rag experiment accelerator
1.0.0
Rag Expelerator는 Azure AI 검색 및 헝겊 패턴을 사용하여 실험 및 평가를 수행하는 데 도움이되는 다양한 도구입니다. 이 문서는 목적, 기능, 설치, 사용법 등과 같은이 도구에 대해 알아야 할 모든 것을 다루는 포괄적 인 안내서를 제공합니다.
Rag Experiment Accelerator 의 주요 목표는 OpenAI의 검색 쿼리 및 응답 품질에 대한 실험 및 평가를보다 쉽고 빠르게 실행하는 것입니다. 이 도구는 다음을 원하는 연구원, 데이터 과학자 및 개발자에게 유용합니다.
2024 년 3 월 18 일 : 컨텐츠 샘플링이 추가되었습니다. 이 기능을 통해 데이터 세트를 지정된 백분율로 샘플링 할 수 있습니다. 데이터는 컨텐츠에 의해 클러스터 된 다음 각 클러스터에서 샘플 백분율을 가져와 샘플링 된 데이터의 분포를 시도합니다.
이는 전체 데이터 세트를 가로 질러 샘플의 대표적인 결과를 보장하기 위해 수행됩니다.
참고 : 새로운 종속성으로 인해이 도구를 사용한 경우 환경을 재건하는 것이 좋습니다.
Rag Experiment Accelerator는 구성 중심이며 그 목적을 지원하기위한 풍부한 기능 세트를 제공합니다.
실험 설정 : 다양한 검색 엔진 매개 변수, 검색 유형, 쿼리 세트 및 평가 메트릭을 지정하여 실험을 정의하고 구성 할 수 있습니다.
통합 : Azure AI Search, Azure Machine Learning, MLFlow 및 Azure Openai와 완벽하게 통합됩니다.
Rich Search Index : 구성 파일에서 사용 가능한 하이퍼 파라미터 구성을 기반으로 여러 검색 인덱스를 만듭니다.
다중 문서 로더 :이 도구는 Azure Document Intelligence 및 기본 Langchain 로더를 통한로드를 포함하여 여러 문서 로더를 지원합니다. 이를 통해 다른 추출 방법을 실험하고 그 효과를 평가할 수있는 유연성을 제공합니다.
사용자 정의 문서 인텔리전스 로더 : 문서 인텔리전스를위한 '사전 제작 된 레이어 아웃'API 모델을 선택할 때이 도구는 사용자 정의 문서 인텔리전스 로더를 사용하여 데이터를로드합니다. 이 사용자 정의 로더는 열 헤더가 키 값 쌍 (LLM의 가독성을 향상시키기 위해)으로 열 헤더가있는 테이블의 형식을 지원하고 LLM의 파일의 관련없는 부분 (예 : 페이지 번호 및 바닥 글)을 제외하고 Regex를 사용하여 파일의 재발 패턴을 제거합니다. 각 테이블 행이 텍스트 라인으로 변환되므로 중간에 행을 깨지 않도록하는 것은 단락과 줄에 의해 재귀 적으로 수행됩니다. 커스텀 로더는 '사전 제작 된 레이어 아웃'이 실패 할 때 더 간단한 '사전 제작 된 레이어 아웃'API 모델에 리조트합니다. 다른 API 모델은 Langchain의 구현을 사용하여 Document Intelligence의 API의 원시 응답을 반환합니다.
쿼리 생성 :이 도구는 다양한 다양한 실험 요구에 맞게 조정할 수있는 다양한 다양하고 사용자 정의 가능한 쿼리 세트를 생성 할 수 있습니다.
다중 검색 유형 : 순수 텍스트, 순수 벡터, 크로스 벡터, 다중 벡터, 하이브리드 등을 포함한 여러 검색 유형을 지원합니다. 이를 통해 검색 기능 및 결과에 대한 포괄적 인 분석을 수행 할 수 있습니다.
하위 쿼리 : 패턴은 사용자 쿼리를 평가하고 충분히 복잡한 것을 발견하면 더 작은 하위 쿼리로 분류하여 관련 컨텍스트를 생성합니다.
REANDING : Azure AI 검색의 쿼리 응답은 LLM을 사용하여 재평가되고 쿼리와 컨텍스트 간의 관련성에 따라 순위가 매겨집니다.
