ainovelprompter
1.0.0
AI 소설 프롬프터는 사용자 지정된 특성을 기반으로 소설에 대한 글쓰기 프롬프트를 생성 할 수 있습니다.
AI Novel Prompter는 작가가 Chatgpt 및 Claude와 같은 AI 작문 조수를 위해 일관되고 잘 구조화 된 프롬프트를 만들 수 있도록 설계된 데스크탑 응용 프로그램입니다. 이 도구는 스토리 요소, 캐릭터 세부 사항을 관리하고 소설을 계속하기 위해 올바르게 형식화 된 프롬프트를 생성하는 데 도움이됩니다.
실행 파일은 빌드/빈 실행 가능에 있습니다
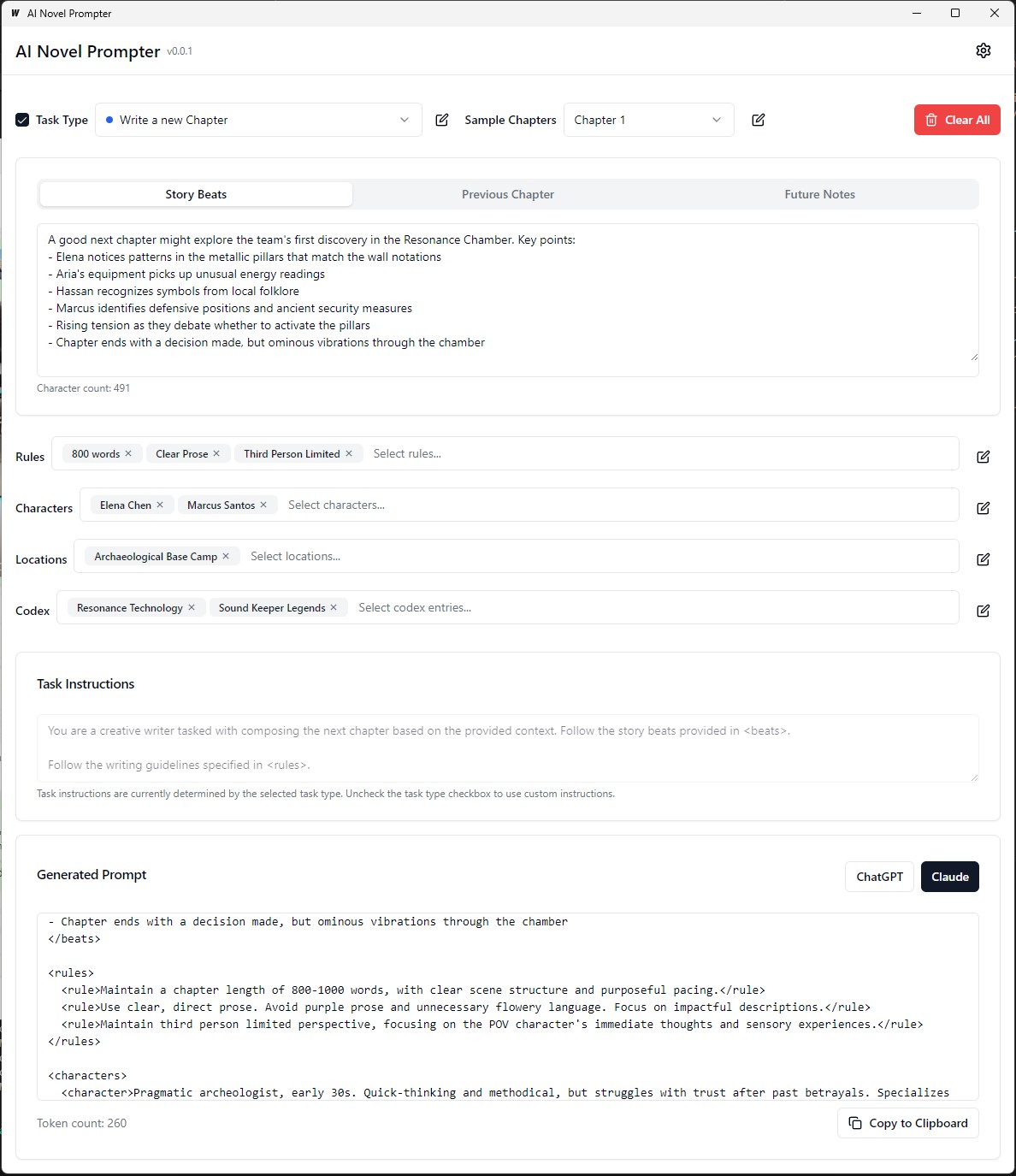
각 카테고리는 다른 프롬프트에서 편집, 저장 및 재사용 할 수 있습니다.
