flash attention
v2.7.0
이 저장소는 다음 논문에서 FlashAttention 및 FlashAttention-2의 공식 구현을 제공합니다.
FlashAttention : IO 인식에 대한 빠르고 메모리 효율적인 정확한주의
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré
종이 : https://arxiv.org/abs/2205.14135
IEEE Spectrum FlashAttention을 사용한 MLPERF 2.0 벤치 마크에 대한 제출에 관한 기사. 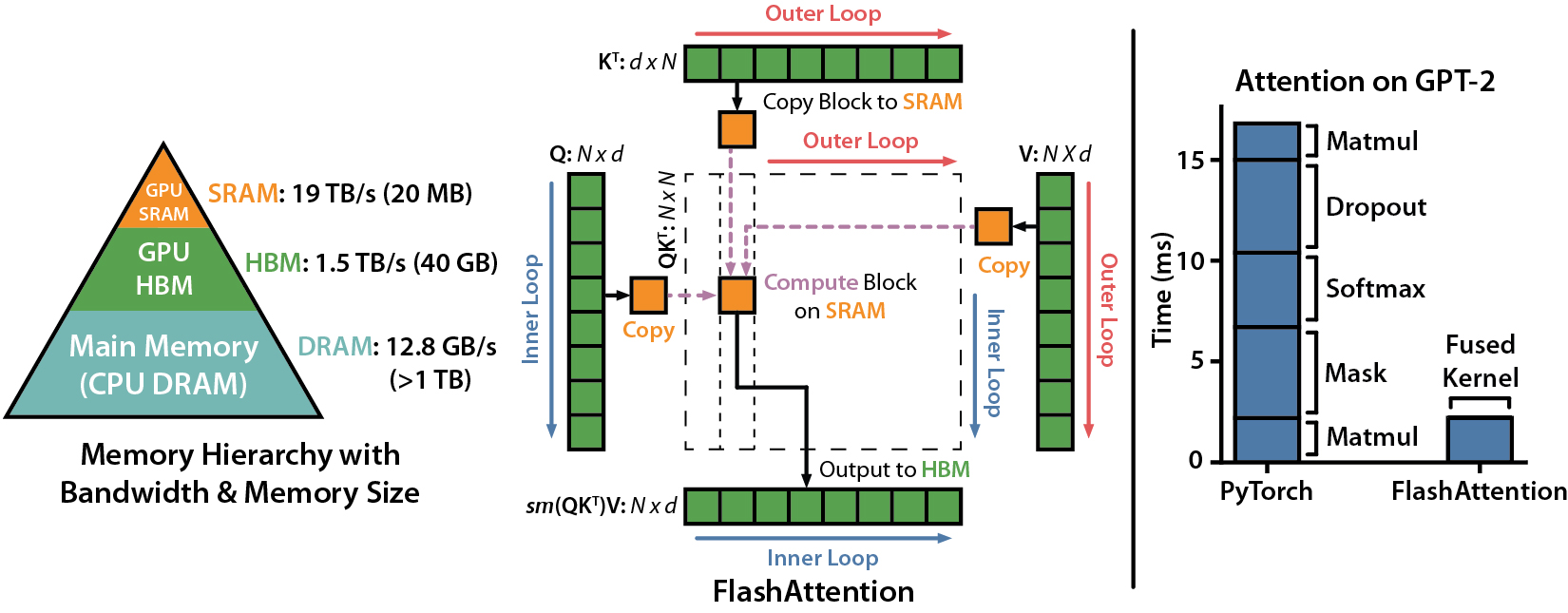
FlashAttention-2 : 더 나은 병렬 처리와 작업 파티셔닝으로 더 빠른 관심
tri dao
종이 : https://tridao.me/publications/flash2/flash2.pdf

우리는 출시 후 짧은 시간에 FlashAttention이 널리 채택되는 것을 보게되어 매우 기뻤습니다. 이 페이지에는 FlashAttention이 사용되는 장소의 일부 목록이 포함되어 있습니다.
FlashAttention 및 FlashAttention-2는 자유롭게 사용하고 수정할 수 있습니다 (라이센스 참조). 사용하면 인용하고 신용을 인용하십시오.
