BRAKER
v3.0.8
다음은 Braker에 대한 첫 번째 BGA23 워크숍 세션의 녹음입니다. 비디오를 보면서 배우는 것이 쉽다면, https://www.youtube.com/watch?v=uxtkj4mukyg
Braker3는 현재 https://usegalaxy.eu/에 있습니다.
Tsebra & Braker3 관련 :
Braker & Augustus 관련 :
GeneMark 관련 :
Mark Borodovsky, Georgia, USA, [email protected]
Tomas Bruna, 미국 공동 게놈 연구소, [email protected]
Alexandre Lomsazde, 미국 조지아 테크, [email protected]
[A] Greifswald 대학교, Walther-Rathenau-Str의 수학 및 컴퓨터 과학 연구소. 47, 17489 Greifswald, 독일
[b] Greifswald 대학교, Felix-Hausdorff-Str의 미생물 기능 유전체학 센터. 17489 년 8 월 Greifswald, 독일
[C] 공동 조지아 테크 및 Emory University Wallace H Coulter Biomedical Engineering Department, 30332 Atlanta, USA
[D] 30332 미국 애틀랜타, 컴퓨터 과학 및 공학 학교
[E] 모스크바 물리 기술 연구소, 모스크바 지역 141701, Dolgoprudny, 러시아
![Braker2-Team-2 [그림 10]](https://images.downcodes.com/uploads/20250214/img_67aee79a0cb7530.png)
![Braker2-team-1 [그림 11]](https://images.downcodes.com/uploads/20250214/img_67aee79a0d1eb31.png)
![Braker2-team-3 [그림12]](https://images.downcodes.com/uploads/20250214/img_67aee79a0da9c32.png)
![Braker2-Team-4 [그림 13]](https://images.downcodes.com/uploads/20250214/img_67aee79a0e49933.png)
그림 1 : 왼쪽에서 오른쪽으로 현재 Braker 저자 : Mario Stanke, Alexandre Lomsadze, Katharina J. Hoff, Tomas Bruna, Lars Gabriel 및 Mark Borodovsky. 우리는 더 큰 과학자 커뮤니티가 Braker 코드 (예 : 풀 요청을 통한)에 기여했음을 인정합니다.
Braker1, Braker2 및 Braker3의 개발은 NIH (National Institutes of Health) [GM128145 ~ MB 및 MS]의 지원을 받았습니다. Braker3의 개발은 독일 Mecklenburg-Vorpommern 정부에 의해 KJH와 MS에 부여 된 프로젝트 데이터 역량에 의해 부분적으로 자금을 지원 받았다.
Braker (Tsebra)의 전사 선택기는 https://github.com/gaius-augustus/tsebra에서 제공됩니다.
Braker의 핵심 유전자 파인더 중 하나 인 Genemark-ETP는 https://github.com/gatech-genemark/genemark-etp에서 제공됩니다.
Braker의 핵심에서 두 번째 유전자 파인더 인 Augustus는 https://github.com/gaius-augustus/augustus에서 제공됩니다.
Miniprot 또는 Genomethreader를 사용하여 훈련 유전자를 생성하기위한 Braker 파이프 라인 스핀 오프 인 Galba는 https://github.com/gaius-augustus/galba에서 제공됩니다.
빠르게 증가하는 시퀀싱 된 게놈 수는 정확한 유전자 구조 주석을위한 완전 자동화 된 방법이 필요합니다. 이 목표를 염두에두고, 우리는 게놈 및 RNA-Seq 데이터를 사용하여 새로운 게놈에서 전체 유전자 구조 주석을 자동으로 생성하는 Genemark-ET R2 및 Augustus R3, R4 의 조합 인 Braker1 R1 R0을 개발했습니다.
그러나, 새로운 게놈에 주석을 달 때 사용할 수있는 RNA-Seq 데이터의 품질은 가변적이며 경우에 따라 RNA-Seq 데이터를 전혀 사용할 수 없습니다.
Braker2는 RNA-Seq 및/또는 단백질 상 동성 정보의 유전자 예측 도구 Genemark-ES/ET/EP/ETP R14, R17 , F1 및 Augustus의 완전 자동 교육을 허용하는 Braker1의 확장이며 RNA-Seq 및 단백질 상 동성 정보의 외적 증거는 예측 으로입니다.
단백질 상 동성 정보에 의존하는 다른 방법과는 달리, Braker2는 매우 밀접하게 관련된 종의 주석이없고 RNA-Seq 데이터가없는 경우에도 높은 유전자 예측 정확도에 도달합니다.
Braker3는 Braker Suite의 최신 파이프 라인입니다. 완전 자동화 된 파이프 라인에서 RNA-Seq 및 단백질 데이터를 사용하여 Genemark-ETP 및 Augustus로 신뢰할 수있는 유전자를 훈련시키고 예측할 수 있습니다. 파이프 라인의 결과는 두 유전자 예측 도구의 결합 된 유전자 세트이며, 여기에는 외적 증거로부터 매우 높은지지를 가진 유전자 만 포함되어 있습니다.
이 사용자 안내서에서는 Braker1, Braker2 및 Braker3을 동일한 스크립트 ( braker.pl )에 의해 실행되기 때문에 Braker 라고 간단히 말합니다.
고품질 게놈 어셈블리를 사용하십시오. 게놈 어셈블리에 수많은 짧은 비계가 있다면, 짧은 발판은 런타임을 극적으로 증가시킬 수 있지만 예측 정확도를 높이 지 않을 것입니다.
게놈 파일에서 간단한 스캐 폴드 이름을 사용하십시오 (예 : >contig1 >contig1my custom species namesome putative function /more/information/ and lots of special characters %&!*(){} )보다 더 잘 작동합니다. 정렬 프로그램을 실행하기 전에 모든 FASTA 파일의 스캐 폴드 이름을 간단하게 만드십시오.
새로운 게놈에서 유전자를 정확하게 예측하기 위해, 게놈은 반복을 위해 마스크되어야한다. 이것은 반복적이고 낮은 복잡한 영역에서 잘못된 양성 유전자 구조의 예측을 피할 것이다. 반복 마스킹은 또한 RNA-Seq 데이터를 일부 도구 (HISAT2와 같은 다른 RNA-Seq 매퍼, 마스킹 정보를 무시 함)를 가진 게놈에 맵핑하는 데 필수적입니다. Genemark-ES/ET/EP/ETP 및 Augustus의 경우, 소프트 마스킹 (즉, 반복 영역을 소문자 및 기타 모든 영역에 상류 문자에 넣음). 알려지지 않은 뉴클레오티드의 N ).
많은 게놈에는 Braker 내의 Genemark-ES/ET/EP/ETP 및 Augustus의 표준 파라미터로 정확하게 예측 될 유전자 구조가 있습니다. 그러나 일부 게놈에는 Clade- 특이 적 특징, 즉 곰팡이의 특수 지점 모델 또는 비표준 스플 라이스 사이트 패턴이 있습니다. 사용자 정의 옵션 중 하나가 목표 종의 게놈에서 유전자 예측 정확도를 향상시킬 수 있는지 여부를 결정하려면 옵션 섹션 [옵션]을 읽으십시오.
추가 사용 전에 항상 유전자 예측 결과를 확인하십시오! 예를 들어, 외부 증거 데이터와 관련하여 유전자 모델을 육안으로 검사하기 위해 게놈 브라우저를 사용할 수 있습니다. Braker는이 목적을 위해 MakeHub와 함께 UCSC 게놈 브라우저의 트랙 데이터 허브 생성을 지원합니다.
Braker는 주로 반 감독 된 외적 증거 데이터 (RNA-Seq 및/또는 단백질 스 플라이 싱 된 정렬 정보)를 지원합니다. 유전자 예측 단계. 그러나 이제 Braker에는 여러 가지 추가 파이프 라인이 포함되어 있습니다. 다음에서는 가능한 입력 파일 및 파이프 라인에 대한 개요를 제공합니다.
![Braker2-Main-A [그림 1]](https://images.downcodes.com/uploads/20250214/img_67aee79a0eaf534.png)
그림 2 : Braker Pipeline A : 게놈 데이터에 대한 Genemark-ES 훈련; Ab initio 유전자 예측과 함께
![Braker2-Main-B [그림 2]](https://images.downcodes.com/uploads/20250214/img_67aee79a0f13f35.png)
그림 3 : Braker Pipeline B : RNA-Seq 스 플라이 싱 된 정렬 정보에 의해 지원되는 GeneMark-ET 교육, 동일한 스 플라이 싱 된 정렬 정보를 사용한 Augustus의 예측.
![Braker2-Main-C [그림 3]](https://images.downcodes.com/uploads/20250214/img_67aee79a0fa1036.png)
그림 4 : Braker Pipeline C : 단백질 스 플라이 싱 된 정렬에 대한 Genemark-EP+ 훈련, 정보를 시작 및 정지, 동일한 정보로 Augustus의 예측, 또한 CDSPART 힌트를 묶습니다. 여기에 사용 된 단백질은 표적 유기체와의 진화 거리가 될 수 있습니다.
![Braker3-Main-A [그림 4]](https://images.downcodes.com/uploads/20250214/img_67aee79a1010b37.png)
그림 5 : 브레이커 파이프 라인 D : 필요한 경우 목표 종에 대한 RNA-Seq 세트의 다운로드 및 정렬. RNA-Seq 정렬 및 큰 단백질 데이터베이스에 의해 지원되는 Genemark-ETP의 훈련 (단백질은 모든 진화 거리 일 수 있음). 결과적으로, Augustus 훈련 및 예측은 Genemark-ETP 결과와 함께 동일한 외적 정보를 사용한 예측입니다. 최종 예측은 Augustus와 Genemark-ETP 결과의 Tsebra 조합입니다.
우리는 Braker3의 "매뉴얼"설치와 그 모든 종속성이 루트 권한없이 지루하고 실제로 도전적이라는 것을 알고 있습니다. 따라서, 우리는 특이점으로 실행되도록 개발 된 도커 컨테이너를 제공합니다. 이 컨테이너에 대한 모든 정보는 https://hub.docker.com/r/teambraker/braker3에서 찾을 수 있습니다.
요컨대, 다음과 같이 구축하십시오.
singularity build braker3.sif docker://teambraker/braker3:latest
실행 :
singularity exec braker3.sif braker.pl
테스트 :
singularity exec -B $PWD:$PWD braker3.sif cp /opt/BRAKER/example/singularity-tests/test1.sh .
singularity exec -B $PWD:$PWD braker3.sif cp /opt/BRAKER/example/singularity-tests/test2.sh .
singularity exec -B $PWD:$PWD braker3.sif cp /opt/BRAKER/example/singularity-tests/test3.sh .
export BRAKER_SIF=/your/path/to/braker3.sif # may need to modify
bash test1.sh
bash test2.sh
bash test3.sh
Docker 내에서 분석을 실행하려는 사용자는 거의 없습니다 (루트 권한이 필요하기 때문에). 그러나 그것이 당신의 목표라면, 당신은 다음과 같이 컨테이너를 실행하고 테스트 할 수 있습니다.
sudo docker run --user 1000:100 --rm -it teambraker/braker3:latest bash
bash /opt/BRAKER/example/docker-tests/test1.sh # BRAKER1
bash /opt/BRAKER/example/docker-tests/test2.sh # BRAKER2
bash /opt/BRAKER/example/docker-tests/test3.sh # BRAKER3
행운을 빌어요 ;-)
$PATH 변수에 남아있는 구형 Genemark 버전은 예상치 못한 간섭으로 이어져 프로그램 실패를 유발할 수 있습니다. 모든 오래된 Genemark 버전을 $PATH 에서 옮기십시오 (예 : ProtHint/dependencies 의 Genemark).
출시 당시이 브레이커 버전은 다음과 같이 테스트되었습니다.