프론트 엔드 :
백엔드 :
.ai-novel-prompter 에서 사용자의 홈 디렉토리에 데이터를 저장합니다 # Clone the repository
git clone [repository-url]
# Install frontend dependencies
cd frontend
npm install
# Build and run the application
cd ..
wails dev 재분배 가능한 생산 모드 패키지를 구축하려면 wails build 사용하십시오.
wails build실행 파일은 빌드/빈 실행 가능에 있습니다
또는 다음과 같이 생성하십시오.
wails build -nsis이것은 Mac에 대해서도 수행 할 수 있으며이 안내서의 최신 부분을 참조하십시오.
빌드 응용 프로그램은 build 디렉토리에서 사용할 수 있습니다.
초기 설정 :
프롬프트 생성 :
출력 생성 :
응용 프로그램을 실행하기 전에 다음과 같은 설치가 있는지 확인하십시오.
git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
server 디렉토리로 이동 :
cd server
GO 의존성 설치 :
go mod download
데이터베이스 구성으로 config.yaml 파일을 업데이트하십시오.
데이터베이스 마이그레이션 실행 :
go run cmd/main.go migrate
백엔드 서버 시작 :
go run cmd/main.go
client 디렉토리로 이동하십시오.
cd ../client
프론트 엔드 종속성 설치 :
npm install
프론트 엔드 개발 서버 시작 :
npm start
http://localhost:3000 방문하여 응용 프로그램에 액세스하십시오. git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
데이터베이스 구성으로 docker-compose.yml 파일을 업데이트하십시오.
Docker Compose를 사용하여 응용 프로그램을 시작하십시오.
docker-compose up -d
http://localhost:3000 방문하여 응용 프로그램에 액세스하십시오. server/config.yaml 파일에서 수정할 수 있습니다.client/src/config.ts 파일에서 수정할 수 있습니다. 생산을위한 프론트 엔드를 구축하려면 client 디렉토리에서 다음 명령을 실행하십시오.
npm run build
프로덕션 지원 파일은 client/build 디렉토리에서 생성됩니다.
이 작은 안내서는 Linux (WSL)의 Windows 서브 시스템에 PostgreSQL을 설치하는 방법과 사용자 권한을 관리하고 일반적인 문제를 해결하는 단계에 대한 지침을 제공합니다.
WSL 터미널 열기 : WSL 배포를 시작하십시오 (Ubuntu 권장).
업데이트 패키지 :
sudo apt updatePostgreSQL 설치 :
sudo apt install postgresql postgresql-contrib설치 확인 :
psql --versionPostgreSQL 사용자 비밀번호 설정 :
sudo passwd postgres데이터베이스 생성 :
createdb mydb액세스 데이터베이스 :
psql mydbSQL 파일에서 테이블 가져 오기 :
psql -U postgres -q mydb < /path/to/file.sql데이터베이스 및 테이블 나열 :
l # List databases
dt # List tables in the current database스위치 데이터베이스 :
c dbname새 사용자 만들기 :
CREATE USER your_db_user WITH PASSWORD ' your_db_password ' ;권한 보조금 :
ALTER USER your_db_user CREATEDB;역할은 존재하지 않습니다. 오류 : 'Postgres'사용자로 전환하십시오.
sudo -i -u postgres
createdb your_db_name확장 생성 : 'Postgres'로 로그인하고 실행하는 권한이 거부되었습니다 .