FlashAttention-3은 호퍼 GPU (예 : H100)에 최적화되었습니다.
블로그 포스트 : https://tridao.me/blog/2024/flash3/
종이 : https://tridao.me/publications/flash3/flash3.pdf
이를 테스트 / 벤치마킹을위한 베타 릴리스입니다.
현재 출시 :
요구 사항 : H100 / H800 GPU, CUDA> = 12.3.
현재 최상의 성능을 위해 CUDA 12.3을 적극 권장합니다.
설치하려면 :
cd hopper
python setup.py install테스트를 실행하려면 :
export PYTHONPATH= $PWD
pytest -q -s test_flash_attn.py요구 사항 :
packaging 파이썬 패키지 ( pip install packaging )ninja 파이썬 패키지 ( pip install ninja ) * * ninja 가 설치되고 올바르게 작동하는지 확인하십시오 (예 : ninja --version echo $? exit 코드 0을 반환해야 함). 그렇지 않은 경우 (때때로 ninja --version echo $? 가 0이 아닌 출구 코드를 반환합니다), ninja 를 다시 설치 한 다음 닌자를 다시 설치하십시오 ( pip uninstall -y ninja && pip install ninja ). ninja 없으면 컴파일은 여러 CPU 코어를 사용하지 않기 때문에 매우 오랜 시간이 걸릴 수 있습니다 (2H). ninja 컴파일을 사용하면 CUDA 툴킷을 사용하여 64 코어 기계에서 3-5 분이 걸립니다.
설치하려면 :
pip install flash-attn --no-build-isolation또는 소스에서 컴파일 할 수 있습니다.
python setup.py install 기계에 96GB 미만의 RAM이 있고 CPU 코어가 많으면 ninja RAM의 양을 소진 할 수있는 병렬 컴파일 작업을 너무 많이 실행할 수 있습니다. 병렬 컴파일 작업의 수를 제한하려면 환경 변수 MAX_JOBS 설정할 수 있습니다.
MAX_JOBS=4 pip install flash-attn --no-build-isolation 인터페이스 : src/flash_attention_interface.py
요구 사항 :
NVIDIA의 Pytorch 컨테이너를 권장하는 것이 좋습니다. NVIDIA는 FlashAttention을 설치하는 데 필요한 모든 도구가 있습니다.
CUDA의 FlashAttention-2는 현재 지원합니다.
ROCM 버전은 composable_kernel을 백엔드로 사용합니다. FlashAttention-2의 구현을 제공합니다.
요구 사항 :
ROCM의 Pytorch 컨테이너는 FlashAttention을 설치하는 데 필요한 모든 도구가 있습니다.
ROCM의 FlashAttention-2는 현재 지원합니다.
주요 기능은 스케일링 된 도트 제품주의를 구현합니다 (SoftMax (q @ k^t * softmax_scale) @ v) :
from flash_attn import flash_attn_qkvpacked_func , flash_attn_func flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
If Q, K, V are already stacked into 1 tensor, this function will be faster than
calling flash_attn_func on Q, K, V since the backward pass avoids explicit concatenation
of the gradients of Q, K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between [i - window_size[0], i + window_size[1]] inclusive.
Arguments:
qkv: (batch_size, seqlen, 3, nheads, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of (-alibi_slope * |i - j|) is added to
the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k: (batch_size, seqlen, nheads_k, headdim)
v: (batch_size, seqlen, nheads_k, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" def flash_attn_with_kvcache (
q ,
k_cache ,
v_cache ,
k = None ,
v = None ,
rotary_cos = None ,
rotary_sin = None ,
cache_seqlens : Optional [ Union [( int , torch . Tensor )]] = None ,
cache_batch_idx : Optional [ torch . Tensor ] = None ,
block_table : Optional [ torch . Tensor ] = None ,
softmax_scale = None ,
causal = False ,
window_size = ( - 1 , - 1 ), # -1 means infinite context window
rotary_interleaved = True ,
alibi_slopes = None ,
):
"""
If k and v are not None, k_cache and v_cache will be updated *inplace* with the new values from
k and v. This is useful for incremental decoding: you can pass in the cached keys/values from
the previous step, and update them with the new keys/values from the current step, and do
attention with the updated cache, all in 1 kernel.
