whisper.cpp
v1.7.2
안정 : v1.7.2 / 로드맵 | FAQ
OpenAI의 Whisper 자동 음성 인식 (ASR) 모델의 고성능 추론 :
지원되는 플랫폼 :
모델의 전체 고급 구현은 Whisper.h 및 Whisper.cpp에 포함되어 있습니다. 나머지 코드는 ggml 머신 러닝 라이브러리의 일부입니다.
이러한 가벼운 모델을 사용하면 모델을 다른 플랫폼과 응용 프로그램에 쉽게 통합 할 수 있습니다. 예를 들어, 다음은 iPhone 13 장치에서 모델을 실행하는 비디오가 있습니다 - 완전히 오프라인, Op -Device : Whisper.objc
당신은 또한 자신의 오프라인 음성 어시스턴트 응용 프로그램을 쉽게 만들 수 있습니다 : 명령
Apple Silicon에서는 추론이 금속을 통해 GPU에서 완전히 실행됩니다.
또는 브라우저에서 바로 실행할 수도 있습니다 : talk.wasm
텐서 연산자는 Apple Silicon CPU에 크게 최적화되어 있습니다. 계산 크기에 따라 ARM Neon Simd Intrinsics 또는 CBLA 가속 프레임 워크 루틴이 사용됩니다. 후자는 Accelerate 프레임 워크가 Modern Apple 제품에서 사용할 수있는 특수 목적 AMX 코 프로세서를 사용하기 때문에 더 큰 크기에 특히 효과적입니다.
먼저 저장소를 복제하십시오.
git clone https://github.com/ggerganov/whisper.cpp.git디렉토리로 이동하십시오.
cd whisper.cpp
그런 다음 ggml 형식으로 변환 된 Whisper 모델 중 하나를 다운로드하십시오. 예를 들어:
sh ./models/download-ggml-model.sh base.en이제 주요 예제를 작성하고 다음과 같은 오디오 파일을 전사하십시오.
# build the main example
make -j
# transcribe an audio file
./main -f samples/jfk.wav 빠른 데모의 경우 간단히 실행 make base.en .
$ make -j base.en
cc -I. -O3 -std=c11 -pthread -DGGML_USE_ACCELERATE -c ggml.c -o ggml.o
c++ -I. -I./examples -O3 -std=c++11 -pthread -c whisper.cpp -o whisper.o
c++ -I. -I./examples -O3 -std=c++11 -pthread examples/main/main.cpp whisper.o ggml.o -o main -framework Accelerate
./main -h
usage: ./main [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
-t N, --threads N [4 ] number of threads to use during computation
-p N, --processors N [1 ] number of processors to use during computation
-ot N, --offset-t N [0 ] time offset in milliseconds
-on N, --offset-n N [0 ] segment index offset
-d N, --duration N [0 ] duration of audio to process in milliseconds
-mc N, --max-context N [-1 ] maximum number of text context tokens to store
-ml N, --max-len N [0 ] maximum segment length in characters
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [5 ] number of best candidates to keep
-bs N, --beam-size N [5 ] beam size for beam search
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
-tdrz, --tinydiarize [false ] enable tinydiarize (requires a tdrz model)
-nf, --no-fallback [false ] do not use temperature fallback while decoding
-otxt, --output-txt [false ] output result in a text file
-ovtt, --output-vtt [false ] output result in a vtt file
-osrt, --output-srt [false ] output result in a srt file
-olrc, --output-lrc [false ] output result in a lrc file
-owts, --output-words [false ] output script for generating karaoke video
-fp, --font-path [/System/Library/Fonts/Supplemental/Courier New Bold.ttf] path to a monospace font for karaoke video
-ocsv, --output-csv [false ] output result in a CSV file
-oj, --output-json [false ] output result in a JSON file
-ojf, --output-json-full [false ] include more information in the JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
-dl, --detect-language [false ] exit after automatically detecting language
--prompt PROMPT [ ] initial prompt
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
-ls, --log-score [false ] log best decoder scores of tokens
-ng, --no-gpu [false ] disable GPU
sh ./models/download-ggml-model.sh base.en
Downloading ggml model base.en ...
ggml-base.en.bin 100%[========================>] 141.11M 6.34MB/s in 24s
Done! Model 'base.en' saved in 'models/ggml-base.en.bin'
You can now use it like this:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
===============================================
Running base.en on all samples in ./samples ...
