이 저장소는 Pytorch에서 구현되고 MNIST 데이터 세트에서 훈련 된 VQ-VAE로 구성됩니다.
VQ-VAE는 변형 자동 인코더 (VAE) 뒤에 동일한 기본 개념을 따릅니다. VQ-VAE 변형 자동 인코더에 개별 잠재 임베딩을 사용합니다. 즉, Z (잠재 벡터)의 각 차원은 입력을 인코딩하는 동안 일반적으로 사용되는 연속 정규 분포 대신 개별 정수입니다.
VAE는 3 개의 부분으로 구성됩니다.
글쎄, 당신은 vq-vaes가 테이블에 가져 오는 차이점에 대해 물을 수 있습니다. 나열하자 :
많은 중요한 실제 객체가 이산적입니다. 예를 들어 이미지에서는 "고양이", "자동차"등과 같은 카테고리가있을 수 있으며 이러한 범주간에 보간하는 것은 의미가 없을 수 있습니다. 개별 표현도 모델링하기가 더 쉽습니다.
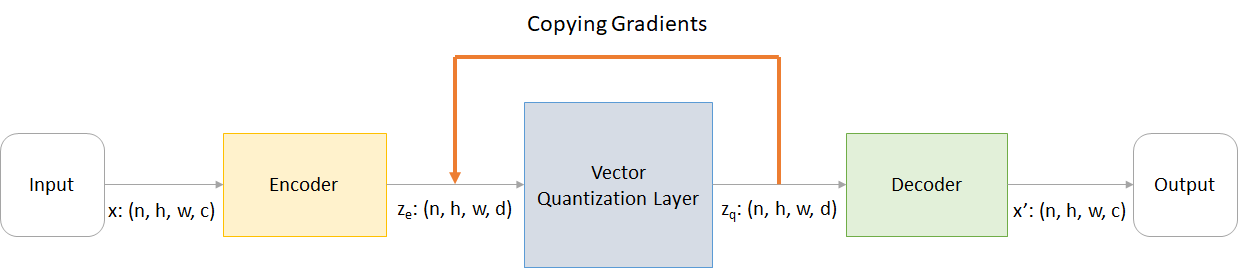
어디:
n : 배치 크기h : 이미지 높이w : 이미지 너비c : 입력 이미지의 채널 수d : 숨겨진 상태의 채널 수 VQ-VAE 네트워크의 작동에 대한 간단한 개요는 다음과 같습니다.
