py spider for wechat
1.0.0
2차 개발 및 PR 제출도 환영인가요?
Python을 사용하여 지정된 공개 계정의 과거 기사와 콘텐츠를 크롤링하고 키워드를 사용한 기사 필터링을 지원하는 크롤러를 구축하세요.
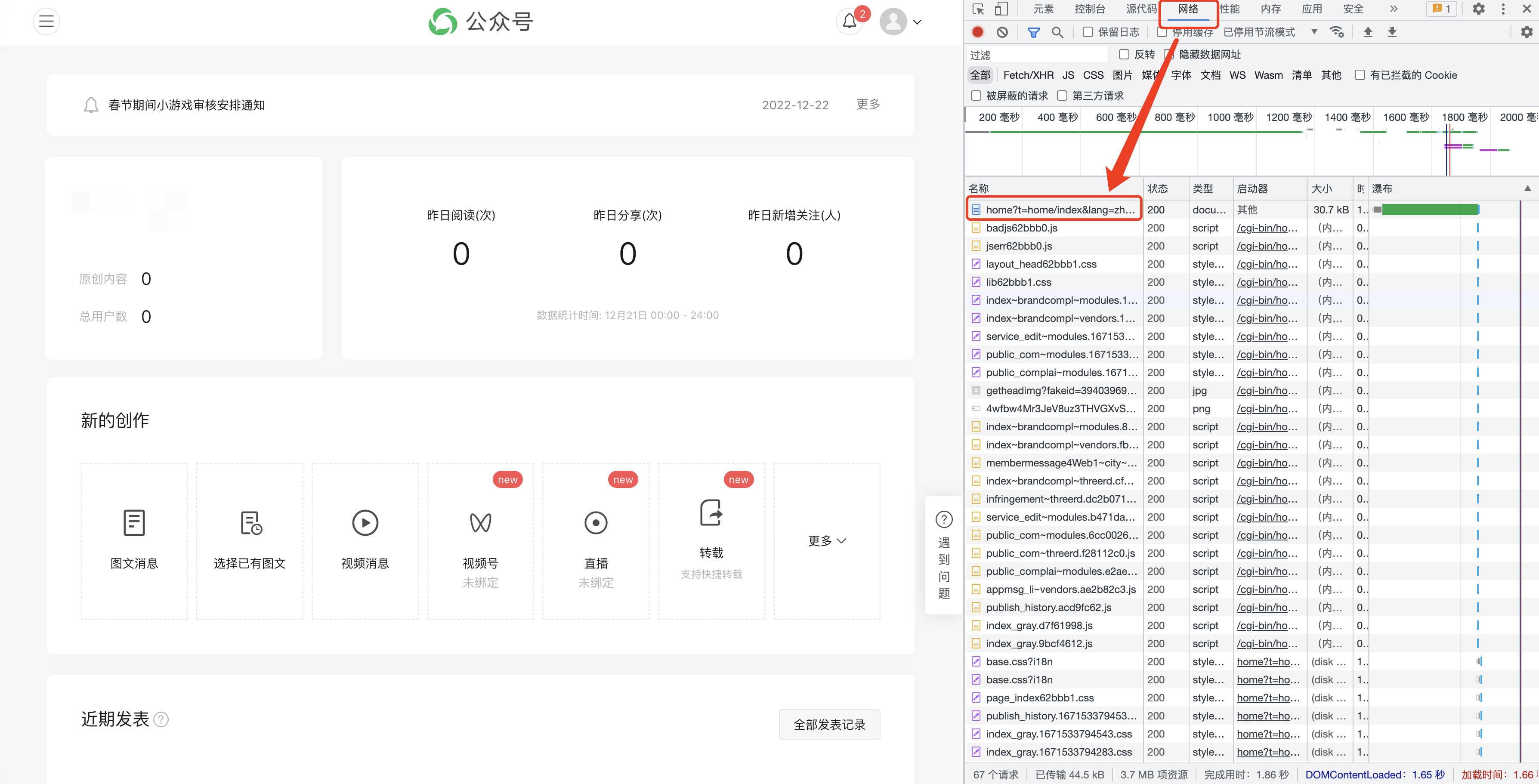
F12 를 눌러 다음 인터페이스를 열고 [네트워크]로 전환합니다. 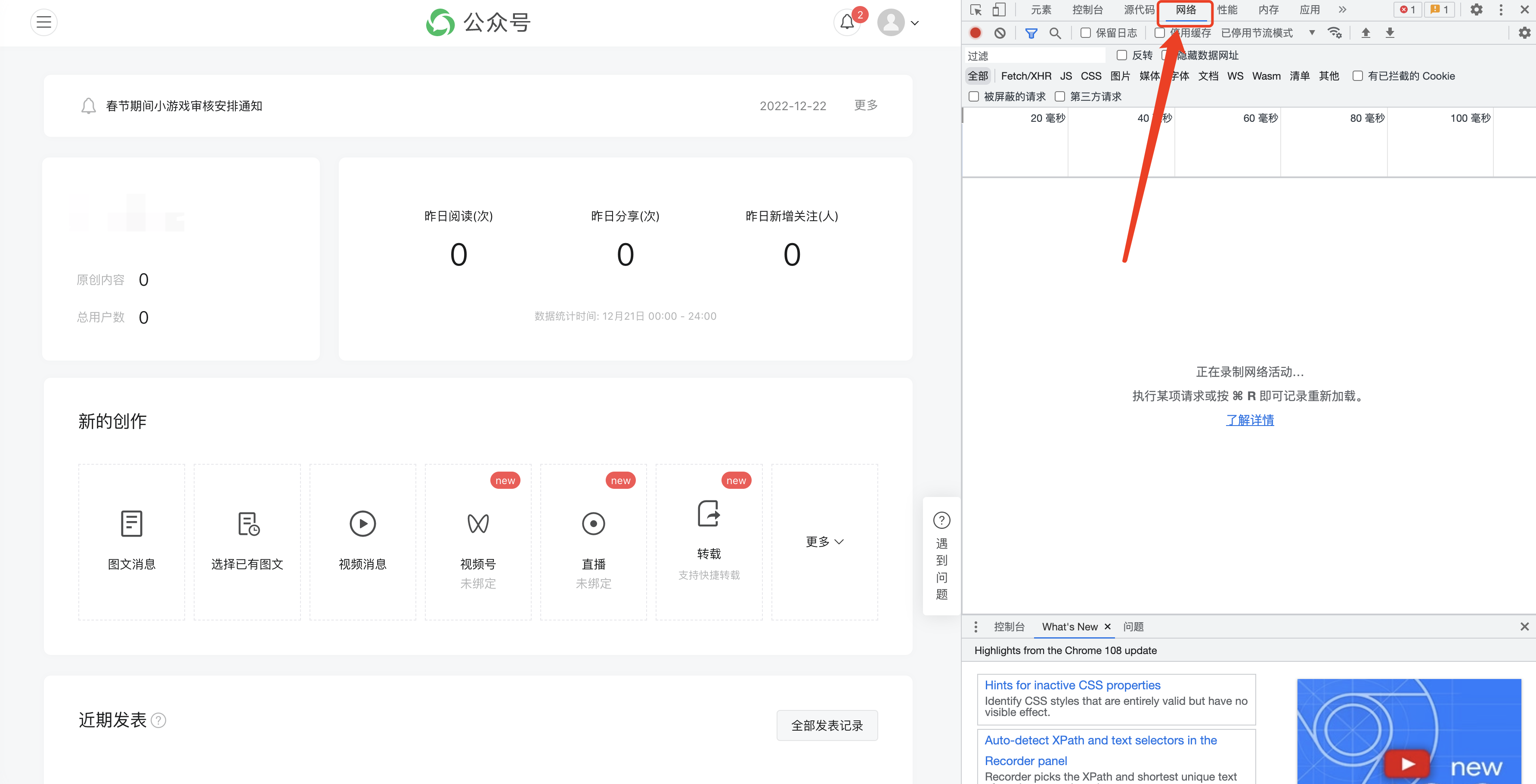
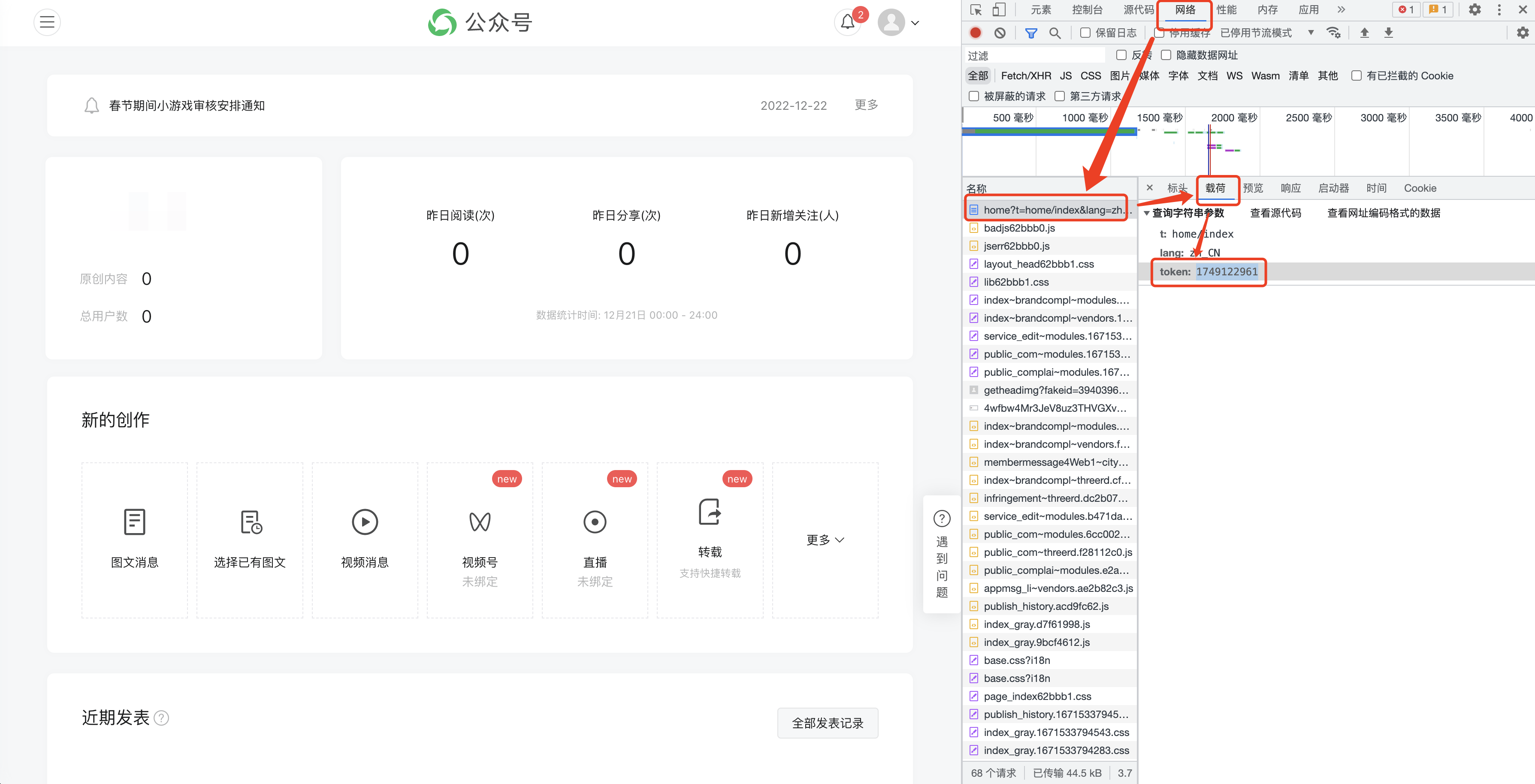
