Marketing Attribution Models
1.0.10
디지털 마케팅 속성에 관한 문제를 해결하기 위해 생성 된 Python 클래스.
온라인으로 탐색하는 동안 사용자는 변환하기 전에 여러 개의 터치 포인트가있어 더 길고 더 복잡한 여행으로 이어질 수 있습니다.
신용 전환을 정식으로 전환하고 미디어에 대한 투자를 장악하는 방법은 무엇입니까?
이를 위해, 우리는 귀속 모델을 적용합니다.
휴리스틱 모델 :
마지막 상호 작용 :
Gogle Analytics 및 Google Ads 및 Facebook Business Manager와 같은 기타 미디어 플랫폼의 기본 속성;
마지막 터치 포인트 만 변환으로 인정됩니다.
마지막으로 클릭하지 않음 :
모든 직접 트래픽은 무시되므로 결과의 100%는 고객이 변환하기 전에 웹 사이트에 도착한 마지막 채널로갑니다.
첫 번째 상호 작용 :
결과는 전적으로 첫 번째 터치 포인트에 기인합니다.
선형 :
모든 터치 포인트도 똑같이 적용됩니다.
시간 붕괴 :
더 최근의 터치 포인트는 신용이 더 많습니다.
위치 기반 :
이 모델에서 결과의 40%는 마지막 터치 포인트에 기인하며, 첫 번째는 40%, 나머지 20%는 중간 채널에 동일하게 분포됩니다.
알고티드 모델
Shapley 가치
게임 이론에 사용되는이 가치는 협동 게임에서 각 개별 플레이어의 기여를 추정하는 것입니다.
전환은 여행을 순수하는 과정에 의해 채널로 인정됩니다. 각 순열에서 채널은 전체적으로 본질적 인 방법을 추정하기 위해 제공됩니다.
예를 들어 , 다음과 같은 과학 적 여정을 살펴 보겠습니다.
유기농 검색> Facebook> Direct> $ 19 (수익)
각 채널의 Shapley 값을 얻으려면 먼저이 주어진 여정의 구성 요소 순열에 대한 모든 변환 값을 고려해야합니다.
유기농 검색> $ 7
Facebook> $ 6
직접> $ 4
유기농 검색> Facebook> $ 15
유기 검색> 직접> $ 7
Facebook> Direct> $ 9
유기농 검색> Facebook> Direct> $ 19
구성 요소의 수는 기하 급수적으로 증가할수록 채널이 더 뚜렷하게 증가합니다. N 채널 의 속도는 2^n (2)입니다.
다시 말해, 3 개의 뚜렷한 터치 포인트로 8 개의 순열이 있습니다. 예를 들어 15 개가 넘는이 프로세스는 불가능합니다 .
기본적으로 Shapley 값을 계산할 때는 터치 포인트의 순서가 고려되지 않으며, 존재 또는 부족 만 고려하지 않습니다. 그렇게하려면 순열 수가 증가합니다 .
이를 염두에두고 상호 작용 순서를 고려할 때이 모델을 사용하는 것은 매우 어렵다는 점에 유의하십시오. N 채널의 경우, 주어진 채널 I 의 2^N 순열뿐만 아니라 다른 위치에 I를 포함하는 모든 순열 도 있습니다.
Shapley 가치의 일부 문제와 한계
Markov Chains Markov Chain은 다음 상태의 확률 분포가 현재 상태의 내용에만 의존하는 특별한 확률 론적 프로세스입니다.
멀티 채널 인력에서, 우리는 Markov 체인을 사용하여 전이 행렬과 의 미디어 채널 쌍 간의 상호 작용 확률을 계산할 수 있습니다.
각 채널의 전환에 대한 기여와 관련하여 제거 효과가 발생합니다. 각 Jorney에 대해 주어진 채널이 제거되고 변환 확률이 계산됩니다.
그러므로 채널에 기인 한 값은 일반적으로 전환 확률과 일단 채널이 일반적인 확률에 걸쳐 다시 제거 될 확률 사이의 차이의 비율에 의해 얻어진다.
다시 말해, 채널의 제거 효과가 클수록 기여가 커집니다.