===============================================
----------------------------------------------
[+] Running base.en on samples/jfk.wav ... (run 'ffplay samples/jfk.wav' to listen)
----------------------------------------------
whisper_init_from_file: loading model from 'models/ggml-base.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 512
whisper_model_load: n_audio_head = 8
whisper_model_load: n_audio_layer = 6
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 512
whisper_model_load: n_text_head = 8
whisper_model_load: n_text_layer = 6
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 2
whisper_model_load: mem required = 215.00 MB (+ 6.00 MB per decoder)
whisper_model_load: kv self size = 5.25 MB
whisper_model_load: kv cross size = 17.58 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 140.60 MB
whisper_model_load: model size = 140.54 MB
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:11.000] And so my fellow Americans, ask not what your country can do for you, ask what you can do for your country.
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: load time = 113.81 ms
whisper_print_timings: mel time = 15.40 ms
whisper_print_timings: sample time = 11.58 ms / 27 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 266.60 ms / 1 runs ( 266.60 ms per run)
whisper_print_timings: decode time = 66.11 ms / 27 runs ( 2.45 ms per run)
whisper_print_timings: total time = 476.31 ms
명령은 base.en 모델을 사용자 정의 ggml 형식으로 변환하고 폴더 samples 의 모든 .wav 샘플에서 추론을 실행합니다.
자세한 사용 지침은 실행 : ./main -h
주요 예제는 현재 16 비트 WAV 파일로만 실행되므로 도구를 실행하기 전에 입력을 변환해야합니다. 예를 들어 다음과 같은 ffmpeg 사용할 수 있습니다.
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wav여분의 오디오 샘플을 재생하려면 간단히 실행하십시오.
make -j samples
Wikipedia에서 몇 가지 오디오 파일을 더 다운로드하여 ffmpeg 통해 16 비트 WAV 형식으로 변환합니다.
다음과 같이 다른 모델을 다운로드하여 실행할 수 있습니다.
make -j tiny.en
make -j tiny
make -j base.en
make -j base
make -j small.en
make -j small
make -j medium.en
make -j medium
make -j large-v1
make -j large-v2
make -j large-v3
make -j large-v3-turbo
| 모델 | 디스크 | 밈 |
|---|---|---|
| 매우 작은 | 75 MIB | ~ 273MB |
| 베이스 | 142 MIB | ~ 388 MB |
| 작은 | 466 MIB | ~ 852 MB |
| 중간 | 1.5 gib | ~ 2.1GB |
| 크기가 큰 | 2.9 gib | ~ 3.9GB |
whisper.cpp Whisper ggml 모델의 정수 양자화를 지원합니다. 양자화 된 모델은 메모리와 디스크 공간이 적으며 하드웨어에 따라보다 효율적으로 처리 할 수 있습니다.
양자화 된 모델을 작성하고 사용하기위한 단계는 다음과 같습니다.
# quantize a model with Q5_0 method
make -j quantize
./quantize models/ggml-base.en.bin models/ggml-base.en-q5_0.bin q5_0
# run the examples as usual, specifying the quantized model file
./main -m models/ggml-base.en-q5_0.bin ./samples/gb0.wav Apple Silicon 장치에서 코어 ML을 통해 ANE (Apple Neural Engine)에서 인코더 추론을 실행할 수 있습니다. 이로 인해 CPU 전용 실행에 비해 X3보다 빠른 속도가 높아질 수 있습니다. 다음은 핵심 ML 모델을 생성하고 whisper.cpp 와 함께 사용하기위한 지침은 다음과 같습니다.
핵심 ML 모델 생성에 필요한 파이썬 종속성을 설치하십시오.
pip install ane_transformers
pip install openai-whisper
pip install coremltoolscoremltools 올바르게 작동하는지 확인하려면 Xcode가 설치되어 있는지 확인하고 xcode-select --install 실행하여 명령 줄 도구를 설치하십시오.conda create -n py310-whisper python=3.10 -yconda activate py310-whisper 핵심 ML 모델을 생성하십시오. 예를 들어, base.en 모델을 생성하려면 사용하십시오.