아우구스투스 3.5.0 F2
Genemark-ETP (소스 DockerFile 참조)
Bamtools 2.5.1 R5
Samtools 1.7-4-G93586ed R6
SPALN 2.3.3d R8, R9, R10
NCBI Blast+ 2.2.31+ R12, R13
다이아몬드 0.9.24
cdbfasta 0.99
CDBYANK 0.981
Gushr 1.0.0
SRA 툴킷 3.00 R14
Hisat2 2.2.1 r15
BedTools 2.30 R16
StringTie2 2.2.1 r17
GFFREAD 0.12.7 R18
보조 0.2.5 R27
Braker를 달리기 위해서는 bash 와 Perl이있는 Linux 시스템이 필요합니다. 또한 Braker는 다음 CPAN-PERL 모듈을 설치해야합니다.
File::Spec::Functions
Hash::Merge
List::Util
MCE::Mutex
Module::Load::Conditional
Parallel::ForkManager
POSIX
Scalar::Util::Numeric
YAML
Math::Utils
File::HomeDir
단백질 및 RNA-Seq가 공급 될 때 사용되는 Genemark-ETP의 경우 :
YAML::XSData::DumperThread::Queuethreads 예를 들어 Ubuntu에서 CPANMINUS F4 : sudo cpanm Module::Name , 예 : sudo cpanm Hash::Merge 로 모듈을 설치하십시오.
Braker는 또한 CPAN에서 사용할 수없는 Perl 모듈 helpMod_braker.pm 을 사용합니다. 이 모듈은 Braker 릴리스의 일부이며 별도의 설치가 필요하지 않습니다.
Linux 시스템에 루트 권한이없는 경우 다음과 같이 Anaconda (https://www.anaconda.com/distribution/) 환경을 설정해보십시오.
wget https://repo.anaconda.com/archive/Anaconda3-2018.12-Linux-x86_64.sh
bash bin/Anaconda3-2018.12-Linux-x86_64.sh # do not install VS (needs root privileges)
conda install -c anaconda perl
conda install -c anaconda biopython
conda install -c bioconda perl-app-cpanminus
conda install -c bioconda perl-file-spec
conda install -c bioconda perl-hash-merge
conda install -c bioconda perl-list-util
conda install -c bioconda perl-module-load-conditional
conda install -c bioconda perl-posix
conda install -c bioconda perl-file-homedir
conda install -c bioconda perl-parallel-forkmanager
conda install -c bioconda perl-scalar-util-numeric
conda install -c bioconda perl-yaml
conda install -c bioconda perl-class-data-inheritable
conda install -c bioconda perl-exception-class
conda install -c bioconda perl-test-pod
conda install -c bioconda perl-file-which # skip if you are not comparing to reference annotation
conda install -c bioconda perl-mce
conda install -c bioconda perl-threaded
conda install -c bioconda perl-list-util
conda install -c bioconda perl-math-utils
conda install -c bioconda cdbtools
conda install -c eumetsat perl-yaml-xs
conda install -c bioconda perl-data-dumper
그 후 콘다 환경에있는 동안 Braker 및 기타 소프트웨어를 "평소와 같이"설치하십시오. 참고 : Bioconda Braker 패키지와 Bioconda Augustus 패키지가 있습니다. 그들은 일합니다. 그러나 그들은 일반적으로 Github의 두 도구의 개발 코드 뒤에 뒤쳐져 있습니다. 따라서 수동 설치 및 마지막 소스 사용을 권장합니다.
Braker는 Perl 및 Python 스크립트 및 Perl 모듈 모듈 모음입니다. Braker를 실행하기 위해 호출 될 주요 스크립트는 braker.pl 입니다. 추가 Perl 및 Python 구성 요소는 다음과 같습니다.
align2hints.pl
filterGenemark.pl
filterIntronsFindStrand.pl
startAlign.pl
helpMod_braker.pm
findGenesInIntrons.pl
downsample_traingenes.pl
ensure_n_training_genes.py
get_gc_content.py
get_etp_hints.py
Braker의 일부인 *.pl 및 *.py 로 끝나는 파일 ( *.pl 및 *.py)은 브레이커를 실행하려면 실행 가능해야합니다. Github에서 Braker를 다운로드 한 경우 이미 그렇습니다. USB 스틱에서 다른 컴퓨터로 Braker를 전송하는 경우 실행 성을 덮어 쓸 수 있습니다. 필요한 파일이 실행 가능한지 확인하려면 Braker Perl 스크립트가 포함 된 디렉토리에서 다음 명령을 실행하십시오.
ls -l *.pl *.py
출력은 다음과 유사해야합니다.
-rwxr-xr-x 1 katharina katharina 18191 Mai 7 10:25 align2hints.pl
-rwxr-xr-x 1 katharina katharina 6090 Feb 19 09:35 braker_cleanup.pl
-rwxr-xr-x 1 katharina katharina 408782 Aug 17 18:24 braker.pl
-rwxr-xr-x 1 katharina katharina 5024 Mai 7 10:25 downsample_traingenes.pl
-rwxr-xr-x 1 katharina katharina 5024 Mai 7 10:23 ensure_n_training_genes.py
-rwxr-xr-x 1 katharina katharina 4542 Apr 3 2019 filter_augustus_gff.pl
-rwxr-xr-x 1 katharina katharina 30453 Mai 7 10:25 filterGenemark.pl
-rwxr-xr-x 1 katharina katharina 5754 Mai 7 10:25 filterIntronsFindStrand.pl
-rwxr-xr-x 1 katharina katharina 7765 Mai 7 10:25 findGenesInIntrons.pl
-rwxr-xr-x 1 katharina katharina 1664 Feb 12 2019 gatech_pmp2hints.pl
-rwxr-xr-x 1 katharina katharina 2250 Jan 9 13:55 log_reg_prothints.pl
-rwxr-xr-x 1 katharina katharina 4679 Jan 9 13:55 merge_transcript_sets.pl
-rwxr-xr-x 1 katharina katharina 41674 Mai 7 10:25 startAlign.pl
각 스크립트마다 -rwxr-xr-x 의 x 존재하는 것이 중요합니다. 그렇지 않은 경우 실행하십시오
`chmod a+x *.pl *.py`
파일 속성을 변경하기 위해
Braker Perl 스크립트가 $PATH Environment 변수에 상주하는 디렉토리를 추가하는 것이 도움이 될 수 있습니다. 단일 배쉬 세션의 경우 다음을 입력하십시오.
PATH=/your_path_to_braker/:$PATH
export PATH
이 $PATH 수정을 모든 Bash 세션에서 사용할 수 있도록하려면 위의 줄을 시작 스크립트 (예 : ~/.bashrc )에 추가하십시오.
Braker는 Braker의 일부가 아닌 다양한 생물 정보학 소프트웨어 도구를 요구합니다. 일부 도구는 의무적이며, 즉, 이러한 도구가 시스템에 존재하지 않으면 전혀 실행되지 않습니다. 다른 도구는 선택 사항입니다. 선택한 모드에서 Braker를 실행하는 데 필요한 모든 도구를 설치하십시오.
http://github.com/gatech-genemark/genemark-etp 또는 https://topaz.gatech.edu/genemark/etp.for_braker.gz에서 genemark-etp f1을 다운로드하십시오. Genemark-ETP의 README 파일에 설명 된대로 GeneMark-ETP를 포장하고 설치하십시오.
$PATH 변수에 이미 포함 된 경우 Braker는 gmes_petap.pl 또는 gmetp.pl 의 위치를 자동으로 추측합니다. 그렇지 않으면 Braker는 환경 변수 GENEMARK_PATH 에서 찾거나 명령 줄 인수 ( --GENEMARK_PATH=/your_path_to_GeneMark_executables/ )를 사용하여 Genemark-ES/ET/EP/ETP 실행 파일을 찾을 수 있습니다.
현재 배쉬 세션의 환경 변수를 설정하려면 다음을 입력하십시오.
export GENEMARK_PATH=/your_path_to_GeneMark_executables/
모든 Bash 세션에 사용할 수 있도록 위의 줄을 시작 스크립트 (예 : ~/.bashrc )에 추가하십시오.
Genemark-ES/ET/EP/ETP 내의 Perl 스크립트는 /usr/bin/perl 의 기본 Perl 위치로 구성됩니다.
Anaconda 환경에서 Genemark-ES/ET/EP/ETP를 실행중인 경우 (또는 다른 이유에 대해 $PATH 변수의 Perl을 사용하려는 경우) 모든 Genemark-ES/ET/EP/ETP 스크립트의 Shebang을 수정하십시오. GeneMark-ES/ET/EP/ETP 폴더 내부에 위치한 다음 명령 :
perl change_path_in_perl_scripts.pl "/usr/bin/env perl"
GeneMark-E-tests 디렉토리에서 check_install.bash 및/또는 실행 예제를 실행하여 Genemark-ES/ET/EP가 올바르게 설치되어 있는지 확인할 수 있습니다.
GeneMark-ETP는 하향 호환성이며, 즉 Braker에서 Genemark-EP 및 Genemark-ET의 기능을 다룹니다.
https://github.com/gaius-augustus/augustus의 마스터 지점에서 Augustus를 다운로드하십시오. Augustus README.TXT 에 따르면 Augustus를 포장하고 Augustus를 설치하십시오. Debian 패키지 또는 Bioconda 패키지 (예 : Debian Package 또는 Bioconda 패키지)의 오래된 Augustus 버전을 사용하지 마십시오! Braker는 특히 최신 Augustus/Scripts 디렉토리에 크게 의존하며 다른 출처는 종종 뒤쳐져 있습니다.
Augustus가 사용하는 라이브러리 버전의 문제를 피하기 위해 Augustus를 자신의 시스템에서 컴파일해야합니다. 컴파일 지침은 Augustus README.TXT 파일 ( Augustus/README.txt )에 제공됩니다.
Augustus는 augustus , 유전자 예측 도구, Augustus/auxprogs 에 위치한 추가 C ++ 도구 및 Augustus/scripts 에 위치한 Perl 스크립트로 구성됩니다. Perl 스크립트는 실행 가능해야합니다 (섹션 브레이커 구성 요소의 지침 참조.
C ++ 도구 bam2hints RNA-Seq와 함께 실행할 때 Braker의 필수 구성 요소입니다. 출처는 Augustus/auxprogs/bam2hints 에 있습니다. 시스템에서 bam2hints 컴파일해야합니다 (Augustus가 컴파일 될 때는 자동으로 컴파일해야하지만 bam2hints 문제의 경우 Augustus/auxprogs/bam2hints/README 에서 문제 해결 지침을 읽으십시오).
Braker는 Augustus를 훈련시키는 파이프 라인이므로 IE는 종별 매개 변수 파일을 작성합니다. Braker는 Augustus ( Augustus/config/ )를 포함하는 Augustus의 구성 디렉토리에 대한 액세스를 작성해야합니다. 시스템에 Augustus를 전 세계적으로 설치하면 config 폴더를 일반적으로 모든 사용자가 쓸 수있는 것은 아닙니다. config Augustus 사용자에게 재귀 적으로 쓰기 가능한 디렉토리를 만들거나 사용자가 허가를받는 위치에 config/ 폴더 (재귀 적으로)를 복사하십시오.
Augustus는 환경 변수 $AUGUSTUS_CONFIG_PATH 를 찾아 config 폴더를 찾습니다. $AUGUSTUS_CONFIG_PATH 변수가 설정되지 않은 경우 Braker는 Augustus 실행 파일을 찾는 디렉토리에 대해 경로를 보게됩니다 ../config . 또는 변수를 Braker ( --AUGUSTUS_CONFIG_PATH=/your_path_to_AUGUSTUS/Augustus/config/ )에 명령 줄 인수로 제공 할 수 있습니다. 현재 Bash 세션의 변수를 내보내는 것이 좋습니다.
export AUGUSTUS_CONFIG_PATH=/your_path_to_AUGUSTUS/Augustus/config/
모든 배쉬 세션에서 변수를 사용할 수 있도록하려면 위의 줄을 시작 스크립트 (예 : ~/.bashrc 에 추가하십시오.