CREATE EXTENSION IF NOT EXISTS pg_trgm; 알 수없는 사용자 오류 : 인식 된 시스템 사용자를 사용하고 있는지 확인하거나 sudo 통해가 아니라 SQL 환경 내에서 PostgreSQL 사용자를 올바르게 참조하십시오.
George MacDonald의 글쓰기 스타일을 모방하기 위해 언어 모델을 미세 조정하기위한 맞춤형 교육 데이터를 생성하기 위해이 과정은 Project Gutenberg에서 그의 소설 중 하나 인 "The Princess and the Goblin"의 전체 텍스트를 얻는 것으로 시작됩니다. 그런 다음 텍스트는 AI가 각 비트에 대한 JSON 객체를 생성하고 저자, 감정 톤, 글쓰기 유형 및 실제 텍스트 발췌를 지시하는 프롬프트를 사용하여 개별 스토리 비트 또는 주요 순간으로 분류됩니다.
다음으로 GPT-4는 이러한 각 스토리 비트를 자체 단어로 다시 작성하는 데 사용되며, 재 작성 된 각 비트를 원래의 상대방에 연결하는 고유 식별자와 병렬 JSON 데이터 세트를 생성합니다. 데이터를 단순화하고 훈련에 더 유용하게하기 위해, 다양한 감정적 톤은 Python 기능을 사용하여 더 작은 코어 톤에 매핑됩니다. 그런 다음 두 JSON 파일 (원본 및 재 작성 비트)은 교육 프롬프트를 생성하는 데 사용되며, 여기서 모델은 원래 저자의 스타일로 GPT-4 생성 텍스트를 다시 제출하도록 요청됩니다. 마지막으로, 이러한 프롬프트와 대상 출력은 JSONL 및 JSON 파일로 형식화되어 언어 모델을 미세 조정하여 MacDonald의 독특한 작문 스타일을 캡처 할 수 있습니다.
이전의 예에서, 언어 모델을 사용하여 면적 기반 텍스트를 생성하는 프로세스에는 일부 수동 작업이 포함되었습니다. 사용자는 입력 텍스트를 수동으로 제공하고 스크립트를 실행 한 다음 생성 된 출력을 검토하여 품질을 보장해야했습니다. 출력이 원하는 기준을 충족하지 않으면 사용자는 다른 매개 변수로 생성 프로세스를 수동으로 재 시도하거나 입력 텍스트를 조정해야합니다.
그러나 process_text_file 기능의 업데이트 된 버전을 사용하면 전체 프로세스가 완전히 자동화되었습니다. 이 함수는 입력 텍스트 파일을 읽고 단락으로 나누고 각 단락을 언어 모델로 자동으로 전송합니다. 생성 된 출력이 원치 않는 문구를 포함하거나 너무 짧거나 너무 길거나 여러 단락으로 구성된 지정된 기준을 충족하지 않는 경우를 처리하기위한 다양한 검사 및 재시도 메커니즘을 통합합니다.
자동화 프로세스에는 몇 가지 주요 기능이 포함됩니다.
마지막으로 처리 된 단락에서 재개 : 스크립트가 중단되거나 여러 번 실행 해야하는 경우 출력 파일을 자동으로 확인하고 마지막으로 성공적으로 해당 단락에서 처리를 재개합니다. 이를 통해 진행이 손실되지 않고 스크립트가 중단 된 곳에서 픽업 할 수 있습니다.
임의의 종자 및 온도를 가진 재 시도 메커니즘 : 생성 된 역할이 지정된 기준을 충족시키지 못하면 스크립트는 생성 프로세스를 지정된 횟수로 자동 복원합니다. 각각의 재 시도마다 종자 및 온도 값을 무작위로 변경하여 생성 된 응답의 변화를 도입하여 만족스러운 출력을 얻을 가능성이 높아집니다.
진행 절약 : 스크립트는 지정된 단락 수 (예 : 500 개 단락마다)마다 출력 파일에 진행 상황을 저장합니다. 이는 큰 텍스트 파일을 처리하는 동안 중단 또는 오류가 발생할 경우 데이터 손실로부터 보호합니다.