메트릭 및 평가 : 거리 기반, 코사인 및 의미 론적 유사성 메트릭을 포함한지면 진실 답변 (예상)과 생성 된 답변 (실제)을 비교하는 엔드 투 엔드 메트릭을 지원합니다. 또한 컨텍스트 리콜 또는 답변 관련성과 같은 심사 위원으로 LLM을 사용하여 검색 및 생성 성능을 평가하기위한 구성 요소 기반 메트릭, 검색 결과를 검색하기위한 검색 메트릭 (예 : MAP@K)도 포함됩니다.
보고서 생성 : Rag Experiment Accelerator는 보고서 생성 프로세스를 자동화하고 실험 결과를 쉽게 분석하고 공유 할 수있는 시각화로 완성됩니다.
다국어 :이 도구는 개별 언어에 대한 언어 지원 및 검색 인덱스의 사용자 정의 패턴에 대한 특수 (언어 비수분) 분석기를위한 언어 분석기를 지원합니다. 자세한 내용은 분석기 유형을 참조하십시오.
샘플링 : 대규모 데이터 세트가 있거나/또는 실험 속도를 높이려면 지정된 백분율에 대한 데이터의 작지만 대표적인 샘플을 만들기 위해 샘플링 프로세스를 사용할 수 있습니다. 데이터는 컨텐츠로 클러스터링되며 각 클러스터의 백분율은 샘플의 일부로 선택됩니다. 얻은 결과는 ~ 10% 마진 내에서 전체 데이터 세트를 대략적으로 나타내야합니다. 접근 방식이 식별되면 정확한 결과를 얻으려면 전체 데이터 세트에서 실행하는 것이 권장됩니다.
현재 Rag Expelerator는 다음 중 하나를 활용하여 로컬로 실행할 수 있습니다.
개발 컨테이너를 사용하면 필요한 모든 소프트웨어가 설치되어 있습니다. WSL이 필요합니다. 개발 컨테이너에 대한 자세한 내용은 컨테이너를 방문하십시오
호스트 컴퓨터에 다음 소프트웨어를 설치하십시오. 배포를 수행합니다.
- Windows -Windows Store Ubuntu 22.04.3 LTS 용
- 도커 데스크탑
- 비주얼 스튜디오 코드
- 대 코드 확장 : 원격 포함
WSL 설정에 대한 추가 지침은 여기에서 찾을 수 있습니다. 이제 전제 조건이 있습니다.
git clone https://github.com/microsoft/rag-experiment-accelerator.git
code .프로젝트가 VScode에서 열리면 "개발 컨테이너에서 이것을 다시 열어야하는지"묻습니다. 네 라고 말하다.
물론 원하는 경우 Windows/Mac 시스템에서 Rag Expection Accelerator를 실행할 수 있습니다. 올바른 툴링을 설치할 책임이 있습니다. 다음과 같은 설치 단계를 따르십시오.
git clone https://github.com/microsoft/rag-experiment-accelerator.gitconda create -n rag-experiment python=3.11
conda init bash터미널을 닫고 새 것을 열고 실행하십시오.
conda activate rag-experiment
pip install .az login
az account set --subscription= " <your_subscription_guid> "
az account show필요한 모든 Azure 서비스를 설치하는 3 가지 옵션이 있습니다.
이 프로젝트는 Azure Developer CLI를 지원합니다.