./models/generate-coreml-model.sh base.en 폴더 models/ggml-base.en-encoder.mlmodelc 가 생성됩니다
Core ML 지원으로 whisper.cpp 구축 :
# using Makefile
make clean
WHISPER_COREML=1 make -j
# using CMake
cmake -B build -DWHISPER_COREML=1
cmake --build build -j --config Release평소와 같이 예제를 실행하십시오. 예를 들어:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_init_state: loading Core ML model from 'models/ggml-base.en-encoder.mlmodelc'
whisper_init_state: first run on a device may take a while ...
whisper_init_state: Core ML model loaded
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 | COREML = 1 |
...
ANE 서비스는 코어 ML 모델을 일부 장치 별 형식으로 컴파일하기 때문에 장치의 첫 번째 실행은 느립니다. 다음 달리기가 더 빠릅니다.
핵심 ML 구현에 대한 자세한 내용은 PR #566을 참조하십시오.
OpenVino를 지원하는 플랫폼에서 X86 CPU 및 Intel GPU (Integrated & Discrete)를 포함한 OpenVino 지원 장치에서 인코더 추론을 실행할 수 있습니다.
이로 인해 인코더 성능에 상당한 속도가 빨라질 수 있습니다. OpenVino 모델을 생성하고 whisper.cpp 와 함께 사용하기위한 지침은 다음과 같습니다.
먼저, Python Virtual Eng을 설정합니다. 파이썬 의존성을 설치하십시오. Python 3.10이 권장됩니다.
Windows :
cd models
python - m venv openvino_conv_env
openvino_conv_envScriptsactivate
python - m pip install -- upgrade pip
pip install - r requirements - openvino.txtLinux 및 MacOS :
cd models
python3 -m venv openvino_conv_env
source openvino_conv_env/bin/activate
python -m pip install --upgrade pip
pip install -r requirements-openvino.txt OpenVino 인코더 모델을 생성합니다. 예를 들어, base.en 모델을 생성하려면 사용하십시오.
python convert-whisper-to-openvino.py --model base.en
이렇게하면 GGML-BASE.EN-ENCODER-OPENVINO.XML/.BIN IR 모델 파일을 생성합니다. OpenVino 확장자가 런타임에 검색 할 기본 위치이므로이를 ggml 모델과 동일한 폴더로 이전하는 것이 좋습니다.
OpenVino 지원으로 whisper.cpp 구축 :
릴리스 페이지에서 OpenVino 패키지를 다운로드하십시오. 사용하는 권장 버전은 2023.0.0입니다.
개발 시스템에 패키지를 다운로드하고 추출한 후 SetupVars 스크립트를 소싱하여 필요한 환경을 설정하십시오. 예를 들어:
Linux :
source /path/to/l_openvino_toolkit_ubuntu22_2023.0.0.10926.b4452d56304_x86_64/setupvars.shWindows (CMD) :
C:PathTow_openvino_toolkit_windows_2023. 0.0 . 10926. b4452d56304_x86_64 setupvars.bat그런 다음 cmake를 사용하여 프로젝트를 구축하십시오.
cmake -B build -DWHISPER_OPENVINO=1
cmake --build build -j --config Release평소와 같이 예제를 실행하십시오. 예를 들어:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_ctx_init_openvino_encoder: loading OpenVINO model from 'models/ggml-base.en-encoder-openvino.xml'
whisper_ctx_init_openvino_encoder: first run on a device may take a while ...
whisper_openvino_init: path_model = models/ggml-base.en-encoder-openvino.xml, device = GPU, cache_dir = models/ggml-base.en-encoder-openvino-cache
whisper_ctx_init_openvino_encoder: OpenVINO model loaded
system_info: n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 | COREML = 0 | OPENVINO = 1 |
...
OpenVino 프레임 워크가 IR (중간 표현) 모델을 장치 별 '블로브'로 컴파일하기 때문에 OpenVino 장치에서 처음으로 실행되는 것은 느립니다. 이 장치 별 블로브는 다음 실행을 위해 캐시됩니다.
핵심 ML 구현에 대한 자세한 내용은 PR #1037을 참조하십시오.
