text embeddings inference
v1.5.1
텍스트 임베딩 모델을위한 타오르는 빠른 추론 솔루션.
서열 길이가 512 토큰 인 Nvidia A10에서 Baai/BGE-Base-EN-V1.5에 대한 벤치 마크 :
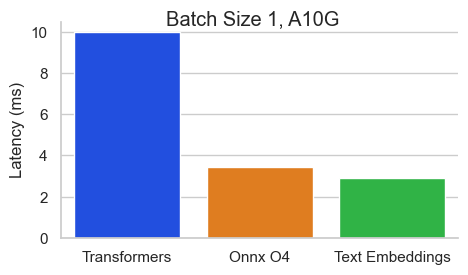
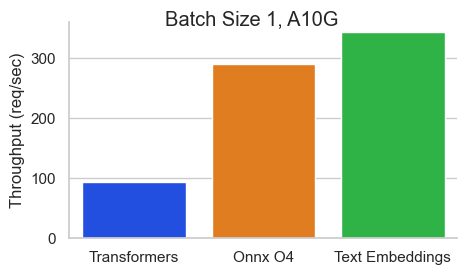
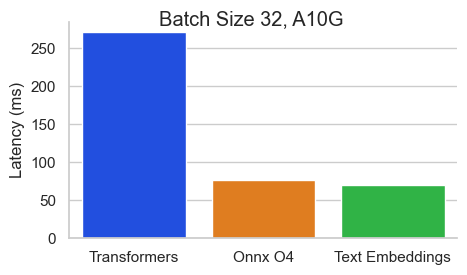
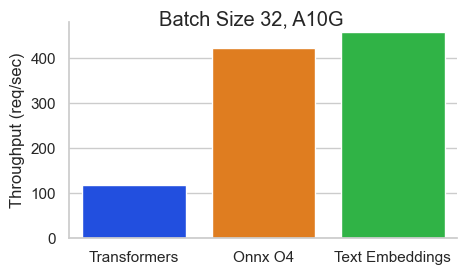
TEI (Text Embeddings Onference)는 오픈 소스 텍스트 임베딩 및 시퀀스 분류 모델을 배포하고 제공하기위한 툴킷입니다. TEI는 Flagembedding, Ember, GTE 및 E5를 포함하여 가장 인기있는 모델에 대한 고성능 추출을 가능하게합니다. TEI는 다음과 같은 많은 기능을 구현합니다.
텍스트 임베딩 추론은 현재 절대 위치를 갖춘 Nomic, Bert, Camembert, XLM-Roberta 모델, Alibi 위치 및 Mistral, Alibaba GTE 및 QWEN2 모델을 가진 Jinabert 모델을 지원합니다.
다음은 현재 지원되는 모델의 몇 가지 예입니다.
| MTEB 순위 | 모델 크기 | 모델 유형 | 모델 ID |
|---|---|---|---|
| 1 | 7B (매우 비싸다) | 미스트랄 | salesforce/sfr-embedding-2_r |
| 2 | 7B (매우 비싸다) | Qwen2 | Alibaba-NLP/GTE-QWEN2-7B- 강조 |
| 9 | 1.5B (비싸다) | Qwen2 | Alibaba-NLP/GTE-QWEN2-1.5B- 강조 |
| 15 | 0.4b | 알리바바 GTE | Alibaba-NLP/GTE-LARGE-EN-V1.5 |
| 20 | 0.3b | 버트 | Whereisai/UAE-Large-V1 |
| 24 | 0.5b | XLM-Roberta | intfloat/다국어 -E5-Large-Instruct |
| N/A | 0.1b | Nomicbert | nomic-AI/nomic-embed-text-v1 |
| N/A | 0.1b | Nomicbert | nomic-AI/nomic-embed-text-v1.5 |
| N/A | 0.1b | Jinabert | Jinaai/Jina-embeddings-V2-Base-En |
| N/A | 0.1b | Jinabert | jinaai/jina-embeddings-v2-base-code |
최상의 성능 텍스트 임베드 모델 목록을 살펴보면 MTEB (Massive Text Embedding Benchmark) 리더 보드를 방문하십시오.
텍스트 임베딩 추론은 현재 Camembert 및 XLM-Roberta 시퀀스 분류 모델을 절대 위치로 지원합니다.