azd provisionazd provision 호출하기 때문에 원하는 경우 azd up 사용할 수도 있습니다.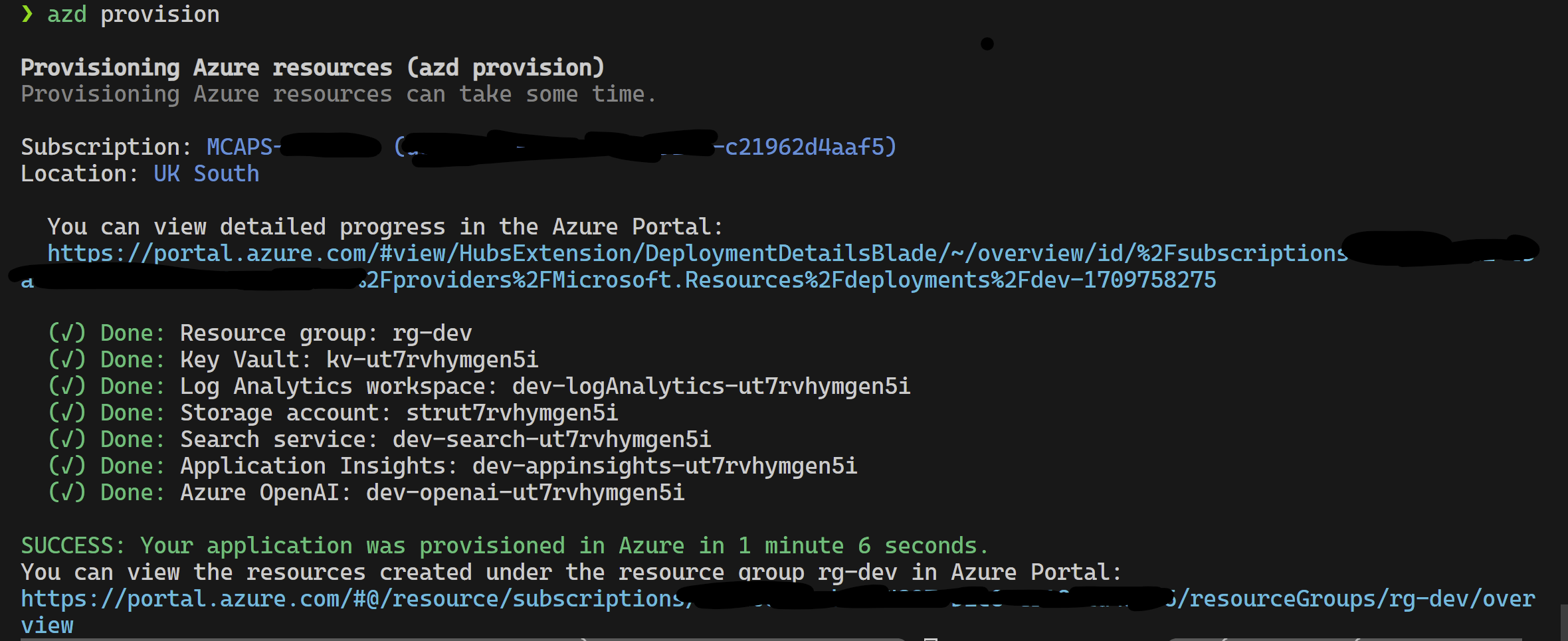
이 작업이 완료되면 런치 구성을 사용하여 실행되거나 4 단계를 디버깅 할 수 있으며 azd 가 프로비저닝 한 현재 환경에는 올바른 값이로드됩니다.
템플릿에서 인프라를 직접 배포하려면 여기를 클릭 할 수 있습니다.
azd 사용하지 않으려면 일반 az CLI도 사용할 수 있습니다.
배포하려면 다음 명령을 사용하십시오.
az login
az deployment sub create --subscription < subscription-id > --location < location > --template-file infra/main.bicep또는
격리 된 네트워크 사용 다음 명령으로 배포하려면 매개 변수 값을 격리 된 네트워크의 세부 사항으로 바꾸십시오. 격리 된 네트워크에 배포하려면 세 가지 매개 변수 (예 : vnetAddressSpace , proxySubnetAddressSpace 및 subnetAddressSpace )를 모두 제공 해야합니다 .
az login
az deployment sub create --location < location > --template-file infra/main.bicep
--parameters vnetAddressSpace= < vnet-address-space >
--parameters proxySubnetAddressSpace= < proxy-subnet-address-space >
--parameters subnetAddressSpace= < azure-subnet-address-space >다음은 매개 변수 값이있는 예입니다.
az deployment sub create --location uksouth --template-file infra/main.bicep
--parameters vnetAddressSpace= ' 10.0.0.0/16 '
--parameters proxySubnetAddressSpace= ' 10.0.1.0/24 '
--parameters subnetAddressSpace= ' 10.0.2.0/24 ' RAG 실험 가속기를 로컬로 사용하려면 다음을 수행하십시오.
제공된 .env.template 파일을 .env 라는 파일에 복사하고 필요한 모든 값을 업데이트하십시오. .env 파일에 필요한 많은 값은 이전에 구성되었거나 제공된 리소스에서 제공됩니다. 또한 기본적으로 LOGGING_LEVEL 은 INFO 로 설정되지만 다음 수준 중 하나로 변경할 수 있습니다 : NOTSET , DEBUG , INFO , WARN , ERROR , CRITICAL .
cp .env.template .env
# change parameters manually 제공된 config.sample.json 파일을 config.json 이라는 파일에 복사하고 하이퍼 파라미터를 변경하여 실험에 맞게 조정하십시오.
cp config.sample.json config.json
# change parameters manually 수집 용 파일 (PDF, HTML, Markdown, Text, JSON 또는 DOCX 형식)을 data 폴더에 복사하십시오.
01_index.py (Python 01_index.py)를 실행하여 Azure AI 검색 인덱스를 생성하고 데이터를로드하십시오.