자세한 로깅 및 요약 : 스크립트는 입력 단락, 생성 된 출력, 재 시도 및 실패 이유를 포함한 자세한 로깅 정보를 제공합니다. 또한 마지막에 요약을 생성하여 총 단락 수, 성공적으로 해당 단락, 건너 뛰는 단락 및 총원 수를 표시합니다.
George MacDonald의 글쓰기 스타일을 모방하기 위해 언어 모델을 미세 조정하기위한 ORPO 사용자 정의 교육 데이터를 생성합니다.
입력 데이터는 JSONL 형식이어야하며 각 라인에는 프롬프트 및 선택한 응답이 포함 된 JSON 객체가 포함되어 있어야합니다. (이전 미세 조정에서) 스크립트를 사용하려면 API 키로 OpenAI 클라이언트를 설정하고 입력 및 출력 파일 경로를 지정해야합니다. 스크립트를 실행하면 JSONL 파일을 처리하고 프롬프트, 선택한 응답 및 생성 된 거부 된 응답에 대한 열이있는 CSV 파일을 생성합니다. 스크립트는 100 줄마다 진행을 저장하고 중단 된 경우 중단 된 곳에서 재개 할 수 있습니다. 완료되면 처리 된 총 라인, 서면 라인, 건너 뛰는 라인 및 재 시도 세부 사항을 요약합니다.
데이터 세트 품질 문제 : 결과의 95%가 데이터 세트 품질에 의존합니다. 약간의 나쁜 데이터조차도 모델을 해칠 수 있으므로 깨끗한 데이터 세트는 필수적입니다.
수동 데이터 검토 : 데이터 세트 청소 및 평가는 모델을 크게 향상시킬 수 있습니다. 매개 변수 조정량이 결함있는 데이터 세트를 수정할 수 없기 때문에 시간이 많이 걸리지 만 필요한 단계입니다.
훈련 매개 변수는 개선되지 않고 모델 저하를 방지해야합니다. 강력한 데이터 세트에서 목표는 모델을 지시하는 동안 부정적인 영향을 피하는 것입니다. 최적의 학습 속도는 없습니다.
모델 스케일 및 하드웨어 제한 사항 : 대형 모델 (33B 매개 변수)은 더 나은 미세 조정을 가능하게 할 수 있지만 48GB 이상의 VRAM이 필요하므로 대부분의 홈 설정에 실용적이지 않습니다.
그라디언트 축적 및 배치 크기 : 그라디언트 축적은 다양한 데이터 세트에서 일반화를 향상시켜 과적으로 적합성을 줄이는 데 도움이되지만 배치 후 품질이 낮아질 수 있습니다.
데이터 세트의 크기는 잘 조정 된 모델보다 기본 모델을 미세 조정하는 데 더 중요합니다. 과도한 데이터로 잘 조정 된 모델을 과부하 시키면 이전의 미세 조정이 저하 될 수 있습니다.
이상적인 학습 속도 일정은 워밍업 단계로 시작하여 에포크의 안정을 유지 한 다음 코사인 일정을 사용하여 점차 감소합니다.
모델 순위 및 일반화 : 훈련 가능한 매개 변수의 양은 모델의 세부 사항과 일반화에 영향을 미칩니다. 낮은 순위 모델은 일반화하지만 세부 사항을 잃어 버립니다.
LORA의 적용 가능성 : 매개 변수 효율적인 미세 조정 (PEFT)은 대형 언어 모델 (LLMS) 및 안정 확산 (SD)과 같은 시스템에 적용되며, 다양성을 보여줍니다.
Unsloth 커뮤니티는 LLAMA3의 Finetuning과 관련된 몇 가지 문제를 해결하는 데 도움이되었습니다. 명심해야 할 몇 가지 핵심 사항은 다음과 같습니다.
이중 BOS 토큰 : 미세 조정 중 이중 BOS 토큰은 물건을 깨뜨릴 수 있습니다. Unsloth는이 문제를 자동으로 수정합니다.