** Markovian 프로세스로 작업 할 때는 채널의 수량 또는 순서로 인해 제한이 없습니다. 그들의 순서 자체는 알고리즘의 기본 부분입니다.
>> pip install marketing_attribution_models from marketing_attribution_models import MAM MAM 객체를 만들 때 매개 변수 Group_Channels 의 값에 따라 두 데이터 프레임 템플릿을 입력으로 사용할 수 있습니다.
이 데모 스트레이트를 위해 우리는 여정이 아직 그룹화되지 않은 데이터 프레임을 사용하고 각 행을 다른 세션으로, 고유 한 여행 ID가없는 데이터 프레임을 사용할 것입니다.
참고 : MAM 클래스에는 Journey ID Creation, Create_journey_id_based_on_conversion을 위한 매개 변수가 내장되어 있으며, true 인 경우 group_channels_id_list 매개 변수의 입력을 기반으로 ID가 생성되고 변환이 있거나없는 열에는 ID가 생성됩니다. 이름은 journey_with_conv_colname 매개 변수로 정의됩니다.
이 시나리오에서는 각 별개의 사용자의 모든 세션이 주문되고 모든 변환에 대해 새로운 Journey ID가 생성됩니다. 그러나 우리는이 여정 ID 생성이 비즈니스와 관련된 지식 과 탐색 적 결론에 따라 맞춤화되도록 권장합니다 . 예를 들어, 주어진 사업에서 평균 여행 기간이 약 일주일이라는 것이 주목되면, 새로운 크리에 레온이 정의 될 수 있으므로 7 일 동안 어떤 사용자가 상호 작용하지 않으면, 여행이 손실되었다고 가정 하에서 여행이 중단됩니다. 관심있는.
현재 매개 변수는 Group_ Channels = True 시나리오에 대한 구성 방법이 있습니다.
attributions = MAM ( df ,
group_channels = True ,
channels_colname = 'channels' ,
journey_with_conv_colname = 'has_transaction' ,
group_channels_by_id_list = [ 'user_id' ],
group_timestamp_colname = 'visitStartTime' ,
create_journey_id_based_on_conversion = True )MAM의 기능을 탐색하고 이해하기 위해 TRUE 로 설정할 때 Random_DF 매개 변수를 사용하여 "랜덤 데이터 프레임 생성기"가 구현되었습니다.
attributions = MAM ( random_df = True )객체 MAM이 생성 된 후, 우리는 journey_id 를 추가하고 attriute ".dataframe"을 사용하여 여행 에 그룹화 된 세션을 포함하여 데이터베이스를 확인할 수 있습니다.
attributions . DataFrame| Journey_ID | 채널 _agg | time_till_conv_agg | converted_agg | conversion_value | |
|---|---|---|---|---|---|
| 0 | ID : 0_J : 0 | 페이스 북 | 0.0 | 진실 | 1 |
| 1 | ID : 0_J : 1 | Google 검색 | 0.0 | 진실 | 1 |
| 2 | ID : 0_J : 10 | Google 검색> 유기농> 이메일 마케팅 | 72.0> 24.0> 0.0 | 진실 | 1 |
| 3 | ID : 0_J : 11 | 본질적인 | 0.0 | 진실 | 1 |
| 4 | ID : 0_J : 12 | 이메일 마케팅> Facebook | 432.0> 0.0 | 진실 | 1 |
| ... | ... | ... | ... | ... | ... |
| 20341 | ID : 9_J : 5 | 직접> 페이스 북 | 120.0> 0.0 | 진실 | 1 |
| 20342 | ID : 9_J : 6 | Google 검색> Google 검색> Google 검색 | 48.0> 24.0> 0.0 | 진실 | 1 |
| 20343 | ID : 9_J : 7 | Organic> Organic> Google 검색> Google 검색 | 480.0> 480.0> 288.0> 0.0 | 진실 | 1 |
| 20344 | ID : 9_J : 8 | 직접> 유기농 | 168.0> 0.0 | 진실 | 1 |
| 20345 | ID : 9_J : 9 | Google 검색> Organic> Google Search> Emai ... | 528.0> 528.0> 408.0> 240.0> 0.0 | 진실 | 1 |
이 속성은 생성 된 모든 속성 모델 에 대해 업데이트 됩니다. 휴리스틱 모델의 경우에만 해당 모델에 의해 주어진 속성 값이 포함 된 새 열이 추가됩니다.