python 01_index.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " 02_qa_generation.py (Python 02_qa_generation.py)를 실행하여 Azure Openai를 사용하여 질문 응답 쌍을 생성합니다.
python 02_qa_generation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " 03_querying.py (Python 03_Querying.py)를 실행하여 Azure AI 검색을 쿼리하여 컨텍스트를 생성하고 컨텍스트의 항목을 다시 평가하고 새로운 컨텍스트를 사용하여 Azure OpenAi로부터 응답을 얻습니다.
python 03_querying.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " 04_evaluation.py (Python 04_evaluation.py)를 실행하여 다양한 방법을 사용하여 메트릭을 계산하고 MLFlow 통합을 사용하여 Azure Machine Learning에서 차트 및 보고서를 생성합니다.
python 04_evaluation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " 또는 Azure ML 파이프 라인을 사용하여 위의 단계 ( 02_qa_generation.py 제외하고)를 실행할 수 있습니다. 그렇게하려면 여기 가이드를 따르십시오.
샘플링은 로컬로 실행되므로 작지만 대표적인 데이터 조각을 생성합니다. 이는 빠른 실험에 도움이되고 비용을 절감합니다. 얻은 결과는 ~ 10% 마진 내에서 전체 데이터 세트를 대략적으로 나타내야합니다. 접근 방식이 식별되면 정확한 결과를 얻으려면 전체 데이터 세트에서 실행하는 것이 권장됩니다.
참고 : 샘플링은 로컬로만 실행할 수 있으며이 단계에서는 분산 AML 컴퓨팅 클러스터에서 지원되지 않습니다. 따라서 프로세스는 로컬로 샘플링을 실행 한 다음 생성 된 샘플 데이터 세트를 사용하여 AML에서 실행하는 것입니다.
매우 큰 데이터 세트가 있고 데이터를 샘플링하기 위해 유사한 접근 방식을 실행하려면 Microsoft Fabric 또는 Azure Synapse Analytics 용 Data Discovery 툴킷에서 Pyspark Inmemory 분산 구현을 사용할 수 있습니다.
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"only_run_sampling" : " If set to true, this will only run the sampling step and will not create an index or any subsequent steps, use this if you want to build a small sampled dataset to run in AML " ,
"sample_percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 " ,
},샘플링 프로세스는 샘플링 디렉토리에서 다음과 같은 아티팩트를 생성합니다.
job_name 이름을 따서 명명 된 디렉토리는 AML에서 전체 프로세스를 실행할 때 --data_dir 인수로 지정할 수 있습니다.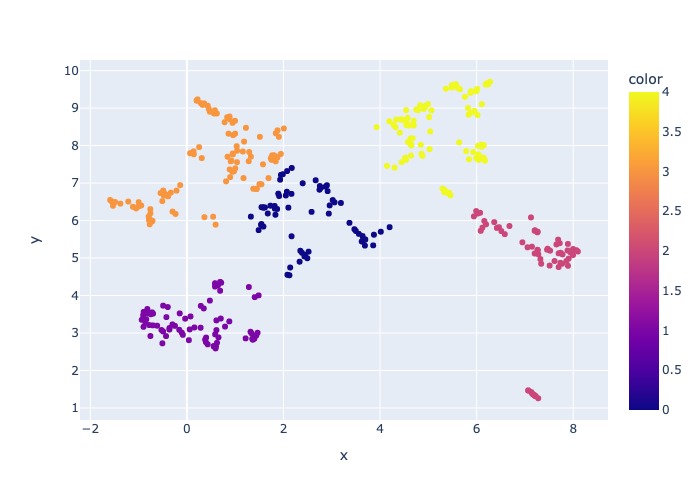
"optimum_k": auto 구성 값이 자동으로 설정된 경우 샘플링 프로세스는 최적의 클러스터 수를 자동으로 설정하려고 시도합니다. 데이터에 얼마나 많은 넓은 컨텐츠가 존재하는지 거의 아는 경우 이는 재정의 할 수 있습니다. 팔꿈치 그래프가 샘플링 폴더에서 생성됩니다. 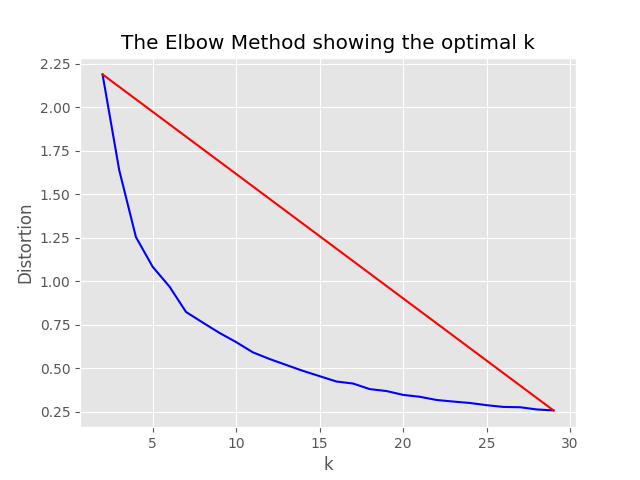
샘플링을 실행하기위한 두 가지 옵션, 즉 :
인덱싱 프로세스를 로컬로 실행하려면 다음 값을 설정하십시오.