GGUF 변환 : GGUF 변환이 파손되었습니다. 이중 BOS에주의를 기울이고 전환을 위해 GPU 대신 CPU를 사용하십시오. Unsloth에는 자동 GGUF 변환이 내장되어 있습니다.
버기베이스 가중치 : 일부 llama 3의베이스 (지시되지 않음) 중량은 "버기"(비 훈련) : <|reserved_special_token_{0->250}|> <|eot_id|> <|start_header_id|> <|end_header_id|> . 이로 인해 NAN과 버그가 발생할 수 있습니다. Unsloth는 자동으로 이것을 수정합니다.
시스템 프롬프트 : Unsloth 커뮤니티에 따르면 시스템 프롬프트를 추가하면 강력한 버전 (및 기본 버전)을 훨씬 향상시킵니다.
양자화 문제 : 양자화 문제가 일반적입니다. LLAMA3로 우수한 성능을 얻을 수 있음을 보여주는이 비교를 참조하십시오. 그러나 잘못된 양자화를 사용하면 성능이 손상 될 수 있습니다. 미세 조정의 경우 Bitsandbytes NF4를 사용하여 정확도를 높이십시오. GGUF의 경우 최대한 I 버전을 사용하십시오.
긴 맥락 모델 : 긴 맥락 모델은 잘 훈련되지 않습니다. 그들은 단순히 밧줄 세타를 연장하고 때로는 훈련 없이도 밧줄을 연장 한 다음 이상한 연결 데이터 세트를 훈련시켜 긴 데이터 세트로 만듭니다. 이 접근법은 잘 작동하지 않습니다. 8K에서 1m 컨텍스트 길이로 스케일링하면 매끄럽고 연속적인 긴 컨텍스트 스케일링이 훨씬 좋았을 것입니다.
이러한 문제 중 일부를 해결하려면 LLAMA3를 미세 조정하려면 Unsloth를 사용하십시오.
저자의 스타일로 역설을위한 언어 모델을 미세 조정할 때 생성 된 역설의 품질과 효과를 평가하는 것이 중요합니다.
다음 평가 메트릭은 모델의 성능을 평가하는 데 사용될 수 있습니다.
Bleu (이중 언어 평가 학부) :
sacrebleu 라이브러리를 사용할 수 있습니다.from sacrebleu import corpus_bleu; bleu_score = corpus_bleu(generated_paraphrases, [original_paragraphs])ROUGE (리콜 지향적 인 학부 평가를위한 리콜 지향 연구) :
rouge 라이브러리를 사용할 수 있습니다.from rouge import Rouge; rouge = Rouge(); scores = rouge.get_scores(generated_paraphrases, original_paragraphs)당황:
perplexity = model.perplexity(generated_paraphrases)스타일 측정 :
stylometry 라이브러리를 사용할 수 있습니다.from stylometry import extract_features; features = extract_features(generated_paraphrases)이러한 평가 메트릭을 Axolotl 파이프 라인에 통합하려면 다음을 수행하십시오.
대상 저자의 작품에서 단락 데이터 세트를 만들어 교육 및 검증 세트로 나누어 교육 데이터를 준비하십시오.
앞에서 논의한 접근 방식에 따라 교육 세트를 사용하여 언어 모델을 미세 조정하십시오.
미세 조정 된 모델을 사용하여 검증 세트에서 단락에 대한 문단을 생성합니다.
각 라이브러리 ( sacrebleu , rouge , stylometry )를 사용하여 평가 메트릭을 구현하고 생성 된 각각의 역설에 대한 점수를 계산하십시오.
인간 평가자의 등급과 피드백을 수집하여 인간 평가를 수행하십시오.
평가 결과를 분석하여 생성 된 도구의 품질과 스타일을 평가하고 미세 조정 프로세스를 개선하기위한 정보에 근거한 결정을 내립니다.