참고 : 속성 .DataFrame 은 모델 계산을 방해하지 않습니다. 사용에 의해 변경되면 다음 결과는 영향을받지 않습니다.
attributions . attribution_last_click ()
attributions . DataFrame| Journey_ID | 채널 _agg | time_till_conv_agg | converted_agg | conversion_value | |
|---|---|---|---|---|---|
| 0 | ID : 0_J : 0 | 페이스 북 | 0.0 | 진실 | 1 |
| 1 | ID : 0_J : 1 | Google 검색 | 0.0 | 진실 | 1 |
| 2 | ID : 0_J : 10 | Google 검색> 유기농> 이메일 마케팅 | 72.0> 24.0> 0.0 | 진실 | 1 |
| 3 | ID : 0_J : 11 | 본질적인 | 0.0 | 진실 | 1 |
| 4 | ID : 0_J : 12 | 이메일 마케팅> Facebook | 432.0> 0.0 | 진실 | 1 |
| ... | ... | ... | ... | ... | ... |
| 20341 | ID : 9_J : 5 | 직접> 페이스 북 | 120.0> 0.0 | 진실 | 1 |
| 20342 | ID : 9_J : 6 | Google 검색> Google 검색> Google 검색 | 48.0> 24.0> 0.0 | 진실 | 1 |
| 20343 | ID : 9_J : 7 | Organic> Organic> Google 검색> Google 검색 | 480.0> 480.0> 288.0> 0.0 | 진실 | 1 |
| 20344 | ID : 9_J : 8 | 직접> 유기농 | 168.0> 0.0 | 진실 | 1 |
| 20345 | ID : 9_J : 9 | Google 검색> Organic> Google Search> Emai ... | 528.0> 528.0> 408.0> 240.0> 0.0 | 진실 | 1 |
일반적으로 작업 된 데이터의 양은 광범위하기 때문에 거래와의 각 여정에 기인 한 결과를 분석하는 것은 실용적이지 않거나 불가능합니다. 그러나 속성 Group_by_channels_Models 를 사용하면 모든 결과는 채널별로 그룹화 할 수 있습니다.
참고 : 동일한 모델이 두 개의 별개의 인스턴스에서 사용되는 경우 그룹화 된 결과는 서로를 덮어 쓰지 않습니다 . 둘 다 (또는 그 이상) " Group_by_channels_models "에 표시됩니다.
attributions . group_by_channels_models| 채널 | Attribution_LAST_CLICK_HEURISTIC |
|---|---|
| 직접 | 2133 |
| 이메일 마케팅 | 1033 |
| 페이스 북 | 3168 |
| Google 디스플레이 | 1073 |
| Google 검색 | 4255 |
| 인스 타 그램 | 1028 |
| 본질적인 | 6322 |
| YouTube | 1093 |
.dataframe 속성과 마찬가지로 Group_by_channels_models는 알고리즘 결과를 표시하지 않는 제한없이 사용되는 모든 모델에 대해 업데이트됩니다.
attributions . attribution_shapley ()
attributions . group_by_channels_models| 채널 | Attribution_LAST_CLICK_HEURISTIC | Attribution_shapley_size4_conv_rate_algorithmic | |
|---|---|---|---|
| 0 | 직접 | 109 | 74.926849 |
| 1 | 이메일 마케팅 | 54 | 70.558428 |
| 2 | 페이스 북 | 160 | 160.628945 |
| 3 | Google 디스플레이 | 65 | 110.649352 |
| 4 | Google 검색 | 193 | 202.179519 |
| 5 | 인스 타 그램 | 64 | 72.982433 |
| 6 | 본질적인 | 315 | 265.768549 |
| 7 | YouTube | 58 | 60.305925 |
모든 휴리스틱 모델은 이전에 설명한대로 .dataframe 및 .group_by_channels_models 속성을 사용할 때 동일하게 동일하며, 모든 휴리스틱 모델 메소드 의 출력은 두 개의 팬더 시리즈를 포함하는 튜플을 반환합니다.
attribution_first_click = attributions . attribution_first_click ()튜플의 첫 번째 시리즈는 .dataframe 속성에서 관찰 된 것과 유사한 여행 세분화 결과입니다.
attribution_first_click [ 0 ] 0 [1, 0, 0, 0, 0]
1 [1]
2 [1, 0, 0, 0, 0, 0, 0, 0, 0]
3 [1, 0]
4 [1]
...