Augustus를 데비안 패키지로 설치하려는 경우 Dockerfile을 살펴보십시오. 그러면 많은 스크립트를 패치해야합니다.
Braker는 Augustus의 전체 config 디렉토리를 $AUGUSTUS_CONFIG_PATH , 즉 내용물 (적어도 generic )과 extrinsic 으로하는 Subfolders species 의 전체 구성 디렉토리를 기대합니다! $AUGUSTUS_CONFIG_PATH 에서 쓰기 가능한 폴더를 제공하는 것은 Braker에게는 효과가 없습니다. Augustus Binary와 $AUGUSTUS_CONFIG_PATH 분리 해야하는 경우, 쓰레기가없는 구성 내용을 쓰기 가능한 위치에 재귀 적으로 복사하는 것이 좋습니다.
/usr/bin/augustus 에서 Augustus의 시스템 전체에 설치되어있는 경우, 치료되지 않는 구성 사본 config /usr/bin/augustus_config/ 에 있습니다. 폴더 /home/yours/ 는 당신에게 쓸 수 있습니다. 다음 명령으로 복사하고 필요한 변수를 추가로 설정) :
cp -r /usr/bin/Augustus/config/ /home/yours/
export AUGUSTUS_CONFIG_PATH=/home/yours/augustus_config
export AUGUSTUS_BIN_PATH=/usr/bin
export AUGUSTUS_SCRIPTS_PATH=/usr/bin/augustus_scripts
Augustus Binaries 및 Scripts의 디렉토리를 $PATH 변수에 추가하면 시스템이 이러한 도구를 자동으로 찾을 수 있습니다. Braker는 다른 환경 변수 ( $AUGUSTUS_CONFIG_PATH )의 위치에서 그들을 추측하려고 시도하거나 braker.pl 에게 명령 줄 인수로 제공 될 수 있기 때문에 Braker를 운영하는 것이 필요하지 않습니다. $PATH 변수에 추가하십시오. 현재 배쉬 세션의 경우 다음을 입력하십시오.
PATH=:/your_path_to_augustus/bin/:/your_path_to_augustus/scripts/:$PATH
export PATH
모든 배쉬 세션의 경우 위의 줄을 시작 스크립트 (예 : ~/.bashrc )에 추가하십시오.
Ubuntu에서 Python3은 일반적으로 기본적으로 설치되며 python3 기본적으로 $PATH 변수에 있으며 Braker는 자동으로이를 찾습니다. 그러나 python3 바이너리 위치를 다른 두 가지 방법으로 지정할 수있는 옵션이 있습니다.
환경 변수 $PYTHON3_PATH , 예를 들어 ~/.bashrc 파일에서 :
export PYTHON3_PATH=/path/to/python3/
명령 줄 옵션 --PYTHON3_PATH=/path/to/python3/ to to braker.pl 을 지정하십시오.
bamtools를 다운로드하십시오 (예 : git clone https://github.com/pezmaster31/bamtools.git ). 쉘에 다음을 입력하여 Bamtools를 설치하십시오.
cd your-bamtools-directory mkdir build cd build cmake .. make
이미 $PATH 변수에있는 경우 Braker는 Bamtools를 자동으로 찾을 수 있습니다. 그렇지 않으면 Braker는 환경 변수 $BAMTOOLS_PATH 사용하거나 명령 줄 인수 ( --BAMTOOLS_PATH=/your_path_to_bamtools/bin/ f6 )를 사용하여 Bamtools 이진을 찾을 수 있습니다. 현재 배쉬 세션의 환경 변수를 설정하려면 다음을 입력하십시오.
export BAMTOOLS_PATH=/your_path_to_bamtools/bin/
모든 배쉬 세션의 환경 변수를 설정하려면 위의 줄을 시작 스크립트 (예 : ~/.bashrc )에 추가하십시오.
중복 훈련 유전자를 제거하기 위해 NCBI Blast+ 또는 Diamond를 사용할 수 있습니다. 두 도구가 모두 필요하지 않습니다. 다이아몬드가 있으면 훨씬 빠르기 때문에 선호됩니다.
다음과 같이 다이아몬드를 획득하고 포장을 풀어주십시오.
wget http://github.com/bbuchfink/diamond/releases/download/v0.9.24/diamond-linux64.tar.gz
tar xzf diamond-linux64.tar.gz
이미 $PATH 변수에있는 경우 Braker는 다이아몬드를 자동으로 찾을 수 있습니다. 그렇지 않으면 Braker는 환경 변수 $DIAMOND_PATH 사용하거나 명령 줄 인수 ( --DIAMOND_PATH=/your_path_to_diamond )를 사용하여 다이아몬드 바이너리를 찾을 수 있습니다. 현재 배쉬 세션의 환경 변수를 설정하려면 다음을 입력하십시오.
export DIAMOND_PATH=/your_path_to_diamond/
모든 배쉬 세션의 환경 변수를 설정하려면 위의 줄을 시작 스크립트 (예 : ~/.bashrc )에 추가하십시오.
Blast+를 결정하면 sudo apt-get install ncbi-blast+ 사용하여 NCBI Blast+를 설치하십시오.
이미 $PATH 변수에있는 경우 Braker는 BLASTP를 자동으로 찾을 수 있습니다. 그렇지 않으면 Braker는 환경 변수 $BLAST_PATH 사용하거나 명령 줄 인수 ( --BLAST_PATH=/your_path_to_blast/ )를 사용하여 Blastp Binary를 찾을 수 있습니다. 현재 배쉬 세션의 환경 변수를 설정하려면 다음을 입력하십시오.
export BLAST_PATH=/your_path_to_blast/
모든 배쉬 세션의 환경 변수를 설정하려면 위의 줄을 시작 스크립트 (예 : ~/.bashrc )에 추가하십시오.
GeneMark-ETP에는 다음 도구가 필요하며 $PATH 변수에서이를 찾으려고합니다. 따라서 위치를 $PATH 에 추가하십시오.
export PATH=$PATH:/your/path/to/Tool
아래의 모든 도구의 경우 모든 Bash 세션에 대한 $PATH 변수를 확장하려면 위의 줄을 시작 스크립트 (예 ~/.bashrc )에 추가하십시오.
이 소프트웨어 도구는 RNA-Seq 및 단백질 데이터로 Braker를 실행하는 경우에만 필수적입니다!
StringTie2는 Genemark-ETP에 의해 정렬 된 RNA-Seq 정렬을 조립하는 데 사용됩니다. 사전 컴파일 된 StringTie2 버전은 https://ccb.jhu.edu/software/stringtie/#install에서 다운로드 할 수 있습니다.
RNA-Seq 및 단백질 데이터로 Braker를 실행하려면 Genemark-ETP에 의해 소프트웨어 패키지 BedTools가 필요합니다. https://github.com/arq5x/bedtools2/releases에서 BedTools를 다운로드 할 수 있습니다. 여기에서는 사전 컴파일 된 버전을 다운로드 할 수 있습니다. bedtools.static.binary , 예 :
wget https://github.com/arq5x/bedtools2/releases/download/v2.30.0/bedtools.static.binary
mv bedtools.static.binary bedtools
chmod a+x
또는 bedtools-2.30.0.tar.gz 다운로드하여 make 사용하여 소스에서 컴파일 할 수 있습니다.
wget https://github.com/arq5x/bedtools2/releases/download/v2.30.0/bedtools-2.30.0.tar.gz
tar -zxvf bedtools-2.30.0.tar.gz
cd bedtools2
make
자세한 내용은 https://bedtools.readthedocs.io/en/latest/content/installation.html을 참조하십시오.
GFFREAD는 Genemark-ETP가 요구하는 유틸리티 소프트웨어입니다. make 에서 다운로드 할 수 있습니다.
wget https://github.com/gpertea/gffread/releases/download/v0.12.7/gffread-0.12.7.Linux_x86_64.tar.gz
tar xzf gffread-0.12.7.Linux_x86_64.tar.gz
cd gffread-0.12.7.Linux_x86_64
make
모든 파일이 형식화되면 Genemark-ETP없이 Braker를 실행하는 데 SamTools가 필요하지 않습니다 (즉, 모든 시퀀스에는 짧고 고유 한 FASTA 이름이 있어야합니다). 모든 파일이 올바르게 고정되어 있는지 확실하지 않은 경우 Braker는 Samtools를 사용하여 특정 형식 문제를 자동으로 수정할 수 있으므로 Samtools를 설치하는 것이 도움이 될 수 있습니다.
Samtools의 전제 조건으로 htslib 다운로드하여 설치하십시오 (예 : git clone https://github.com/samtools/htslib.git htslib 문서를 참조하십시오).
samtools를 다운로드하여 설치하십시오 (예 : git clone git://github.com/samtools/samtools.git ), 설치를 위해 Samtools 문서를 따르십시오).
이미 $PATH 변수에있는 경우 Braker는 Samtools를 자동으로 찾을 수 있습니다. 그렇지 않으면 Braker는 명령 줄 인수 ( --SAMTOOLS_PATH=/your_path_to_samtools/ )를 취하거나 환경 변수 $SAMTOOLS_PATH 사용하여 SamTools를 찾을 수 있습니다. 현재 배쉬 세션의 변수를 내보내기 위해 다음을 입력하십시오.
export SAMTOOLS_PATH=/your_path_to_samtools/
모든 배쉬 세션의 환경 변수를 설정하려면 위의 줄을 시작 스크립트 (예 : ~/.bashrc )에 추가하십시오.
Biopython이 설치되면 Braker는 Augustus에 의해 예측 된 코딩 시퀀스 및 단백질 서열로 Fasta-Files를 생성하고 MakeHub R16을 사용하여 Braker Run의 시각화를 위해 트랙 데이터 허브를 생성 할 수 있습니다. 선택 단계입니다. 첫 번째는 명령 줄 깃발 --skipGetAnnoFromFasta 으로 비활성화 할 수 있으며, 두 번째는 명령 줄 옵션을 사용하여 활성화 할 수 있습니다 --makehub [email protected] 수행해야합니다.
Ubuntu에서는 Python3 패키지 관리자를 다음과 같이 설치하십시오.
`sudo apt-get install python3-pip`
그런 다음 다음과 함께 바이오 파티 톤을 설치하십시오.
`sudo pip3 install biopython`
CDBFASTA 및 CDBYANK는 Augustus script fix_in_frame_stop_codon_genes.py를 사용하여 프레임 스톱 코돈 (스 플라이 싱 스톱 코돈)으로 Augustus 유전자를 수정하기 위해 Braker가 필요합니다. --skip_fixing_broken_genes 로 건너 뛸 수 있습니다.
Ubuntu에서는 다음과 같이 cdbfasta를 설치하십시오.
sudo apt-get install cdbfasta
다른 시스템의 경우 예를 들어 https://github.com/gpertea/cdbfasta에서 cdbfasta를 얻을 수 있습니다.
git clone https://github.com/gpertea/cdbfasta.git
cd cdbfasta
make all
Ubuntu에서는 Cdbfasta 및 CDByank가 설치 후 $PATH 변수에 있으며 Braker는 자동으로이를 찾습니다. 그러나 cdbfasta 및 cdbyank 바이너리 위치를 다른 두 가지 방법으로 지정할 수있는 옵션이 있습니다.
$CDBTOOLS_PATH , 예를 들어 ~/.bashrc 파일에서 : export CDBTOOLS_PATH=/path/to/cdbtools/
--CDBTOOLS_PATH=/path/to/cdbtools/ TO braker.pl 을 지정하십시오. 참고 : Braker 내에서 독립형 Spaln (Prothint of Prothint)의 지원은 더 이상 사용되지 않습니다.