NVIDIA 카드를 사용하면 모델의 처리는 Cublas 및 Custom Cuda 커널을 통해 GPU에서 효율적으로 수행됩니다. 먼저 cuda : https://developer.nvidia.com/cuda-downloads를 설치했는지 확인하십시오
이제 CUDA 지원으로 whisper.cpp 구축하십시오.
make clean
GGML_CUDA=1 make -j
GPU의 워크로드를 가속화 할 수있는 크로스 벤더 솔루션. 먼저 그래픽 카드 드라이버가 Vulkan API를 지원하는지 확인하십시오.
이제 Vulkan 지원으로 whisper.cpp 구축하십시오.
make clean
make GGML_VULKAN=1 -j
OpenBlas를 통해 CPU에서 인코더 처리를 가속화 할 수 있습니다. 먼저 openblas 설치했는지 확인하십시오 : https://www.openblas.net/
이제 OpenBlas 지원으로 whisper.cpp 구축하십시오.
make clean
GGML_OPENBLAS=1 make -j
인텔 수학 커널 라이브러리의 BLAS 호환 인터페이스를 통해 CPU에서 인코더 처리를 가속화 할 수 있습니다. 먼저, 인텔의 MKL 런타임 및 개발 패키지를 설치했는지 확인하십시오 : https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl-dolload.html
이제 Intel MKL BLAS 지원으로 whisper.cpp 구축하십시오.
source /opt/intel/oneapi/setvars.sh
mkdir build
cd build
cmake -DWHISPER_MKL=ON ..
WHISPER_MKL=1 make -j
Ascend NPU는 CANN 및 AI 코어를 통해 추론 가속을 제공합니다.
먼저 Ascend NPU 장치가 지원되는지 확인하십시오.
확인 된 장치
| NPU를 상승시킵니다 | 상태 |
|---|---|
| 아틀라스 300T A2 | 지원하다 |
그런 다음 CANN toolkit 설치했는지 확인하십시오. CANN의 지속 된 버전에는 권장됩니다.
이제 CANN 지원으로 whisper.cpp 구축하십시오.
mkdir build
cd build
cmake .. -D GGML_CANN=on
make -j
평소와 같이 추론 예제를 실행하십시오.
./build/bin/main -f samples/jfk.wav -m models/ggml-base.en.bin -t 8
참고 :
Verified devices 업데이트하십시오. 이 프로젝트에는 2 개의 Docker 이미지가 있습니다.
ghcr.io/ggerganov/whisper.cpp:main :이 이미지에는 curl 및 ffmpeg 뿐만 아니라 기본 실행 파일이 포함되어 있습니다. (플랫폼 : linux/amd64 , linux/arm64 )ghcr.io/ggerganov/whisper.cpp:main-cuda : main 과 동일하지만 CUDA 지원으로 편집되었습니다. (플랫폼 : linux/amd64 ) # download model and persist it in a local folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./models/download-ggml-model.sh base /models "
# transcribe an audio file
docker run -it --rm
-v path/to/models:/models
-v path/to/audios:/audios
whisper.cpp:main " ./main -m /models/ggml-base.bin -f /audios/jfk.wav "
# transcribe an audio file in samples folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./main -m /models/ggml-base.bin -f ./samples/jfk.wav " Whisper.cpp 용 사전 제작 된 바이너리를 설치하거나 Conan을 사용하여 소스에서 빌드 할 수 있습니다. 다음 명령을 사용하십시오.
conan install --requires="whisper-cpp/[*]" --build=missing
Conan 사용 방법에 대한 자세한 지침은 Conan 문서를 참조하십시오.
다음은 medium.en 모델을 사용하여 MacBook M1 Pro에서 약 30 분 만에 3:24 분 연설을 전사하는 또 다른 예입니다.
$ ./main -m models/ggml-medium.en.bin -f samples/gb1.wav -t 8
whisper_init_from_file: loading model from 'models/ggml-medium.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 1024
whisper_model_load: n_audio_head = 16
whisper_model_load: n_audio_layer = 24
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 1024
whisper_model_load: n_text_head = 16
whisper_model_load: n_text_layer = 24
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 4
whisper_model_load: mem required = 1720.00 MB (+ 43.00 MB per decoder)
whisper_model_load: kv self size = 42.00 MB
whisper_model_load: kv cross size = 140.62 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 1462.35 MB
whisper_model_load: model size = 1462.12 MB
system_info: n_threads = 8 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/gb1.wav' (3179750 samples, 198.7 sec), 8 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:08.000] My fellow Americans, this day has brought terrible news and great sadness to our country.