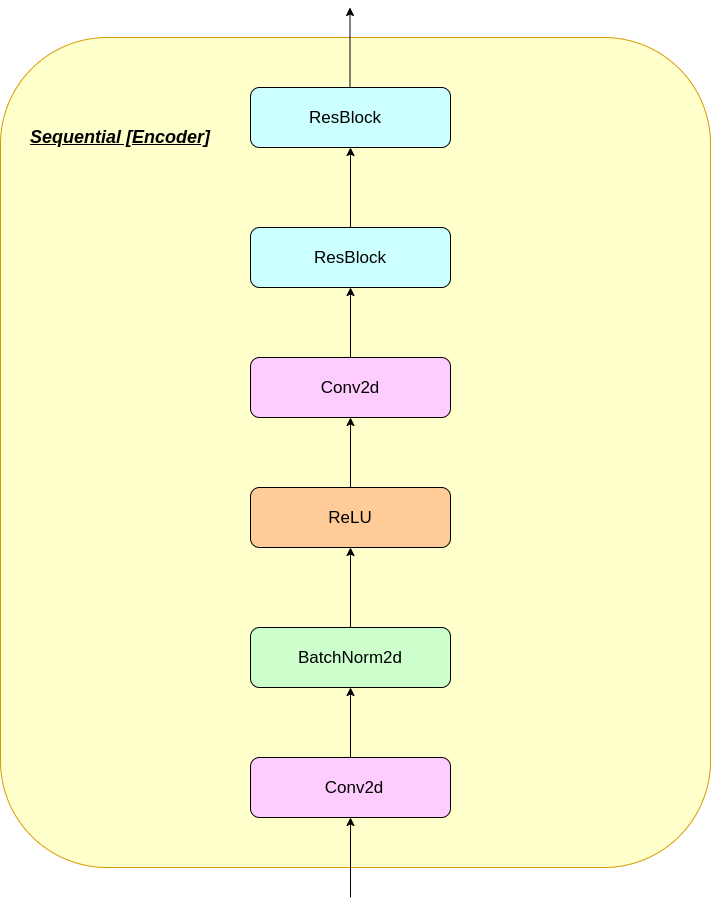
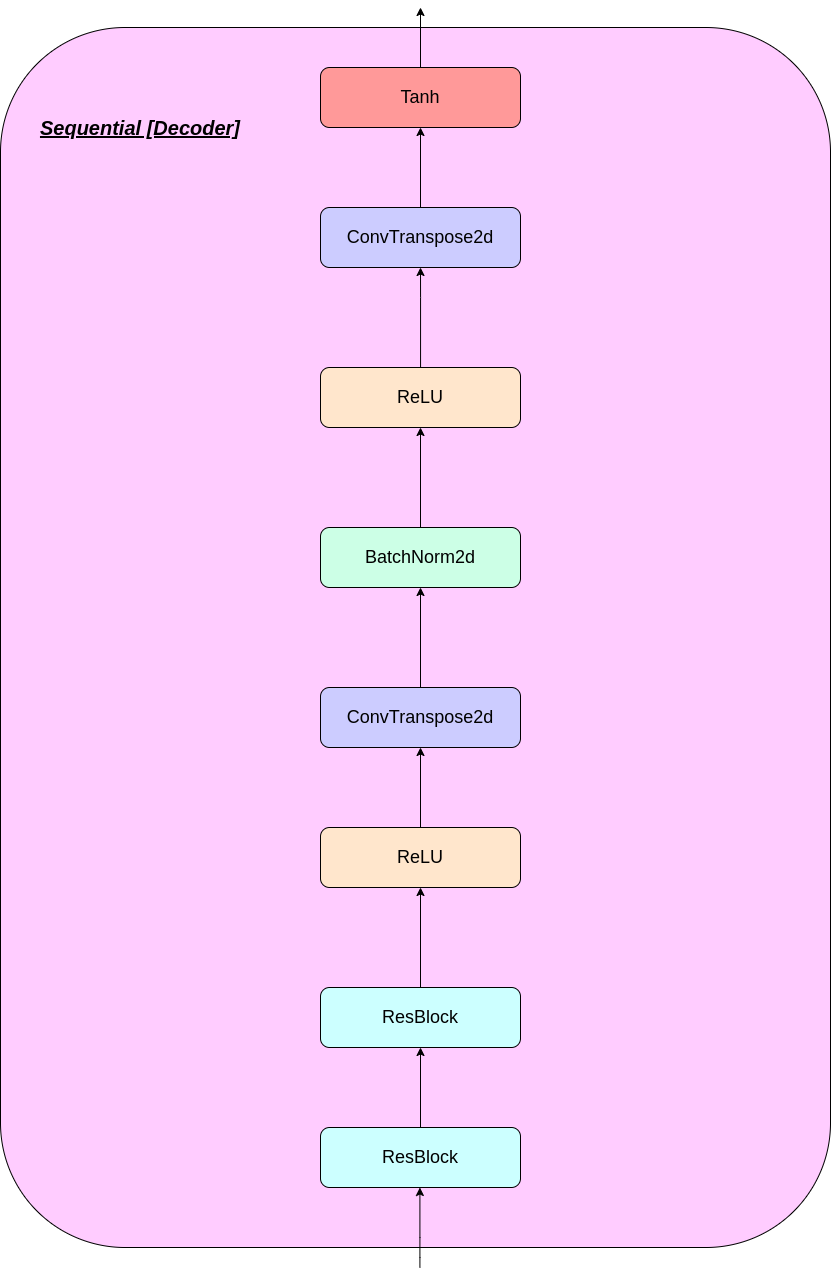
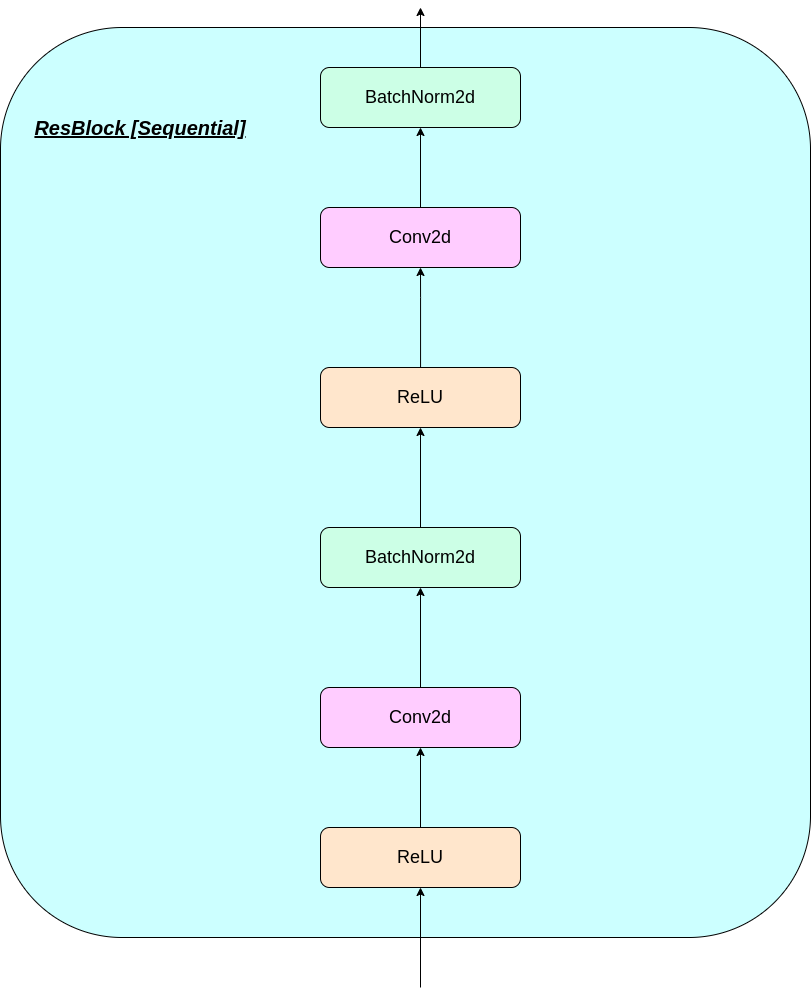
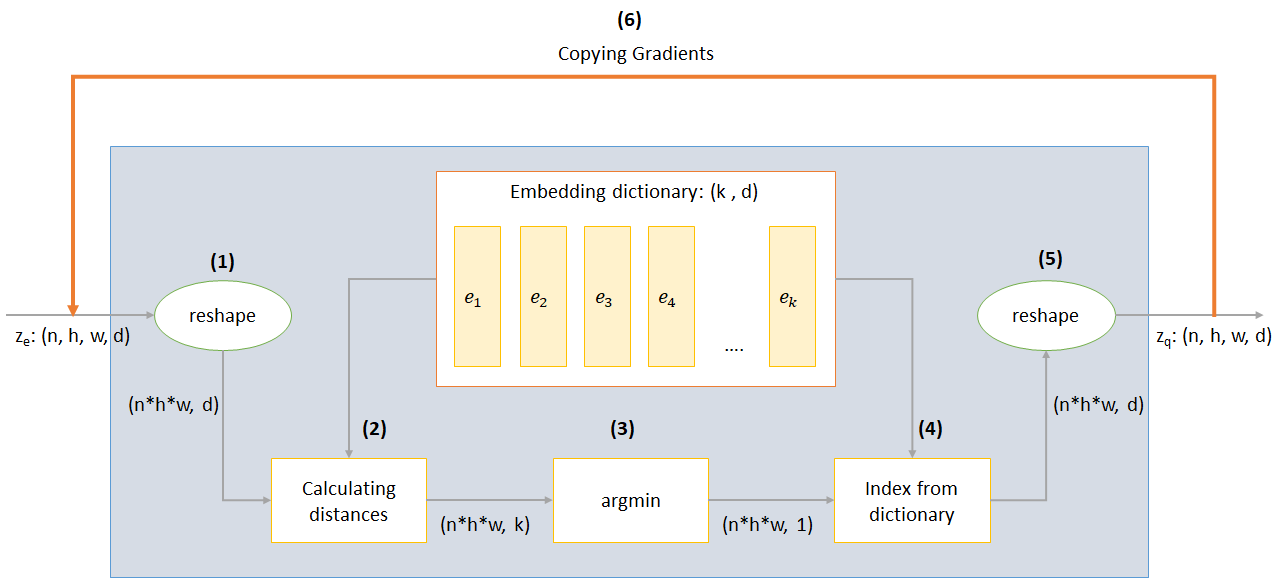
VQ 층의 작동은 그림에서 번호가 매겨진 6 단계로 설명 될 수 있습니다.
VQ-VAE는 3 가지 손실을 사용하여 훈련 중 총 손실을 계산합니다.
재구성 손실 : 디코더와 인코더를 VAE로 최적화합니다. 즉, 입력 이미지와 재구성의 차이.
reconstruction_loss = -log( p(x|z_q) )
코드북 손실 : 그라디언트가 임베딩을 우회한다는 사실로 인해 L2 오류를 사용하여 임베딩 벡터 E_I를 인코더 출력으로 이동시키는 사전 학습 알고리즘이 사용됩니다.
codebook_loss = ‖ sg[z_e(x)]− e ‖^2
(SG는 정지 그라디언트 연산자를 나타냅니다.
