awesome RLHF
1.0.0
이것은 인간 피드백 (RLHF)을 사용한 강화 학습을 위한 연구 논문의 모음입니다. RLHF의 프론티어를 추적하기 위해 저장소가 지속적으로 업데이트됩니다.
팔로우하고 스타에 오신 것을 환영합니다!
굉장한 RLHF (인간 피드백이 포함 된 RL)
2024
2023
2022
2021
2020 년과 그 이전
상해
목차
RLHF의 개요
서류
코드베이스
데이터 세트
블로그
다른 언어 지원
기여
특허
RLHF의 아이디어는 강화 학습의 방법을 사용하여 인간의 피드백으로 언어 모델을 직접 최적화하는 것입니다. RLHF는 언어 모델이 일반적인 텍스트 데이터에 대한 교육을받은 모델을 복잡한 인간 가치의 모델에 맞게 정렬 할 수있게 해주었다.
대형 언어 모델 용 RLHF (LLM)
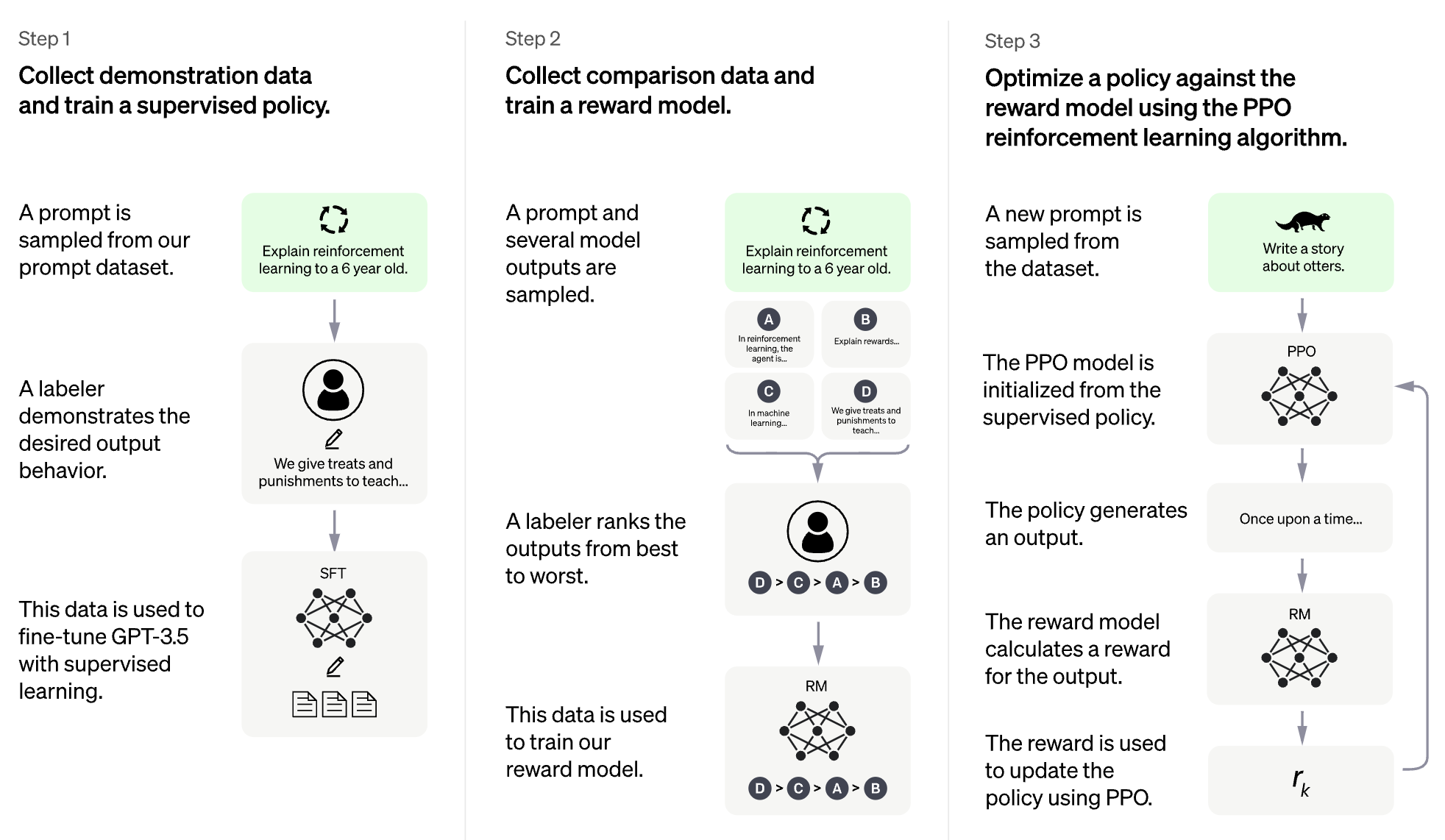
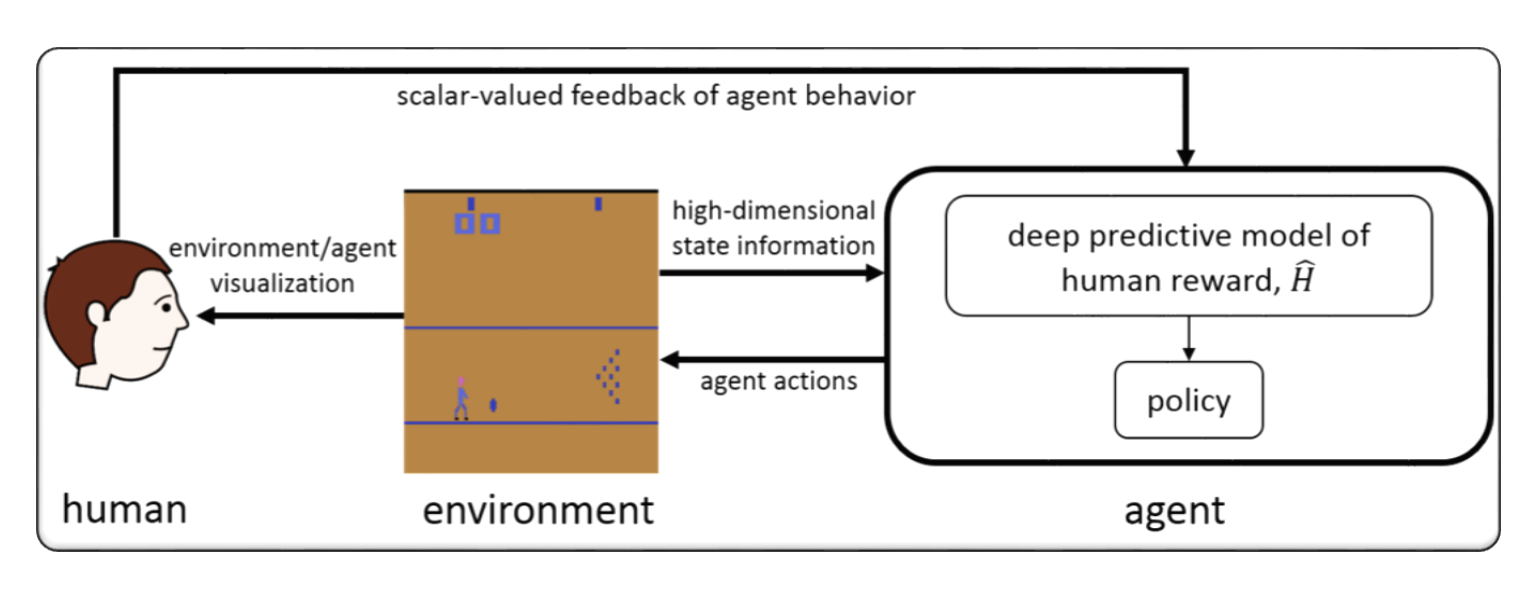
비디오 게임을위한 RLHF (예 : atari)
(다음 섹션은 Chatgpt에 의해 자동으로 생성되었습니다)
RLHF는 일반적으로 "인간 피드백을 사용한 강화 학습"을 나타냅니다. 강화 학습 (RL)은 환경의 피드백을 기반으로 결정을 내리기 위해 에이전트를 훈련시키는 기계 학습 유형입니다. RLHF에서, 에이전트는 또한 인간으로부터 등급 또는 행동에 대한 평가 형태로 피드백을 받으므로 더 빠르고 정확하게 배우는 데 도움이 될 수 있습니다.
RLHF는 인공 지능 분야의 활발한 연구 분야이며 로봇 공학, 게임 및 개인화 된 권장 시스템과 같은 분야의 응용 프로그램이 있습니다. 에이전트가 환경에서 피드백에 대한 액세스 권한을 제한하고 성능을 향상시키기 위해 인간의 의견이 필요한 시나리오에서 RL의 문제를 해결하려고합니다.
인간 피드백 (RLHF)을 통한 강화 학습 (RLHF)은 인공 지능에 대한 빠르게 발전하는 연구 분야이며, RLHF 시스템의 성능을 향상시키기 위해 개발 된 몇 가지 고급 기술이 있습니다. 몇 가지 예는 다음과 같습니다.
Inverse Reinforcement Learning (IRL) : IRL은 미리 정의 된 보상 기능에 의존하기보다는 에이전트가 인간 피드백에서 보상 기능을 배울 수있는 기술입니다. 이를 통해 에이전트는 원하는 행동의 데모와 같은보다 복잡한 피드백 신호에서 배울 수 있습니다.