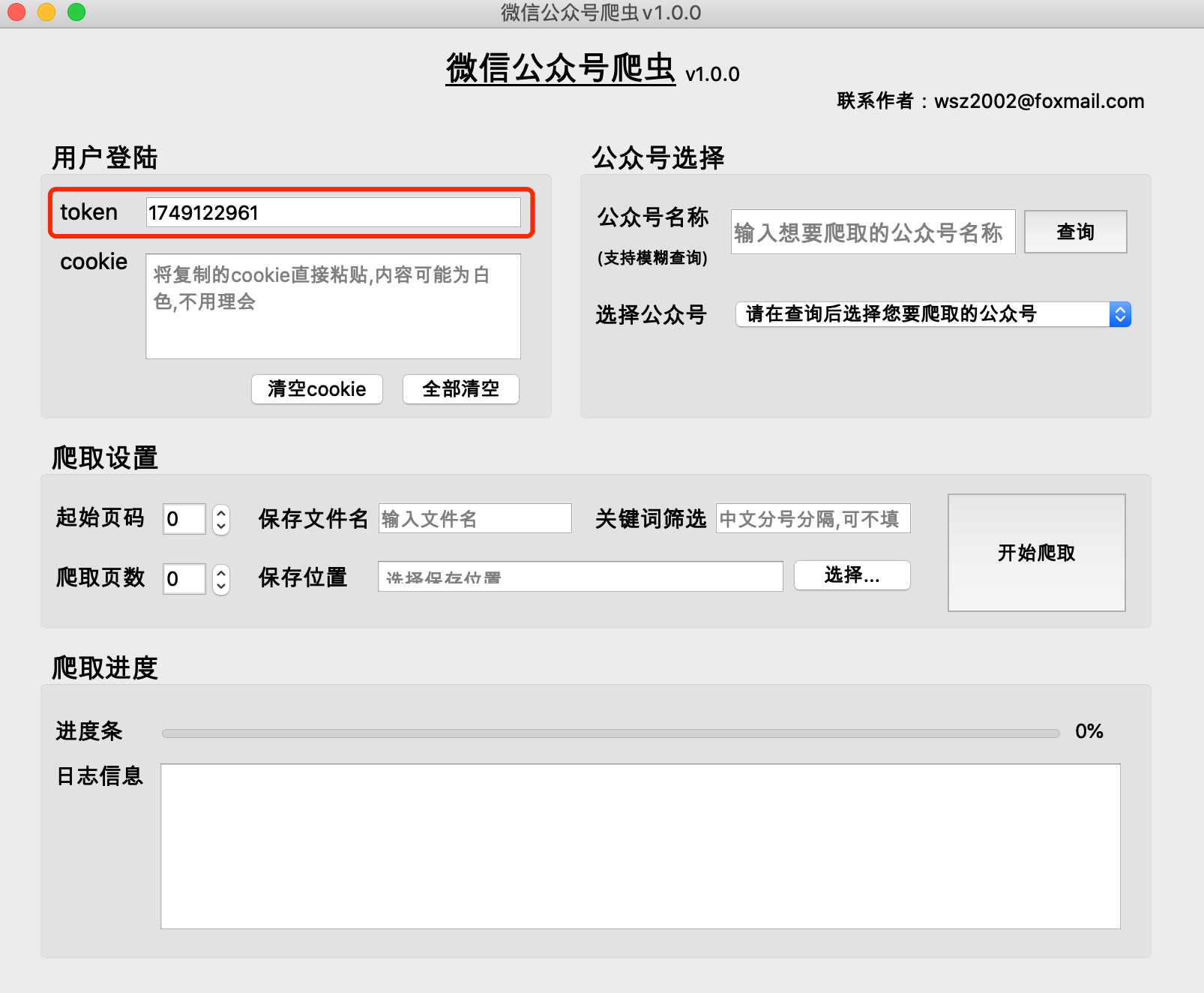
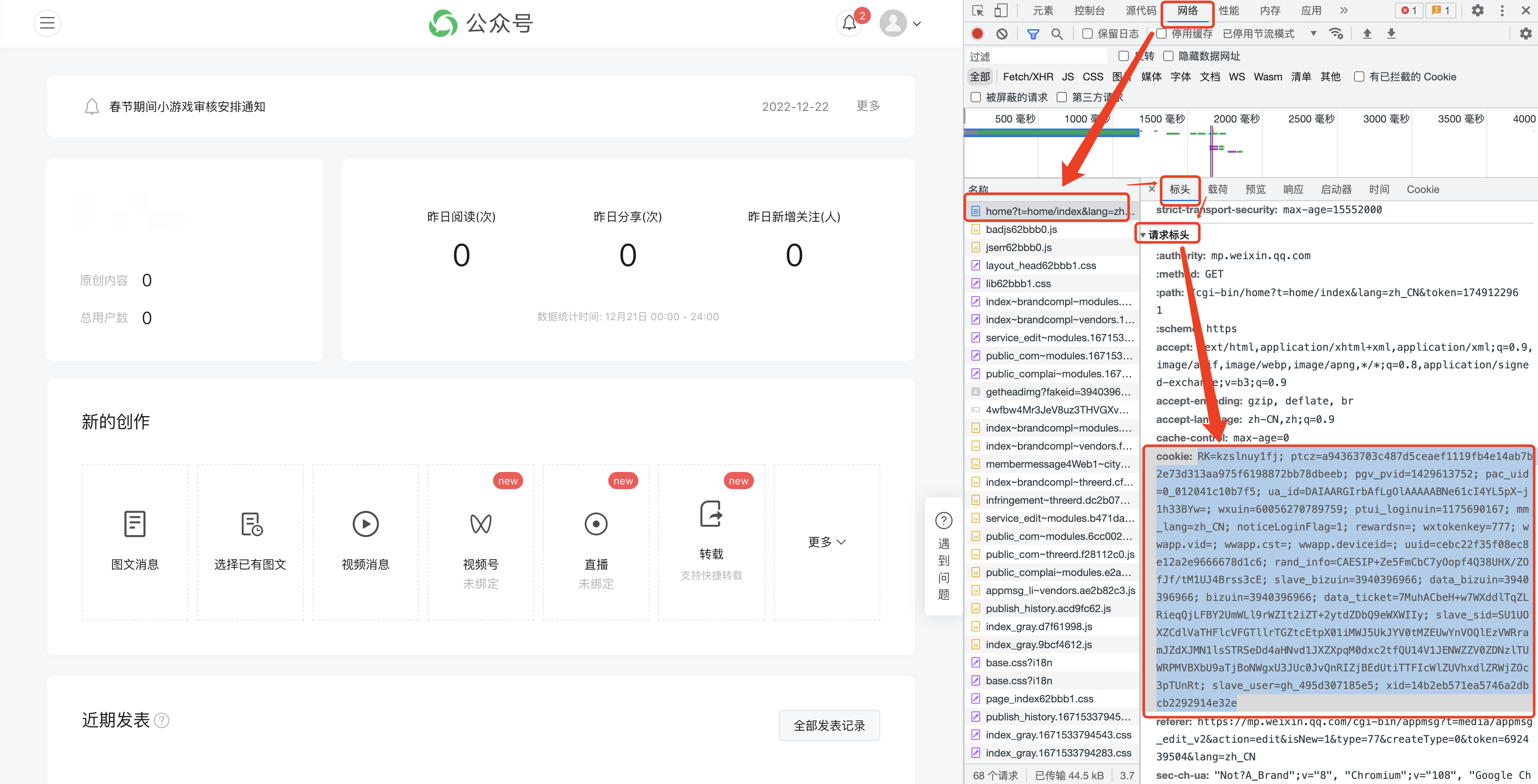
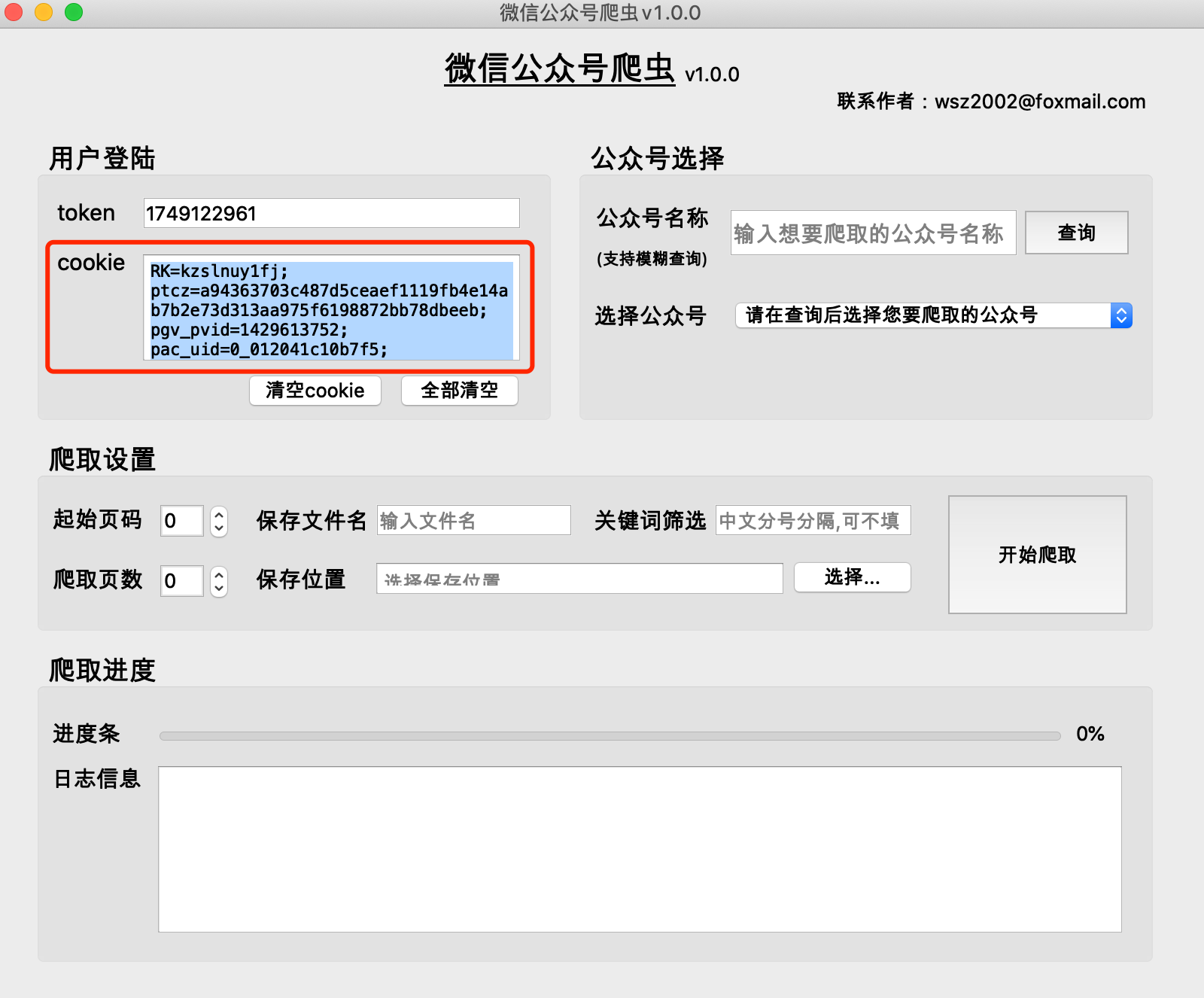