[00:00:08.000 --> 00:00:17.000] At nine o'clock this morning, Mission Control in Houston lost contact with our Space Shuttle Columbia.
[00:00:17.000 --> 00:00:23.000] A short time later, debris was seen falling from the skies above Texas.
[00:00:23.000 --> 00:00:29.000] The Columbia's lost. There are no survivors.
[00:00:29.000 --> 00:00:32.000] On board was a crew of seven.
[00:00:32.000 --> 00:00:39.000] Colonel Rick Husband, Lieutenant Colonel Michael Anderson, Commander Laurel Clark,
[00:00:39.000 --> 00:00:48.000] Captain David Brown, Commander William McCool, Dr. Kultna Shavla, and Ilan Ramon,
[00:00:48.000 --> 00:00:52.000] a colonel in the Israeli Air Force.
[00:00:52.000 --> 00:00:58.000] These men and women assumed great risk in the service to all humanity.
[00:00:58.000 --> 00:01:03.000] In an age when space flight has come to seem almost routine,
[00:01:03.000 --> 00:01:07.000] it is easy to overlook the dangers of travel by rocket
[00:01:07.000 --> 00:01:12.000] and the difficulties of navigating the fierce outer atmosphere of the Earth.
[00:01:12.000 --> 00:01:18.000] These astronauts knew the dangers, and they faced them willingly,
[00:01:18.000 --> 00:01:23.000] knowing they had a high and noble purpose in life.
[00:01:23.000 --> 00:01:31.000] Because of their courage and daring and idealism, we will miss them all the more.
[00:01:31.000 --> 00:01:36.000] All Americans today are thinking as well of the families of these men and women
[00:01:36.000 --> 00:01:40.000] who have been given this sudden shock and grief.
[00:01:40.000 --> 00:01:45.000] You're not alone. Our entire nation grieves with you,
[00:01:45.000 --> 00:01:52.000] and those you love will always have the respect and gratitude of this country.
[00:01:52.000 --> 00:01:56.000] The cause in which they died will continue.
[00:01:56.000 --> 00:02:04.000] Mankind is led into the darkness beyond our world by the inspiration of discovery
[00:02:04.000 --> 00:02:11.000] and the longing to understand. Our journey into space will go on.
[00:02:11.000 --> 00:02:16.000] In the skies today, we saw destruction and tragedy.
[00:02:16.000 --> 00:02:22.000] Yet farther than we can see, there is comfort and hope.
[00:02:22.000 --> 00:02:29.000] In the words of the prophet Isaiah, "Lift your eyes and look to the heavens
[00:02:29.000 --> 00:02:35.000] who created all these. He who brings out the starry hosts one by one
[00:02:35.000 --> 00:02:39.000] and calls them each by name."
[00:02:39.000 --> 00:02:46.000] Because of His great power and mighty strength, not one of them is missing.
[00:02:46.000 --> 00:02:55.000] The same Creator who names the stars also knows the names of the seven souls we mourn today.
[00:02:55.000 --> 00:03:01.000] The crew of the shuttle Columbia did not return safely to earth,
[00:03:01.000 --> 00:03:05.000] yet we can pray that all are safely home.
[00:03:05.000 --> 00:03:13.000] May God bless the grieving families, and may God continue to bless America.
[00:03:13.000 --> 00:03:19.000] [Silence]
whisper_print_timings: fallbacks = 1 p / 0 h
whisper_print_timings: load time = 569.03 ms
whisper_print_timings: mel time = 146.85 ms
whisper_print_timings: sample time = 238.66 ms / 553 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 18665.10 ms / 9 runs ( 2073.90 ms per run)
whisper_print_timings: decode time = 13090.93 ms / 549 runs ( 23.85 ms per run)
whisper_print_timings: total time = 32733.52 ms
이것은 마이크에서 오디오에서 실시간 추론을 수행하는 순진한 예입니다. 스트림 도구는 0.5 초마다 오디오를 샘플링하고 전사를 지속적으로 실행합니다. 더 많은 정보는 이슈 #10에서 확인할 수 있습니다.
make stream -j
./stream -m ./models/ggml-base.en.bin -t 8 --step 500 --length 5000 --print-colors 인수를 추가하면 실험적인 색상 코딩 전략을 사용하여 전사 된 텍스트를 인쇄하여 자신감이 높거나 낮은 단어를 강조합니다.
