pytorch openai transformer lm
1.0.0
이것은 Alec Radford, Karthik Narasimhan, Tim Salimans 및 Ilya Sutskever의 OpenAi의 논문 "생성 사전 훈련에 의한 언어 이해 향상"으로 제공된 텐서 플로 코드의 Pytorch 구현입니다.
이 구현은 Pytorch 모델에서 Tensorflow 구현을 통해 저자가 미리 훈련 한 가중치를로드하는 스크립트 로 구성됩니다.
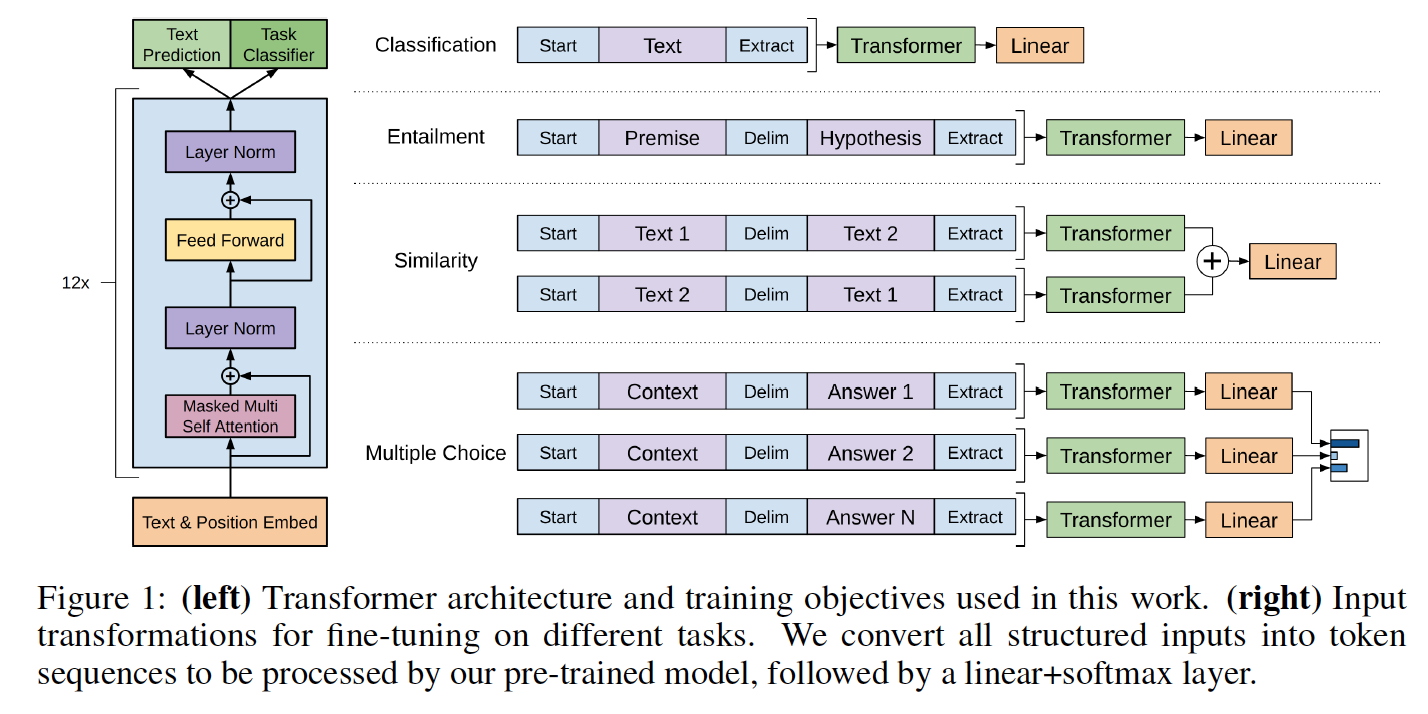
모델 클래스 및로드 스크립트는 Model_PyTorch.py에 있습니다.
Pytorch 모델의 모듈 이름은 Tensorflow 구현의 변수 이름을 따릅니다. 이 구현은 원래 코드를 최대한 밀접하게 따라 불일치를 최소화하려고합니다.
따라서이 구현은 또한 OpenAI의 논문에 사용 된 수정 된 ADAM 최적화 알고리즘으로 구성됩니다.
model_pytorch.py를 가져 와서 Model IT-Self를 사용하려면 다음과 같습니다.
Train.py에서 분류기 교육 스크립트를 실행하려면 다음과 같은 것이 필요합니다.
Alec Radford의 저장소를 복제하고 현재 리포지션에 미리 훈련 된 가중치가 포함 된 model 폴더를 배치하여 OpenAi 사전 훈련 된 버전의 가중치를 다운로드 할 수 있습니다.
이 모델은 다음과 같이 OpenAI의 미리 훈련 된 가중치를 가진 변압기 언어 모델로 사용될 수 있습니다.
from model_pytorch import TransformerModel , load_openai_pretrained_model , DEFAULT_CONFIG
args = DEFAULT_CONFIG
model = TransformerModel ( args )
load_openai_pretrained_model ( model ) 이 모델은 변압기의 숨겨진 상태를 생성합니다. model_pytorch.py의 LMHead 클래스를 사용하여 인코더의 가중치와 묶인 디코더를 추가하고 전체 언어 모델을 얻을 수 있습니다. Model_PyTorch.py의 ClfHead 클래스를 사용하여 변압기 위에 분류기를 추가하고 OpenAI의 간행물에 설명 된대로 분류기를 얻을 수 있습니다. (Train.py의 __main__ 함수에서 둘 다의 예를 참조하십시오)
변압기의 위치 인코더를 사용하려면 utils.py의 encode_dataset() 함수를 사용하여 데이터 세트를 인코딩해야합니다. 어휘를 올바르게 정의하고 데이터 세트를 인코딩하는 방법을 확인하려면 Train.py에서 __main__ 함수의 시작을 참조하십시오.
이 모델은 OpenAI의 논문에 자세히 설명 된대로 분류기에 통합 될 수도 있습니다. Rocstories Cloze 작업에 대한 미세 조정의 예는 Train.py의 교육 코드에 포함됩니다.
Rocstories 데이터 세트는 관련 웹 사이트에서 다운로드 할 수 있습니다.
Tensorflow 코드와 마찬가지로이 코드는 실행을 통해 재현 할 수있는 용지에보고 된 Rocstories Cloze 테스트 결과를 구현합니다.
python -m spacy download en
python train.py --dataset rocstories --desc rocstories --submit --analysis --data_dir [path to data here]Rocstories에서 3 개의 에포크에 대한 Pytorch 모델을 미세 조정하는 것은 단일 Nvidia K-80에서 실행하는 데 10 분이 걸립니다.
이 Pytorch 버전의 단일 실행 테스트 정확도는 85.84%이며, 저자는 텐서 플로 코드 85.8%로 중간 정확도를보고하고 논문은 86.5%의 최상의 단일 런 정확도를보고합니다.
저자 구현은 8 GPU를 사용하므로 64 개의 샘플 배치를 수용 할 수 있으며, 현재 구현은 단일 GPU이며 결과적으로 메모리상의 이유로 K80에서 20 개의 인스턴스로 제한됩니다. 테스트에서 배치 크기를 8에서 20 샘플로 늘리면 테스트 정확도가 2.5 포인트 증가했습니다. 멀티 GPU 설정을 사용하여 더 나은 정확도를 얻을 수 있습니다 (아직 시도되지 않음).
Rocstories 데이터 세트의 이전 SOTA는 77.6%입니다 (Chaturvedi et al.의 "Hidden Coherence Model".