다음은 현재 지원되는 모델의 몇 가지 예입니다.
| 일 | 모델 유형 | 모델 ID |
|---|---|---|
| 재 계정 | XLM-Roberta | BAAI/BGE-RERANKER-LARGE |
| 재 계정 | XLM-Roberta | BAAI/BGE-RERANKER-BASE |
| 재 계정 | gte | Alibaba-NLP/gte-multingual-rancher-base |
| 감정 분석 | 로베르타 | Samlowe/Roberta-Base-go_emotions |
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model그런 다음 요청을 할 수 있습니다
curl 127.0.0.1:8080/embed
-X POST
-d ' {"inputs":"What is Deep Learning?"} '
-H ' Content-Type: application/json '참고 : GPU를 사용하려면 NVIDIA 컨테이너 툴킷을 설치해야합니다. 기계의 NVIDIA 드라이버는 CUDA 버전 12.2 이상과 호환되어야합니다.
모델에 서비스를 제공하는 모든 옵션을 보려면 :
text-embeddings-router --help Usage: text-embeddings-router [OPTIONS]
Options:
--model-id <MODEL_ID>
The name of the model to load. Can be a MODEL_ID as listed on <https://hf.co/models> like `thenlper/gte-base`.
Or it can be a local directory containing the necessary files as saved by `save_pretrained(...)` methods of
transformers
[env: MODEL_ID=]
[default: thenlper/gte-base]
--revision <REVISION>
The actual revision of the model if you're referring to a model on the hub. You can use a specific commit id
or a branch like `refs/pr/2`
[env: REVISION=]
--tokenization-workers <TOKENIZATION_WORKERS>
Optionally control the number of tokenizer workers used for payload tokenization, validation and truncation.
Default to the number of CPU cores on the machine
[env: TOKENIZATION_WORKERS=]
--dtype <DTYPE>
The dtype to be forced upon the model
[env: DTYPE=]
[possible values: float16, float32]
--pooling <POOLING>
Optionally control the pooling method for embedding models.
If `pooling` is not set, the pooling configuration will be parsed from the model `1_Pooling/config.json` configuration.
If `pooling` is set, it will override the model pooling configuration
[env: POOLING=]
Possible values:
- cls: Select the CLS token as embedding
- mean: Apply Mean pooling to the model embeddings
- splade: Apply SPLADE (Sparse Lexical and Expansion) to the model embeddings. This option is only
available if the loaded model is a `ForMaskedLM` Transformer model
- last-token: Select the last token as embedding
--max-concurrent-requests <MAX_CONCURRENT_REQUESTS>
The maximum amount of concurrent requests for this particular deployment.
Having a low limit will refuse clients requests instead of having them wait for too long and is usually good
to handle backpressure correctly
[env: MAX_CONCURRENT_REQUESTS=]
[default: 512]
--max-batch-tokens <MAX_BATCH_TOKENS>
**IMPORTANT** This is one critical control to allow maximum usage of the available hardware.
This represents the total amount of potential tokens within a batch.
For `max_batch_tokens=1000`, you could fit `10` queries of `total_tokens=100` or a single query of `1000` tokens.
Overall this number should be the largest possible until the model is compute bound. Since the actual memory
overhead depends on the model implementation, text-embeddings-inference cannot infer this number automatically.
[env: MAX_BATCH_TOKENS=]
[default: 16384]
--max-batch-requests <MAX_BATCH_REQUESTS>
Optionally control the maximum number of individual requests in a batch
[env: MAX_BATCH_REQUESTS=]
--max-client-batch-size <MAX_CLIENT_BATCH_SIZE>
Control the maximum number of inputs that a client can send in a single request
[env: MAX_CLIENT_BATCH_SIZE=]
[default: 32]
--auto-truncate
Automatically truncate inputs that are longer than the maximum supported size
Unused for gRPC servers
[env: AUTO_TRUNCATE=]
--default-prompt-name <DEFAULT_PROMPT_NAME>
The name of the prompt that should be used by default for encoding. If not set, no prompt will be applied.
Must be a key in the `sentence-transformers` configuration `prompts` dictionary.
For example if ``default_prompt_name`` is "query" and the ``prompts`` is {"query": "query: ", ...}, then the
sentence "What is the capital of France?" will be encoded as "query: What is the capital of France?" because
the prompt text will be prepended before any text to encode.
The argument '--default-prompt-name <DEFAULT_PROMPT_NAME>' cannot be used with '--default-prompt <DEFAULT_PROMPT>`
[env: DEFAULT_PROMPT_NAME=]
--default-prompt <DEFAULT_PROMPT>
The prompt that should be used by default for encoding. If not set, no prompt will be applied.
For example if ``default_prompt`` is "query: " then the sentence "What is the capital of France?" will be
encoded as "query: What is the capital of France?" because the prompt text will be prepended before any text
to encode.