"sampling" : {
"sample_data" : true ,
"only_run_sampling" : false ,
"sample_percentage" : 10 ,
"optimum_k" : auto,
"min_cluster" : 2 ,
"max_cluster" : 30
}, only_run_sampling config 값이 true로 설정된 경우 샘플링 단계 만 실행되며 인덱스가 생성되지 않으며 다른 후속 단계가 실행되지 않습니다. --data_dir 인수를 샘플링 프로세스에서 만든 디렉토리로 설정하십시오.
artifacts/sampling/config.[job_name] 및 AML 파이프 라인 단계를 실행합니다.
모든 값은 요소 목록이 될 수 있습니다. 중첩 구성을 포함합니다. 모든 배열은 메소드 flatten() 특정 노드에서 호출 될 때 평평한 구성의 조합을 생성하여 1 임의 조합을 선택하여 메소드 sample() 호출합니다.
{
"experiment_name" : " If provided, this will be the experiment name in Azure ML and it will group all job run under the same experiment, otherwise (if left empty) index_name_prefix will be used and there may be more than one experiment " ,
"job_name" : " If provided, all jobs runs in Azure ML will be named with this property value plus timestamp, otherwise (if left empty) each job with be named only with timestamp " ,
"job_description" : " You may provide a description for the current job run which describes in words what you are about to experiment with " ,
"data_formats" : " Specifies the supported data formats for the application. You can choose from a variety of formats such as JSON, CSV, PDF, and more. [*] - means all formats included " ,
"main_instruction" : " Defines the main instruction prompt coming with queries to LLM " ,
"use_checkpoints" : " A boolean. If true, enables use of checkpoints to load data and skip processing that was already done in previous executions. " ,
"index" : {
"index_name_prefix" : " Search index name prefix " ,
"ef_construction" : " ef_construction value determines the value of Azure AI Search vector configuration. " ,
"ef_search" : " ef_search value determines the value of Azure AI Search vector configuration. " ,
"chunking" : {
"preprocess" : " A boolean. If true, preprocess documents, split into smaller chunks, embed and enrich them, and finally upload documents chunks for retrieval into Azure Search Index. " ,
"chunk_size" : " Size of each chunk e.g. [500, 1000, 2000] " ,
"overlap_size" : " Overlap Size for each chunk e.g. [100, 200, 300] " ,
"generate_title" : " A boolean. If true, a title is generated for the chunk of content and an embedding is created for it " ,
"generate_summary" : " A boolean. If true, a summary is generated for the chunk of content and an embedding is created for it " ,
"override_content_with_summary" : " A boolean. If true, The chunk content is replaced with its summary " ,
"chunking_strategy" : " determines the chunking strategy. Valid values are 'azure-document-intelligence' or 'basic' " ,
"azure_document_intelligence_model" : " represents the Azure Document Intelligence Model. Used when chunking strategy is 'azure-document-intelligence'. When set to 'prebuilt-layout', provides additional features (see above) "
},
"embedding_model" : " see 'Description of embedding models config' below " ,
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 "
}
},
"language" : {
"analyzer" : {
"analyzer_name" : " name of the analyzer to use for the field. This option can be used only with searchable fields and it can't be set together with either searchAnalyzer or indexAnalyzer. " ,
"index_analyzer_name" : " name of the analyzer used at indexing time for the field. This option can be used only with searchable fields. It must be set together with searchAnalyzer and it cannot be set together with the analyzer option. " ,
"search_analyzer_name" : " name of the analyzer used at search time for the field. This option can be used only with searchable fields. It must be set together with indexAnalyzer and it cannot be set together with the analyzer option. This property cannot be set to the name of a language analyzer; use the analyzer property instead if you need a language analyzer. " ,
"char_filters" : " The character filters for the index " ,
"tokenizers" : " The tokenizers for the index " ,
"token_filters" : " The token filters for the index "
},
