lumiere pytorch
0.0.24
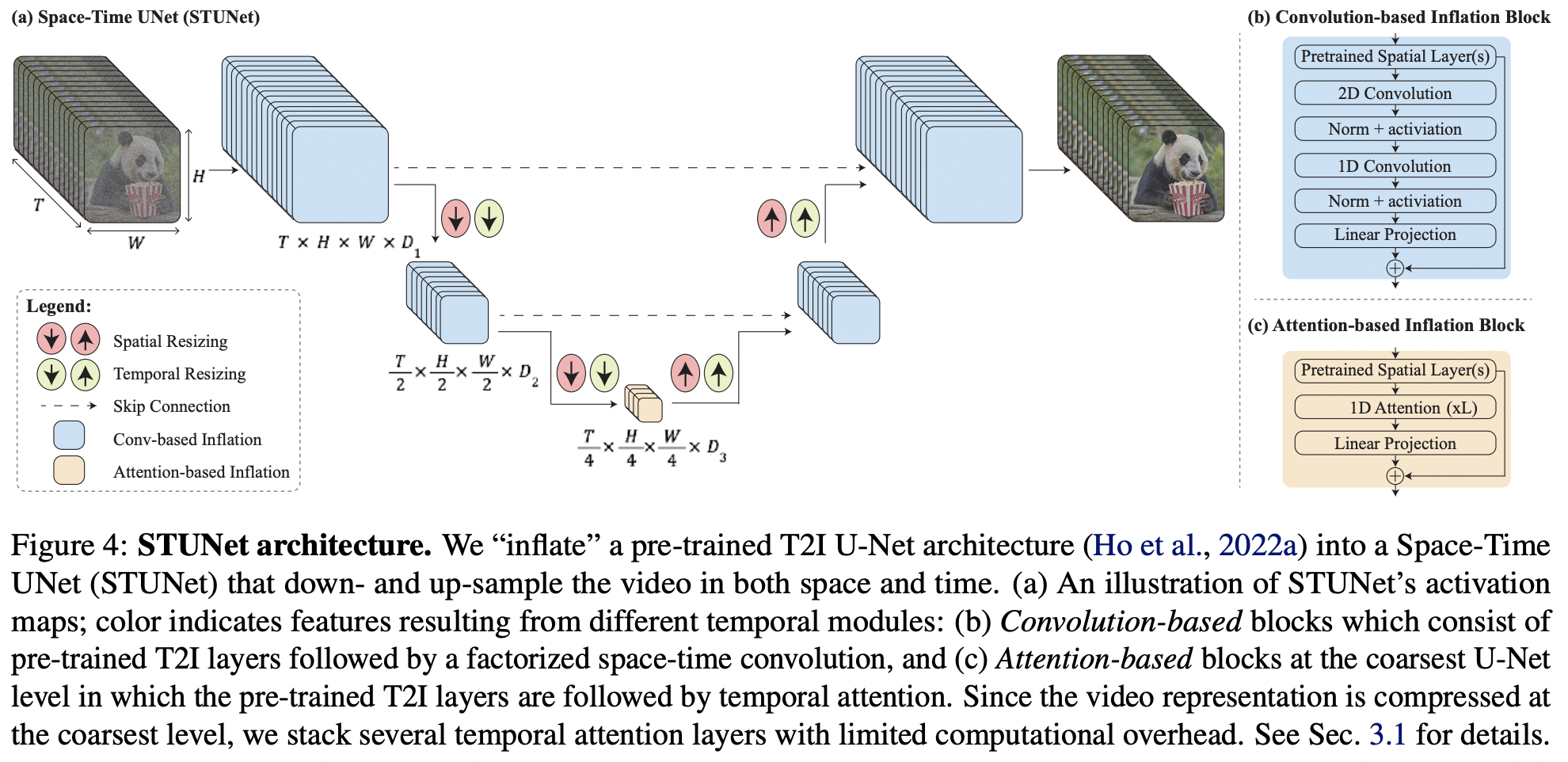
Pytorch에서 Google Deepmind의 SOTA 텍스트-비디오 생성인 Lumiere 구현
Yannic의 논문 리뷰
이 문서는 대부분 텍스트-이미지 모델에 대한 몇 가지 핵심 아이디어이므로 한 단계 더 나아가 이 저장소 내에서 새로운 Karras U-net을 비디오로 확장할 것입니다.
$ pip install lumiere-pytorch import torch
from lumiere_pytorch import MPLumiere
from denoising_diffusion_pytorch import KarrasUnet
karras_unet = KarrasUnet (
image_size = 256 ,
dim = 8 ,
channels = 3 ,
dim_max = 768 ,
)
lumiere = MPLumiere (
karras_unet ,
image_size = 256 ,
unet_time_kwarg = 'time' ,
conv_module_names = [
'downs.1' ,
'ups.1' ,
'downs.2' ,
'ups.2' ,
],
attn_module_names = [
'mids.0'
],
upsample_module_names = [
'ups.2' ,
'ups.1' ,
],
downsample_module_names = [
'downs.1' ,
'downs.2'
]
)
noised_video = torch . randn ( 2 , 3 , 8 , 256 , 256 )
time = torch . ones ( 2 ,)
denoised_video = lumiere ( noised_video , time = time )
assert noised_video . shape == denoised_video . shape 모든 시간적 레이어 추가
학습을 위해 시간적 매개변수만 노출하고 다른 모든 항목은 동결합니다.
시간적 다운샘플링 후 시간 조절을 처리하는 가장 좋은 방법을 찾아보세요. 처음에는 pytree 변환 대신 아마도 모든 모듈에 연결하고 배치 크기를 검사해야 할 것입니다.
(batch, seq, dim) 출력 형태를 가질 수 있는 중간 모듈을 처리합니다.
Tero Karras의 결론에 따라 크기 보존 기능을 갖춘 4개 모듈의 변형을 즉석에서 만들어 보세요.
imagen-pytorch에서 테스트해보세요
다중 확산을 살펴보고 간단한 래퍼로 바뀔 수 있는지 확인하세요.
@inproceedings { BarTal2024LumiereAS ,
title = { Lumiere: A Space-Time Diffusion Model for Video Generation } ,
author = { Omer Bar-Tal and Hila Chefer and Omer Tov and Charles Herrmann and Roni Paiss and Shiran Zada and Ariel Ephrat and Junhwa Hur and Yuanzhen Li and Tomer Michaeli and Oliver Wang and Deqing Sun and Tali Dekel and Inbar Mosseri } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:267095113 }
} @article { Karras2023AnalyzingAI ,
title = { Analyzing and Improving the Training Dynamics of Diffusion Models } ,
author = { Tero Karras and Miika Aittala and Jaakko Lehtinen and Janne Hellsten and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2312.02696 } ,
url = { https://api.semanticscholar.org/CorpusID:265659032 }
}