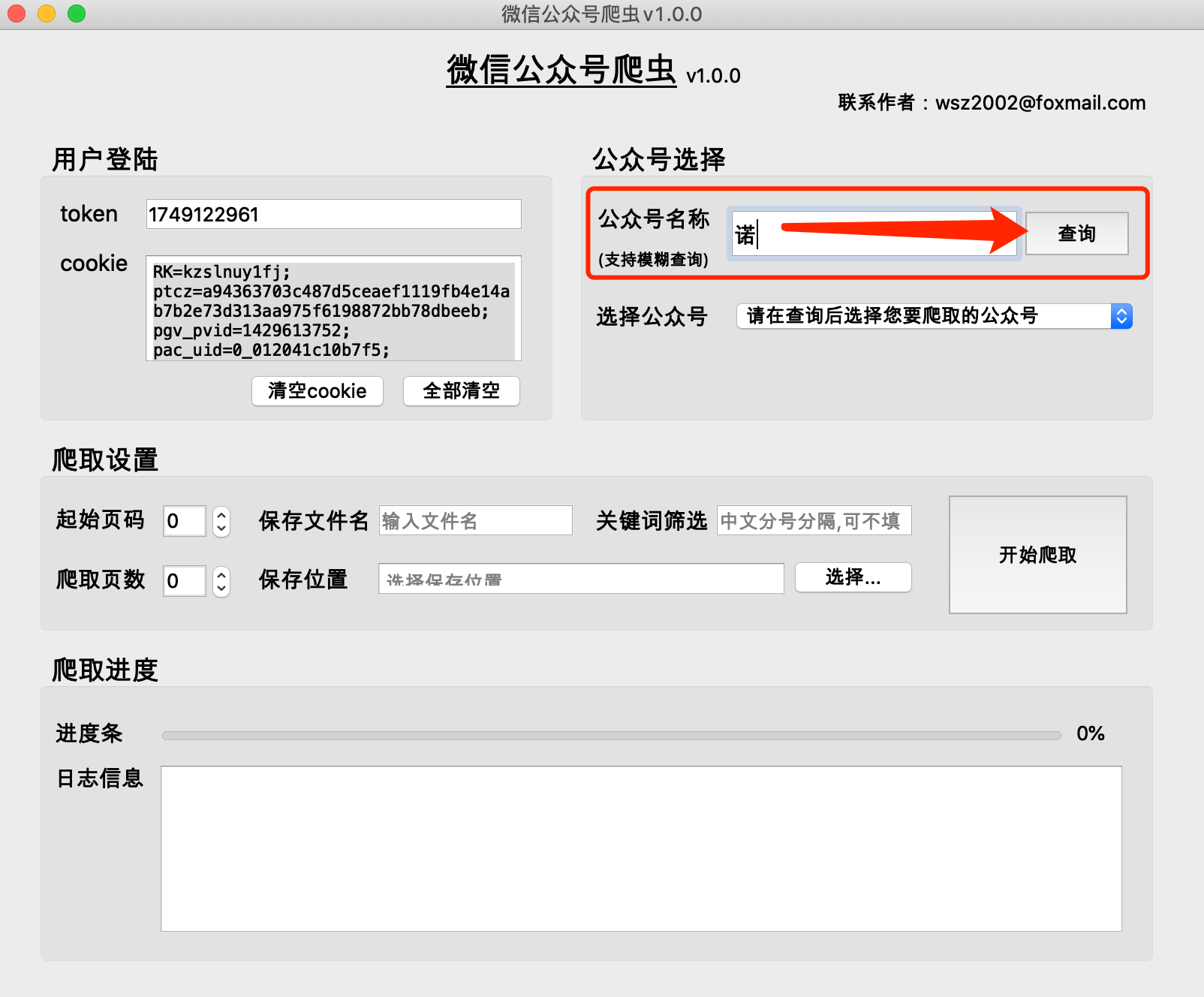
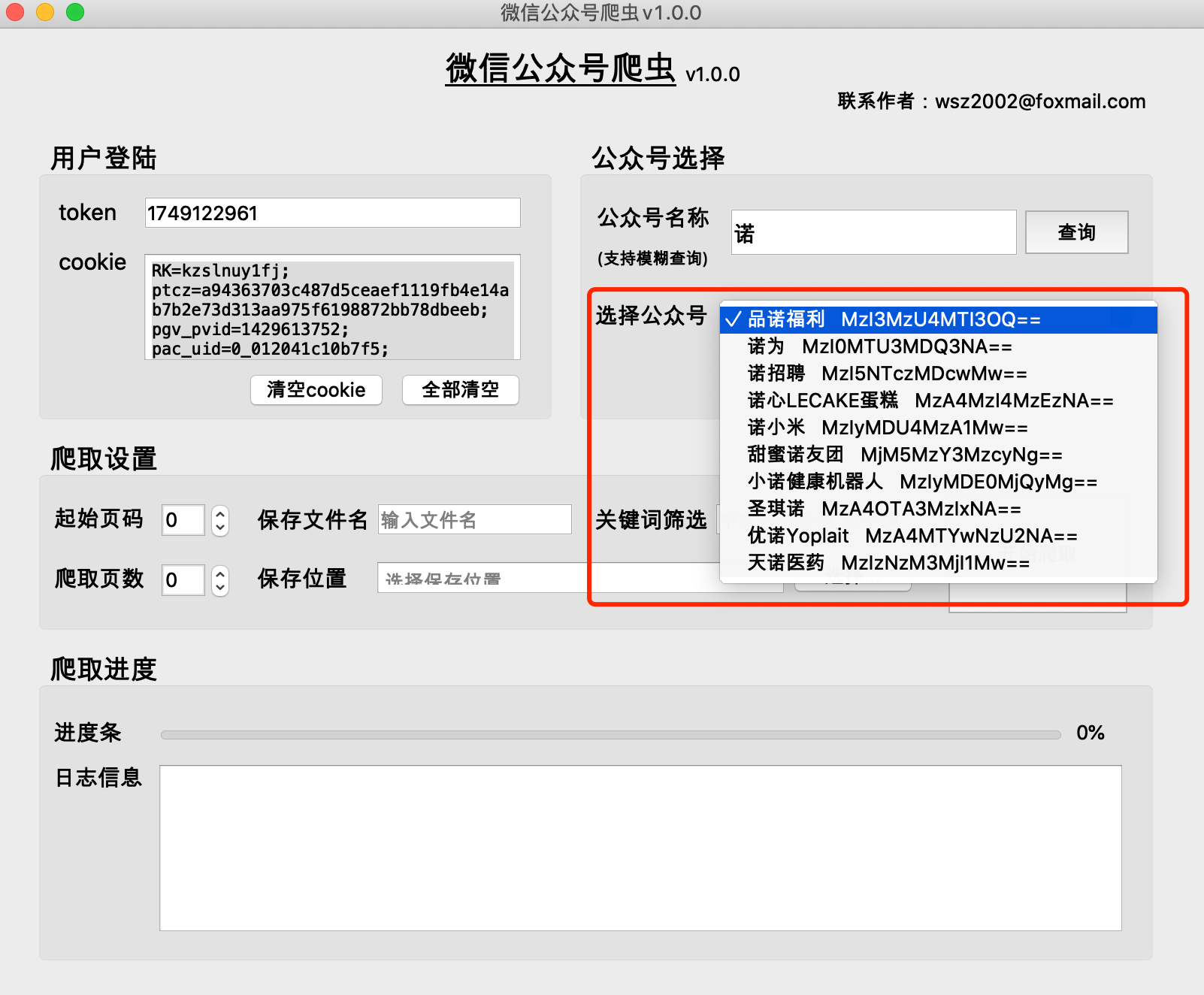
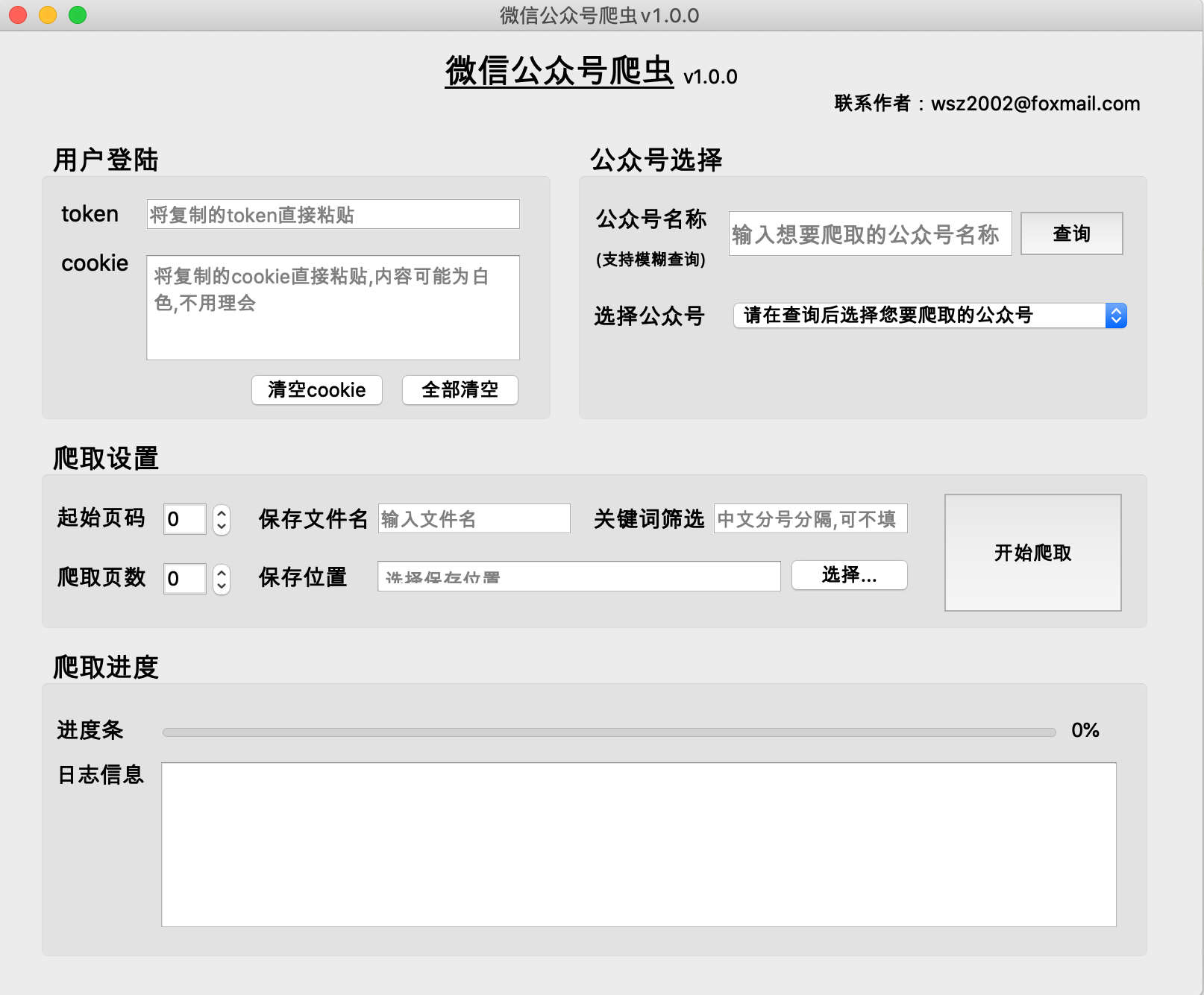