이 도구는 Prothint를 실행하거나 Prothint 외부의 Spaln을 사용하여 Braker와 게놈 정렬에 단백질을 실행하려는 경우 필요합니다. Prothint 외부에서 Spaln을 사용하는 것은 표적 게놈에 대한 짧은 진화 거리의 주석이 달린 종을 이용할 수있는 경우에만 적합한 접근법입니다. Braker를 위해 Prothint를 통해 Spaln을 운영하는 것이 좋습니다. Prothint는 Spaln Binary를 따라 가져옵니다. 그것이 시스템에서 작동하지 않으면 https://github.com/ogotoh/spaln에서 spaln을 다운로드하십시오. spaln/doc/SpalnReadMe22.pdf 에 따라 포장을 풀고 설치하십시오.
Braker는 환경 변수 $ALIGNMENT_TOOL_PATH 사용하여 SPALN 실행 파일을 찾으려고합니다. 또는 이것은 명령 줄 인수 ( --ALIGNMENT_TOOL_PATH=/your/path/to/spaln )로 제공 될 수 있습니다.
이 도구는 예측 된 유전자에 UTR (RNA-Seq 데이터에서)을 추가하거나 Augustus의 UTR 매개 변수를 훈련시키고 UTRS를 갖는 유전자를 예측하려는 경우에만 필요합니다. 어쨌든 Gushr은 RNA-Seq 데이터의 입력이 필요합니다.
Gushr은 https://github.com/gaius-augustus/gushr에서 다운로드 할 수 있습니다. 입력하여 얻으십시오.
git clone https://github.com/Gaius-Augustus/GUSHR.git
Gushr은 Gemoma Jar 파일 R19, R20, R21 을 실행 하고이 JAR 파일에는 Java 1.8이 필요합니다. Ubuntu에서는 다음 명령으로 Java 1.8을 설치할 수 있습니다.
sudo apt-get install openjdk-8-jdk
시스템에 여러 개의 Java 버전이 설치된 경우, 실행하여 Java를 사용하여 1.8 Prior Running Braker를 활성화해야합니다.
sudo update-alternatives --config java
올바른 버전을 선택합니다.
http://hgdownload.soe.ucsc.edu/admin/exe에서 다운로드 할 수있는 다음 도구가 필요 --UTR=on .
twobitinfo
Fatotwobit
이러한 도구를 $ 경로에 설치하는 것이 선택 사항입니다. 그렇지 않고 --UTR=on 전환하면 bamtowig.py는 자동으로 작업 디렉토리로 다운로드됩니다.
자동적으로 Braker Run의 트랙 데이터 허브를 생성하려면 https://github.com/gaius-augustus/makehub에서 사용할 수있는 MakeHub 소프트웨어가 필요합니다. 소프트웨어 다운로드 git clone https://github.com/Gaius-Augustus/MakeHub.git , https://github.com/gaius-augithubs/makehub/releases에서 릴리스를 선택하여 릴리스를 추출하십시오. 릴리스를 다운로드 한 경우 패키지 (예 : unzip MakeHub.zip 또는 tar -zxvf MakeHub.tar.gz .
Braker는 환경 변수 $MAKEHUB_PATH 사용하여 make_hub.py 스크립트를 찾으려고합니다. 또는 이것은 명령 줄 인수 ( --MAKEHUB_PATH=/your/path/to/MakeHub/ )로 제공 될 수 있습니다. Braker는 또한 시스템에서 MakeHub의 위치를 추측 할 수 있습니다.
Braker가 NCBI의 SRA에서 RNA-Seq 라이브러리를 다운로드하도록하려면 SRA 툴킷이 필요합니다. http://daehwankimlab.github.io/hisat2/download/#version-hisat2-221에서 사전 컴파일 된 버전의 SRA 툴킷을 얻을 수 있습니다.
Braker는 환경 변수 $SRATOOLS_PATH 사용하여 SRA 툴킷 (FastQ-Dump, Prefetch)에서 실행 가능한 바이너리를 찾으려고합니다. 또는 이것은 명령 줄 인수 ( --SRATOOLS_PATH=/your/path/to/SRAToolkit/ )로 제공 될 수 있습니다. Braker는 실행 파일이 $PATH 변수에 있으면 시스템에서 SRA 툴킷의 위치를 추측 할 수 있습니다.
정렬되지 않은 RNA-Seq 읽기를 사용하려면 HisAT2 소프트웨어를 게놈에 매핑해야합니다. hisat2의 사전 컴파일 버전은 http://daehwankimlab.github.io/hisat2/download/#version-hisat2-221에서 다운로드 할 수 있습니다.
Braker는 환경 변수 $HISAT2_PATH 사용하여 실행 가능한 Hisat2 Binaries (Hisat2, Hisat2-Build)를 찾으려고 노력할 것입니다. 대안 적으로, 이것은 명령 줄 인수 ( --HISAT2_PATH=/your/path/to/HISAT2/ )로 제공 될 수 있습니다. Braker는 실행 파일이 $PATH 변수에 있으면 시스템에서 HisAT2의 위치를 추측하려고 시도 할 수 있습니다.
Busco 완전성 최대화 모드에서 Braker 내에서 Tsebra를 실행하려면 Compleasm을 설치해야합니다.
wget https://github.com/huangnengCSU/compleasm/releases/download/v0.2.4/compleasm-0.2.4_x64-linux.tar.bz2
tar -xvjf compleasm-0.2.4_x64-linux.tar.bz2 &&
결과 폴더 Compleasm_kit을 $PATH 변수에 추가하십시오.
export PATH=$PATH:/your/path/to/compleasm_kit
Complerem에는 팬더가 필요하며 다음과 같이 설치할 수 있습니다.
pip install pandas
Braker (Braker.pl)는 getConf를 사용하여 시스템에서 얼마나 많은 스레드를 실행할 수 있는지 확인합니다. 우분투에서는 다음과 같이 설치할 수 있습니다.
sudo apt-get install libc-bin
다음에서는 "일반적인"Braker가 다른 입력 데이터 유형을 요구하는 것을 설명합니다. 일반적으로 반복을 위해 소프트 마스크를받은 게놈 서열에서 Braker를 실행하는 것이 좋습니다. Braker는 반복을 위해 소프트 마스크를받은 게놈에만 적용되어야합니다!
This approach is suitable for genomes of species for which RNA-Seq libraries with good transcriptome coverage are available and for which protein data is not at hand. The pipeline is illustrated in Figure 2.
BRAKER has several ways to receive RNA-Seq data as input:
You can provide ID(s) of RNA-Seq libraries from SRA (in case of multiple IDs, separate them by comma) as argument to --rnaseq_sets_ids . The libraries belonging to the IDs are then downloaded automatically by BRAKER, eg:
braker.pl --species=yourSpecies --genome=genome.fasta
--rnaseq_sets_ids=SRA_ID1,SRA_ID2
You can use local FASTQ file(s) of unaligned reads as input. In this case, you have to provide BRAKER with the ID(s) of the RNA-Seq set(s) as argument to --rnaseq_sets_ids and the path(s) to the directories, where the FASTQ files are located as argument to --rnaseq_sets_dirs . For each ID ID , BRAKER will search in these directories for one FASTQ file named ID.fastq if the reads are unpaired, or for two FASTQ files named ID_1.fastq and ID_2.fastq if they are paired.
For example, if you have a paired library called 'SRA_ID1' and an unpaired library named 'SRA_ID2', you have to have a directory /path/to/local/fastq/files/ , where the files SRA_ID1_1.fastq , SRA_ID1_2.fastq , and SRA_ID2.fastq reside. Then, you could run BRAKER with following command:
braker.pl --species=yourSpecies --genome=genome.fasta
--rnaseq_sets_ids=SRA_ID1,SRA_ID2
--rnaseq_sets_dirs=/path/to/local/fastq/files/
There are two ways of supplying BRAKER with RNA-Seq data as bam file(s). First, you can do it in the same way as you would supply FASTQ file(s): Provide the ID(s)/name(s) of your bam file(s) as argument to --rnaseq_sets_ids and specify directories where the bam files reside with --rnaseq_sets_dirs . BRAKER will automatically detect that these ID(s) are bam and not FASTQ file(s), eg:
braker.pl --species=yourSpecies --genome=genome.fasta
--rnaseq_sets_ids=BAM_ID1,BAM_ID2
--rnaseq_sets_dirs=/path/to/local/bam/files/
Second, you can specify the paths to your bam file(s) directly, eg can either extract RNA-Seq spliced alignment information from bam files, or it can use such extracted information, directly.
braker.pl --species=yourSpecies --genome=genome.fasta
--bam=file1.bam,file2.bam
Please note that we generally assume that bam files were generated with HiSat2 because that is the aligner that would also be executed by BRAKER3 with fastq input. If you want for some reason to generate the bam files with STAR, use the option --outSAMstrandField intronMotif of STAR to produce files that are compatible wiht StringTie in BRAKER3.
In order to run BRAKER with RNA-Seq spliced alignment information that has already been extracted, run:
braker.pl --species=yourSpecies --genome=genome.fasta
--hints=hints1.gff,hints2.gff
The format of such a hints file must be as follows (tabulator separated file):
chrName b2h intron 6591 8003 1 + . pri=4;src=E
chrName b2h intron 6136 9084 11 + . mult=11;pri=4;src=E
...
The source b2h in the second column and the source tag src=E in the last column are essential for BRAKER to determine whether a hint has been generated from RNA-Seq data.
It is also possible to provide RNA-Seq sets in different ways for the same BRAKER run, any combination of above options is possible. It is not recommended to provide RNA-Seq data with --hints if you run BRAKER in ETPmode (RNA-Seq and protein data), because GeneMark-ETP won't use these hints!
This approach is suitable for genomes of species for which no RNA-Seq libraries are available. A large database of proteins (with possibly longer evolutionary distance to the target species) should be used in this case. This mode is illustrated in figure 9.