"query_language" : " The language of the query. Possible values: en-us, en-gb, fr-fr etc. "
},
"rerank" : {
"enabled" : " determines if search results should be re-ranked. Value values are TRUE or FALSE " ,
"type" : " determines the type of re-ranking. Value values are llm or cross_encoder " ,
"llm_rerank_threshold" : " determines the threshold when using llm re-ranking. Chunks with rank above this number are selected in range from 1 - 10. " ,
"cross_encoder_at_k" : " determines the threshold when using cross-encoding re-ranking. Chunks with given rank value are selected. " ,
"cross_encoder_model" : " determines the model used for cross-encoding re-ranking step. Valid value is cross-encoder/stsb-roberta-base "
},
"search" : {
"retrieve_num_of_documents" : " determines the number of chunks to retrieve from the search index " ,
"search_type" : " determines the search types used for experimentation. Valid value are search_for_match_semantic, search_for_match_Hybrid_multi, search_for_match_Hybrid_cross, search_for_match_text, search_for_match_pure_vector, search_for_match_pure_vector_multi, search_for_match_pure_vector_cross, search_for_manual_hybrid. e.g. ['search_for_manual_hybrid', 'search_for_match_Hybrid_multi','search_for_match_semantic'] " ,
"search_relevancy_threshold" : " the similarity threshold to determine if a doc is relevant. Valid ranges are from 0.0 to 1.0 "
},
"query_expansion" : {
"expand_to_multiple_questions" : " whether the system should expand a single question into multiple related questions. By enabling this feature, you can generate a set of alternative related questions that may improve the retrieval process and provide more accurate results " .,
"query_expansion" : " determines if query expansion feature is on. Value values are TRUE or FALSE " ,
"hyde" : " this feature allows you to experiment with various query expansion approaches which may improve the retrieval metrics. The possible values are 'disabled' (default), 'generated_hypothetical_answer', 'generated_hypothetical_document_to_answer' reference article - Precise Zero-Shot Dense Retrieval without Relevance Labels (HyDE - Hypothetical Document Embeddings) - https://arxiv.org/abs/2212.10496 " ,
"min_query_expansion_related_question_similarity_score" : " minimum similarity score in percentage between LLM generated related queries to the original query using cosine similarly score. default 90% "
},
"openai" : {
"azure_oai_chat_deployment_name" : " determines the Azure OpenAI deployment name " ,
"azure_oai_eval_deployment_name" : " determines the Azure OpenAI deployment name used for evaluation " ,
"temperature" : " determines the OpenAI temperature. Valid value ranges from 0 to 1. "
},
"eval" : {
"metric_types" : " determines the metrics used for evaluation (end-to-end or component-wise metrics using LLMs). Valid values for end-to-end metrics are lcsstr, lcsseq, cosine, jaro_winkler, hamming, jaccard, levenshtein, fuzzy_score, cosine_ochiai, bert_all_MiniLM_L6_v2, bert_base_nli_mean_tokens, bert_large_nli_mean_tokens, bert_large_nli_stsb_mean_tokens, bert_distilbert_base_nli_stsb_mean_tokens, bert_paraphrase_multilingual_MiniLM_L12_v2. Valid values for component-wise LLM-based metrics are llm_answer_relevance, llm_context_precision and llm_context_recall. e.g ['fuzzy_score','bert_all_MiniLM_L6_v2','cosine_ochiai','bert_distilbert_base_nli_stsb_mean_tokens', 'llm_answer_relevance'] " ,
}
}참고 : 구성을 변경할 때 변경해야합니다.
config.sample.json (다른 사람이 복사 할 예제 구성) embedding_model 은 임베딩 모델을 사용할 구성을 포함하는 배열입니다. 임베딩 모델 type Azure Openai 모델의 azure 하며 sentence-transformer 여야합니다.
{
"type" : " azure " ,
"model_name" : " the name of the Azure OpenAI model " ,
"dimension" : " the dimension of the embedding model. For example, 1536 which is the dimension of text-embedding-ada-002 "
} text-embedding-ada-002 이외의 모델을 사용하는 경우 dimension 필드의 모델에 해당하는 차원을 지정해야합니다. 예를 들어:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 3072
}다른 Azure OpenAI 임베딩 모델의 크기는 Azure OpenAI 서비스 모델 문서에서 찾을 수 있습니다.