Apprenticeship Learning : 견습생 학습은 IRL과 감독 된 학습을 결합하여 에이전트가 인간의 피드백과 전문가 시연을 통해 배울 수있는 기술입니다. 이를 통해 에이전트는 긍정적 인 피드백과 부정적인 피드백을 통해 배울 수 있으므로 에이전트가 더 빠르고 효과적으로 학습하는 데 도움이 될 수 있습니다.
Interactive Machine Learning (IML) : IML은 에이전트와 휴먼 전문가 간의 능동적 상호 작용을 포함하는 기술로, 전문가는 에이전트의 행동에 대한 피드백을 실시간으로 제공 할 수 있습니다. 이는 학습 과정의 각 단계에서 행동에 대한 피드백을받을 수 있으므로 에이전트가보다 빠르고 효율적으로 학습하는 데 도움이 될 수 있습니다.
Human-in-the-Loop Reinforcement Learning (HITLRL) : Hitlrl은 보상 형성, 행동 선택 및 정책 최적화와 같은 여러 수준에서 인간 피드백을 RL 프로세스에 통합하는 기술입니다. 이는 인간과 기계의 강점을 활용하여 RLHF 시스템의 효율성과 효과를 향상시키는 데 도움이 될 수 있습니다.
다음은 인간 피드백 (RLHF)을 통한 강화 학습의 몇 가지 예입니다.
Game Playing : 게임 재생에서 인간 피드백은 에이전트가 다른 게임 시나리오에서 효과적인 전략과 전술을 학습하는 데 도움이 될 수 있습니다. 예를 들어, 인기있는 GO 게임에서 인간 전문가는 상담원에게 움직임에 대한 피드백을 제공하여 게임 플레이와 의사 결정을 향상시킬 수 있습니다.
Personalized Recommendation Systems : 권장 시스템에서 인간 피드백은 에이전트가 개별 사용자의 선호도를 배우도록 도와 주어 개인화 된 권장 사항을 제공 할 수 있습니다. 예를 들어, 에이전트는 권장 제품의 사용자의 피드백을 사용하여 가장 중요한 기능을 배울 수 있습니다.
Robotics : 로봇 공학에서 인간의 피드백은 에이전트가 안전하고 효율적인 방식으로 물리적 환경과 상호 작용하는 방법을 배우는 데 도움이 될 수 있습니다. 예를 들어, 로봇은 최상의 경로에서 인간 운영자의 피드백을 통해 새로운 환경을보다 빠르게 탐색하는 법을 배울 수 있습니다.