If you pass in k / v, you must make sure that the cache is large enough to hold the new values.
For example, the KV cache could be pre-allocated with the max sequence length, and you can use
cache_seqlens to keep track of the current sequence lengths of each sequence in the batch.
Also apply rotary embedding if rotary_cos and rotary_sin are passed in. The key @k will be
rotated by rotary_cos and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If causal or local (i.e., window_size != (-1, -1)), the query @q will be rotated by rotary_cos
and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If not causal and not local, the query @q will be rotated by rotary_cos and rotary_sin at
indices cache_seqlens only (i.e. we consider all tokens in @q to be at position cache_seqlens).
See tests/test_flash_attn.py::test_flash_attn_kvcache for examples of how to use this function.
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
1 1 1 1 0
1 1 1 1 1
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
0 0
0 0
0 0
1 0
1 1
If the row of the mask is all zero, the output will be zero.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Note: Does not support backward pass.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
page_block_size must be a multiple of 256.
v_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
k [optional]: (batch_size, seqlen_new, nheads_k, headdim). If not None, we concatenate
k with k_cache, starting at the indices specified by cache_seqlens.
v [optional]: (batch_size, seqlen_new, nheads_k, headdim). Similar to k.
rotary_cos [optional]: (seqlen_ro, rotary_dim / 2). If not None, we apply rotary embedding
to k and q. Only applicable if k and v are passed in. rotary_dim must be divisible by 16.
rotary_sin [optional]: (seqlen_ro, rotary_dim / 2). Similar to rotary_cos.
cache_seqlens: int, or (batch_size,), dtype torch.int32. The sequence lengths of the
KV cache.
block_table [optional]: (batch_size, max_num_blocks_per_seq), dtype torch.int32.
cache_batch_idx: (batch_size,), dtype torch.int32. The indices used to index into the KV cache.
If None, we assume that the batch indices are [0, 1, 2, ..., batch_size - 1].
If the indices are not distinct, and k and v are provided, the values updated in the cache
might come from any of the duplicate indices.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
rotary_interleaved: bool. Only applicable if rotary_cos and rotary_sin are passed in.
If True, rotary embedding will combine dimensions 0 & 1, 2 & 3, etc. If False,
rotary embedding will combine dimensions 0 & rotary_dim / 2, 1 & rotary_dim / 2 + 1
(i.e. GPT-NeoX style).
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
Return:
out: (batch_size, seqlen, nheads, headdim).
"""이러한 기능이 다중 헤드주의 계층 (QKV 투영, 출력 투영 포함)에서 어떻게 사용되는지 보려면 MHA 구현을 참조하십시오.
FlashAttention (1.x)에서 FlashAttention-2로 업그레이드
이러한 기능의 이름이 바뀌 었습니다.
flash_attn_unpadded_func > flash_attn_varlen_funcflash_attn_unpadded_qkvpacked_func > flash_attn_varlen_qkvpacked_funcflash_attn_unpadded_kvpacked_func > flash_attn_varlen_kvpacked_func입력이 동일한 배치에서 동일한 시퀀스 길이를 갖는 경우 이러한 기능을 사용하는 것이 더 간단하고 빠릅니다.
flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ) flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False )seqlen_q! = seqlen_k 및 aitial = true 인 경우, 인과 마스크는 왼쪽 상단 코너 대신주의 매트릭스의 오른쪽 하단에 정렬됩니다.
예를 들어, seqlen_q = 2 및 seqlen_k = 5 인 경우 인과 마스크 (1 = 유지, 0 = 마스크 아웃)는 다음과 같습니다.
v2.0 :
1 0 0 0 0
1 1 0 0 0
v2.1 :
1 1 1 1 0
1 1 1 1 1
seqlen_q = 5 및 seqlen_k = 2 인 경우 인과 마스크는 다음과 같습니다.
v2.0 :
1 0
1 1
1 1
1 1
1 1
v2.1 :
0 0
0 0
0 0
1 0
1 1
마스크의 행이 모두 0이면 출력은 0이됩니다.
