Extendible Hashing for DBMS
1.0.0
데이터베이스 시스템을 위한 확장 가능한 해싱의 저수준 구현입니다.
이 방법은 디렉터리와 버킷을 사용하여 데이터를 해시하며 컴퓨팅 시간의 유연성과 효율성으로 널리 알려져 있습니다.
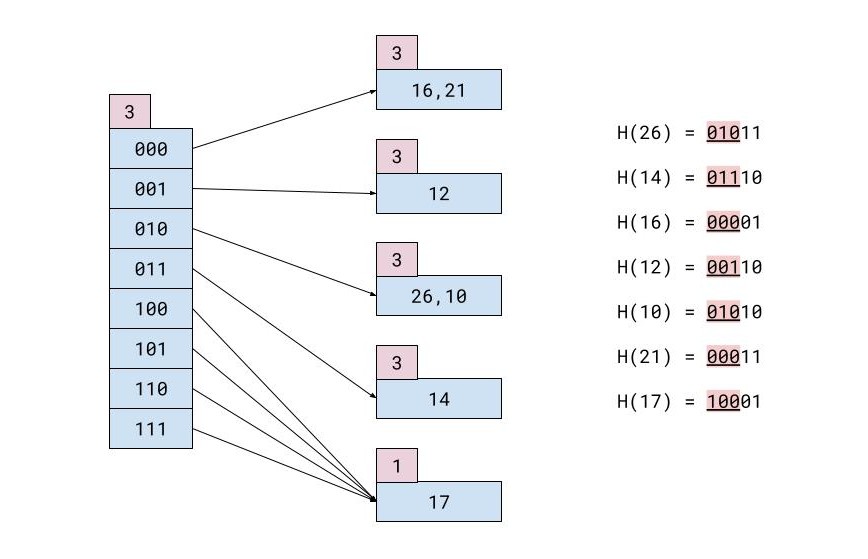
예를 들어 다음과 같은 레코드 테이블이 있습니다.
| ID | 이름 | 성 | 도시 |
|---|---|---|---|
| 26 | 마리아 | 코로니스 | 홍콩 |
| 14 | 크리스토포로스 | 가이타니스 | 도쿄 |
| 16 | 마리아나 | 카르부나리 | 마이애미 |
| 12 | 테오필로스 | 니콜로풀로스 | 런던 |
| 10 | 이오시프 | 스빙고스 | 도쿄 |
| 21 | 테오필로스 | 미카스 | 아테네 |
| 17 | 요르고스 | 할라시스 | 뮌헨 |
각 메모리 블록에 2개의 레코드만 있을 수 있는 경우 모든 삽입 후의 해시 파일은 다음과 같습니다.
이 프로그램은 두 가지 주요 기능으로 실행될 수 있습니다. 첫 번째는 파일에 많은 수의 레코드를 삽입하고 두 번째는 세 개의 다른 파일에 동시에 레코드를 생성하여 삽입합니다.
테스트_메인1:
make main1
./build/runner
test_main2:
make main2
./build/runner