약속 손실 : 임베딩 공간의 양은 치수가 없기 때문에, 임베딩 E_I가 인코더 매개 변수만큼 빨리 훈련하지 않으면 임의로 성장할 수 있으므로 인코더가 내장을 저지르는 것을 확인하기 위해 약정 손실이 추가됩니다.
commitment_loss = β‖ z_e(x)− sg[e] ‖^2
(β는 다른 구성 요소에 비해 약정 손실을 얼마나 평가하려는 의지를 제어하는과 파라미터입니다)
CMD 프롬프트에서 다음을 실행하여 레포를 다운로드하거나 복제 할 수 있습니다.
https://github.com/praeclarumjj3/VQ-VAE-on-MNIST.git
다음 명령 (Google Colab)으로 모델을 처음부터 교육 할 수 있습니다.
! python3 VQ-VAE.py --output-folder [NAME_OF_OUTPUT_FOLDER] --data-folder [PATH_TO_MNIST_dataset] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --batch-size [BATCH_SIZE] --num_epoch [NUMBER_OF_EPOCHS] --lr [LEARNING_RATE] --beta [VALUE] --num-workers [NUMBER_OF_WORKERS]
output-folder - 데이터 폴더의 이름data-folder 데이터 폴더의 이름device - 장치 설정 (CPU 또는 CUDA, 기본값 : CPU)hidden-size - 잠재 벡터의 크기 (기본값 : 40)k 잠재적 벡터 수 (기본값 : 512)batch-size - 배치 크기 (기본값 : 128)num-epochs 에포크 수 (기본값 : 10)lr Adam Optimizer의 학습 속도 (기본값 : 2E -4)beta - 0.1에서 2.0 사이의 약정 손실 기여 (기본값 : 1.0)num-workers 궤적 샘플링을위한 근로자 수 (기본값 : CPU_COUNT () -1) 이 프로그램은 MNIST 데이터 세트를 자동으로 다운로드하여 PATH_TO_MNIST_dataset 폴더에 저장합니다 (이 폴더를 작성해야 함). 이것은 한 번만 발생합니다.