20512 [1, 0]
20513 [1, 0, 0]
20514 [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
20515 [1, 0, 0]
20516 [1, 0, 0, 0]
Length: 20517, dtype: object
두 번째는 .group_by_channels_models 속성에서 볼 수 있듯이 채널 세분화 의 결과를 포함합니다.
attribution_first_click [ 1 ]| 채널 | Attribution_FIRST_CLICK_HEURISTIC | |
|---|---|---|
| 0 | 직접 | 2078 |
| 1 | 이메일 마케팅 | 1095 |
| 2 | 페이스 북 | 3177 |
| 3 | Google 디스플레이 | 1066 |
| 4 | Google 검색 | 4259 |
| 5 | 인스 타 그램 | 1007 |
| 6 | 본질적인 | 6361 |
| 7 | YouTube | 1062 |
객체 MAM에 존재하는 모든 모델 중 마지막 클릭 만 클릭, 첫 클릭 및 선형에는 사용자 정의 가능한 매개 변수가 없지만 Group_By_channels_Models 는 거짓 으로 설정할 때 부울 값이 있습니다.
이전의 중재가 주어진 타임 스파 (기본적으로 6 개월)에 직접 자체 이외의 특정 트래픽 소스가있는 경우 직접 트래픽을 덮어 쓴 경우 Google 웹 로그 분석의 기본값 ( 마지막 클릭 비 직접 )을 복제하도록 만들어졌습니다.
지정되지 않은 경우 매개 변수 BUT_NOT_THIS_CHANNEL은 'Direct' 로 설정되어 있지만 비즈니스에 대한 다른 관심 채널로 설정할 수 있습니다.
attributions . attribution_last_click_non ( but_not_this_channel = 'Direct' )[ 1 ]| 채널 | Attribution_LAST_CLICK_NON_DIRECT_HEURISTIC | |
|---|---|---|
| 0 | 직접 | 11 |
| 1 | 이메일 마케팅 | 60 |
| 2 | 페이스 북 | 172 |
| 3 | Google 디스플레이 | 69 |
| 4 | Google 검색 | 224 |
| 5 | 인스 타 그램 | 67 |
| 6 | 본질적인 | 350 |
| 7 | YouTube | 65 |
이 모델에는 매개 변수 list_positions_first_middle_last 가 있는데, 여기에는 각 여행에서 채널 위치에 대한 가중치가 비즈니스 관련 결정에 따라 지정할 수 있습니다. 매개 변수의 기본 분포는 도입 채널의 경우 40% , 변환 / 마지막 채널의 경우 40% , 횡 방향 채널의 경우 20% 입니다.
attributions . attribution_position_based ( list_positions_first_middle_last = [ 0.3 , 0.3 , 0.4 ])[ 1 ]| 채널 | Attribution_Position_based_0.3_0.3_0.4_Heuristic | |
|---|---|---|
| 0 | 직접 | 95.685085 |
| 1 | 이메일 마케팅 | 57.617191 |
| 2 | 페이스 북 | 145.817501 |
| 3 | Google 디스플레이 | 56.340693 |
| 4 | Google 검색 | 193.282305 |
| 5 | 인스 타 그램 | 54.678557 |
| 6 | 본질적인 | 288.148896 |
| 7 | YouTube | 55.629772 |
두 가지 사용자 정의 가능한 설정이 있습니다 : 붕괴 속도 , Decay_over_time * 매개 변수를 throght 및 주파수 매개 변수를 통해 각 유쾌한 사이의 시간 (시간).
그러나 주파수 간격 사이에 둘 이상의 터치 포인트가있는 경우 변환 값이 이러한 채널에 동일하게 분포 될 것임을 주목할 가치가 있습니다.