Education : 교육에서 인간의 피드백은 에이전트가 학생들이 학생들을보다 효과적으로 가르치는 방법을 배우도록 도울 수 있습니다. 예를 들어, AI 기반 교사는 교사의 피드백을 다른 학생들과 다른 학생들과 가장 잘 작동하는 교사의 피드백을 사용할 수있어 학습 경험을 개인화하는 데 도움이됩니다.
format: - [title](paper link) [links] - author1, author2, and author3... - publisher - keyword - code - experiment environments and datasets
Hybridflow : 유연하고 효율적인 RLHF 프레임 워크
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu
키워드 : 유연하고 효율적인 RLHF 프레임 워크
코드 : 공식
알람 : 계층 적 보상 모델링을 통해 언어 모델을 정렬합니다
Yuhang Lai, Siyuan Wang, Shujun Liu, Xuanjing Huang, Zhongyu Wei
키워드 : 계층 적 보상, 오픈 텍스트 생성 작업
코드 : 공식
TLCR : 인간 피드백으로부터 세밀한 강화 학습을위한 토큰 수준의 지속적인 보상
Eunseop Yoon, Hee Suk Yoon, Soohwan Eom, Gunsoo Han, Daniel Wontae Nam, Daejin Jo, Kyoung-Woon, Mark A. Hasegawa-Johnson, Sungwoong Kim, Chang D. Yoo
키워드 : 토큰 수준의 연속 보상, RLHF
코드 : 공식
대규모 멀티 모달 모델을 RLHF를 실제로 증강시키는 것과 정렬합니다
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming Yang, Kurt Keutzer, Trevor Darrell
키워드 : RLHF, 비전 및 언어, 인적 선호도 데이터 세트의 사실상 증강
코드 : 공식
자체 보상 대조적 인 신속 증류를 통한 직접 대형 언어 모델 정렬
Aiwei Liu, Haoping Bai, Zhiyun Lu, Xiang Kong, Simon Wang, Jiulong Shan, Meng Cao, Lijie Wen
키워드 : 사람의 선호 데이터가 없으면 자기 보상, DPO
코드 : 공식
다양한 사용자 선호도를위한 LLM의 산술 제어 : 다목적 보상과 방향 선호도 정렬
Haoxiang Wang, Yong Lin, Wei Xiong, Rui Yang, Shizhe Diao, Shuang Qiu, Han Zhao, Tong Zhang
키워드 : 사용자 선호도, 다목적 보상 모델, 거부 샘플링 결합
코드 : 공식
기본 사항으로 돌아 가기 : LLM에서 인간 피드백에서 학습을위한 강화 스타일 최적화 재 방문
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet üstün, Sara Hooker
키워드 : 온라인 RL 최적화, 낮은 계산 비용
코드 : 공식
최소한 편집 제약으로 세밀한 강화 학습을 통한 대형 언어 모델 향상
Zhipeng Chen, Kun Zhou, Wayne Xin Zhao, Junchen Wan, Fuzheng Zhang, Di Zhang, Ji-Rong Wen
키워드 : 토큰 수준의 보상, LLM
코드 : 공식
RLAIF vs. RLHF : AI 피드백으로 인간 피드백에서 강화 학습 스케일링
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Ren Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, Sushant Prakash
키워드 : AI 피드백의 RL
코드 : 공식
양감진 강화 학습 및 RLHF를위한 원칙적 페널티 기반 방법
한 젠, Zhuoran Yang, Tianyi Chen
키워드 : 바일 레벨 최적화
코드 : 공식
인간 피드백으로부터 강화 학습에서 무료로 밀도가 높은 보상
Alex James Chan, Hao Sun, Samuel Holt, Mihaela van der Schaar
키워드 : 보상 성형, RLHF
코드 : 공식
인간의 피드백으로부터 학습을 강화하기위한 최소한의 접근
Gokul Swamy, Christoph Dann, Rahul Kidambi, Steven Wu, Alekh Agarwal
키워드 : Minimax 수상자, 자체 플레이 선호도 최적화
코드 : 공식
RLHF-V : 세분화 된 교정 인간 피드백으로부터 행동 정렬을 통한 신뢰할 수있는 MLLM을 향해
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, Tat-Seng Chua
키워드 : 멀티 모달 대형 언어 모델, 환각 문제, 인간 피드백의 강화 학습
코드 : 공식
RLHF 워크 플로 : 보상 모델링에서 온라인 RLHF에 이르기까지
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, Tong Zhang
키워드 : 온라인 반복 RLHF, 선호도 모델링, 대형 언어 모델
코드 : 공식
Maxmin-RLHF : 다양한 인간 선호도와 큰 언어 모델의 공평한 정렬을 향해
Souradip Chakraborty, Jiahao Qiu, Hui Yuan, Alec Koppel, Furong Huang, Dinesh Manocha, Amrit Singh Bedi, Mengdi Wang
키워드 : 선호 분포의 혼합, Maxmin 정렬 목표
코드 : 공식
RLHF에 대한 데이터 세트 재설정 정책 최적화
Jonathan D. Chang, Wenhao Zhan, Owen Oertell, Kianté Brantley, Dipendra Misra, Jason D. Lee, Wen Sun
키워드 : 데이터 세트 정책 최적화 재설정
코드 : 공식
선호하는 텍스트-이미지 확산을 정렬하는 데 대한 조밀 한 보상보기
Shentao Yang, Tianqi Chen, Mingyuan Zhou
키워드 : 텍스트-이미지 생성을위한 RLHF, DPO의 조밀 한 보상 개선, 효율적인 정렬
코드 : 공식
자체 재생 미세 조정은 약한 언어 모델을 강력한 언어 모델로 변환합니다.