또한 logs 폴더 및 models 폴더를 생성하고 그 안에는 각각 로그와 모델 체크 포인트를 저장하기 위해 이름을 전달한 폴더를 만듭니다.
가우시안에서 무작위로 샘플링 된 z에서 새로운 이미지를 생성하려면 다음 명령을 실행합니다 (Google Colab).
! python3 generate.py --model [SAVED_MODEL_FILENAME] --input [MNIST_or_random] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --filename [SAVING_NAME]
model - 모델이 포함 된 파일 이름input - mnist 또는 랜덤device - 장치 설정 (CPU 또는 CUDA, 기본값 : CPU)hidden-size - 잠재 벡터의 크기 (기본값 : 40)k 잠재적 벡터 수 (기본값 : 512)filename 저장할 파일이있는 이름 generatedImages 라는 폴더에 저장된 10*10 그리드의 이미지를 생성합니다.
model.txt 의 링크에서 다운로드하여 미리 훈련 된 모델을 사용할 수 있습니다.
저장소에는 다음 파일이 포함되어 있습니다
modules.py 모델 제작에 사용되는 다양한 모듈이 포함되어 있습니다.VQ-VAE.py vq-vae 모델을 훈련하기위한 기능과 코드가 포함되어 있습니다.vector_quantizer.py 벡터 양자화 클래스는이 파일에 정의되어 있습니다.generate-py 미리 훈련 된 모델에서 새 이미지를 생성합니다model.txt 미리 훈련 된 모델에 대한 링크가 포함되어 있습니다README.md repo의 개요를 제공합니다references.txt 이 repo를 작성하는 동안 사용 된 참조readme_images readme에 대한 다양한 이미지가 있습니다MNIST ZIPPENT MNIST 데이터 세트가 포함되어 있습니다 (필요한 경우 자동으로 다운로드됩니다).Training track for VQ-VAE.txt -VQ-VAE 모델 교육 중 손실 값이 포함되어 있습니다.logs_VQ-VAE vq-vae 모델의 Zipple Tensorboard 로그가 포함되어 있습니다 (프로그램에서 자동으로 생성)testers.py 정의 된 모듈을 테스트하는 몇 가지 기능이 포함되어 있습니다.Tensorboard (Google Colab) 실행 명령 :
%load_ext tensorboard
%tensordboard --logdir [path_to_folder_with_logs]
훈련 이미지
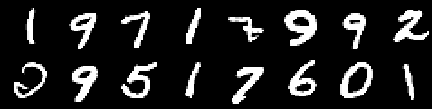
0th Epoch의 이미지

두 번째 시대의 이미지
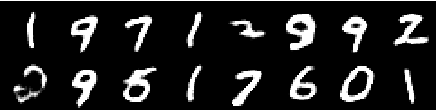
4 번째 에포크의 이미지
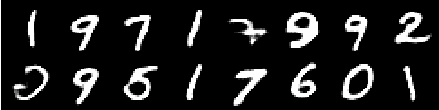
6 번째 에포크의 이미지
8 번째 에포크의 이미지
10th Epoch의 이미지
재구성은 계속 개선되며 마지막에는 손실 값에 반영된 Training_Set 이미지와 거의 비슷합니다 ( Training track for VQ-VAE.txt 확인).