예를 들어 :
attributions . attribution_time_decay (
decay_over_time = 0.6 ,
frequency = 7 )[ 1 ]| 채널 | Attribution_time_decay0.6_freq7_heuristic | |
|---|---|---|
| 0 | 직접 | 108.679538 |
| 1 | 이메일 마케팅 | 54.425914 |
| 2 | 페이스 북 | 159.592216 |
| 3 | Google 디스플레이 | 64.350107 |
| 4 | Google 검색 | 192.838884 |
| 5 | 인스 타 그램 | 64.611414 |
| 6 | 본질적인 | 314.920082 |
| 7 | YouTube | 58.581845 |
Uppon 호출되는이 모델은 4 개의 구성 요소가있는 튜플을 반환합니다. 처음 두 (색인 0 및 1)는 각각 .dataframe 및 .group_by_channels_models 의 표현과 함께 휴리스틱 모델과 같습니다. 세 번째 및 네 번째 구성 요소 (인덱스 2 및 3)의 경우 결과는 전이 행렬 및 제거 효과 테이블 입니다.
시작하려면 동일한 상태 전이가 고려되는지 여부를 표시 할 수 있습니다 ( 예 : 직접 직접).
attribution_markov = attributions . attribution_markov ( transition_to_same_state = False )| 채널 | Attribution_markov_algorithmic | |
|---|---|---|
| 0 | 직접 | 2305.324362 |
| 1 | 이메일 마케팅 | 1237.400774 |
| 2 | 페이스 북 | 3273.918832 |
| 3 | YouTube | 1231.183938 |
| 4 | Google 검색 | 4035.260685 |
| 5 | 인스 타 그램 | 1205.949095 |
| 6 | 본질적인 | 5358.270644 |
| 7 | Google 디스플레이 | 1213.691671 |
이 구성은 각 채널에 대한 전체 귀속 결과 에 영향을 미치지 않지만 전이 행렬 에서 관찰 된 값에 영향을 미칩니다. 전환 _to_same_state를 false 로 설정하기 때문에 상태가 스스로 전환되는 상태를 나타내는 대각선이 무효화됩니다.
ax , fig = plt . subplots ( figsize = ( 15 , 10 ))
sns . heatmap ( attribution_markov [ 2 ]. round ( 3 ), cmap = "YlGnBu" , annot = True , linewidths = .5 )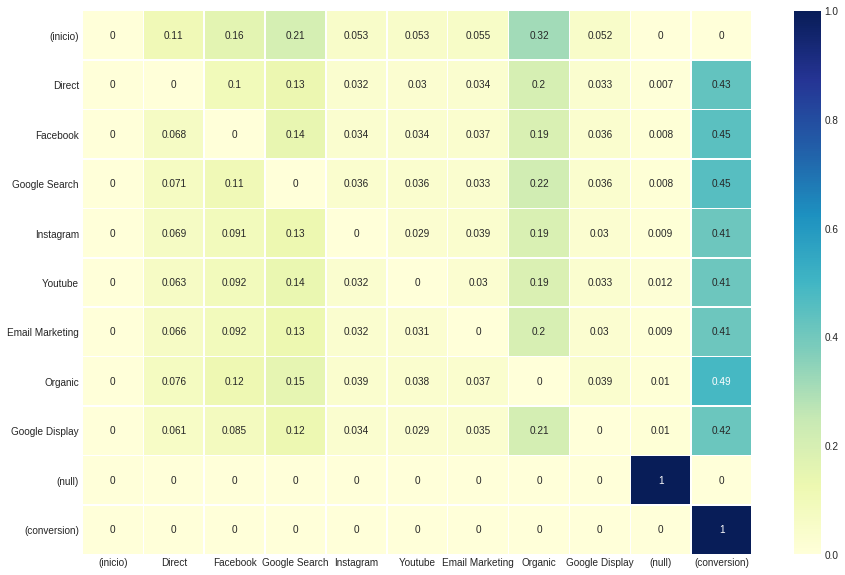
네 번째 Attribution_markov 출력 인 제거 효과는 일반적으로 전환 확률과 일단 채널이 일반적인 확률에 따라 다시 제거되면 확률의 차이의 비율에 의해 얻어집니다.
ax , fig = plt . subplots ( figsize = ( 2 , 5 ))
sns . heatmap ( attribution_markov [ 3 ]. round ( 3 ), cmap = "YlGnBu" , annot = True , linewidths = .5 )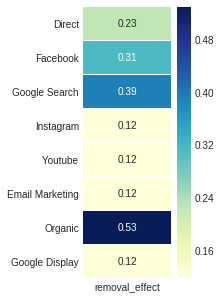
마지막으로, 게임 이론 에서 나오는 MAM 의 두 번째 알고리즘 모델. 여기서 목표는 주어진 채널이 있거나없는 여정 조합을 사용하여 계산 된 협력 게임에서 각 플레이어 (우리의 경우 채널)의 기여를 배포하는 것입니다.