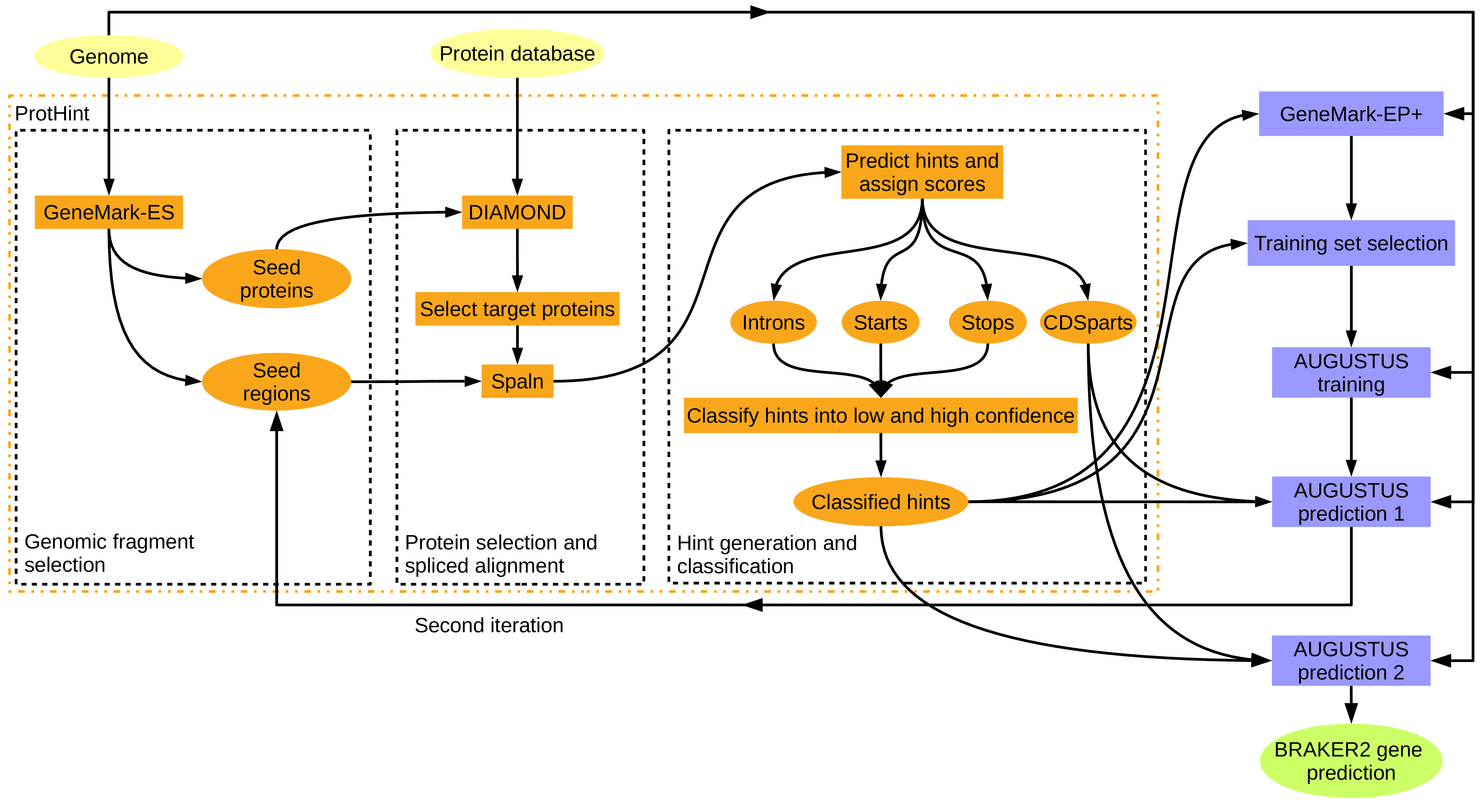
Figure 9: BRAKER with proteins of any evolutionary distance. ProtHint protein mapping pipelines is used to generate protein hints. ProtHint automatically determines which alignments are from close relatives, and which are from rather distant relatives.
For running BRAKER in this mode, type:
braker.pl --genome=genome.fa --prot_seq=proteins.fa
We recommend using OrthoDB as basis for proteins.fa . The instructions on how to prepare the input OrthoDB proteins are documented here: https://github.com/gatech-genemark/ProtHint#protein-database-preparation.
You can of course add additional protein sequences to that file, or try with a completely different database. Any database will need several representatives for each protein, though.
Instead of having BRAKER run ProtHint, you can also start BRAKER with hints already produced by ProtHint, by providing ProtHint's prothint_augustus.gff output:
braker.pl --genome=genome.fa --hints=prothint_augustus.gff
The format of prothint_augustus.gff in this mode looks like this:
2R ProtHint intron 11506230 11506648 4 + . src=M;mult=4;pri=4
2R ProtHint intron 9563406 9563473 1 + . grp=69004_0:001de1_702_g;src=C;pri=4;
2R ProtHint intron 8446312 8446371 1 + . grp=43151_0:001cae_473_g;src=C;pri=4;
2R ProtHint intron 8011796 8011865 2 - . src=P;mult=1;pri=4;al_score=0.12;
2R ProtHint start 234524 234526 1 + . src=P;mult=1;pri=4;al_score=0.08;
The prediction of all hints with src=M will be enforced. Hints with src=C are 'chained evidence', ie they will only be incorporated if all members of the group (grp=...) can be incorporated in a single transcript. All other hints have src=P in the last column. Supported features in column 3 are intron , start , stop and CDSpart .
If RNA-Seq (and only RNA-Seq) data is provided to BRAKER as a bam-file, and if the genome is softmasked for repeats, BRAKER can automatically train UTR parameters for AUGUSTUS. After successful training of UTR parameters, BRAKER will automatically predict genes including coverage information form RNA-Seq data. Example call:
braker.pl --species=yourSpecies --genome=genome.fasta
--bam=file.bam --UTR=on
Warnings:
This feature is experimental!
--UTR=on is currently not compatible with bamToWig.py as released in AUGUSTUS 3.3.3; it requires the current development code version from the github repository (git clone https://github.com/Gaius-Augustus/Augustus.git).
--UTR=on increases memory consumption of AUGUSTUS. Carefully monitor jobs if your machine was close to maxing RAM without --UTR=on! Reducing the number of cores will also reduce RAM consumption.
UTR prediction sometimes improves coding sequence prediction accuracy, but not always. If you try this feature, carefully compare results with and without UTR parameters, afterwards (eg in UCSC Genome Browser).
For running BRAKER without UTR parameters, it is not very important whether RNA-Seq data was generated by a stranded protocol (because spliced alignments are 'artificially stranded' by checking the splice site pattern). However, for UTR training and prediction, stranded libraries may provide information that is valuable for BRAKER.
After alignment of the stranded RNA-Seq libraries, separate the resulting bam file entries into two files: one for plus strand mappings, one for minus strand mappings. Call BRAKER as follows:
braker.pl --species=yourSpecies --genome=genome.fasta
--bam=plus.bam,minus.bam --stranded=+,-
--UTR=on
You may additionally include bam files from unstranded libraries. Those files will not used for generating UTR training examples, but they will be included in the final gene prediction step as unstranded coverage information, example call:
braker.pl --species=yourSpecies --genome=genome.fasta
--bam=plus.bam,minus.bam,unstranded.bam
--stranded=+,-,. --UTR=on
Warning: This feature is experimental and currently has low priority on our maintenance list!
The native mode for running BRAKER with RNA-Seq and protein data. This will call GeneMark-ETP, which will use RNA-Seq and protein hints for training GeneMark-ETP. Subsequently, AUGUSTUS is trained on 'high-confindent' genes (genes with very high extrinsic evidence support) from the GeneMark-ETP prediction and a set of genes is predicted by AUGUSTUS. In a last step, the predictions of AUGUSTUS and GeneMark-ETP are combined using TSEBRA.
Alignment of RNA-Seq reads
GeneMark-ETP utilizes Stringtie2 to assemble RNA-Seq data, which requires that the aligned reads (BAM files) contain the XS (strand) tag for spliced reads. Therefore, if you align your reads with HISAT2, you must enable the --dta option, or if you use STAR, you must use the --outSAMstrandField intronMotif option. TopHat alignments include this tag by default.
To call the pipeline in this mode, you have to provide it with a protein database using --prot_seq (as described in BRAKER with protein data), and RNA-Seq data either by their SRA ID so that they are downloaded by BRAKER, as unaligned reads in FASTQ format, and/or as aligned reads in bam format (as described in BRAKER with RNA-Seq data). You could also specify already processed extrinsic evidence using the --hints option. However, this is not recommend for a normal BRAKER run in ETPmode, as these hints won't be used in the GeneMark-ETP step. Only use --hints when you want to skip the GenMark-ETP step!
Examples of how you could run BRAKER in ETPmode:
braker.pl --genome=genome.fa --prot_seq=orthodb.fa
--rnaseq_sets_ids=SRA_ID1,SRA_ID2
--rnaseq_sets_dirs=/path/to/local/RNA-Seq/files/
braker.pl --genome=genome.fa --prot_seq=orthodb.fa
--rnaseq_sets_ids=SRA_ID1,SRA_ID2,SRA_ID3
braker.pl --genome=genome.fa --prot_seq=orthodb.fa
--bam=/path/to/SRA_ID1.bam,/path/to/SRA_ID2.bam
A preliminary protocol for integration of assembled subreads from PacBio ccs sequencing in combination with short read Illumina RNA-Seq and protein database is described at https://github.com/Gaius-Augustus/BRAKER/blob/master/docs/long_reads/long_read_protocol.md
We forked GeneMark-ETP and hard coded that StringTie will perform long read assembly in that particular version. If you want to use this 'fast-hack' version for BRAKER, you have to prepare the BAM file with long read to genome spliced alignments outside of BRAKER, eg:
T=48 # adapt to your number of threads
minimap2 -t${T} -ax splice:hq -uf genome.fa isoseq.fa > isoseq.sam
samtools view -bS --threads ${T} isoseq.sam -o isoseq.bam
Pull the adapted container:
singularity build braker3_lr.sif docker://teambraker/braker3:isoseq
Calling BRAKER3 with a BAM file of spliced-aligned IsoSeq Reads:
singularity exec -B ${PWD}:${PWD} braker3_lr.sif braker.pl --genome=genome.fa --prot_seq=protein_db.fa –-bam=isoseq.bam --threads=${T}
Warning Do NOT mix short read and long read data in this BRAKER/GeneMark-ETP variant!
Warning The accuracy of gene prediction here heavily depends on the depth of your isoseq data. We verified with PacBio HiFi reads from 2022 that given sufficient completeness of the assembled transcriptome you will reach similar results as with short reads. However, we also observed a drop in accuracy compared to short reads when using other long read data sets with higher error rates and less sequencing depth.
Please run braker.pl --help to obtain a full list of options.
Compute AUGUSTUS ab initio predictions in addition to AUGUSTUS predictions with hints (additional output files: augustus.ab_initio.* . This may be useful for estimating the quality of training gene parameters when inspecting predictions in a Browser.
One or several command line arguments to be passed to AUGUSTUS, if several arguments are given, separate them by whitespace, ie "--first_arg=sth --second_arg=sth" . This may be be useful if you know that gene prediction in your particular species benefits from a particular AUGUSTUS argument during the prediction step.
Specifies the maximum number of threads that can be used during computation. BRAKER has to run some steps on a single thread, others can take advantage of multiple threads. If you use more than 8 threads, this will not speed up all parallelized steps, in particular, the time consuming optimize_augustus.pl will not use more than 8 threads. However, if you don't mind some threads being idle, using more than 8 threads will speed up other steps.
GeneMark-ETP option: run algorithm with branch point model. Use this option if you genome is a fungus.
Use the present config and parameter files if they exist for 'species'; will overwrite original parameters if BRAKER performs an AUGUSTUS training.
Execute CRF training for AUGUSTUS; resulting parameters are only kept for final predictions if they show higher accuracy than HMM parameters. This increases runtime!
Change the parameter
Generate UTR training examples for AUGUSTUS from RNA-Seq coverage information, train AUGUSTUS UTR parameters and predict genes with AUGUSTUS and UTRs, including coverage information for RNA-Seq as evidence. This is an experimental feature!
If you performed a BRAKER run without --UTR=on, you can add UTR parameter training and gene prediction with UTR parameters (and only RNA-Seq hints) with the following command:
braker.pl --genome=../genome.fa --addUTR=on
--bam=../RNAseq.bam --workingdir=$wd
--AUGUSTUS_hints_preds=augustus.hints.gtf
--threads=8 --skipAllTraining --species=somespecies
Modify augustus.hints.gtf to point to the AUGUSTUS predictions with hints from previous BRAKER run; modify flaning_DNA value to the flanking region from the log file of your previous BRAKER run; modify some_new_working_directory to the location where BRAKER should store results of the additional BRAKER run; modify somespecies to the species name used in your previous BRAKER run.
Add UTRs from RNA-Seq converage information to AUGUSTUS gene predictions using GUSHR. No training of UTR parameters and no gene prediction with UTR parameters is performed.
If you performed a BRAKER run without --addUTR=on, you can add UTRs results of a previous BRAKER run with the following command:
braker.pl --genome=../genome.fa --addUTR=on
--bam=../RNAseq.bam --workingdir=$wd
--AUGUSTUS_hints_preds=augustus.hints.gtf --threads=8
--skipAllTraining --species=somespecies
Modify augustus.hints.gtf to point to the AUGUSTUS predictions with hints from previous BRAKER run; modify some_new_working_directory to the location where BRAKER should store results of the additional BRAKER run; this run will not modify AUGUSTUS parameters. We recommend that you specify the original species of the original run with --species=somespecies . Otherwise, BRAKER will create an unneeded species parameters directory Sp_* .