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan JI, Quanquan Gu
키워드 : 자체 플레이 미세 조정
코드 : 공식
RLHF 해독 : LLM에 대한 인간 피드백으로부터 강화 학습에 대한 비판적 분석
Shreyas Chaudhari, Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, Bruno Castro da Silva
키워드 : RLHF, oracular 보상, 보상 모델 분석, 설문 조사
확산 모델에 대한 보상 과잉 최적화에 직면 : 유도 및 우선 순위 편견의 관점
Ziyi Zhang, Sen Zhang, Yibing Zhan, Yong Luo, Yonggang Wen, Dacheng Tao
키워드 : 확산 모델, 정렬, 강화 학습, RLHF, 과도한 최적화 보상, 우선 순위 편견
코드 : 공식
큰 언어 모델 정렬의 다각화 된 선호도에
Dun Zeng, Yong Dai, Pengyu Cheng, Tianhao Hu, Wanshun Chen, Nan Du, Zenglin Xu
키워드 : 공유 선호도 정렬, 보상 모델링 메트릭, LLM
코드 : 공식
배포 선호도 보상 모델링을 통해 군중 피드백을 조정합니다
Dexun Li, Cong Zhang, Kuicai Dong, Derrick Goh Xin Deik, Ruiming Tang, Yong Liu
키워드 : RLHF, 기본 설정 분포, 정렬, LLM
일방성에 맞는 정렬을 넘어서 : 다목적 직접 선호도 최적화
Zhanhui Zhou, Jie Liu, Chao Yang, Jing Shao, Yu Liu, Xiangyu Yue, Wanli Ouyang, Yu Qiao
키워드 : 보상 모델링이없는 다목적 RLHF, DPO
코드 : 공식
에뮬레이션 분리 : 대형 언어 모델의 안전 정렬은 역효과를 낳을 수 있습니다!
Zhanhui Zhou, Jie Liu, Zhichen Dong, Jiaheng Liu, Chao Yang, Wanli Ouyang, Yu Qiao
키워드 : LLM 추론 시간 공격, DPO, 교육없이 유해한 LLM 생산
코드 : 공식
일반적인 KL- 규제 선호에 따라 인간 피드백으로부터 내쉬 학습에 대한 이론적 분석
Chenlu Ye, Wei Xiong, Yuheng Zhang, Nan Jiang, Tong Zhang
키워드 : 게임 기반 RLHF, 내쉬 학습, 보상 모델이없는 Oracle의 정렬
RLHF의 정렬 세금 완화
Yong Lin, Hangyu Lin, Wei Xiong, Shizhe Diao, Jianmeng Liu, Jipeng Zhang, Rui Pan, Haoxiang Wang, Wenbin Hu, Hanning Zhang, Hanze Dong, Renjie Pi, Han Zhao, Nan Jiang, Heng Ji, Yuan Yao, Tong Zhang
키워드 : RLHF, 정렬 세, 치명적인 잊어 버린
강화 학습을 가진 확산 모델
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, Sergey Levine
키워드 : 강화 학습, RLHF, 확산 모델
코드 : 공식
AlignDiff : 행동에시기 가능한 확산 모델을 통해 다양한 인간 선호도를 정렬합니다
Zibin Dong, Yifu Yuan, Jianye Hao, Fei Ni, Yao Mu, Yan Zheng, Yujing Hu, Tangjie LV, Changjie Fan, Zhipeng Hu
키워드 : 강화 학습; 확산 모델; RLHF; 선호도 정렬
코드 : 공식
인간 피드백으로부터 강화 학습에서 무료로 밀도가 높은 보상
Alex J. Chan, Hao Sun, Samuel Holt, Mihaela van der Schaar
키워드 : RLHF
코드 : 공식
대형 언어 모델을 정렬하기위한 보상을 변환하고 결합합니다
Zihao Wang, Chirag Nagpal, Jonathan Berant, Jacob Eisenstein, Alex D 'Amour, Sanmi Koyejo, Victor Veitch
키워드 : RLHF, 정렬, LLM
인간의 피드백으로부터의 매개 변수 효율적인 강화 학습
Hakim Sidahmed, Samrat Phatale, Alex Hutcheson, Zhuonan Lin, Zhang Chen, Zac Yu, Jarvis Jin, Simral Chaudhary, Roman Komarytsia, Christiane Ahlheim, Yonghao Zhu, Bowen Li, Saravanan Ganesh, Bill Byrne, Jessica Hoffmann, Hassan Mansoor, Wei , Abhinav Rastogi, Lucas Dixon
키워드 : RLHF, 매개 변수 효율적인 방법, 낮은 계산 비용, LLM, VLM
효율적인 보상 모델 앙상블로 인간 피드백에서 강화 학습 개선
Shun Zhang, Zhenfang Chen, Sunli Chen, Yikang Shen, Zhiqing Sun, Chuang Gan
키워드 : RLHF, 보상 앙상블, 효율적인 앙상블 방법
인간의 선호에서 학습을 이해하는 일반적인 이론적 패러다임
Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, Rémi Munos
키워드 : RLHF, 쌍별 선호도
세밀한 인간 피드백은 언어 모델 훈련에 더 나은 보상을 제공합니다.
Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A. Smith, Mari Ostendorf, Hannaneh Hajishirzi
키워드 : RLHF, 문장 수준 보상, LLM
코드 : 공식
언어 모델 미세 조정에 대한 기본 설정 토큰 수준의 지침
Shentao Yang, Shujian Zhang, Congying Xia, Yihao Feng, Caiming Xiong, Mingyuan Zhou
키워드 : RLHF, 토큰 수준의 교육 지침, 대체/온라인 교육 프레임 워크, 미니멀리스트 교육 목표
코드 : 공식
환상적인 보상과 길들이기 방법 : 작업 중심 대화 시스템에 대한 보상 학습에 대한 사례 연구
Yihao Feng*, Shentao Yang*, Shujian Zhang, Jianguo Zhang, Caiming Xiong, Mingyuan Zhou, Huan Wang
키워드 : RLHF, 유전자화 보상 기능 학습, 보상 기능 활용, 작업 중심 대화 시스템, 학습 대행
코드 : 공식
역 선호도 학습 : 보상 기능이없는 선호도 기반 RL
Joey Hejna, Dorsa Sadigh
키워드 : 보상 모델이없는 역 선호도 학습
코드 : 공식
Alpacafarm : 인간 피드백에서 배우는 방법을위한 시뮬레이션 프레임 워크
Yann Dubois, Chen Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Geestrin, Percy S. Liang, Tatsunori B. Hashimoto
키워드 : RLHF, 시뮬레이션 프레임 워크
코드 : 공식
인간 정렬에 대한 선호도 순위 최적화
Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, Houfeng Wang
키워드 : 기본 설정 순위 최적화
코드 : 공식
적대적 선호도 최적화
Pengyu Cheng, Yifan Yang, Jian Li, Yong Dai, Nan du
키워드 : RLHF, 간, 적대 게임
코드 : 공식
인간 피드백에서 반복적 인 선호 학습 : KL-Constraint 하의 RLHF에 대한 이론 및 실습 브리징 이론 및 실습
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
키워드 : RLHF, 반복 DPO, 수학적 기초
적극적인 탐사를 통한 인간 피드백에서 샘플 효율적인 강화 학습
Viraj Mehta, Vikramjeet Das, Ojash Neopane, Yijia Dai, Ilija Bogunovic, Jeff Schneider, Willie Neiswanger
키워드 : RLHF, 샘플 효율성, 탐색
통계적 피드백으로부터 강화 학습 : AB 테스트에서 개미 테스트까지의 여정
Feiyang Han, Yimin Wei, Zhaofeng Liu, Yanxing Qi
키워드 : RLHF, AB 테스트, RLSF
유통 시프닝 하에서 재단 모델을 정확하게 분석하는 보상 모델의 기준 분석
Ben Pikus, Will Levine, Tony Chen, Sean Hendryx
키워드 : RLHF, OOD, 배포 전환
자연 언어를 통한 인간 피드백과 큰 언어 모델의 데이터 효율적인 정렬
Di Jin, Shikib Mehri, Devamanyu Hazarika, Aishwarya Padmakumar, Sungjin Lee, Yang Liu, Mahdi Namazifar
키워드 : RLHF, 데이터 효율적, 정렬
단계별로 강화합시다
Sarah Pan, Vladislav Lialin, Sherin Muckatira, Anna Rumshisky
키워드 : RLHF, 추론
보상 모델링없이 직접 선호도 기반 정책 최적화
Gaon An, Junhyeok Lee, Xingdong Zuo, Norio Kosaka, Kyung-Min Kim, Hyun Oh Song
키워드 : 보상 모델링, 대조 학습, 오프라인 정유 학습이없는 RLHF
AlignDiff : 행동에시기 가능한 확산 모델을 통해 다양한 인간 선호도를 정렬합니다
Zibin Dong, Yifu Yuan, Jianye Hao, Fei Ni, Yao Mu, Yan Zheng, Yujing Hu, Tangjie LV, Changjie Fan, Zhipeng Hu
키워드 : RLHF, 정렬, 확산 모델
유레카 : 대형 언어 모델을 코딩하여 인간 수준의 보상 설계
Yecheng Jason MA, William Liang, Guanzhi Wang, De-an Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi 팬, Annandkumar
키워드 : LLM 기반, 보상 기능 디자인
안전한 RLHF : 인간 피드백으로부터 안전한 강화 학습
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiagming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, Yaodong Yang
키워드 : Sale RL, LLM Fine-Ture
인간의 피드백을 통한 품질 다양성
Li Ding, Jenny Zhang, Jeff Clune, Lee Spector, Joel Lehman
키워드 : 품질 다양성, 확산 모델
Remax : 대형 언어 모델을 조정하기위한 간단하고 효과적이며 효율적인 강화 학습 방법
Ziniu Li, Tian Xu, Yushun Zhang, Yang Yu, Ruoyu Sun, Zhi-Quan Luo
키워드 : 계산 효율, 분산 감소 기술
작업 보상으로 컴퓨터 비전 모델을 조정합니다
André Susano Pinto, Alexander Kolesnikov, Yuge Shi, Lucas Beyer, Xiaohua Zhai
키워드 : 컴퓨터 비전의 보상 튜닝
후시의 지혜는 언어 모델을 더 나은 교육 추종자로 만듭니다.
Tianjun Zhang, Fangchen Liu, Justin Wong, Pieter Abbeel, Joseph E. Gonzalez
키워드 : Hindsight Instruction Relabeling, RLHF 시스템, 가치 네트워크 필요 없음
코드 : 공식
인간 -AI 조정을위한 언어가 강화 학습을 지시했습니다
Hengyuan Hu, Dorsa Sadigh
키워드 : 인간 -AI 조정, 인간 선호도 정렬, 지시 조건 RL
인간 피드백에서 오프라인 강화 학습과 언어 모델을 정렬
Jian Hu, Li Tao, June Yang, Chandler Zhou
키워드 : 의사 결정 변압기 기반 정렬, 오프라인 강화 학습, RLHF 시스템
인간 정렬에 대한 선호도 순위 최적화
Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li 및 Houfeng Wang
키워드 : 감독 된 인간 선호도 정렬, 선호도 순위 확장
코드 : 공식
차이 브리징 : 자연 언어 생성에 대한 (인간) 피드백 통합에 대한 설문 조사
Patrick Fernandes, Aman Madaan, Emmy Liu, António Farinhas, Pedro Henrique Martins, Amanda Bertsch, José GC de Souza, Shuyan Zhou, Tongshuang Wu, Graham Neubig, André FT Martins
키워드 : 자연 언어 생성, 인간 피드백 통합, 피드백 공식화 및 분류, AI 피드백 및 원칙 기반 판단
GPT-4 기술 보고서
Openai
키워드 : 대규모, 멀티 모달 모델, 변압기 기반 모델, 미세 조정 중고 RLHF