매개 변수 크기는 모든 여행에서 채널 체인의 길이 의 한계를 정의합니다. 기본적으로 값은 4 로 설정되므로 변환 이전의 4 개의 마지막 채널 만 고려됩니다.
각 채널의 한계 기여 계산 방법은 순서 매개 변수에 따라 다를 수 있습니다. 기본적으로 그것은 거짓 으로 설정되어 있으며, 이는 기여가 여행에서 각 채널의 순서를 무시하는 것을 계산한다는 것을 의미합니다.
attributions . attribution_shapley ( size = 4 , order = True , values_col = 'conv_rate' )[ 0 ]| 조합 | 전환 | Total_sequences | conversion_value | conv_rate | Attribution_shapley_size4_conv_rate_order_algorithmic | |
|---|---|---|---|---|---|---|
| 0 | 직접 | 909 | 926 | 909 | 0.981641 | [909.0] |
| 1 | 직접> 이메일 마케팅 | 27 | 28 | 27 | 0.964286 | [13.948270234099155, 13.051729765900845] |
| 2 | 직접> 이메일 마케팅> Facebook | 5 | 5 | 5 | 1.000000 | [1.6636366232390172, 1.5835883671498818, 1.752 ... |
| 3 | 직접> 이메일 마케팅> Facebook> Google D ... | 1 | 1 | 1 | 1.000000 | [0.2563402919193473, 0.2345560799963515, 0.259 ... |
| 4 | 직접> 이메일 마케팅> Facebook> Google S ... | 1 | 1 | 1 | 1.000000 | [0.2522517802130265, 0.2401286956930936, 0.255 ... |
| ... | ... | ... | ... | ... | ... | ... |
| 1278 | YouTube> Organic> Google Search> Google Dis ... | 1 | 2 | 1 | 0.500000 | [0.2514214624662836, 0.24872101523605275, 0.24 ... |
| 1279 | YouTube> Organic> Google 검색> Instagram | 1 | 1 | 1 | 1.000000 | [0.2544401477637237, 0.254107188956603, 0.253 ... |
| 1280 | YouTube> Organic> Instagram | 4 | 4 | 4 | 1.000000 | [1.2757196742326997, 1.4712839059493295, 1.252 ... |
| 1281 | YouTube> Organic> Instagram> Facebook | 1 | 1 | 1 | 1.000000 | [0.2357631944623868, 0.2610913781266248, 0.247 ... |
| 1282 | YouTube> Organic> Instagram> Google 검색 | 3 | 3 | 3 | 1.000000 | [0.7223482210689489, 0.769049003203142, 0.726 ... |
마지막으로, Shapley 값을 계산하는 데 사용되는 메트릭을 나타내는 매개 변수는 value_col 입니다. 기본적으로 기본적으로 변환율 로 설정됩니다. 그렇게하면 전환이없는 여정이 Acount로 가져갑니다.
그러나 아래에서 볼 수 있듯이 모델을 사용할 때는 문자 전환 만 고려할 수 있습니다.