If --UTR=on is enabled, strand-separated bam-files can be provided with --bam=plus.bam,minus.bam . In that case, --stranded=... should hold the strands of the bam files ( + for plus strand, - for minus strand, . for unstranded). Note that unstranded data will be used in the gene prediction step, only, if the parameter --stranded=... is set. This is an experimental feature! GUSHR currently does not take advantage of stranded data.
If --makehub and [email protected] (with your valid e-mail adress) are provided, a track data hub for visualizing results with the UCSC Genome Browser will be generated using MakeHub (https://github.com/Gaius-Augustus/MakeHub).
By default, GeneMark-ES/ET/EP/ETP uses a probability of 0.001 for predicting the donor splice site pattern GC (instead of GT). It may make sense to increase this value for species where this donor splice site is more common. For example, in the species Emiliania huxleyi , about 50% of donor splice sites have the pattern GC (https://media.nature.com/original/nature-assets/nature/journal/v499/n7457/extref/nature12221-s2.pdf, page 5).
Use a species-specific lineage, eg arthropoda_odb10 for an arthropod. BRAKER does not support auto-typing of the lineage.
Specifying a BUSCO-lineage invokes two changes in BRAKER R28 :
BRAKER will run compleasm with the specified lineage in genome mode and convert the detected BUSCO matches into hints for AUGUSTUS. This may increase the number of BUSCOs in the augustus.hints.gtf file slightly.
BRAKER will invoke best_by_compleasm.py to check whether the braker.gtf file that is by default generated by TSEBRA has the lowest amount of missing BUSCOs compared to the augustus.hints.gtf and the genemark.gtf file. If not, the following decision schema is applied to re-run TSEBRA to minimize the missing BUSCOs in the final output of BRAKER (always braker.gtf). If an alternative and better gene set is created, the original braker.gtf gene set is moved to a directory called braker_original. Information on what happened during the best_by_compleasm.py run is written to the file best_by_compleasm.log.
![best_by_busco[fig14]](https://images.downcodes.com/uploads/20250214/img_67aee79a11fd439.png)
Please note that using BUSCO to assess the quality of a gene set, in particular when comparing BRAKER to other pipelines, does not make sense once you specified a BUSCO lineage. We recommend that you use other measures to assess the quality of your gene set, eg by comparing it to a reference gene set or running OMArk.
BRAKER produces several important output files in the working directory.
braker.gtf: Final gene set of BRAKER. This file may contain different contents depending on how you called BRAKER
in ETPmode: Final gene set of BRAKER consisting of genes predicted by AUGUSTUS and GeneMark-ETP that were combined and filtered by TSEBRA.
otherwise: Union of augustus.hints.gtf and reliable GeneMark-ES/ET/EP predictions (genes fully supported by external evidence). In --esmode , this is the union of augustus.ab_initio.gtf and all GeneMark-ES genes. Thus, this set is generally more sensitive (more genes correctly predicted) and can be less specific (more false-positive predictions can be present). This output is not necessarily better than augustus.hints.gtf, and it is not recommended to use it if BRAKER was run in ESmode.
braker.codingseq: Final gene set with coding sequences in FASTA format
braker.aa: Final gene set with protein sequences in FASTA format
braker.gff3: Final gene set in gff3 format (only produced if the flag --gff3 was specified to BRAKER.
Augustus/*: Augustus gene set(s) in as gtf/conding/aa files
GeneMark-E*/genemark.gtf: Genes predicted by GeneMark-ES/ET/EP/EP+/ETP in GTF-format.
hintsfile.gff: The extrinsic evidence data extracted from RNAseq.bam and/or protein data.
braker_original/*: Genes predicted by BRAKER (TSEBRA merge) before compleasm was used to improve BUSCO completeness
bbc/*: output folder of best_by_compleasm.py script from TSEBRA that is used to improve BUSCO completeness in the final output of BRAKER
Output files may be present with the following name endings and formats:
Coding sequences in FASTA-format are produced if the flag --skipGetAnnoFromFasta was not set.
Protein sequence files in FASTA-format are produced if the flag --skipGetAnnoFromFasta was not set.
For details about gtf format, see http://www.sanger.ac.uk/Software/formats/GFF/. A GTF-format file contains one line per predicted exon. 예:
HS04636 AUGUSTUS initial 966 1017 . + 0 transcript_id "g1.1"; gene_id "g1";
HS04636 AUGUSTUS internal 1818 1934 . + 2 transcript_id "g1.1"; gene_id "g1";
The columns (fields) contain:
seqname source feature start end score strand frame transcript ID and gene ID
If the --makehub option was used and MakeHub is available on your system, a hub directory beginning with the name hub_ will be created. Copy this directory to a publicly accessible web server. A file hub.txt resides in the directory. Provide the link to that file to the UCSC Genome Browser for visualizing results.
An incomplete example data set is contained in the directory BRAKER/example . In order to complete the data set, please download the RNA-Seq alignment file (134 MB) with wget :
cd BRAKER/example
wget http://topaz.gatech.edu/GeneMark/Braker/RNAseq.bam
In case you have trouble accessing that file, there's also a copy available from another server:
cd BRAKER/example
wget http://bioinf.uni-greifswald.de/augustus/datasets/RNAseq.bam
The example data set was not compiled in order to achieve optimal prediction accuracy, but in order to quickly test pipeline components. The small subset of the genome used in these test examples is not long enough for BRAKER training to work well.
Data corresponds to the last 1,000,000 nucleotides of Arabidopsis thaliana 's chromosome Chr5, split into 8 artificial contigs.
RNA-Seq alignments were obtained by VARUS.
The protein sequences are a subset of OrthoDB v10 plants proteins.
List of files:
genome.fa - genome file in fasta formatRNAseq.bam - RNA-Seq alignment file in bam format (this file is not a part of this repository, it must be downloaded separately from http://topaz.gatech.edu/GeneMark/Braker/RNAseq.bam)RNAseq.hints - RNA-Seq hints (can be used instead of RNAseq.bam as RNA-Seq input to BRAKER)proteins.fa - protein sequences in fasta formatThe below given commands assume that you configured all paths to tools by exporting bash variables or that you have the necessary tools in your $PATH.
The example data set also contains scripts tests/test*.sh that will execute below listed commands for testing BRAKER with the example data set. You find example results of AUGUSTUS and GeneMark-ES/ET/EP/ETP in the folder results/test* . Be aware that BRAKER contains several parts where random variables are used, ie results that you obtain when running the tests may not be exactly identical. To compare your test results with the reference ones, you can use the compare_intervals_exact.pl script as follows:
# Compare CDS features
compare_intervals_exact.pl --f1 augustus.hints.gtf --f2 ../../results/test${N}/augustus.hints.gtf --verbose
# Compare transcripts
compare_intervals_exact.pl --f1 augustus.hints.gtf --f2 ../../results/test${N}/augustus.hints.gtf --trans --verbose
Several tests use --gm_max_intergenic 10000 option to make the test runs faster. It is not recommended to use this option in real BRAKER runs, the speed increase achieved by adjusting this option is negligible on full-sized genomes.
We give runtime estimations derived from computing on Intel(R) Xeon(R) CPU E5530 @ 2.40GHz .
The following command will run the pipeline according to Figure 3:
braker.pl --genome genome.fa --bam RNAseq.bam --threads N --busco_lineage=lineage_odb10
This test is implemented in test1.sh , expected runtime is ~20 minutes.
The following command will run the pipeline according to Figure 4:
braker.pl --genome genome.fa --prot_seq proteins.fa --threads N --busco_lineage=lineage_odb10
This test is implemented in test2.sh , expected runtime is ~20 minutes.
The following command will run a pipeline that first trains GeneMark-ETP with protein and RNA-Seq hints and subsequently trains AUGUSTUS on the basis of GeneMark-ETP predictions. AUGUSTUS predictions are also performed with hints from both sources, see Figure 5.
Run with local RNA-Seq file:
braker.pl --genome genome.fa --prot_seq proteins.fa --bam ../RNAseq.bam --threads N --busco_lineage=lineage_odb10
This test is implemented in test3.sh , expected runtime is ~20 minutes.
Download RNA-Seq library from Sequence Read Archive (~1gb):
braker.pl --genome genome.fa --prot_seq proteins.fa --rnaseq_sets_ids ERR5767212 --threads N --busco_lineage=lineage_odb10
This test is implemented in test3_4.sh , expected runtime is ~35 minutes.
The training step of all pipelines can be skipped with the option --skipAllTraining . This means, only AUGUSTUS predictions will be performed, using pre-trained, already existing parameters. For example, you can predict genes with the command:
braker.pl --genome=genome.fa --bam RNAseq.bam --species=arabidopsis
--skipAllTraining --threads N
This test is implemented in test4.sh , expected runtime is ~1 minute.
The following command will run the pipeline with no extrinsic evidence:
braker.pl --genome=genome.fa --esmode --threads N
This test is implemented in test5.sh , expected runtime is ~20 minutes.
The following command will run BRAKER with training UTR parameters from RNA-Seq coverage data:
braker.pl --genome genome.fa --bam RNAseq.bam --UTR=on --threads N
This test is implemented in test6.sh , expected runtime is ~20 minutes.
The following command will add UTRs to augustus.hints.gtf from RNA-Seq coverage data:
braker.pl --genome genome.fa --bam RNAseq.bam --addUTR=on --threads N
This test is implemented in test7.sh , expected runtime is ~20 minutes.
There is currently no clean way to restart a failed BRAKER run (after solving some problem). However, it is possible to start a new BRAKER run based on results from a previous run -- given that the old run produced the required intermediate results. We will in the following refer to the old working directory with variable ${BRAKER_OLD} , and to the new BRAKER working directory with ${BRAKER_NEW} . The file what-to-cite.txt will always only refer to the software that was actually called by a particular run. You might have to combine the contents of ${BRAKER_NEW}/what-to-cite.txt with ${BRAKER_OLD}/what-to-cite.txt for preparing a publication. The following figure illustrates at which points BRAKER run may be intercepted.
![braker-intercept[fig8]](https://images.downcodes.com/uploads/20250214/img_67aee79a12cab310.png)
Figure 10: Points for intercepting a BRAKER run and reusing intermediate results in a new BRAKER run.
This option is only possible for BRAKER in ETmode or EPmode and ~ 아니다 in ETPmode!
If you have access to an existing BRAKER output that contains hintsfiles that were generated from extrinsic data, such as RNA-Seq or protein sequences, you can recycle these hints files in a new BRAKER run. Also, hints from a separate ProtHint run can be directly used in BRAKER.
The hints can be given to BRAKER with --hints ${BRAKER_OLD}/hintsfile.gff option. This is illustrated in the test files test1_restart1.sh , test2_restart1.sh , test4_restart1.sh . The other modes (for which this test is missing) cannot be restarted in this way.
The GeneMark result can be given to BRAKER with --geneMarkGtf ${BRAKER_OLD}/GeneMark*/genemark.gtf option if BRAKER is run in ETmode or EPmode. This is illustrated in the test files test1_restart2.sh , test2_restart2.sh , test5_restart2.sh .
In ETPmode, you can either provide BRAKER with the results of the GeneMarkETP step manually, with --geneMarkGtf ${BRAKER_OLD}/GeneMark-ETP/proteins.fa/genemark.gtf , --traingenes ${BRAKER_OLD}/GeneMark-ETP/training.gtf , and --hints ${BRAKER_OLD}/hintsfile.gff (see test3_restart1.sh for an example), or you can specify the previous GeneMark-ETP results with the option --gmetp_results_dir ${BRAKER_OLD}/GeneMark-ETP/ so that BRAKER can search for the files automatically (see test3_restart2.sh for an example).