다음은 이러한 메트릭을 파이프 라인에 통합하는 방법의 예입니다.
from sacrebleu import corpus_bleu
from rouge import Rouge
from stylometry import extract_features
# Fine-tune the model using the training set
fine_tuned_model = train_model ( training_data )
# Generate paraphrases for the validation set
generated_paraphrases = generate_paraphrases ( fine_tuned_model , validation_data )
# Calculate evaluation metrics
bleu_score = corpus_bleu ( generated_paraphrases , [ original_paragraphs ])
rouge = Rouge ()
rouge_scores = rouge . get_scores ( generated_paraphrases , original_paragraphs )
perplexity = fine_tuned_model . perplexity ( generated_paraphrases )
stylometric_features = extract_features ( generated_paraphrases )
# Perform human evaluation
human_scores = collect_human_evaluations ( generated_paraphrases )
# Analyze and interpret the results
analyze_results ( bleu_score , rouge_scores , perplexity , stylometric_features , human_scores )필요한 라이브러리 (Sacrebleu, Rouge, stylmetry)를 설치하고 Axolotl 또는 이와 유사한 구현에 맞게 코드를 조정해야합니다.
이 실험에서는 자세한 프롬프트를 기반으로 1500 단어 텍스트를 생성 할 때 다양한 AI 모델 간의 기능과 차이점을 탐색했습니다. LM Studio의 https://chat.lmsys.org/, Chatgpt4, Claude 3 Opus 및 일부 지역 모델에서 모델을 테스트했습니다. 각 모델은 출력의 변동성을 관찰하기 위해 텍스트를 세 번 생성했습니다. 또한 각 모델의 첫 번째 반복 작성을 평가할 별도의 프롬프트를 만들었고 Chatgpt 4와 Claude Opus 3에게 피드백을 제공하도록 요청했습니다.
이 과정을 통해 일부 모델은 실행 사이에 더 높은 변동성을 나타내며 다른 모델은 비슷한 문구를 사용하는 경향이 있음을 관찰했습니다. 생성 된 단어 수와 각 모델에서 생성 된 대화의 양, 설명 및 단락의 양에는 상당한 차이가있었습니다. 평가 피드백은 Chatgpt가보다 "정제 된"산문을 제안하는 반면, Claude는 보라색 산문을 덜 권장합니다. 이러한 결과를 바탕으로, 나는 정밀, 다양한 문장 구조, 강한 동사, 판타지 주제에 대한 독특한 비틀기, 일관된 톤, 독특한 내레이터 음성 및 참여 페이싱에 중점을 둔 다음 프롬프트에 통합 할 테이크 아웃 목록을 편집했습니다. 고려해야 할 또 다른 기술은 피드백을 요청한 다음 해당 피드백을 기반으로 텍스트를 다시 작성하는 것입니다.
저는 각 모델에 대한 프롬프트를 더 미세 조정하고 창의적인 작문 작업에서 기능을 탐색하기 위해 다른 사람들과 협력 할 수 있습니다.
모델에는 고유 한 형식 바이어스가 있습니다. 일부 모델은 목록의 하이픈을 선호하고 다른 모델은 별표를 선호합니다. 이 모델을 사용할 때는 일관된 출력에 대한 선호도를 반영하는 것이 도움이됩니다.
형식 경향 :
Llama 3은 대담한 제목과 별표가있는 목록을 선호합니다.
예 : 대담한 타이틀 케이스 제목
두 개의 신약 후 별표가있는 항목을 나열하십시오
하나의 Newline으로 분리 된 항목을 나열합니다
다음 목록
더 많은 목록 항목
등...
소수의 예제 :
시스템 프롬프트 준수 :
컨텍스트 창 :
검열:
지능:
일관성:
목록 및 서식 :
채팅 설정 :
파이프 라인 설정 :
Llama 3은 유연하고 지능적이지만 상황과 인용 한계가 있습니다. 그에 따라 프롬프트 방법을 조정하십시오.
모든 의견을 환영합니다. 버그를 찾거나 개선을위한 권장 사항이있는 경우 문제를 열거나 풀 요청을 보내십시오.
이 프로젝트는 다음과 같이 라이센스가 부여됩니다. Attribution-noncommercial-Noderivatives (By-NC-ND) 라이센스 참조 : https://creativecommons.org/licenses/by-nc-nd/4.0/deed.en


