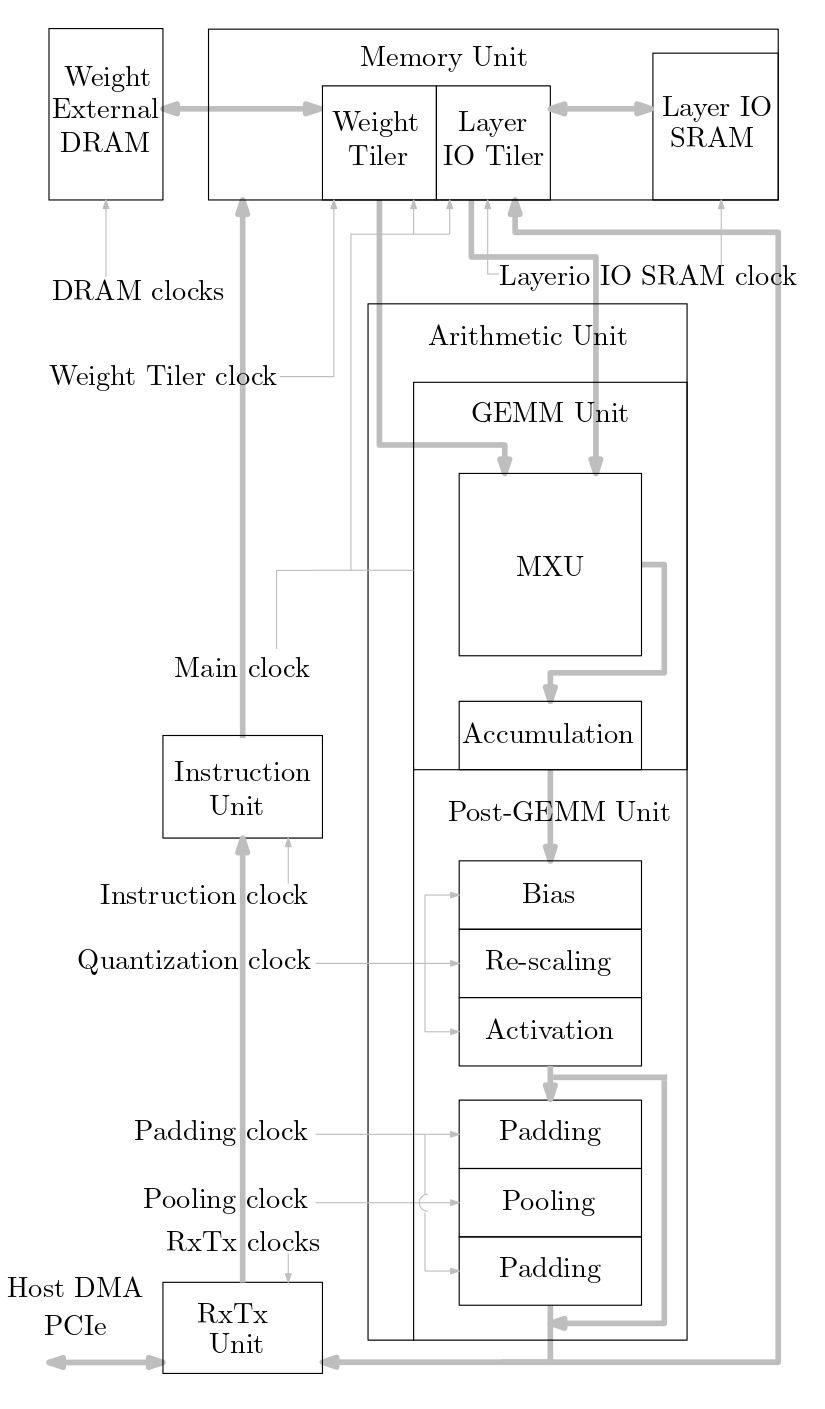
다음 다이어그램은 이 소스 코드에 구현된 ML 가속기 시스템의 개요를 보여줍니다.