The argument '--default-prompt <DEFAULT_PROMPT>' cannot be used with '--default-prompt-name <DEFAULT_PROMPT_NAME>`
[env: DEFAULT_PROMPT=]
--hf-api-token <HF_API_TOKEN>
Your HuggingFace hub token
[env: HF_API_TOKEN=]
--hostname <HOSTNAME>
The IP address to listen on
[env: HOSTNAME=]
[default: 0.0.0.0]
-p, --port <PORT>
The port to listen on
[env: PORT=]
[default: 3000]
--uds-path <UDS_PATH>
The name of the unix socket some text-embeddings-inference backends will use as they communicate internally
with gRPC
[env: UDS_PATH=]
[default: /tmp/text-embeddings-inference-server]
--huggingface-hub-cache <HUGGINGFACE_HUB_CACHE>
The location of the huggingface hub cache. Used to override the location if you want to provide a mounted disk
for instance
[env: HUGGINGFACE_HUB_CACHE=]
--payload-limit <PAYLOAD_LIMIT>
Payload size limit in bytes
Default is 2MB
[env: PAYLOAD_LIMIT=]
[default: 2000000]
--api-key <API_KEY>
Set an api key for request authorization.
By default the server responds to every request. With an api key set, the requests must have the Authorization
header set with the api key as Bearer token.
[env: API_KEY=]
--json-output
Outputs the logs in JSON format (useful for telemetry)
[env: JSON_OUTPUT=]
--otlp-endpoint <OTLP_ENDPOINT>
The grpc endpoint for opentelemetry. Telemetry is sent to this endpoint as OTLP over gRPC. e.g. `http://localhost:4317`
[env: OTLP_ENDPOINT=]
--otlp-service-name <OTLP_SERVICE_NAME>
The service name for opentelemetry. e.g. `text-embeddings-inference.server`
[env: OTLP_SERVICE_NAME=]
[default: text-embeddings-inference.server]
--cors-allow-origin <CORS_ALLOW_ORIGIN>
Unused for gRPC servers
[env: CORS_ALLOW_ORIGIN=]
텍스트 임베딩 추론 특정 백엔드를 타겟팅하는 데 사용할 수있는 여러 Docker 이미지가 포함 된 선박 :
| 건축학 | 영상 |
|---|---|
| CPU | ghcr.io/huggingface/text-embeddings-inference:cpu-1.5 |
| 볼타 | 지원되지 않습니다 |
| 튜링 (T4, RTX 2000 시리즈, ...) | ghcr.io/huggingface/text-embeddings-inference : turing-1.5 (실험) |
| 암페어 80 (A100, A30) | ghcr.io/huggingface/text-embeddings-inference:1.5 |
| Ampere 86 (A10, A40, ...) | ghcr.io/huggingface/text-embeddings-inference:86-1.5 |
| Ada Lovelace (RTX 4000 시리즈, ...) | ghcr.io/huggingface/text-embeddings-inference:89-1.5 |
| 호퍼 (H100) | ghcr.io/huggingface/text-embeddings-inference:hopper-1.5 (실험) |
경고 : 정밀 문제로 인해 튜링 이미지에 대한 기본적으로 플래시주의가 꺼집니다. USE_FLASH_ATTENTION=True 환경 변수를 사용하여 플래시주의 v1을 켤 수 있습니다.
/docs 경로를 사용하여 text-embeddings-inference REST API의 OpenAPI 문서를 참조 할 수 있습니다. Swagger UI는 https://huggingface.github.io/text-embeddings- inference에서도 사용할 수 있습니다.
text-embeddings-inference 에서 사용한 토큰을 구성하기 위해 HF_API_TOKEN 환경 변수를 활용할 수있는 옵션이 있습니다. 이를 통해 보호 자원에 액세스 할 수 있습니다.
예를 들어:
HF_API_TOKEN=<your cli READ token>또는 Docker와 함께 :
model= < your private model >
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
token= < your cli READ token >
docker run --gpus all -e HF_API_TOKEN= $token -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model공기 갭 환경에서 텍스트 임베딩 추론을 배치하려면 먼저 가중치를 다운로드 한 다음 볼륨을 사용하여 컨테이너 내부에 장착하십시오.
예를 들어:
# (Optional) create a `models` directory
mkdir models
cd models
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/Alibaba-NLP/gte-base-en-v1.5
# Set the models directory as the volume path
volume= $PWD
# Mount the models directory inside the container with a volume and set the model ID
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id /data/gte-base-en-v1.5 text-embeddings-inference V0.4.0 Camembert, Roberta, XLM-Roberta 및 GTE 시퀀스 분류 모델에 대한 지원이 추가되었습니다. 재 랭커 모델은 쿼리와 텍스트 사이의 유사성을 점수하는 단일 클래스의 시퀀스 분류 크로스 코더 모델입니다.