./main -m models/ggml-base.en.bin -f samples/gb0.wav --print-colors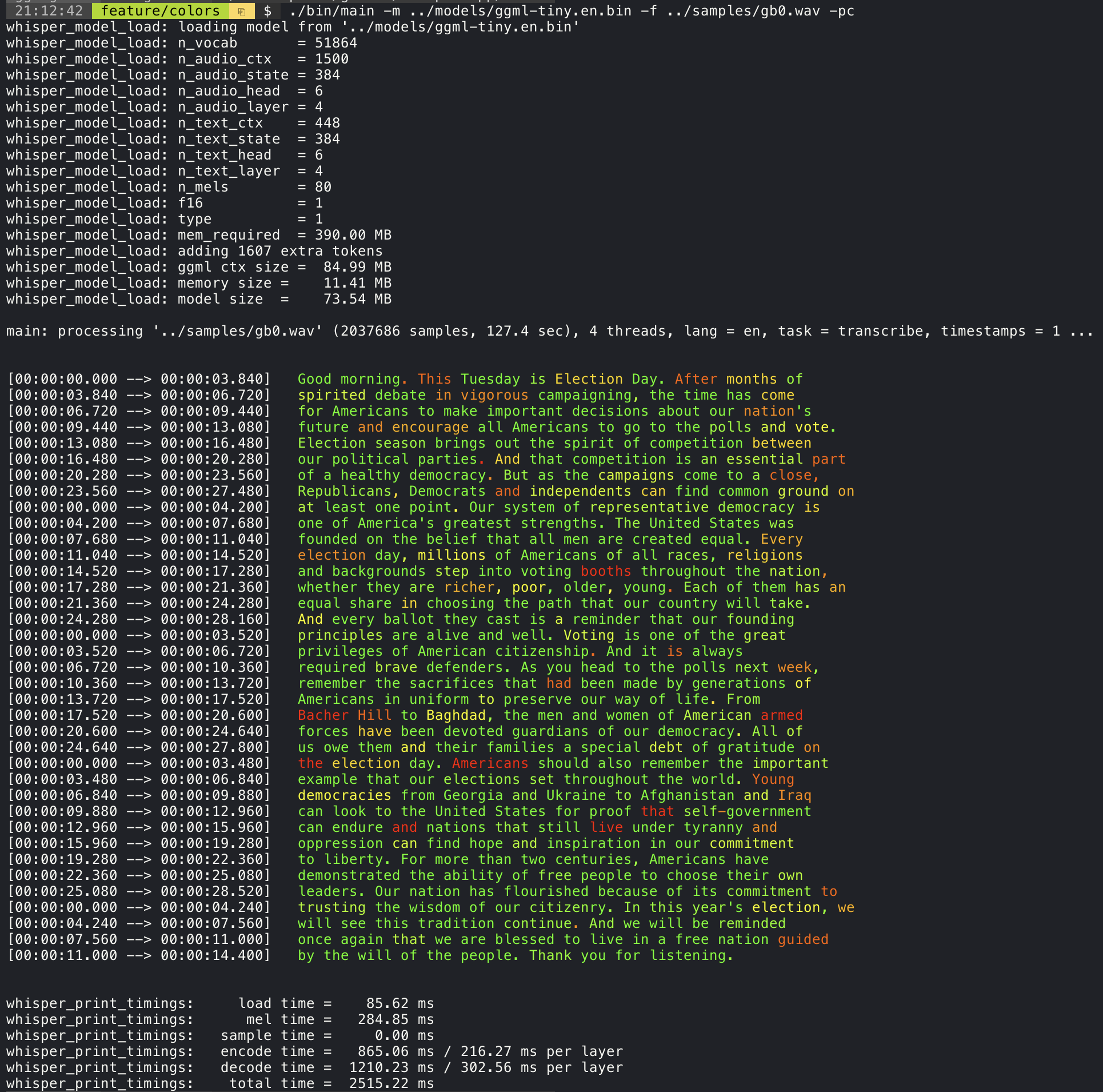
예를 들어, 라인 길이를 최대 16 자로 제한하려면 -ml 16 추가하십시오.
