paper2slides
1.0.0
LLM (Large Language Models)을 사용하여 모든 ARXIV 용지를 슬라이드로 변환하십시오! 이 도구는 연구 논문의 주요 아이디어를 빠르게 파악하는 데 유용합니다.
생성 된 슬라이드의 일부 예는 Word2vec, Gan, Transformer, Vit, Chain of-Thought, Star, DPO 및 AI 과학자입니다. 데모에서 생성 된 슬라이드의 다른 많은 예를 참조하십시오.
스크립트는 인터넷 (ARXIV)에서 파일을 다운로드하고 OpenAI API에 정보를 보내고 로컬로 컴파일됩니다. 공유되는 콘텐츠와 잠재적 위험에 대해 조심하십시오. 관심있는 특정 ARXIV ID가 있고 코드를 직접 실행하고 싶지 않은 경우 "토론"에서 알려 주시면 슬라이드를 데모 목록에 추가하게되어 기쁩니다.
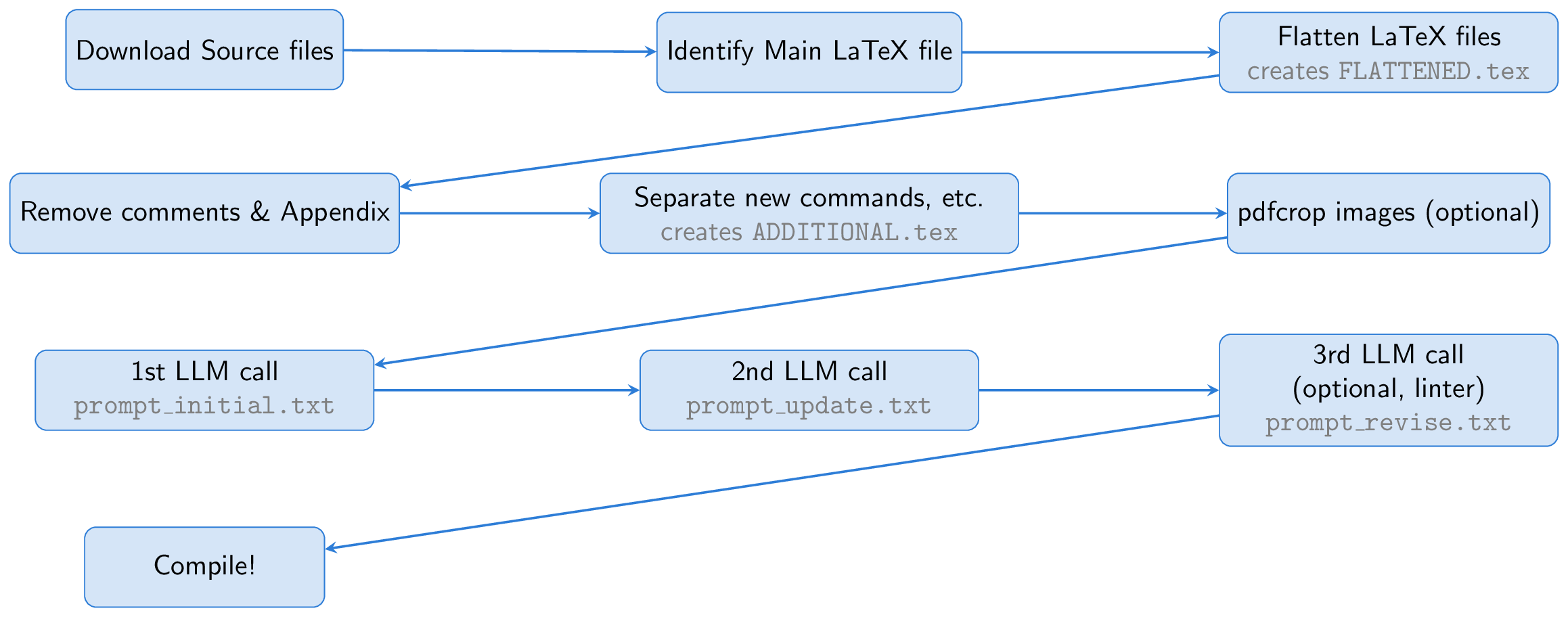
프로세스는 ARXIV 용지의 소스 파일을 다운로드하여 시작합니다. 기본 라텍스 파일이 식별되고 평평 해져 모든 입력 파일을 단일 문서 ( FLATTENED.tex )로 병합합니다. 댓글과 부록을 제거 하여이 병합 파일을 전처리합니다. 이 전처리 된 파일은 좋은 슬라이드를 생성하기위한 지침과 함께 프롬프트의 기초를 형성합니다.
한 가지 주요 아이디어는 슬라이드 생성을 위해 Beamer를 사용하여 라텍스 생태계 내에 전적으로 머무를 수 있도록하는 것입니다. 이 접근법은 본질적으로 작업을 요약 연습으로 바꿉니다. 긴 라텍스 용지를 간결한 비머 라텍스로 변환합니다. LLM은 캡션에서 그림의 내용을 유추하여 슬라이드에 포함시켜 비전 기능의 필요성을 제거 할 수 있습니다.