코드 : 공식
데이터 세트 : Drop, Winogrande, Hellaswag, Arc, Humaneval, GSM8K, MMLU, Pruthfulqa
RAFT : Generative Foundation 모델 정렬에 대한 보상 순위
Hanze Dong, Wei Xiong, Deepanshu Goyal, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, Tong Zhang
키워드 : 거부 샘플링 Finetuning, PPO 대안, 확산 모델
코드 : 공식
RRHF : 눈물없이 인간 피드백으로 언어 모델을 조정하는 응답 순위
Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, Fei Huang
키워드 : RLHF의 새로운 패러다임
코드 : 공식
인간-루프 RL에 대한 소수의 선호 학습
Joey Hejna, Dorsa Sadigh
키워드 : 선호도 학습, 대화식 학습, 멀티 태스킹 학습, 인간-루프 RL을 보면 사용 가능한 데이터 풀 확장
코드 : 공식
인간 선호도와 텍스트 대상 모델을 더 잘 정렬합니다
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, Hongsheng Li
키워드 : 확산 모델, 텍스트-이미지, 미학
코드 : 공식
Imagereward : 텍스트 대상 생성에 대한 인간 선호도를 배우고 평가합니다
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, Yuxiao Dong
키워드 : 일반 목적 텍스트-이미지 인간 선호 RM, 텍스트-이미지 생성 모델 평가
코드 : 공식
데이터 세트 : Coco, DiffusionDB
인간 피드백을 사용하여 텍스트-이미지 모델을 정렬합니다
Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Shixiang Shane Gu
키워드 : 텍스트-이미지, 안정적인 확산 모델, 인간 피드백을 예측하는 보상 기능
Visual Chatgpt : Visual Foundation 모델로 말하기, 그리기 및 편집
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan
키워드 : Visual Foundation 모델, Visual Chatgpt
코드 : 공식
인간 선호도 (PHF)를 가진 사전 여지가있는 언어 모델
Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Bhalerao, Christopher L. Buckley, Jason Phang, Samuel R. Bowman, Ethan Perez
키워드 : 사전 여지, 오프라인 RL, 의사 결정 변압기
코드 : 공식
F-Divergence Minimization (F-DPG)을 통한 선호도와 언어 모델 정렬
Dongyoung Go, Tomasz Korbak, Germán Kruszewski, Jos Rozen, Nahyeon Ryu, Marc Dymetman
키워드 : F-Divergence, KL 처벌이있는 RL
쌍별 또는 k-wise 비교에서 인간 피드백을 가진 원칙 강화 학습
Banghua Zhu, Jiantao Jiao, Michael I. Jordan
키워드 : 비관적 MLE, Max-Entropy IRL
큰 언어 모델에서 도덕적 자기 교정 능력
인류
키워드 : RLHF 교육을 늘려서 도덕적 자기 교정 능력을 향상시킵니다
데이터 세트; 바베큐
자연 언어 처리를위한 강화 학습 (Not)?
Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté, Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, Yejin Choi
키워드 : RL, 벤치 마크, 수행자 RL 알고리즘으로 언어 생성기 최적화
코드 : 공식
데이터 세트 : IMDB, Commongen, CNN Daily Mail, Totto, WMT-16 (en-de), NarrativeQa, DailyDialog
보상 모델과 최적화를위한 법률 스케일링
Leo Gao, John Schulman, Jacob Hilton
키워드 : Gold Reward Model Train 프록시 보상 모델, 데이터 세트 크기, 정책 매개 변수 크기, BON, PPO
대상 인간 판단 (Sparrow)을 통한 대화 에이전트의 정렬 개선
Amelia Glaese, Nat McAleese, Maja Trębacz 등.
키워드 : 정보를 찾는 대화 에이전트, 좋은 대화를 자연어 규칙으로 나누고 DPC, 모델과 상호 작용하여 특정 규칙 위반을 이끌어냅니다 (Adversarial Probing)
데이터 세트 : 자연 질문, ELI5, 품질, 트리비아 카, 위노비아, 바베큐
피해를 줄이기위한 빨간 팀 언어 모델 : 방법, 스케일링 행동 및 배운 교훈
Deep Ganguli, Liane Lovitt, Jackson Kernion 등.
키워드 : 빨간색 팀 언어 모델, 스케일링 동작 조사, 팀 구성 데이터 세트 읽기
코드 : 공식
강화 학습을 사용한 개방형 대화의 동적 계획
데보라 코헨, 문키
키워드 : 실시간, 개방형 대화 시스템은 언어 모델, CAQL, CQL, Bert에 의한 대화 상태의 간결한 내부를 짝을 이룹니다.
Quark : 강화 된 실험으로 제어 가능한 텍스트 생성
Ximing Lu, Sean Welleck, Jack Hessel, Liwei Jiang, Lianhui Qin, Peter West, Prithviraj Ammanabrolu, Yejin Choi
키워드 :하지 말아야 할 신호에 대한 언어 모델 미세 조정, 의사 결정 변압기, PPO를 사용한 LLM 튜닝
코드 : 공식
데이터 세트 : WritingPrompts, SST-2, Wikitext-103
인간 피드백으로부터 강화 학습을 통해 도움이되고 무해한 조수 교육
Yuntao Bai, Andy Jones, Kamal Ndousse 등.
키워드 : 무해한 조수, 온라인 모드, RLHF 교육의 견고성, OOD 탐지.
코드 : 공식
데이터 세트 : Triviaqa, Hellaswag, Arc, OpenBookqa, Lambada, Humaneval, Mmlu, Pruthfulqa
검증 된 인용문 (Gophercite)으로 답변을 지원하기위한 언어 모델 교육
Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, Nat Mcaleese
키워드 : 구체적인 증거를 인용하는 답변을 생성하고 확실하지 않은 경우 답변을 삼가십시오.
데이터 세트 : 자연 질문, ELI5, 품질, 진실한 QA
인간 피드백 (instructgpt)으로 지침을 따르는 언어 모델 교육
Long Ouyang, Jeff Wu, Xu Jiang 등
키워드 : 대형 언어 모델, 인간 의도와 언어 모델을 정렬
코드 : 공식
데이터 세트 : PruryfulQa, RealToxicityPrompts
헌법 AI : AI 피드백의 무해함
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion 등.
키워드 : AI 피드백 (RLAIF)의 RL, 자기 개선, 사슬의 사슬 스타일, AI 동작을보다 정확하게 통제하여 무해한 AI 조수 훈련
코드 : 공식
모델 작성된 평가를 통해 언어 모델 동작 발견
Ethan Perez, Sam Ringer, Kamilė Lukošiūtė, Karina Nguyen, Edwin Chen 등.