재건 손실
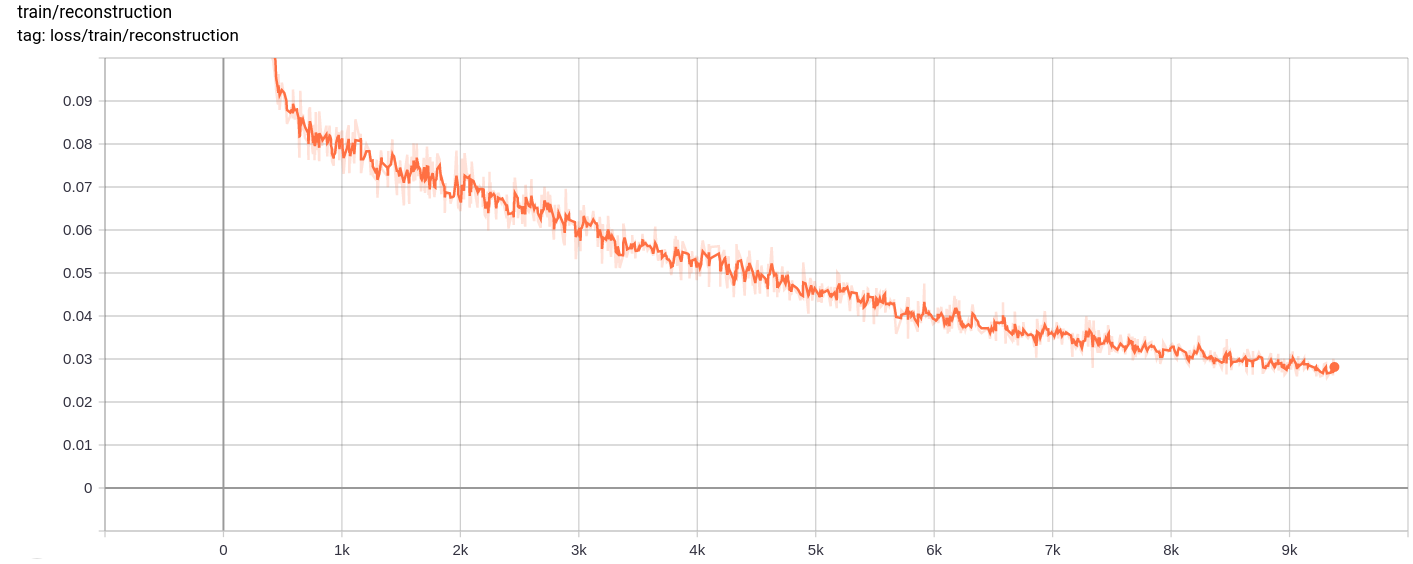
양자화 손실
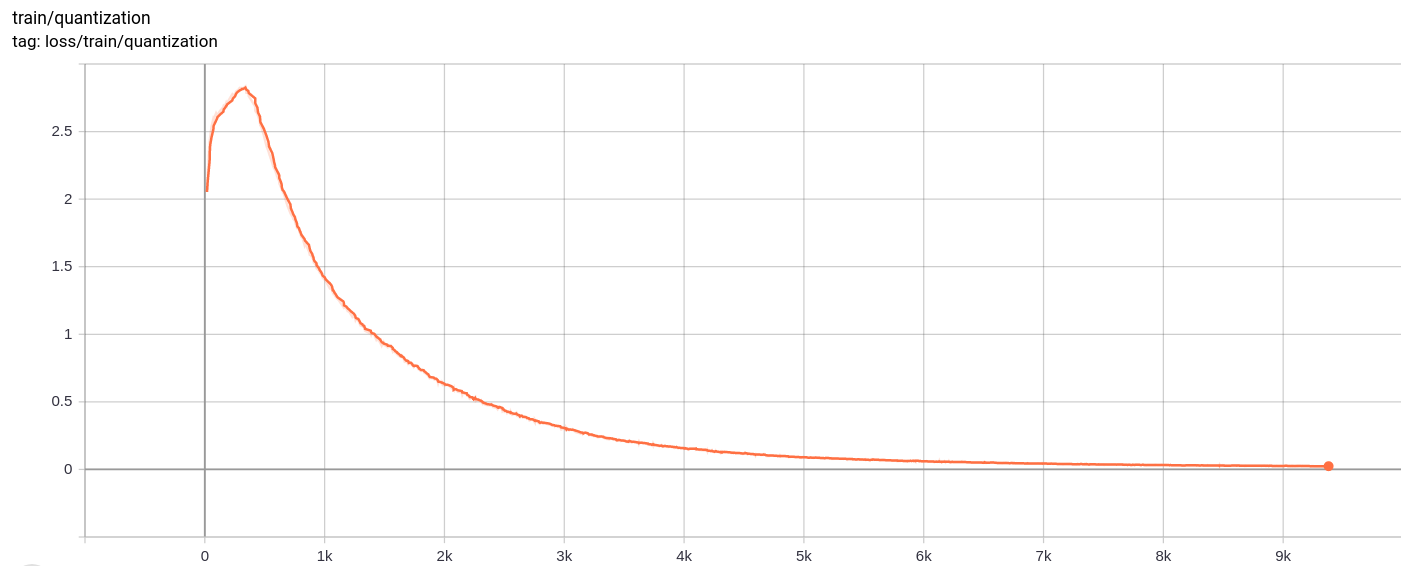