쿼리의 시퀀스 길이가 매우 작은 경우 (예 : 쿼리 시퀀스 길이 = 1) 추론 (반복 디코딩)을 최적화하십시오. 여기서 병목 현상은 KV 캐시를 최대한 빨리로드하는 것이며, 우리는 별도의 커널을 통해 다른 스레드 블록을 가로 질러 로딩을 분할하여 결과를 결합합니다.
추론을위한 더 많은 기능이있는 기능 flash_attn_with_kvcache 기능을 참조하십시오 (로터리 임베딩 수행, KV 캐시 업데이트 업데이트).
이 협업을 위해 Xformers 팀, 특히 Daniel Haziza에게 감사드립니다.
슬라이딩 윈도우주의를 구현하십시오 (즉, 로컬주의). 이 기여에 대해 Mistral AI, 특히 Timothée Lacroix에게 감사드립니다. 슬라이딩 윈도우는 Mistral 7B 모델에 사용되었습니다.
Alibi를 구현하십시오 (Press et al., 2021). 이 기여에 대해 Kakao Brain의 Sanghun Cho에게 감사드립니다.
결정 론적 후진 패스를 구현하십시오. 이 기여에 대해 Meituan의 엔지니어들에게 감사합니다.
PAGED KV 캐시를 지원합니다 (즉, PageDattention). 이 기여에 대한 @Beginlner에게 감사드립니다.
Gemma-2 및 Grok 모델에 사용되는 Softcapping의주의를 지원합니다. 이 기여에 대한 @narsil 및 @lucidrains에게 감사드립니다.
이 기여에 대해 @ani300에 감사드립니다.
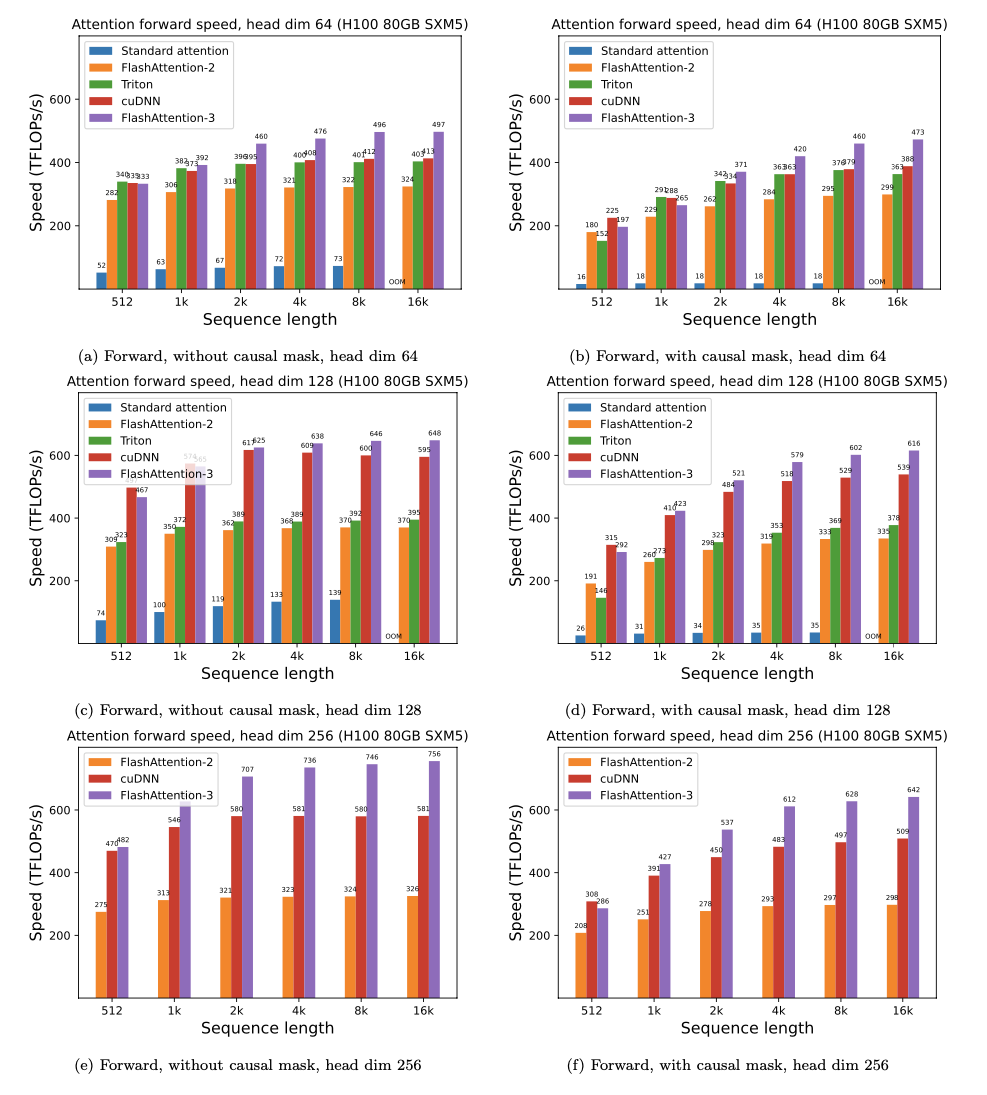
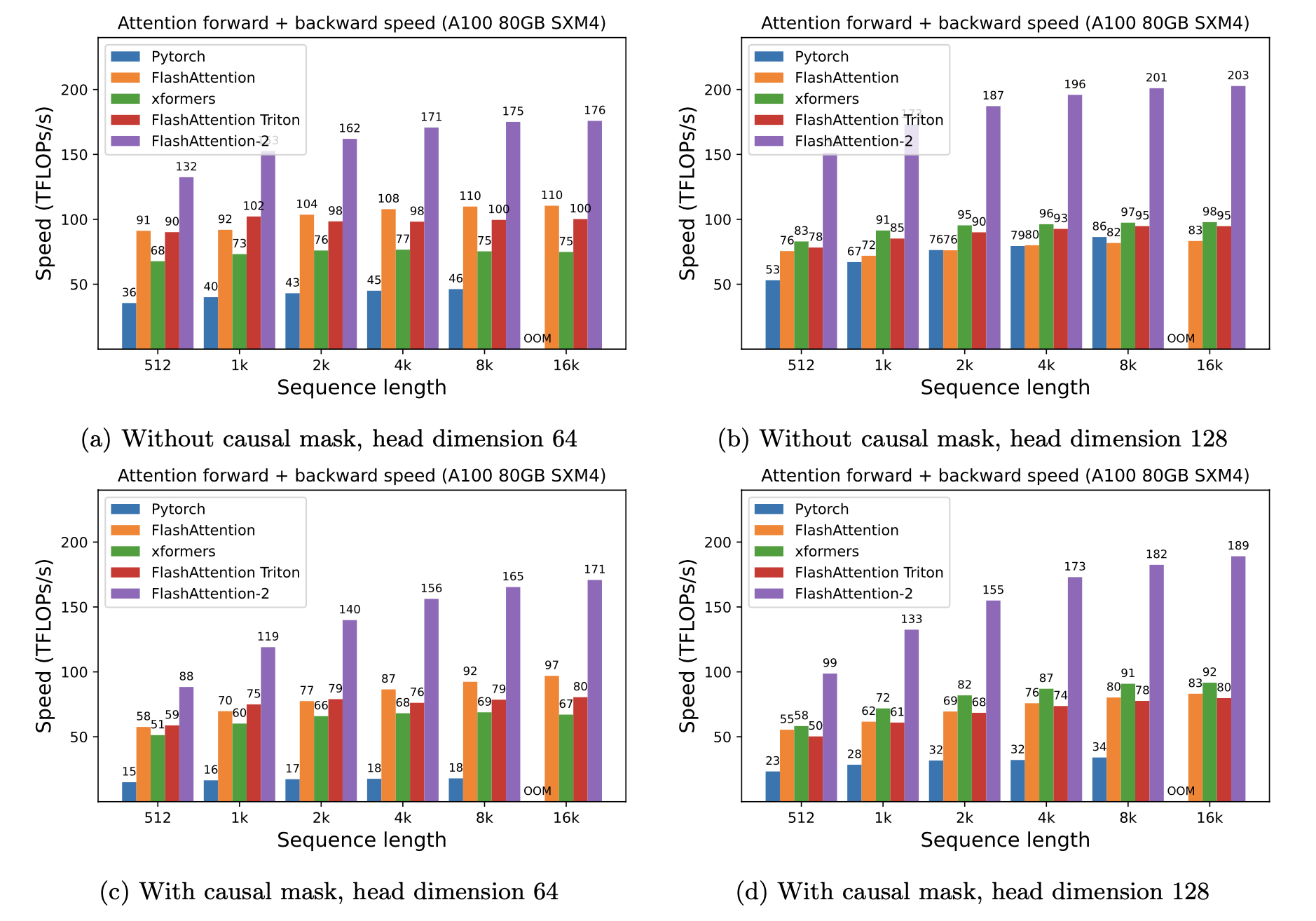
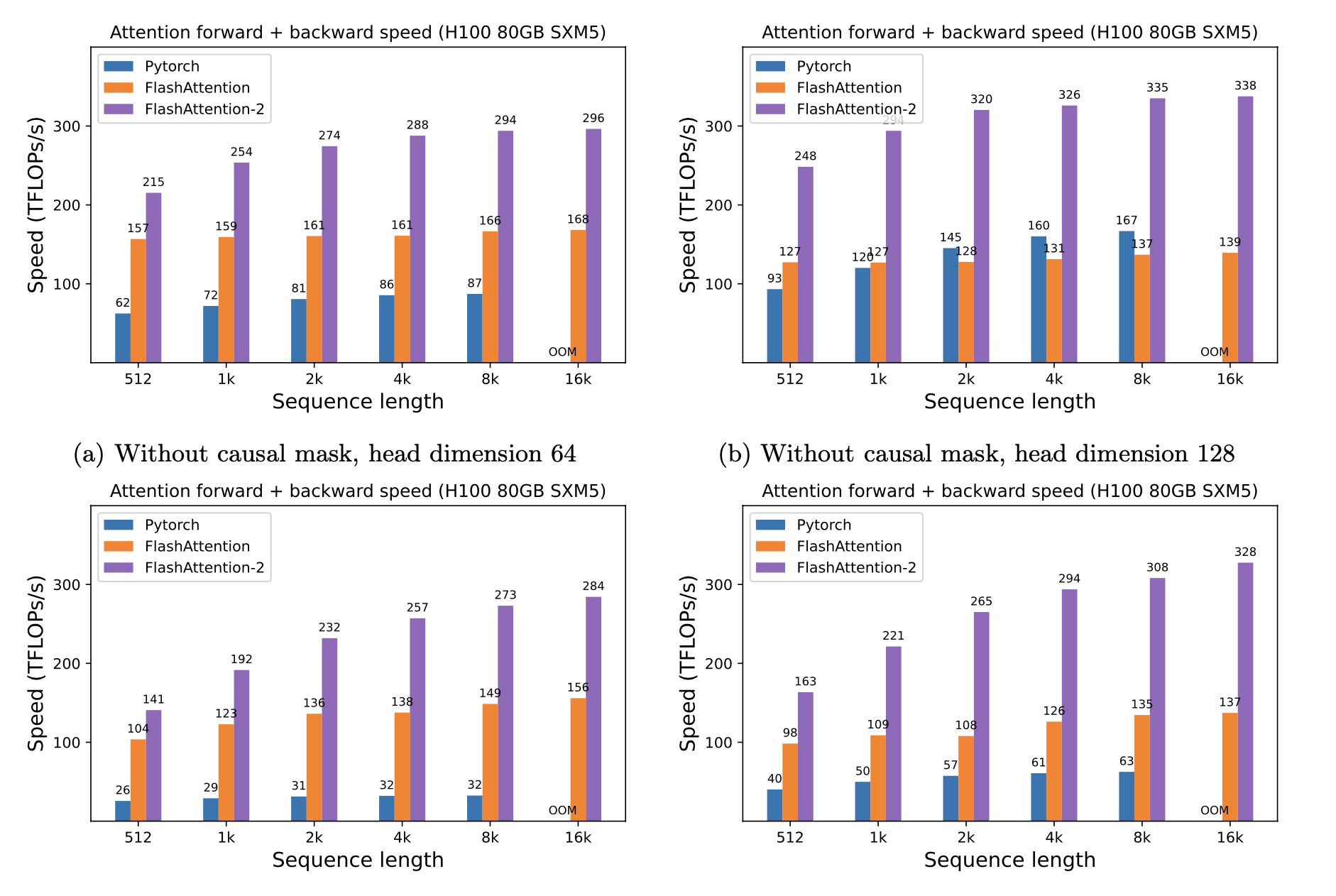
우리는 시퀀스 길이에 따라 다른 GPU에 따라 Pytorch 표준주의에 대한 FlashAttention을 사용하여 예상 속도 업 (결합 + 뒤로 패스) 및 메모리 절약을 제시합니다 (속도는 메모리 대역폭에 따라 다릅니다. 우리는 GPU 메모리의 느린 속도가 더 느려집니다).
현재이 GPU에 대한 벤치 마크가 있습니다.
이러한 매개 변수를 사용하여 FlashAttention 속도를 표시합니다.
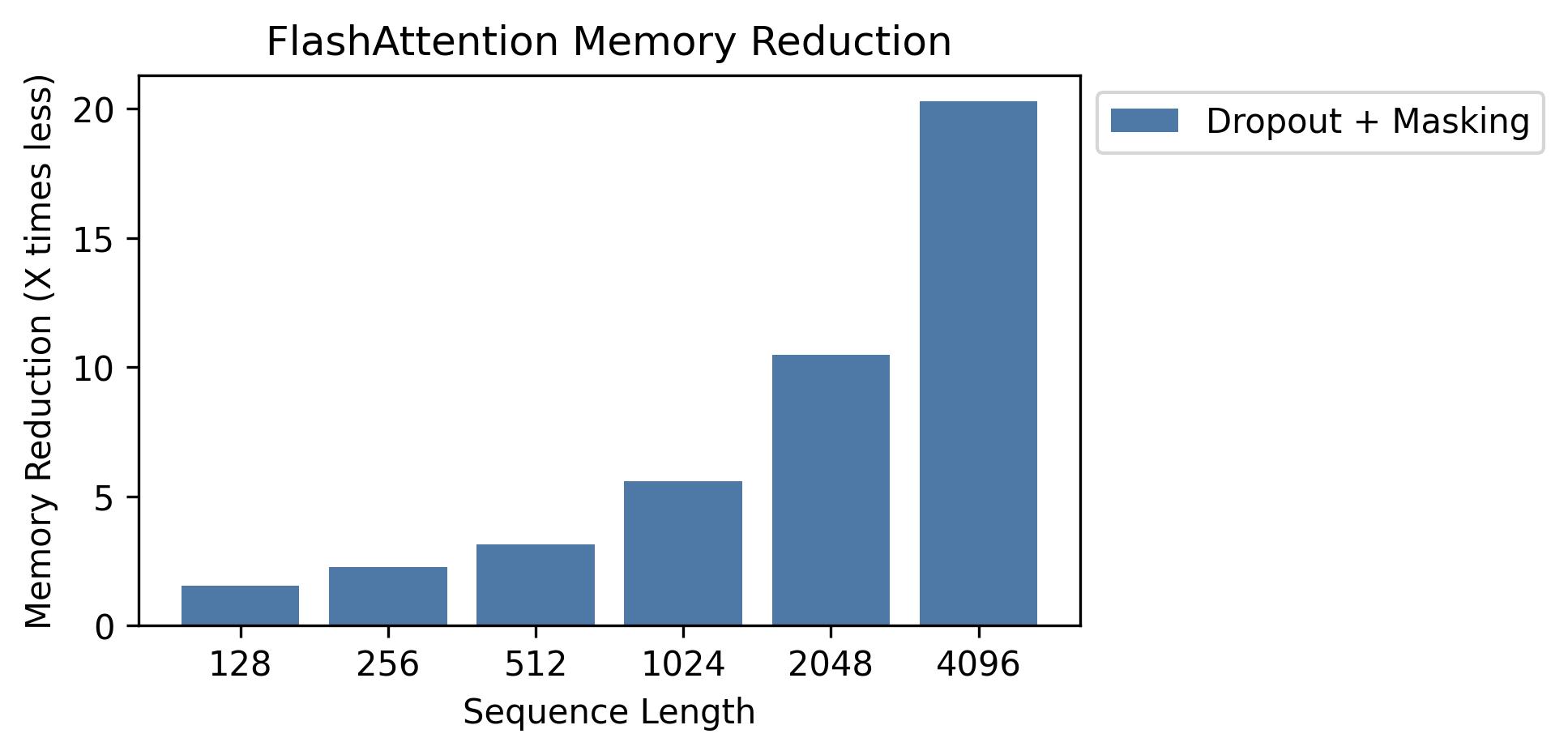