attributions . attribution_shapley ( size = 3 , order = False , values_col = 'conversions' )[ 0 ]| 조합 | 전환 | Total_sequences | conversion_value | conv_rate | Attribution_shapley_size3_conversions_algorithmic | |
|---|---|---|---|---|---|---|
| 0 | 직접 | 11 | 18 | 18 | 0.611111 | [11.0] |
| 1 | 직접> 이메일 마케팅 | 4 | 5 | 5 | 0.800000 | [2.0, 2.0] |
| 2 | 직접> 이메일 마케팅> Google 검색 | 1 | 2 | 2 | 0.500000 | [-3.1666666666666665, -7.6666666666666666, 11.8 ... |
| 3 | 직접> 이메일 마케팅> 유기농 | 4 | 6 | 6 | 0.666667 | [-7.83333333333333, -10.83333333333332, 22.6 ... |
| 4 | 직접> 페이스 북 | 3 | 4 | 4 | 0.750000 | [-8.5, 11.5] |
| ... | ... | ... | ... | ... | ... | ... |
| 75 | Instagram> Organic> YouTube | 46 | 123 | 123 | 0.373984 | [5.8333333333332, 34.3333333333333, 5.83333 ... |
| 76 | Instagram> YouTube | 2 | 4 | 4 | 0.500000 | [2.0, 0.0] |
| 77 | 본질적인 | 64 | 92 | 92 | 0.695652 | [64.0] |
| 78 | 유기농> YouTube | 8 | 11 | 11 | 0.727273 | [30.5, -22.5] |
| 79 | YouTube | 11 | 15 | 15 | 0.733333 | [11.0] |
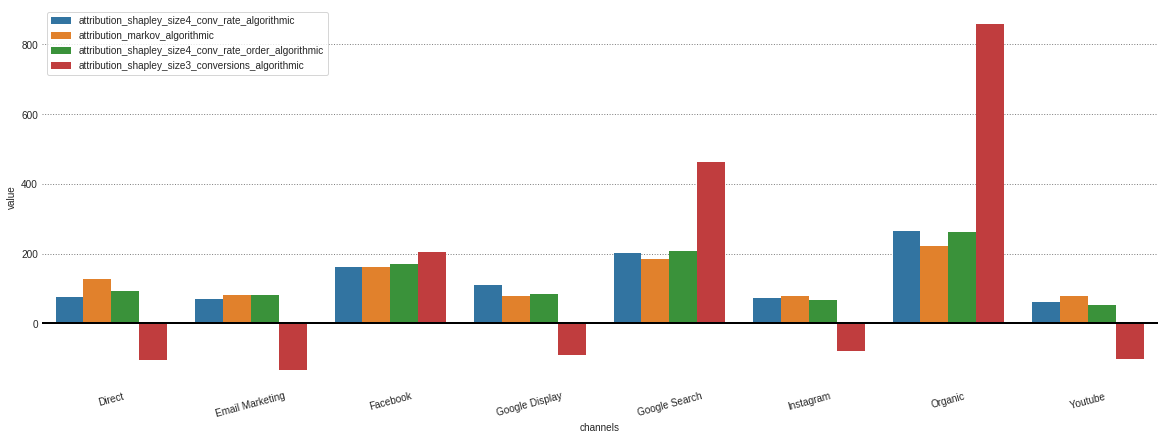
.group_by_channels_models 객체에 저장된 다른 모델에서 모든 속성을 얻은 후 통찰력에 대한 결과를 플롯하고 비교할 수 있습니다.
attributions . plot ()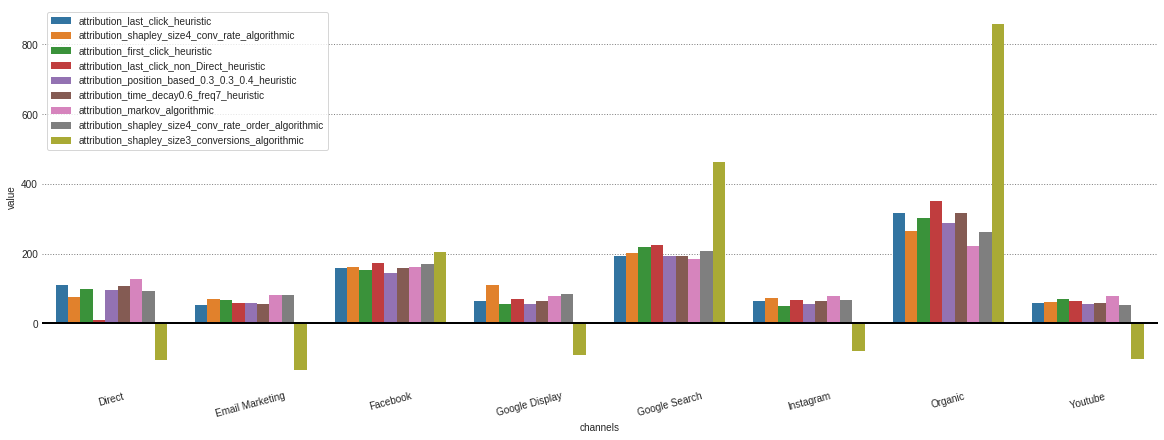
알고리즘 모델에만 관심이있는 경우 Model_Type 매개 변수에 지정할 수 있습니다.
attributions . plot ( model_type = 'algorithmic' )