Total_loss
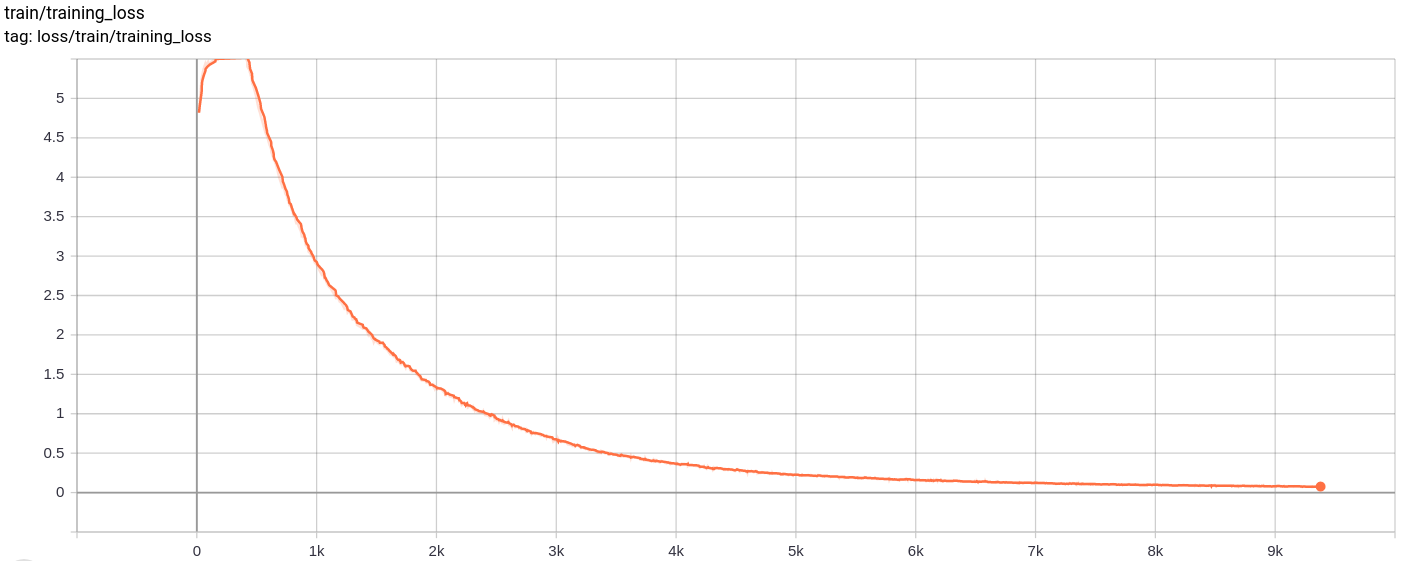
총 손실, 재건 손실 및 양자화 손실은 예상대로 균일하게 감소합니다.