이 그래프에서 메모리 절약을 보여줍니다 (메모리 발자국은 드롭 아웃 또는 마스킹을 사용하든 상관없이 동일합니다). 메모리 절약은 시퀀스 길이에 비례합니다. 표준주의는 순서 길이에서 메모리 2 차를 갖는 반면 FlashAttention은 순서 길이의 메모리 선형을 갖기 때문입니다. 시퀀스 길이 2K에서 10 배 메모리 절약, 4K에서 20x가 표시됩니다. 결과적으로 FlashAttention은 훨씬 긴 시퀀스 길이로 확장 할 수 있습니다.
전체 GPT 모델 구현을 출시했습니다. 우리는 또한 다른 층의 최적화 된 구현 (예 : MLP, Layernorm, 교차 엔트로피 손실, 로터리 임베딩)을 제공합니다. 전반적으로 이것은 Huggingf
또한 OpenWebText에서 GPT2를 훈련시키고 더미에서 GPT3를 훈련시키는 교육 스크립트도 포함되어 있습니다.
Phil Tillet (Openai)은 Triton에서 FlashAttention을 실험적으로 구현했습니다 : https://github.com/openai/triton/blob/master/python/tutorials/06-fuded-attention.py
Triton은 Cuda보다 높은 수준의 언어이므로 이해하고 실험하는 것이 더 쉬울 수 있습니다. Triton 구현의 표기법은 또한 우리 논문에 사용 된 것에 더 가깝습니다.
또한 Triton에서주의 편향 (예 : Alibi)을 지원하는 실험적 구현을 가지고 있습니다. https://github.com/dao-ailab/flash-attention/blob/main/flash_attn/flash_attn_triton.py
우리는 FlashAttention이 기준 구현과 동일한 출력 및 기울기를 일부 수치 적 공차까지 생성하는 것을 테스트합니다. 특히, FlashAttention의 최대 수치 오차는 Pytorch에서 기준선 구현의 수치 오차의 두 배나 최대 두 배의 수치임을 확인합니다 (다른 헤드 치수, 입력 DType, 시퀀스 길이, 인과 / 비 causal).
테스트를 실행하려면 :
pytest -q -s tests/test_flash_attn.py이 새로운 FlashAttention-2는 주로 A100 GPU에서 여러 GPT 스타일 모델에서 테스트되었습니다.
버그가 발생하면 Github 문제를여십시오!
테스트를 실행하려면 :
pytest tests/test_flash_attn_ck.py이 코드베이스를 사용하거나 다른 방식으로 우리의 작업이 가치있는 것을 발견하면 다음을 인용하십시오.
@inproceedings{dao2022flashattention,
title={Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness},
author={Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}
@inproceedings{dao2023flashattention2,
title={Flash{A}ttention-2: Faster Attention with Better Parallelism and Work Partitioning},
author={Dao, Tri},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}