(1) 공개계정의 역사적 기사는 일반적으로 한 페이지에 5~10개의 기사로 구성됩니다.
(2) 공개 계정의 과거 기사 페이지 수가 적을수록 0페이지에 최신 기사가 저장됩니다.
(3) 시작 페이지 번호는 0부터 시작하는 것을 권장합니다.
(4) 크롤링된 페이지 수는 0일 수 없습니다. 그렇지 않으면 크롤링 결과가 비어 있게 됩니다.
올바른 파일 이름을 입력하고 파일 위치를 선택하십시오.
(1) 기능: 키워드를 기준으로 기사를 필터링하고 기사 제목에 키워드가 포함된 기사를 가져오는 데 사용됩니다. 작성하지 않으면 모든 기사가 검색됩니다.
(2) 형식:关键词1;关键词2;关键词3
[중국어 세미콜론]으로 구분, 마지막 키워드 뒤에는 세미콜론 없음
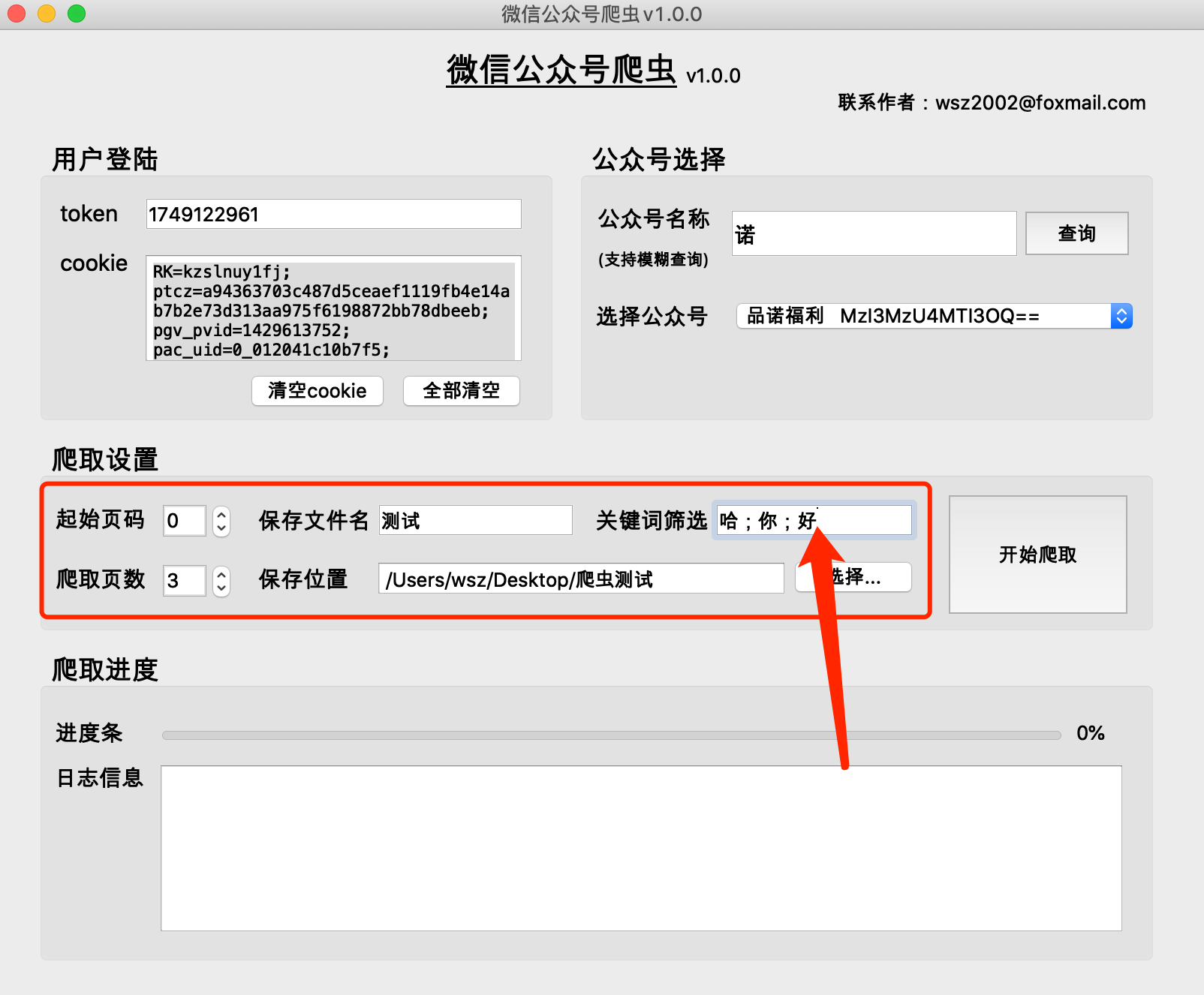
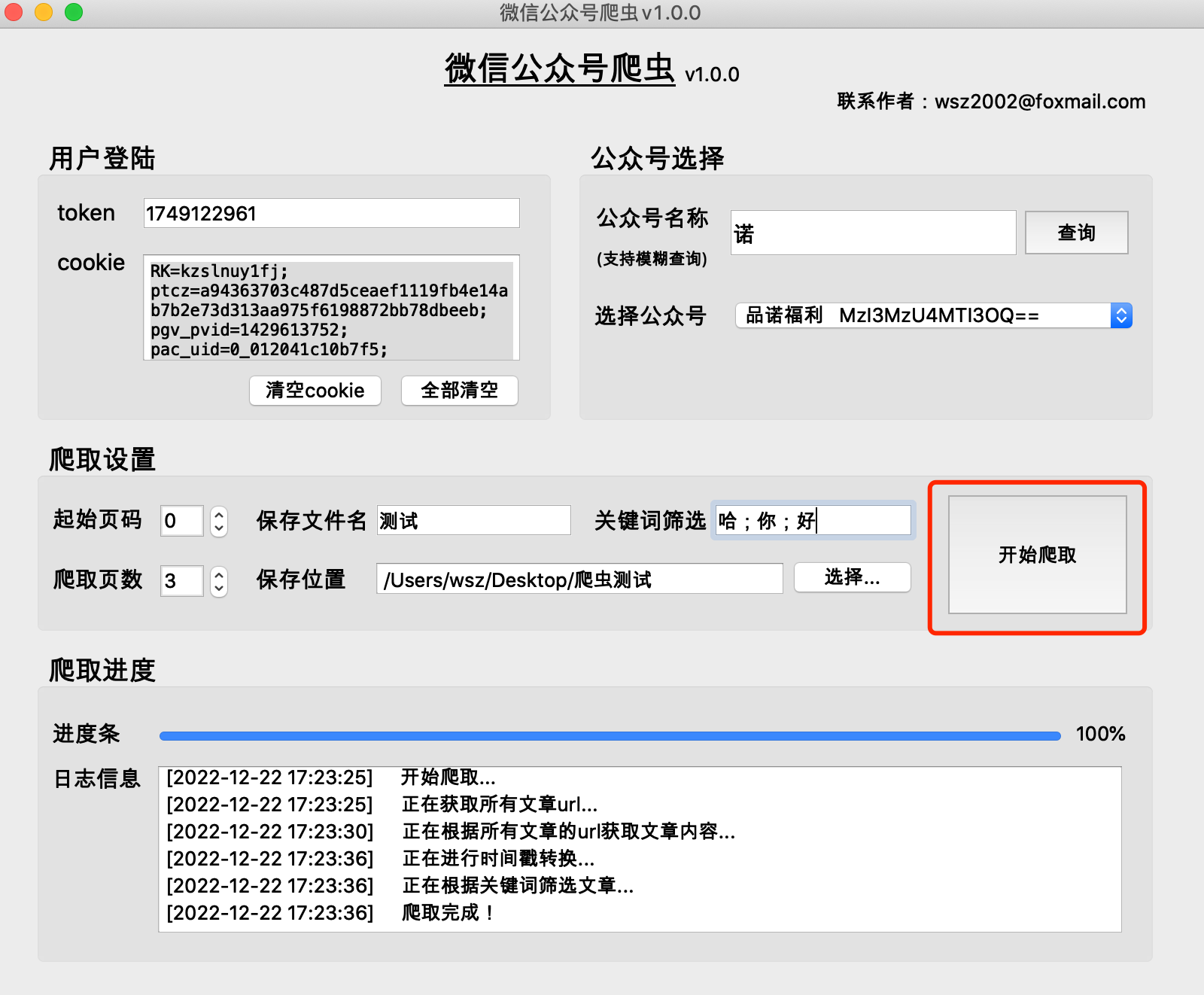
(1) 프로그램은 선택한 파일 저장 위치 디렉터리에保存文件名_当日日期의 폴더를 생성하고 이 폴더에 크롤링된 콘텐츠를 저장합니다.
(2) raw 폴더의 내용은 크롤링 과정에서 생성된 캐시 파일로 삭제될 수 있습니다.