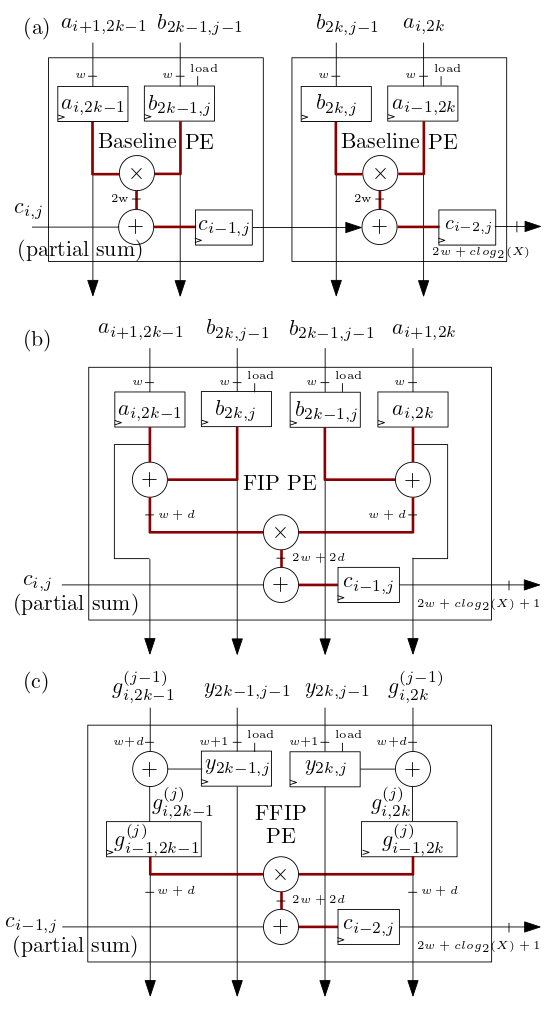
아래 (b)와 (c)에 표시된 FIP 및 FFIP 수축기 배열/MXU 처리 요소(PE)는 FIP 및 FFIP 내적 알고리즘을 구현하고 각각 개별적으로 (에 표시된 두 기준 PE와 동일한 유효 계산 능력을 제공합니다. a) 이전 수축기 배열 ML 가속기에서와 같이 기본 내적을 구현하는 결합:
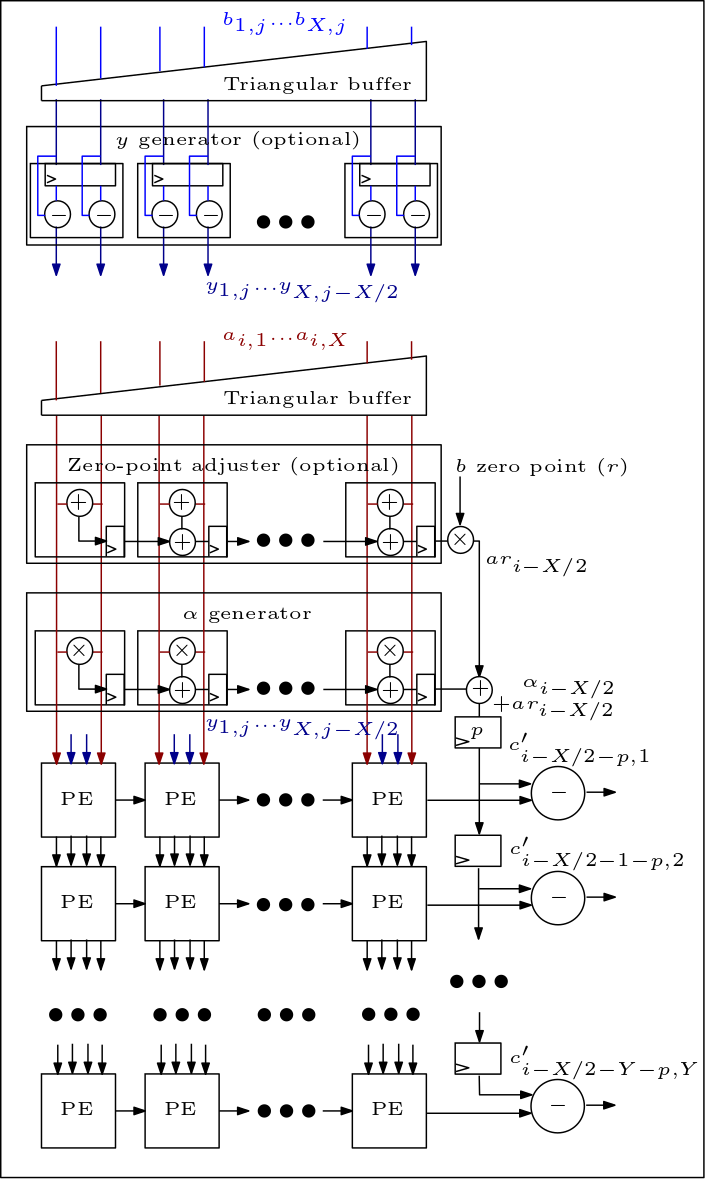
다음은 MXU/수축기 어레이의 다이어그램이며 PE가 연결되는 방식을 보여줍니다.
소스코드 구성은 다음과 같습니다.
rtl/top/define.svh 및 rtl/top/pkg.sv 파일에는 수축기 배열 유형(기준선, FIP 또는 FFIP)을 정의하는 Define.svh의 FIP_METHOD, 정의하는 SZI 및 SZJ와 같은 구성 가능한 여러 매개변수가 포함되어 있습니다. 입력 비트폭을 정의하는 수축기 배열 높이/너비 및 LAYERIO_WIDTH/WEIGHT_WIDTH.
rtl/arith 디렉터리에는 기준선, FIP 및 FFIP 수축기 배열 아키텍처에 대한 RTL이 포함된 mxu.sv 및 mac_array.sv가 포함되어 있습니다(FIP_METHOD 매개변수 값에 따라 다름).