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.850] And so my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:04.140] Americans, ask
[00:00:04.140 --> 00:00:05.660] not what your
[00:00:05.660 --> 00:00:06.840] country can do
[00:00:06.840 --> 00:00:08.430] for you, ask
[00:00:08.430 --> 00:00:09.440] what you can do
[00:00:09.440 --> 00:00:10.020] for your
[00:00:10.020 --> 00:00:11.000] country.
--max-len 인수는 단어 수준 타임 스탬프를 얻는 데 사용될 수 있습니다. 단순히 -ml 1 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.320]
[00:00:00.320 --> 00:00:00.370] And
[00:00:00.370 --> 00:00:00.690] so
[00:00:00.690 --> 00:00:00.850] my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:02.850] Americans
[00:00:02.850 --> 00:00:03.300] ,
[00:00:03.300 --> 00:00:04.140] ask
[00:00:04.140 --> 00:00:04.990] not
[00:00:04.990 --> 00:00:05.410] what
[00:00:05.410 --> 00:00:05.660] your
[00:00:05.660 --> 00:00:06.260] country
[00:00:06.260 --> 00:00:06.600] can
[00:00:06.600 --> 00:00:06.840] do
[00:00:06.840 --> 00:00:07.010] for
[00:00:07.010 --> 00:00:08.170] you
[00:00:08.170 --> 00:00:08.190] ,
[00:00:08.190 --> 00:00:08.430] ask
[00:00:08.430 --> 00:00:08.910] what
[00:00:08.910 --> 00:00:09.040] you
[00:00:09.040 --> 00:00:09.320] can
[00:00:09.320 --> 00:00:09.440] do
[00:00:09.440 --> 00:00:09.760] for
[00:00:09.760 --> 00:00:10.020] your
[00:00:10.020 --> 00:00:10.510] country
[00:00:10.510 --> 00:00:11.000] .
이 접근법에 대한 자세한 내용은 다음을 참조하십시오 : #1058
샘플 사용 :
# download a tinydiarize compatible model
. / models / download - ggml - model . sh small . en - tdrz
# run as usual, adding the "-tdrz" command-line argument
. / main - f . / samples / a13 . wav - m . / models / ggml - small . en - tdrz . bin - tdrz
...
main : processing './samples/a13.wav' ( 480000 samples , 30.0 sec ), 4 threads , 1 processors , lang = en , task = transcribe , tdrz = 1 , timestamps = 1 ...
...
[ 00 : 00 : 00.000 - - > 00 : 00 : 03.800 ] Okay Houston , we ' ve had a problem here . [ SPEAKER_TURN ]
[ 00 : 00 : 03.800 - - > 00 : 00 : 06.200 ] This is Houston . Say again please . [ SPEAKER_TURN ]
[ 00 : 00 : 06.200 - - > 00 : 00 : 08.260 ] Uh Houston we ' ve had a problem .
[ 00 : 00 : 08.260 - - > 00 : 00 : 11.320 ] We ' ve had a main beam up on a volt . [ SPEAKER_TURN ]
[ 00 : 00 : 11.320 - - > 00 : 00 : 13.820 ] Roger main beam interval . [ SPEAKER_TURN ]
[ 00 : 00 : 13.820 - - > 00 : 00 : 15.100 ] Uh uh [ SPEAKER_TURN ]
[ 00 : 00 : 15.100 - - > 00 : 00 : 18.020 ] So okay stand , by thirteen we ' re looking at it . [ SPEAKER_TURN ]
[ 00 : 00 : 18.020 - - > 00 : 00 : 25.740 ] Okay uh right now uh Houston the uh voltage is uh is looking good um .
[ 00 : 00 : 27.620 - - > 00 : 00 : 29.940 ] And we had a a pretty large bank or so . 주요 예는 현재 발음 된 단어가 강조된 가라오케 스타일 영화의 출력을 지원합니다. -wts 인수를 사용하고 생성 된 배쉬 스크립트를 실행하십시오. ffmpeg 설치해야합니다.