Llamaindex 팀 의이 블로그 포스트를보고 RAG 파이프 라인에서 재 랭커 모델을 사용하여 다운 스트림 성능을 향상시키는 방법을 이해하십시오.
model=BAAI/bge-reranker-large
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model그런 다음 쿼리와 텍스트 목록 사이의 유사성을 다음과 같이 평가할 수 있습니다.
curl 127.0.0.1:8080/rerank
-X POST
-d ' {"query": "What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."]} '
-H ' Content-Type: application/json ' SamLowe/roberta-base-go_emotions 와 같은 클래식 시퀀스 분류 모델을 사용할 수도 있습니다.
model=SamLowe/roberta-base-go_emotions
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model 모델을 배포 한 후에는 predict 엔드 포인트를 사용하여 입력과 가장 관련된 감정을 얻을 수 있습니다.
curl 127.0.0.1:8080/predict
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json 'Bert 및 Distilbert Maskedlm 아키텍처 용 Splade Pooling을 활성화하도록 선택할 수 있습니다.
model=naver/efficient-splade-VI-BT-large-query
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model --pooling splade 모델을 배포 한 후에는 /embed_sparse 엔드 포인트를 사용하여 드문 임베딩을 얻을 수 있습니다.
curl 127.0.0.1:8080/embed_sparse
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json ' text-embeddings-inference OpenTelemetry를 사용하여 분산 추적으로 계측됩니다. 주소를 --otlp-endpoint 인수와 함께 OTLP 컬렉터로 설정 하여이 기능을 사용할 수 있습니다.
text-embeddings-inference 고성능 배포를위한 기본 HTTP API의 대안으로 GRPC API를 제공합니다. API Protobuf 정의는 여기에서 찾을 수 있습니다.
Tei Docker 이미지에 -grpc 태그를 추가하여 GRPC API를 사용할 수 있습니다. 예를 들어:
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5-grpc --model-id $model grpcurl -d ' {"inputs": "What is Deep Learning"} ' -plaintext 0.0.0.0:8080 tei.v1.Embed/Embed 로컬에서 text-embeddings-inference 설치하도록 선택할 수도 있습니다.
먼저 Rust 설치 :
curl --proto ' =https ' --tlsv1.2 -sSf https://sh.rustup.rs | sh그런 다음 실행 :
# On x86
cargo install --path router -F mkl
# On M1 or M2
cargo install --path router -F metal이제 CPU에서 텍스트 임베딩 추론을 시작할 수 있습니다.
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080참고 : 일부 컴퓨터에서는 OpenSSL 라이브러리와 GCC가 필요할 수도 있습니다. Linux 시스템에서 실행 :
sudo apt-get install libssl-dev gcc -yCuda Compute 기능이있는 GPU <7.5는 지원되지 않습니다 (V100, Titan V, GTX 1000 Series, ...).
CUDA와 NVIDIA 드라이버가 설치되어 있는지 확인하십시오. 장치의 NVIDIA 드라이버는 CUDA 버전 12.2 이상과 호환되어야합니다. 또한 Nvidia Binaries를 당신의 길에 추가해야합니다.
export PATH= $PATH :/usr/local/cuda/bin그런 다음 실행 :
# This can take a while as we need to compile a lot of cuda kernels
# On Turing GPUs (T4, RTX 2000 series ... )
cargo install --path router -F candle-cuda-turing -F http --no-default-features
# On Ampere and Hopper
cargo install --path router -F candle-cuda -F http --no-default-features이제 GPU에서 텍스트 임베딩 추론을 시작할 수 있습니다.
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080다음과 같이 CPU 컨테이너를 만들 수 있습니다.
docker build .CUDA 컨테이너를 만들려면 런타임에 사용할 GPU의 컴퓨팅 캡을 알아야합니다.
그런 다음 컨테이너를 만들 수 있습니다.
# Example for Turing (T4, RTX 2000 series, ...)
runtime_compute_cap=75
# Example for A100
runtime_compute_cap=80
# Example for A10
runtime_compute_cap=86
# Example for Ada Lovelace (RTX 4000 series, ...)
runtime_compute_cap=89
# Example for H100
runtime_compute_cap=90
docker build . -f Dockerfile-cuda --build-arg CUDA_COMPUTE_CAP= $runtime_compute_cap여기에 설명 된 바와 같이 MPS-ready, ARM64 Docker 이미지, 금속 / MP는 Docker를 통해 지원되지 않습니다. 이러한 추론은 CPU 결합 될 것이며 M1/M2 ARM CPU 에서이 Docker 이미지를 사용할 때는 매우 느립니다.
docker build . -f Dockerfile --platform=linux/arm64