testing_loss
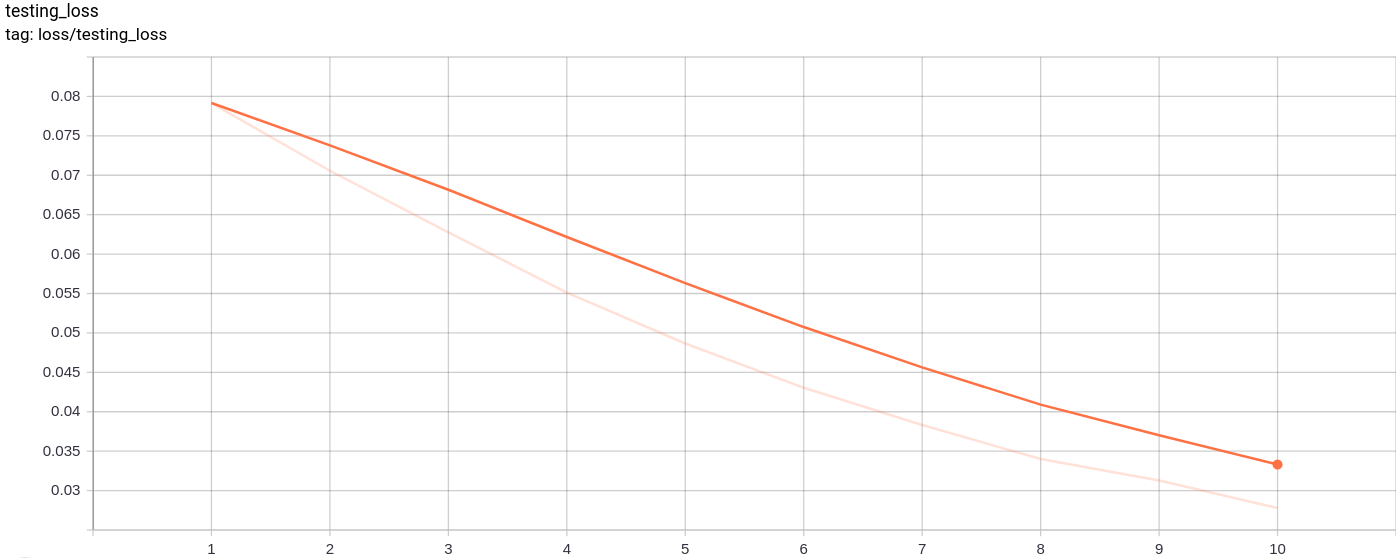
테스트 손실은 예상대로 균일하게 감소합니다.
MNIST 이미지를 입력으로 전달한 후 다음 이미지 그리드가 생성되었습니다.

세대는 꽤 좋습니다.
다음 이미지 그리드는 가우시안에서 모델에 대한 입력으로 무작위로 샘플링 된 AZ를 통과 한 후 디코더를 통과 한 후 생성되었습니다.


이미지는 완벽 해 보이지 않습니다. 잠재적 인 공간의 치수, 삽입 벡터 수 등을 조정하면 더 나은 임의의 이미지를 생성하는 데 도움이 될 수 있습니다.
이 모델은 Google Colab에서 10 개의 에포크에 대한 교육을 받았으며 배치 크기는 128입니다.
훈련 후 모델은 입력 이미지를 아주 잘 재구성 할 수 있었으며 생성 된 이미지가 좋지 않지만 새로운 이미지를 생성 할 수있었습니다.
시험 손실뿐만 아니라 훈련도 거의 단조로 감소했습니다.
나는 10-20 개가 넘는 에포크에 대한 모델을 훈련시키는 것이 모델에서 과적으로 적합 할 가능성이있는 징후를 제안하는 결과를 생성한다는 것을 관찰했다. 또한, 나는 latnt 공간의 다른 치수를 실험했고 최종 dimension = 40 에서 최상의 결과를 얻었습니다. 치수의 가장 좋은 범위는 16-42 사이입니다.
다음 출처는이 저장소를 만드는 데 많은 도움이되었습니다.