The trained species parameters for AGUSTUS can be passed with --skipAllTraining and --species $speciesName options. This is illustrated in test*_restart3.sh files. Note that in ETPmode you have to specify the GeneMark files as described in Option 2!
Before reporting bugs, please check that you are using the most recent versions of GeneMark-ES/ET/EP/ETP, AUGUSTUS and BRAKER. Also, check the list of Common problems, and the Issue list on GitHub before reporting bugs. We do monitor open issues on GitHub. Sometimes, we are unable to help you, immediately, but we try hard to solve your problems.
If you found a bug, please open an issue at https://github.com/Gaius-Augustus/BRAKER/issues (or contact [email protected] or [email protected]).
Information worth mentioning in your bug report:
Check in braker/yourSpecies/braker.log at which step braker.pl crashed.
There are a number of other files that might be of interest, depending on where in the pipeline the problem occurred. Some of the following files will not be present if they did not contain any errors.
braker/yourSpecies/errors/bam2hints.*.stderr - will give details on a bam2hints crash (step for converting bam file to intron gff file)
braker/yourSpecies/hintsfile.gff - is this file empty? If yes, something went wrong during hints generation - does this file contain hints from source “b2h” and of type “intron”? If not: GeneMark-ET will not be able to execute properly. Conversely, GeneMark-EP+ will not be able to execute correctly if hints from the source "ProtHint" are missing.
braker/yourSpecies/spaln/*err - errors reported by spaln
braker/yourSpecies/errors/GeneMark-{ET,EP,ETP}.stderr - errors reported by GeneMark-ET/EP+/ETP
braker/yourSpecies/errors/GeneMark-{ET,EP,ETP).stdout - may give clues about the point at which errors in GeneMark-ET/EP+/ETP occured
braker/yourSpecies/GeneMark-{ET,EP,ETP}/genemark.gtf - is this file empty? If yes, something went wrong during executing GeneMark-ET/EP+/ETP
braker/yourSpecies/GeneMark-{ET,EP}/genemark.f.good.gtf - is this file empty? If yes, something went wrong during filtering GeneMark-ET/EP+ genes for training AUGUSTUS
braker/yourSpecies/genbank.good.gb - try a “grep -c LOCUS genbank.good.gb” to determine the number of training genes for training AUGUSTUS, should not be low
braker/yourSpecies/errors/firstetraining.stderr - contains errors from first iteration of training AUGUSTUS
braker/yourSpecies/errors/secondetraining.stderr - contains errors from second iteration of training AUGUSTUS
braker/yourSpecies/errors/optimize_augustus.stderr - contains errors optimize_augustus.pl (additional training set for AUGUSTUS)
braker/yourSpecies/errors/augustus*.stderr - contain AUGUSTUS execution errors
braker/yourSpecies/startAlign.stderr - if you provided a protein fasta file, something went wrong during protein alignment
braker/yourSpecies/startAlign.stdout - may give clues on at which point protein alignment went wrong
BRAKER complains that the RNA-Seq file does not correspond to the provided genome file, but I am sure the files correspond to each other!
Please check the headers of the genome FASTA file. If the headers are long and contain whitespaces, some RNA-Seq alignment tools will truncate sequence names in the BAM file. This leads to an error with BRAKER. Solution: shorten/simplify FASTA headers in the genome file before running the RNA-Seq alignment and BRAKER.
GeneMark fails!
(a) GeneMark by default only uses contigs longer than 50k for training. If you have a highly fragmented assembly, this might lead to "no data" for training. You can override the default minimal length by setting the BRAKER argument --min_contig=10000 .
(b) see "[something] failed to execute" below.
[something] failed to execute!
When providing paths to software to BRAKER, please use absolute, non-abbreviated paths. For example, BRAKER might have problems with --SAMTOOLS_PATH=./samtools/ or --SAMTOOLS_PATH=~/samtools/ . Please use SAMTOOLS_PATH=/full/absolute/path/to/samtools/ , instead. This applies to all path specifications as command line options to braker.pl . Relative paths and absolute paths will not pose problems if you export a bash variable, instead, or if you append the location of tools to your $PATH variable.
GeneMark-ETP in BRAKER dies with '/scratch/11232323': No such file or directory.
This appears to be related to sorting large files, and it's a system configuration depending problem. Solve it with export TMPDIR=/tmp/ before calling BRAKER via Singularity.
BRAKER cannot find the Augustus script XYZ...
Update Augustus from github with git clone https://github.com/Gaius-Augustus/Augustus.git . Do not use Augustus from other sources. BRAKER is highly dependent on an up-to-date Augustus. Augustus releases happen rather rarely, updates to the Augustus scripts folder occur rather frequently.
Does BRAKER depend on Python3?
It does. The python scripts employed by BRAKER are not compatible with Python2.
Why does BRAKER predict more genes than I expected?
If transposable elements (or similar) have not been masked appropriately, AUGUSTUS tends to predict those elements as protein coding genes. This can lead to a huge number genes. You can check whether this is the case for your project by BLASTing (or DIAMONDing) the predicted protein sequences against themselves (all vs. all) and counting how many of the proteins have a high number of high quality matches. You can use the output of this analysis to divide your gene set into two groups: the protein coding genes that you want to find and the repetitive elements that were additionally predicted.
I am running BRAKER in Anaconda and something fails...
Update AUGUSTUS and BRAKER from github with git clone https://github.com/Gaius-Augustus/Augustus.git and git clone https://github.com/Gaius-Augustus/BRAKER.git . The Anaconda installation is great, but it relies on releases of AUGUSTUS and BRAKER - which are often lagging behind. Please use the current GitHub code, instead.
Why and where is the GenomeThreader support gone?
BRAKER is a joint project between teams from University of Greifswald and Georgia Tech. While the group of Mark Bordovsky from Georgia Tech contributes GeneMark expertise, the group of Mario Stanke from University of Greifswald contributes AUGUSTUS expertise. Using GenomeThreader to build training genes for AUGUSTUS in BRAKER circumvents execution of GeneMark. Thus, the GenomeThreader mode is strictly speaking not part of the BRAKER project. The previous functionality of BRAKER with GenomeThreader has been moved to GALBA at https://github.com/Gaius-Augustus/GALBA. Note that GALBA has also undergone extension for using Miniprot instead of GenomeThreader.
My BRAKER gene set has too many BUSCO duplicates!
AUGUSTUS within BRAKER can predict alternative splicing isoforms. Also the merge of the AUGUSTUS and GeneMark gene set by TSEBRA within BRAKER may result in additional isoforms for a single gene. The BUSCO duplicates usually come from alternative splicing isoforms, ie they are expected.
Augustus and/or etraining within BRAKER complain that the file aug_cmdln_parameters.json is missing. Even though I am using the latest Singularity container!
BRAKER copies the AUGUSTUS_CONFIG_PATH folder to a writable location. In older versions of Augustus, that file was indeed not existing. If the local writable copy of a folder already exists, BRAKER will not re-copy it. Simply delete the old folder. (It is often ~/.augustus , so you can simply do rm -rf ~/.augustus ; the folder might be residing in $PWD if your home directory was not writable).
I sit behind a firewall, compleasm cannot download the BUSCO files, what can I do? See Issue #785 (comment)
Since BRAKER is a pipeline that calls several Bioinformatics tools, publication of results obtained by BRAKER requires that not only BRAKER is cited, but also the tools that are called by BRAKER. BRAKER will output a file what-to-cite.txt in the BRAKER working directory, informing you about which exact sources apply to your run.
Always cite:
Stanke, M., Diekhans, M., Baertsch, R. and Haussler, D. (2008). Using native and syntenically mapped cDNA alignments to improve de novo gene finding. Bioinformatics, doi: 10.1093/bioinformatics/btn013.
Stanke. M., Schöffmann, O., Morgenstern, B. and Waack, S. (2006). Gene prediction in eukaryotes with a generalized hidden Markov model that uses hints from external sources. BMC Bioinformatics 7, 62.
If you provided any kind of evidence for BRAKER, cite:
If you provided both short read RNA-Seq evidence and a large database of proteins, cite:
Gabriel, L., Bruna, T., Hoff, KJ, Ebel, M., Lomsadze, A., Borodovsky, M., Stanke, M. (2023). BRAKER3: Fully Automated Genome Annotation Using RNA-Seq and Protein Evidence with GeneMark-ETP, AUGUSTUS and TSEBRA. bioRxiV, doi: 10.1101/2023.06.10.54444910.1101/2023.01.01.474747.
Bruna, T., Lomsadze, A., Borodovsky, M. (2023). GeneMark-ETP: Automatic Gene Finding in Eukaryotic Genomes in Consistence with Extrinsic Data. bioRxiv, doi: 10.1101/2023.01.13.524024.
Kovaka, S., Zimin, AV, Pertea, GM, Razaghi, R., Salzberg, SL, & Pertea, M. (2019). Transcriptome assembly from long-read RNA-seq alignments with StringTie2. Genome biology, 20(1):1-13.
Pertea, G., & Pertea, M. (2020). GFF utilities: GffRead and GffCompare. F1000Research, 9.
Quinlan, AR (2014). BEDTools: the Swiss‐army tool for genome feature analysis. Current protocols in bioinformatics, 47(1):11-12.
If the only source of evidence for BRAKER was a large database of protein sequences, cite:
If the only source of evidence for BRAKER was RNA-Seq data, cite:
Hoff, KJ, Lange, S., Lomsadze, A., Borodovsky, M. and Stanke, M. (2016). BRAKER1: unsupervised RNA-Seq-based genome annotation with GeneMark-ET and AUGUSTUS. Bioinformatics, 32(5):767-769.
Lomsadze, A., Paul DB, and Mark B. (2014) Integration of Mapped Rna-Seq Reads into Automatic Training of Eukaryotic Gene Finding Algorithm. Nucleic Acids Research 42(15): e119--e119
If you called BRAKER3 with an IsoSeq BAM file, or if you envoked the --busco_lineage option, cite:
If you called BRAKER with the --busco_lineage option, in addition, cite:
Simão, FA, Waterhouse, RM, Ioannidis, P., Kriventseva, EV, & Zdobnov, EM (2015). BUSCO: assessing genome assembly and annotation completeness with single-copy orthologs. Bioinformatics, 31(19), 3210-3212.
Li, H. (2023). Protein-to-genome alignment with miniprot. Bioinformatics, 39(1), btad014.
Huang, N., & Li, H. (2023). compleasm: a faster and more accurate reimplementation of BUSCO. Bioinformatics, 39(10), btad595.
If any kind of AUGUSTUS training was performed by BRAKER, check carefully whether you configured BRAKER to use NCBI BLAST or DIAMOND. One of them was used to filter out redundant training gene structures.
If you used NCBI BLAST, please cite:
Altschul, AF, Gish, W., Miller, W., Myers, EW and Lipman, DJ (1990). A basic local alignment search tool. J Mol Biol 215:403--410.
Camacho, C., Coulouris, G., Avagyan, V., Ma, N., Papadopoulos, J., Bealer, K., and Madden, TL (2009). Blast+: architecture and applications. BMC bioinformatics, 10(1):421.
If you used DIAMOND, please cite:
If BRAKER was executed with a genome file and no extrinsic evidence, cite, then GeneMark-ES was used, cite:
Lomsadze, A., Ter-Hovhannisyan, V., Chernoff, YO and Borodovsky, M. (2005). Gene identification in novel eukaryotic genomes by self-training algorithm. Nucleic Acids Research, 33(20):6494--6506.