LLM을 돕기 위해 필요한 모든 패키지, NewCommand 정의 및 논문에 사용 된 기타 라텍스 설정이 포함 된 ADDITIONAL.tex 라는 파일을 만듭니다. 프롬프트에 input{ADDITIONAL.tex} 사용 하여이 파일을 포함 시키면 특히 많은 맞춤형 명령이있는 이론적 용지의 경우 슬라이드 생성을보다 신뢰할 수 있습니다.
LLM은 라텍스 소스에서 비머 코드를 생성하지만 첫 번째 실행에는 문제가있을 수 있으므로 LLM에 자체 정보를 제공하고 출력을 개선하도록 요청합니다. 선택적으로, 세 번째 단계는 Linter를 사용하여 생성 된 코드를 확인하는 것과 관련이 있으며, 결과는 추가 수정을 위해 LLM에 Fed Back에 Fed Back을 사용하는 것입니다 (이 Linter 단계는 AI 과학자에서 영감을 얻었습니다). 마지막으로, 비머 코드는 pdflatex를 사용하여 PDF 프레젠테이션으로 컴파일됩니다.
all.zsh 스크립트는 전체 프로세스를 자동화하며, 일반적으로 단일 용지의 경우 GPT-4O로 몇 분 이내에 완료됩니다.
요구 사항은 다음과 같습니다.
requestsarxiv 라이브러리openai 라이브러리arxiv-latex-cleaner 라이브러리pdflatex 의 작업 설치설치 단계 :
이 저장소를 복제하십시오.
git clone https://github.com/takashiishida/paper2slides.git
cd paper2slides필요한 파이썬 패키지를 설치하십시오.
pip install requests arxiv openai arxiv-latex-cleaner pdflatex 설치되어 시스템 경로에 사용 가능합니다. pdflatex test.tex 로 샘플 test.tex 컴파일 할 수 있는지 선택적으로 확인하십시오. test.pdf 올바르게 생성되었는지 확인하십시오. 선택적으로 chktex 및 pdfcrop 작동하는지 확인하십시오.
OpenAI API 키 설정 :
export OPENAI_API_KEY= ' your-api-key ' all.sh 스크립트 사용이 스크립트는 ARXIV 용지를 다운로드하여 처리하여 Beamer 프레젠테이션으로 변환하는 프로세스를 자동화합니다.
bash all.sh < arxiv_id > <arxiv_id> 원하는 ARXIV 용지 ID로 교체하십시오. ID는 URL : https://arxiv.org/abs/xxxx.xxxx 의 xxxx.xxxx 에서 식별 할 수 있습니다.
더 많은 제어를 위해 Python 스크립트를 개별적으로 실행할 수도 있습니다.
ARXIV 소스 파일을 다운로드하여 처리하십시오
python arxiv2tex.py < arxiv_id > 이 스크립트는 지정된 ARXIV 용지의 소스 파일을 다운로드하여 추출하여 기본 라텍스 파일을 처리합니다. 결과는 source/<arxiv_id>/FLATTENED.tex 및 source/<arxiv_id>/ADDITIONAL.tex 에 저장됩니다.
라텍스를 비머로 변환합니다
python tex2beamer.py --arxiv_id < arxiv_id > 이 스크립트는 처리 된 라텍스 파일을 읽고 Beamer 슬라이드를 준비합니다. 여기에서 OpenAI API를 사용하는 곳입니다. 우리는 두 번 호출하여 먼저 비머 코드를 생성 한 다음 Beamer 코드를 자체 지급합니다. 선택적으로 다음 플래그를 사용하십시오 : --use_linter 및 --use_pdfcrop . LLM에 보낸 프롬프트와 LLM의 응답은 tex2beamer.log 에 저장됩니다. Linter 로그는 source/<arxiv_id>/linter.log 에 저장됩니다.
비머를 PDF로 변환하십시오
python beamer2pdf.py < arxiv_id >이 스크립트는 Beamer 파일을 PDF 프레젠테이션으로 컴파일합니다.
프롬프트는 prompt_initial.txt , prompt_update.txt 및 prompt_revise.txt 에 저장되지만 필요에 맞게 조정하십시오. 여기에는 PLACEHOLDER_FOR_FIGURE_PATHS 라는 자리 표시자가 포함되어 있습니다. 이것은 용지에 사용 된 그림 경로로 대체됩니다. 경로가 비머 코드에서 올바르게 사용되도록하고 싶습니다. LLM은 종종 실수를 저지르기 때문에 우리는 이것을 프롬프트에 명시 적으로 포함시킵니다.
내 경험에서 성공률은 약 90 %입니다 (컴파일은 실패하거나 이미지 경로가 잘못 될 수 있습니다). 문제가 발생하거나 개선을위한 제안이 있으면 언제든지 알려주십시오!