키워드 : LMS로 평가를 자동으로 생성하고 RLHF가 더 많아지면 LMS가 더 악화되고 LM 작성된 평가는 고품질입니다.
코드 : 공식
데이터 세트 : BBQ, Winogender Schemas
해석 가능한 다중 인스턴스 학습을 통한 궤적 라벨에서 비마르코르어 보상 모델링
조셉 일찍, Tom Bewley, Christine Evers, Sarvapali Ramchurn
키워드 : 보상 모델링 (RLHF), 비 마르 코비안, 다중 인스턴스 학습, 해석 가능성
코드 : 공식
WebGpt : 인간 피드백을 가진 브라우저 지원 질문-응답 (webgpt)
Reiichiro Nakano, Jacob Hilton, Suchir Balaji 등.
키워드 : 모델 검색 웹을 검색하고 참조, 모방 학습, BC, 긴 양식 질문 제공
데이터 세트 : Eli5, Triviaqa, Pruthfulqa
인간의 피드백으로 책을 재귀 적으로 요약합니다
Jeff Wu, Long Ouyang, Daniel M. Ziegler, Nisan Stiennon, Ryan Lowe, Jan Leike, Paul Christiano
키워드 : 인간이 더 넓은 과제를 평가하는 데 도움이되는 작은 작업에 대한 교육을받은 모델, BC
데이터 세트 : Booksum, NarrativeQa
신경 기계 번역을위한 강화 학습의 약점 재 방문
Samuel Kiegeland, Julia Kreutzer
키워드 : 정책 그라디언트의 성공은 출력 분포, 기계 번역, NMT, 도메인 적응의 모양보다는 보상 때문입니다.
코드 : 공식
데이터 세트 : WMT15, IWSLT14
인간의 피드백에서 요약하는 법을 배웁니다
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, Paul Christiano
키워드 : 요약 품질, 훈련 손실에 대한 관리 모델 동작, 보상 모델은 새로운 데이터 세트에 일반화됩니다.
코드 : 공식
데이터 세트 : TL; DR, CNN/DM
인간의 선호에서 미세 조정 언어 모델
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving
키워드 : 언어에 대한 보상, 긍정적 인 감정, 요약 과제, 물리적 설명
코드 : 공식
데이터 세트 : TL; DR, CNN/DM
보상 모델링을 통한 확장 가능한 에이전트 정렬 : 연구 방향
Jan Leike, David Krueger, Tom Everitt, Miljan Martic, Vishal Maini, Shane Legg
키워드 : 에이전트 정렬 문제, 상호 작용에서 보상 배우기, RL로 보상 최적화, 재귀 보상 모델링
코드 : 공식
Env : Atari
Atari의 인간의 선호와 시위에서 학습을 보상합니다
Borja Ibarz, Jan Leike, Tobias Pohlen, Geoffrey Irving, Shane Legg, Dario Amodei
키워드 : 전문가 데모 궤적 환경 설정 보상 해킹 문제, 인간 레이블의 소음
코드 : 공식
Env : Atari
딥 테이머 : 고차원 상태 공간에서 대화식 에이전트 형성
개렛 워 넬, 니콜라스 웨이 토치, 버논 로너, 피터 스톤
키워드 : 높은 차원 상태, 인간 트레이너의 입력을 활용
코드 : 제 3 자
Env : Atari
인간의 선호에서 깊은 강화 학습
Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, Dario Amodei
키워드 : 궤적 분할 쌍 간의 인적 선호도에서 정의 된 목표 탐색, 인간 피드백보다 더 복잡한 것을 배우십시오.
코드 : 공식
Env : Atari, Mujoco
정책 의존적 인간 피드백으로부터의 대화식 학습
James MacGlashan, Mark K Ho, Robert Loftin, Bei Peng, Guan Wang, David Roberts, Matthew E. Taylor, Michael L. Littman
키워드 : 결정은 인간의 피드백보다는 현재 정책의 영향을 받고, 지역 최적으로 수렴하는 정책 의존 피드백에서 배우십시오.
format: - [title](codebase link) [links] - author1, author2, and author3... - keyword - experiment environments, datasets or tasks
Verl : LLM을위한 화산 엔진 강화 학습
Bytedance Seed MLSYS 팀 및 HKU : Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu
키워드 : 유연하고 효율적인 RLHF 프레임 워크
작업 : RLHF, 수학 및 코드를 포함한 추론 작업.
Openrlhf
Openrlhf
키워드 : 70b, RLHF, DeepSpeed, Ray, Vllm
작업 : 사용하기 쉽고 확장 가능하며 고성능 RLHF 프레임 워크 (지원 70B+ Full Tuning & LORA & Mixtral & KTO).
팜 + rlhf -pytorch
Phil Wang, Yachine Zahidi, Ikko Eltociear Ashimine, Eric Alcaide
키워드 : 변압기, 팜 아키텍처
데이터 세트 : enwik8
LM-Human-Preferences
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving
키워드 : 언어에 대한 보상, 긍정적 인 감정, 요약 과제, 물리적 설명
데이터 세트 : TL; DR, CNN/DM
후속 조명-인간 피드백
Long Ouyang, Jeff Wu, Xu Jiang 등
키워드 : 대형 언어 모델, 인간 의도와 언어 모델을 정렬
데이터 세트 : Pruthfulqa realToxicityPrompts
변압기 강화 학습 (TRL)
Leandro von Werra, Younes Belkada, Lewis Tunstall 등.
키워드 : RL, PPO, 변압기로 LLM을 Train
과제 : IMDB 감정
변압기 강화 학습 X (TRLX)
Jonathan Tow, Leandro von Werra 등.