Ter-Hovhannisyan, V., Lomsadze, A., Chernoff, YO and Borodovsky, M. (2008). Gene prediction in novel fungal genomes using an ab initio algorithm with unsupervised training. Genome research, pages gr--081612, 2008.
Hoff, KJ, Lomsadze, A., Borodovsky, M. and Stanke, M. (2019). Whole-Genome Annotation with BRAKER. Methods Mol Biol. 1962:65-95, doi: 10.1007/978-1-4939-9173-0_5.
If BRAKER was run with proteins as source of evidence, please cite all tools that are used by the ProtHint pipeline to generate hints:
Bruna, T., Lomsadze, A., & Borodovsky, M. (2020). GeneMark-EP+: eukaryotic gene prediction with self-training in the space of genes and proteins. NAR Genomics and Bioinformatics, 2(2), lqaa026.
Buchfink, B., Xie, C., Huson, DH (2015). Fast and sensitive protein alignment using DIAMOND. Nature Methods 12:59-60.
Lomsadze, A., Ter-Hovhannisyan, V., Chernoff, YO and Borodovsky, M. (2005). Gene identification in novel eukaryotic genomes by self-training algorithm. Nucleic Acids Research, 33(20):6494--6506.
Iwata, H., and Gotoh, O. (2012). Benchmarking spliced alignment programs including Spaln2, an extended version of Spaln that incorporates additional species-specific features. Nucleic acids research, 40(20), e161-e161.
Gotoh, O., Morita, M., Nelson, DR (2014). Assessment and refinement of eukaryotic gene structure prediction with gene-structure-aware multiple protein sequence alignment. BMC bioinformatics, 15(1), 189.
If BRAKER was executed with RNA-Seq alignments in bam-format, then SAMtools was used, cite:
Li, H., Handsaker, B., Wysoker, A., Fennell, T., Ruan, J., Homer, N., Marth, G., Abecasis, G., Durbin, R.; 1000 Genome Project Data Processing Subgroup (2009). The Sequence Alignment/Map format and SAMtools. Bioinformatics, 25(16):2078-9.
Barnett, DW, Garrison, EK, Quinlan, AR, Strömberg, MP and Marth GT (2011). BamTools: a C++ API and toolkit for analyzing and managing BAM files. Bioinformatics, 27(12):1691-2
If BRAKER downloaded RNA-Seq libraries from SRA using their IDs, cite SRA, SRA toolkit, and HISAT2:
Leinonen, R., Sugawara, H., Shumway, M., & International Nucleotide Sequence Database Collaboration. (2010). The sequence read archive. Nucleic acids research, 39(suppl_1), D19-D21.
SRA Toolkit Development Team (2020). SRA Toolkit. https://trace.ncbi.nlm.nih.gov/Traces/sra/sra.cgi?view=software.
Kim, D., Paggi, JM, Park, C., Bennett, C., & Salzberg, SL (2019). Graph-based genome alignment and genotyping with HISAT2 and HISAT-genotype. Nature biotechnology, 37(8):907-915.
If BRAKER was executed using RNA-Seq data in FASTQ format, cite HISAT2:
If BRAKER called MakeHub for creating a track data hub for visualization of BRAKER results with the UCSC Genome Browser, cite:
If BRAKER called GUSHR for generating UTRs, cite:
Keilwagen, J., Hartung, F., Grau, J. (2019) GeMoMa: Homology-based gene prediction utilizing intron position conservation and RNA-seq data. Methods Mol Biol. 1962:161-177, doi: 10.1007/978-1-4939-9173-0_9.
Keilwagen, J., Wenk, M., Erickson, JL, Schattat, MH, Grau, J., Hartung F. (2016) Using intron position conservation for homology-based gene prediction. Nucleic Acids Research, 44(9):e89.
Keilwagen, J., Hartung, F., Paulini, M., Twardziok, SO, Grau, J. (2018) Combining RNA-seq data and homology-based gene prediction for plants, animals and fungi. BMC Bioinformatics, 19(1):189.
All source code, ie scripts/*.pl or scripts/*.py are under the Artistic License (see http://www.opensource.org/licenses/artistic-license.php).
[F1] EX = ES/ET/EP/ETP, all available for download under the name GeneMark-ES/ET/EP ↩
[F2] Please use the latest version from the master branch of AUGUSTUS distributed by the original developers, it is available from github at https://github.com/Gaius-Augustus/Augustus. Problems have been reported from users that tried to run BRAKER with AUGUSTUS releases maintained by third parties, ie Bioconda. ↩
[F4] install with sudo apt-get install cpanminus ↩
[F6] The binary may eg reside in bamtools/build/src/toolkit ↩
[R0] Bruna, Tomas, Hoff, Katharina J., Lomsadze, Alexandre, Stanke, Mario, and Borodovsky, Mark. 2021. “BRAKER2: automatic eukaryotic genome annotation with GeneMark-EP+ and AUGUSTUS supported by a protein database." NAR Genomics and Bioinformatics 3(1):lqaa108.↩
[R1] Hoff, Katharina J, Simone Lange, Alexandre Lomsadze, Mark Borodovsky, and Mario Stanke. 2015. “BRAKER1: Unsupervised Rna-Seq-Based Genome Annotation with Genemark-et and Augustus.” Bioinformatics 32 (5). Oxford University Press: 767--69.↩
[R2] Lomsadze, Alexandre, Paul D Burns, and Mark Borodovsky. 2014. “Integration of Mapped Rna-Seq Reads into Automatic Training of Eukaryotic Gene Finding Algorithm.” Nucleic Acids Research 42 (15). Oxford University Press: e119--e119.↩
[R3] Stanke, Mario, Mark Diekhans, Robert Baertsch, and David Haussler. 2008. “Using Native and Syntenically Mapped cDNA Alignments to Improve de Novo Gene Finding.” Bioinformatics 24 (5). Oxford University Press: 637--44.↩
[R4] Stanke, Mario, Oliver Schöffmann, Burkhard Morgenstern, and Stephan Waack. 2006. “Gene Prediction in Eukaryotes with a Generalized Hidden Markov Model That Uses Hints from External Sources.” BMC Bioinformatics 7 (1). BioMed Central: 62.↩
[R5] Barnett, Derek W, Erik K Garrison, Aaron R Quinlan, Michael P Strömberg, and Gabor T Marth. 2011. “BamTools: A C++ Api and Toolkit for Analyzing and Managing Bam Files.” Bioinformatics 27 (12). Oxford University Press: 1691--2.↩
[R6] Li, Heng, Handsaker, Bob, Alec Wysoker, Tim Fennell, Jue Ruan, Nils Homer, Gabor Marth, Goncalo Abecasis, and Richard Durbin. 2009. “The Sequence Alignment/Map Format and Samtools.” Bioinformatics 25 (16). Oxford University Press: 2078--9.↩
[R7] Gremme, G. 2013. “Computational Gene Structure Prediction.” PhD thesis, Universität Hamburg.↩
[R8] Gotoh, Osamu. 2008a. “A Space-Efficient and Accurate Method for Mapping and Aligning cDNA Sequences onto Genomic Sequence.” Nucleic Acids Research 36 (8). Oxford University Press: 2630--8.↩
[R9] Iwata, Hiroaki, and Osamu Gotoh. 2012. “Benchmarking Spliced Alignment Programs Including Spaln2, an Extended Version of Spaln That Incorporates Additional Species-Specific Features.” Nucleic Acids Research 40 (20). Oxford University Press: e161--e161.↩
[R10] Osamu Gotoh. 2008b. “Direct Mapping and Alignment of Protein Sequences onto Genomic Sequence.” Bioinformatics 24 (21). Oxford University Press: 2438--44.↩
[R11] Slater, Guy St C, and Ewan Birney. 2005. “Automated Generation of Heuristics for Biological Sequence Comparison.” BMC Bioinformatics 6(1). BioMed Central: 31.↩
[R12] Altschul, SF, W. Gish, W. Miller, EW Myers, and DJ Lipman. 1990. “Basic Local Alignment Search Tool.” Journal of Molecular Biology 215:403--10.↩
[R13] Camacho, Christiam, et al. 2009. “BLAST+: architecture and applications.“ BMC Bioinformatics 1(1): 421.↩
[R14] Lomsadze, A., V. Ter-Hovhannisyan, YO Chernoff, and M. Borodovsky. 2005. “Gene identification in novel eukaryotic genomes by self-training algorithm.” Nucleic Acids Research 33 (20): 6494--6506. doi:10.1093/nar/gki937.↩
[R15] Ter-Hovhannisyan, Vardges, Alexandre Lomsadze, Yury O Chernoff, and Mark Borodovsky. 2008. “Gene Prediction in Novel Fungal Genomes Using an Ab Initio Algorithm with Unsupervised Training.” Genome Research . Cold Spring Harbor Lab, gr--081612.↩
[R16] Hoff, KJ 2019. MakeHub: Fully automated generation of UCSC Genome Browser Assembly Hubs. Genomics, Proteomics and Bioinformatics , in press, preprint on bioarXive, doi: https://doi.org/10.1101/550145.↩
[R17] Bruna, T., Lomsadze, A., & Borodovsky, M. 2020. GeneMark-EP+: eukaryotic gene prediction with self-training in the space of genes and proteins. NAR Genomics and Bioinformatics, 2(2), lqaa026. doi: https://doi.org/10.1093/nargab/lqaa026.↩
[R18] Kriventseva, EV, Kuznetsov, D., Tegenfeldt, F., Manni, M., Dias, R., Simão, FA, and Zdobnov, EM 2019. OrthoDB v10: sampling the diversity of animal, plant, fungal, protist, bacterial and viral genomes for evolutionary and functional annotations of orthologs. Nucleic Acids Research, 47(D1), D807-D811.↩
[R19] Keilwagen, J., Hartung, F., Grau, J. (2019) GeMoMa: Homology-based gene prediction utilizing intron position conservation and RNA-seq data. Methods Mol Biol. 1962:161-177, doi: 10.1007/978-1-4939-9173-0_9.↩
[R20] Keilwagen, J., Wenk, M., Erickson, JL, Schattat, MH, Grau, J., Hartung F. (2016) Using intron position conservation for homology-based gene prediction. Nucleic Acids Research, 44(9):e89.↩
[R21] Keilwagen, J., Hartung, F., Paulini, M., Twardziok, SO, Grau, J. (2018) Combining RNA-seq data and homology-based gene prediction for plants, animals and fungi. BMC Bioinformatics, 19(1):189.↩
[R22] SRA Toolkit Development Team (2020). SRA Toolkit. https://trace.ncbi.nlm.nih.gov/Traces/sra/sra.cgi?view=software.[↩](#a22)
[R23] Kim, D., Paggi, JM, Park, C., Bennett, C., & Salzberg, SL (2019). Graph-based genome alignment and genotyping with HISAT2 and HISAT-genotype. Nature biotechnology, 37(8):907-915.↩
[R24] Quinlan, AR (2014). BEDTools: the Swiss‐army tool for genome feature analysis. Current protocols in bioinformatics, 47(1):11-12.↩
[R25] Kovaka, S., Zimin, AV, Pertea, GM, Razaghi, R., Salzberg, SL, & Pertea, M. (2019). Transcriptome assembly from long-read RNA-seq alignments with StringTie2. Genome biology, 20(1):1-13.↩
[R26] Pertea, G., & Pertea, M. (2020). GFF utilities: GffRead and GffCompare. F1000Research, 9.↩
[R27] Huang, N., & Li, H. (2023). compleasm: a faster and more accurate reimplementation of BUSCO. Bioinformatics, 39(10), btad595.↩
[R28] Bruna, T., Gabriel, L. & Hoff, KJ (2024). Navigating Eukaryotic Genome Annotation Pipelines: A Route Map to BRAKER, Galba, and TSEBRA. arXiv, https://doi.org/10.48550/arXiv.2403.19416 .↩