다음은 몇 가지 "일반적인" 예입니다.
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
source ./samples/mm0.wav.wts
ffplay ./samples/mm0.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
source ./samples/gb0.wav.wts
ffplay ./samples/gb0.wav.mp4Scripts/Bench-Wts.sh 스크립트를 사용하여 다음 형식으로 비디오를 생성하십시오.
./scripts/bench-wts.sh samples/jfk.wav
ffplay ./samples/jfk.wav.all.mp4다른 시스템 구성에서 추론의 성능을 객관적으로 비교하려면 벤치 도구를 사용하십시오. 이 도구는 단순히 모델의 인코더 부분을 실행하고 실행하는 데 얼마나 많은 시간이 걸렸는지 인쇄합니다. 결과는 다음 Github 문제에 요약되어 있습니다.
벤치 마크 결과
또한 다른 모델과 오디오 파일로 whisper.cpp를 실행하는 스크립트에 벤치 .py가 제공됩니다.
다음 명령으로 실행할 수 있습니다. 기본적으로 모델 폴더의 모든 표준 모델에 대해 실행됩니다.
python3 scripts/bench.py -f samples/jfk.wav -t 2,4,8 -p 1,2벤치마킹 사용 사례를 쉽게 수정하고 확장 할 의도로 파이썬으로 작성되었습니다.
벤치마킹 결과와 함께 CSV 파일을 출력합니다.
ggml 형식원래 모델은 사용자 정의 이진 형식으로 변환됩니다. 이를 통해 필요한 모든 것을 단일 파일로 포장 할 수 있습니다.
모델/다운로드 -ggml-model.sh 스크립트를 사용하여 변환 된 모델을 다운로드하거나 여기에서 수동으로 다운로드 할 수 있습니다.
자세한 내용은 변환 스크립트 모델/convert-pt-to-ggml.py 또는 models/readme.md를 참조하십시오.
예제 폴더에서 다른 프로젝트에 라이브러리를 사용하는 다양한 예가 있습니다. 예제 중 일부는 WebAssembly를 사용하여 브라우저에서 실행되도록 포팅됩니다. 확인하십시오!
| 예 | 편물 | 설명 |
|---|---|---|
| 기본 | Whisper.wasm | Whisper를 사용하여 오디오를 번역하고 전사하는 도구 |
| 벤치 | Bench.wasm | 컴퓨터에서 Whisper의 성능을 벤치마킹하십시오 |
| 개울 | 스트림 .wasm | 원시 마이크 캡처의 실시간 전사 |
| 명령 | 명령 .wasm | 마이크에서 음성 명령을 받기위한 기본 음성 어시스턴트 예제 |
| wchess | wchess.wasm | 음성 제어 체스 |
| 말하다 | talk.wasm | GPT-2 봇과 대화하십시오 |
| 토크 롤라 | 라마 봇과 이야기하십시오 | |
| Whisper.objc | Whisper.cpp를 사용한 iOS 모바일 애플리케이션 | |
| Whisper.swiftui | Whisper.cpp를 사용한 Swiftui iOS / MacOS 응용 프로그램 | |
| whisper.android | Whisper.cpp를 사용한 Android 모바일 애플리케이션 | |
| Whisper.nvim | Neovim의 음성 텍스트 플러그인 | |
| 생성 -KARAOKE.SH | 원시 오디오 캡처의 노래방 비디오를 쉽게 생성하기위한 도우미 스크립트 | |
| livestream.sh | 라이브 스트림 오디오 전사 | |
| yt-wsp.sh | 다운로드 + 전사 및/또는 VOD (원본) 번역 | |
| 섬기는 사람 | OAI- 유사 API가있는 HTTP 전사 서버 |
이 프로젝트에 대한 피드백이 있으면 토론 섹션을 사용하고 새로운 주제를 열어주십시오. 쇼를 사용하고 카테고리를 알리면 whisper.cpp 사용하는 자신의 프로젝트를 공유 할 수 있습니다. 질문이 있으시면 자주 묻는 질문 (#126) 토론을 확인하십시오.