키워드 : 분산 교육 프레임 워크, T5 기반 언어 모델, RL, PPO, ILQL을 사용하여 LLM을 Train LLM
작업 : 제공된 보상 기능 또는 보상 표시 데이터 세트를 사용하여 RL을 사용하여 미세 조정 LLM
RL4LMS (인간 선호도에 대한 언어 모델을 미세 조정하기위한 모듈 식 RL 라이브러리)
Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté, Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, Yejin Choi
키워드 : RL, 벤치 마크, 수행자 RL 알고리즘으로 언어 생성기 최적화
데이터 세트 : IMDB, Commongen, CNN Daily Mail, Totto, WMT-16 (en-de), NarrativeQa, DailyDialog
LAMDA-RLHF-PYTORCH
필 왕
키워드 : Lamda,주의 메커니즘
작업 : Pytorch에서 Google의 Lamda 연구 논문의 오픈 소스 사전 훈련 구현
Textrl
에릭 램
키워드 : Huggingface의 변압기
작업 : 텍스트 생성
ENV : PFRL, 체육관
minrlhf
톰 포스터
키워드 : PPO, 최소 라이브러리
과제 : 교육 목적
깊은 속도 chat
마이크로 소프트
키워드 : 저렴한 RLHF 교육
단봉 낙타
IBM
키워드 : 최소 인간 감독, 자기 정렬
과제 : 최소한의 인간 감독으로 훈련 된 자체 정렬 언어 모델
FG-RLHF
Zeqiu Wu, Yushi Hu, Weijia Shi 등.
키워드 : 세그먼트 후에 보상을 제공하는 세분화 된 RLHF, 다른 피드백 유형과 관련된 여러 RM을 통합합니다.
과제 : 밀도가 세밀한 보상 기능과 다중 RMS -Safe-RlHF로부터 훈련 및 학습을 가능하게하는 프레임 워크
Xuehai Pan, Ruiyang Sun, Jiatming Ji 등.
키워드 : 인기있는 미리 훈련 된 모델, 대규모 인간 표지 데이터 세트, 안전 제약 조건 검증을위한 다중 규모 메트릭, 맞춤형 매개 변수를 지원합니다.
작업 : 안전한 RLHF를 통한 제한된 가치 정렬 LLM
format: - [title](dataset link) [links] - author1, author2, and author3... - keyword - experiment environments or tasks
HH-RLHF
벤 만, 깊은 강
키워드 : 사람 선호도 데이터 세트, 빨간색 팀링 데이터, 기계 작성
작업 : 인간 선호도를위한 오픈 소스 데이터 세트 도움과 무해함에 대한 데이터 세트
Stanford Human Preferences 데이터 세트 (SHP)
Ethayarajh, Kawin and Zhang, Heidi and Wang, Yizhong and Jurafsky, Dan
키워드 : 자연적으로 발생하고 인간이 쓴 데이터 세트, 18 개의 다른 주제 영역
작업 : RLHF 보상 모델을 훈련시키는 데 사용됩니다.
프롬프트 소스
Stephen H. Bach, Victor Sanh, Zheng-Xin Yong et al.
키워드 : 영어 데이터 세트를 자극하고 데이터 예제를 자연 언어로 매핑
작업 : 자연어 프롬프트 생성, 공유 및 사용을위한 툴킷
구조화 된 지식 접지 (SKG) 리소스 컬렉션
Tianbao Xie, Chen Henry Wu, Peng Shi et al.
키워드 : 구조화 된 지식 접지
작업 : 데이터 세트 수집은 구조화 된 지식 근거와 관련이 있습니다.
플랜 컬렉션
Longpre Shayne, Hou Le, Vu Tu et al.
작업 : Collection은 FLAN 2021, P3, Super Natural Intructions의 데이터 세트를 컴파일합니다.
rlhf-reward-datasets
yiting xie
키워드 : 기계 작성 데이터 세트
webgpt_comparisons
Openai
키워드 : 인간이 작성한 데이터 세트, 긴 양식 질문 답변
작업 : 인간의 선호도와 일치하도록 긴 형태의 질문 응답 모델을 훈련
요약 _from_feedback
Openai
키워드 : 인간 작성 데이터 세트, 요약
작업 : 인간 선호도에 맞게 요약 모델을 훈련
dahoas/합성 강의-gptj-pairwise
Dahoas
키워드 : 인간 작성 데이터 세트, 합성 데이터 세트
안정적인 정렬 - 소셜 게임의 정렬 학습
Ruibo Liu, Ruixin (Ray) Yang, Qiang Peng
키워드 : 정렬 교육에 사용되는 상호 작용 데이터, 샌드 박스에서 실행됩니다.
작업 : 시뮬레이션 된 소셜 게임에서 기록 된 상호 작용 데이터를 훈련
리마
메타 ai
키워드 : RLHF가 없으면 신중하게 선별 된 프롬프트 및 응답이 거의 없습니다.
작업 : Lima 모델 교육에 사용되는 데이터 세트
[Openai] chatgpt : 대화를위한 언어 모델 최적화
[Hugging Face] 인간 피드백으로부터 강화 학습을 설명 (RLHF)
[Zhihu] ih Agi 之路 : 大型语言模型 (llm) 技术精要
[Zhihu] ih : 现象与解释
[Zhihu] ih hh-rlhf 数据集上的 ppo 实践
[W & B 완전히 연결된] 인간 피드백에서 강화 학습 이해 (RLHF)
[DeepMind] 인간의 피드백을 통한 학습
[개념] 深入理解语言模型的突现能力
[개념] 拆解追溯 gpt-3.5 各项能力的起源
[GIST] 언어 모델에 대한 강화 학습
[YouTube] John Schulman- 인간의 피드백으로부터의 강화 학습 : 진보와 도전
[Openai / Arrize] 인간 피드백을 가진 강화 학습에 대한 Openai
[Encord] 컴퓨터 비전을위한 인간 피드백 (RLHF)의 강화 학습 안내서
[Weixun Wang] RL (HF)+LLM의 개요
터키
우리의 목적은이 repo를 더 좋게 만드는 것입니다. 기부에 관심이 있으시면 기여 지침은 여기를 참조하십시오.
Awesome RLHF는 Apache 2.0 라이센스에 따라 릴리스됩니다.


