liuli
v0.2.0
간단히 설명하자면 다음과 같습니다.
Collector : 자신이 팔로우하는 공개 계정, 도서, 블로그 소스 등 맞춤형 독서 소스를 모니터링하고 입력 소스로 통일된 표준 형식으로 Liuli 에 유입됩니다.
프로세서 : 기계 학습을 사용하여 과거 광고 데이터를 기반으로 자동으로 광고 분류기에 라벨을 지정하거나 관련 노드에서 실행할 후크 기능을 도입하는 등 대상 콘텐츠를 사용자 정의합니다.
배포자 : 인터페이스 계층을 사용하여 데이터 요청 및 응답을 수행하고 사용자에게 개인화된 구성을 제공한 다음 구성에 따라 자동으로 배포하여 깨끗한 기사를 WeChat, DingTalk, TG, RSS 클라이언트 및 자체 구축 웹사이트에 전달합니다.
후원자 : 처리된 글을 데이터베이스나 GitHub 등에 보관하는 등 백업합니다.
이를 통해 얻은 데이터를 바탕으로 깨끗한 독서 환경을 구축할 수 있습니다.
개발 진행 상황 대시보드:
v0.2.0: 일반적인 시나리오에 대한 솔루션을 적용할 수 있도록 기본 기능을 구현합니다.
v0.3.0: 수집기 사용자 지정을 구현하여 사용자는 자신이 보는 것을 수집할 수 있습니다.
모델의 인식 정확도를 높이기 위해 모든 사람이 광고 샘플을 제공할 수 있기를 바랍니다. 샘플 파일: .files/datasets/ads.csv를 참조하세요. 형식은 다음과 같습니다.
| 제목 | URL | is_process |
|---|---|---|
| 광고 기사 제목 | 광고기사 링크 | 0 |
필드 설명:
제목: 기사 제목
url: 기사 링크. WeChat 기사를 사용하려면 먼저 기사가 유효하지 않은지 확인하세요.
is_process: 샘플 처리 수행 여부를 나타냅니다. 기본적으로 0 입력합니다.
예를 들어보겠습니다:
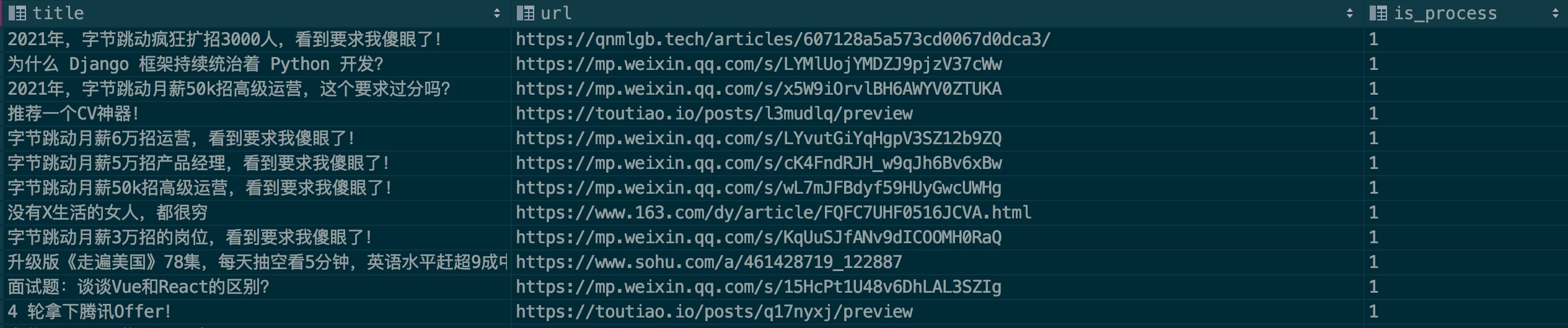
일반적으로 여러 공개 계정에 광고가 반복적으로 게재됩니다. 작성 시 이 기록이 있는지 확인하시기 바랍니다. 모두가 함께 힘을 모아 PR을 통해 힘을 보태주시길 바랍니다.
다음 오픈 소스 프로젝트 덕분에:
Flask: 웹 프레임워크
Vue: 프로그레시브 JavaScript 프레임워크
Ruia: 비동기 크롤러 프레임워크(자체 개발 및 사용)
극작가: 브라우저를 사용한 데이터 스크래핑
위에는 핵심 오픈 소스 종속성만 나열되어 있습니다. 더 많은 타사 종속성을 보려면 Pipfile 파일을 참조하세요.
귀하가 받는 모든 PR은 Liuli 프로젝트에 대한 강력한 지원입니다. (특별한 순서 없이) 기여해 주신 다음 개발자들에게 매우 감사드립니다.
함께 소통하는 것을 환영합니다(그룹 팔로우):