최신 임베딩 모델 (v3)을 사용하는 경우 단축 임베딩에 대한 지원을 활용할 수도 있습니다. 이 경우 필요한 치수 수를 지정하고 shorten_dimensions 플래그를 추가하여 임베딩을 단축하려는 것을 나타냅니다. 예를 들어:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 256 ,
"shorten_dimensions" : true
}{
"type" : " sentence-transformer " ,
"model_name" : " the name of the sentence transformer model " ,
"dimension" : " the dimension of the model. This field is not required if model name is one of ['all-MiniLM-L6-v2', 'all-mpnet-base-v2', 'bert-large-nli-mean-tokens] "
}질문에 대한 질문에 대한 가상의 답변의 예를 제시합니다. 쿼리에 대한 답을 보유하거나 대체 관련 질문이 거의 발생하지 않으면 검색을 개선하여 LLM 컨텍스트로 전달할 수있는보다 정확한 문서 청크를 얻을 수 있습니다. 참조 기사를 기반으로 - 관련성 레이블이없는 정확한 제로 샷 고밀도 검색 (Hyde- 가상 문서 임베드).
다음 구성 옵션은이 실험 접근법을 켜는다.
{
"hyde" : " generated_hypothetical_answer "
}{
"hyde" : " generated_hypothetical_document_to_answer "
} 이 기능은 미세 관련 질문을 생성하고 원래 쿼리 (코사인 유사성 점수 사용)에서 min_query_expansion_related_question_similarity_score 퍼센트를 필터링하고 원래 쿼리와 함께 각각의 문서에 대한 검색 문서를 검색하고 RERANKER 및 TOP K 단계로 반환합니다.
min_query_expansion_related_question_similarity_score 의 기본값은 90%로 설정되어 config.json 에서이를 변경할 수 있습니다.
{
"query_expansion" : true ,
"min_query_expansion_related_question_similarity_score" : 90
}이 솔루션은 Azure Machine Learning과 통합되며 MLFlow를 사용하여 실험, 작업 및 아티팩트를 관리합니다. 다음 보고서를 평가 프로세스의 일부로 볼 수 있습니다.
all_metrics_current_run.html 선택한 각 메트릭에 대한 질문 및 검색 유형에 대한 평균 점수를 표시합니다.
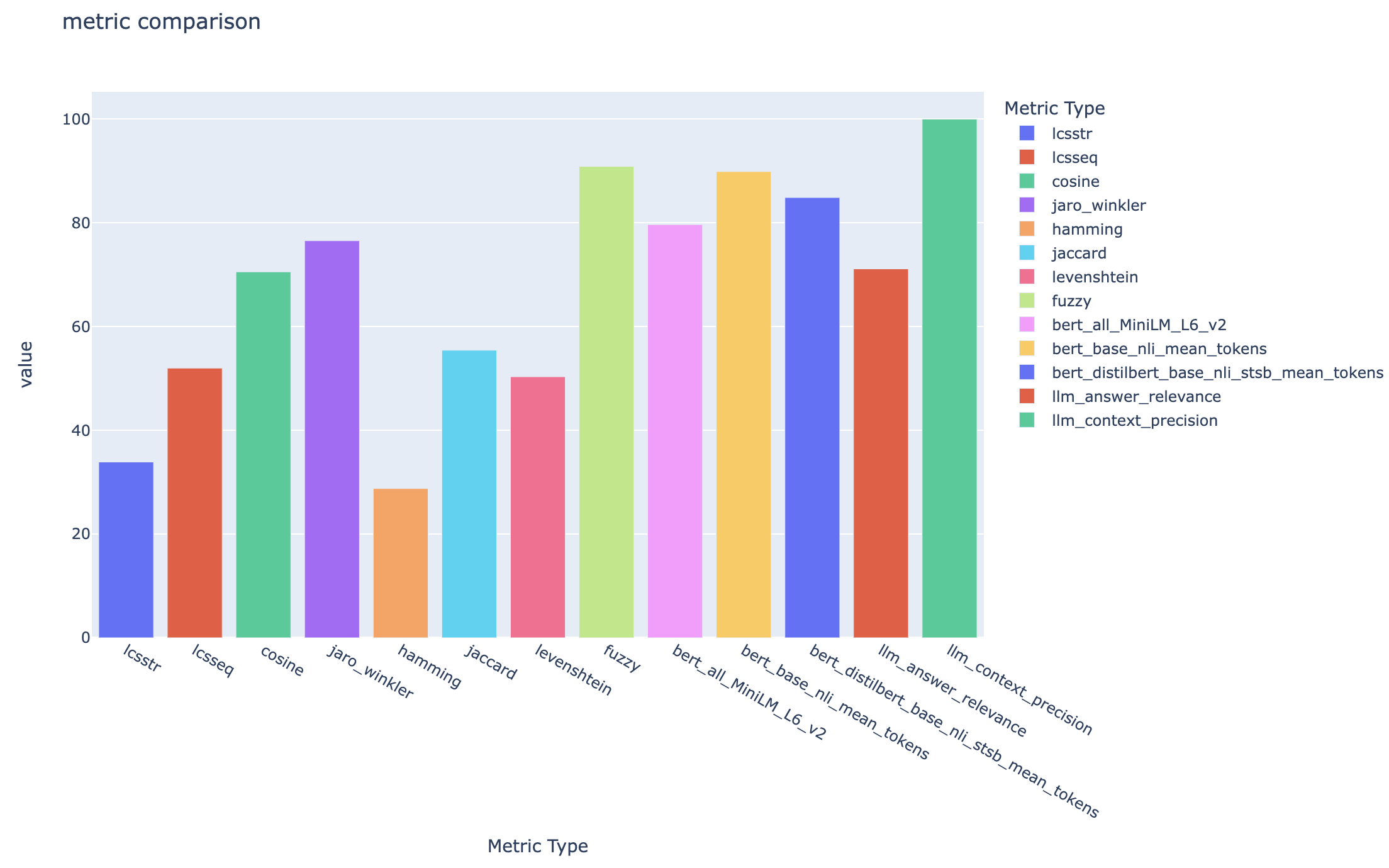
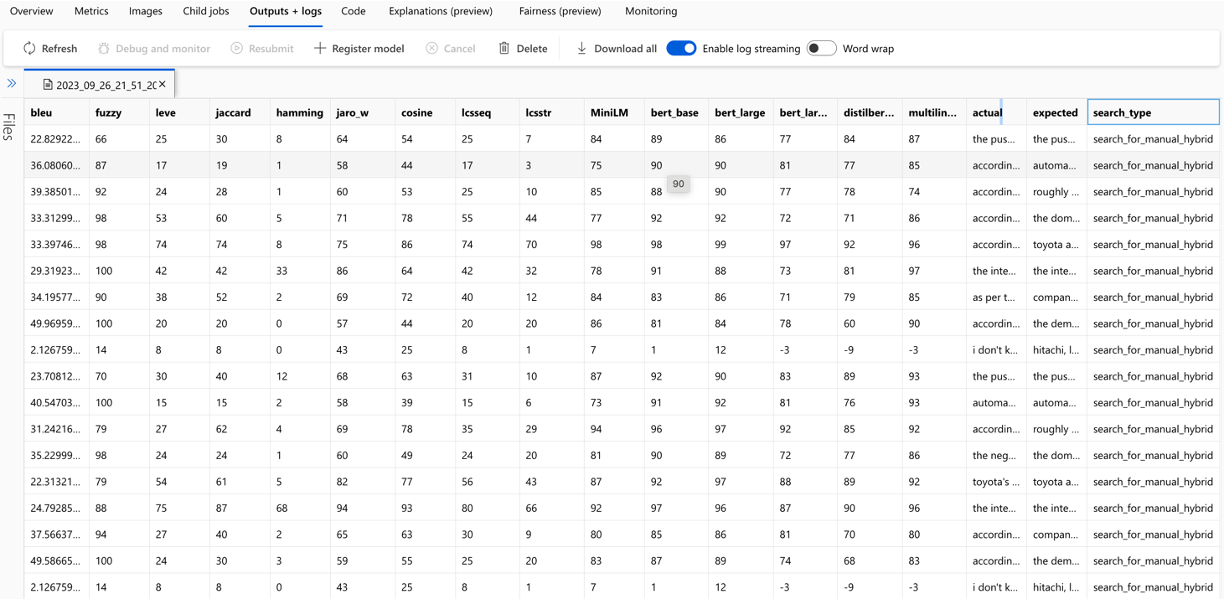
평가에 사용되는 각 메트릭 및 필드의 계산은 출력 CSV 파일의 각 질문 및 검색 유형에 대해 추적됩니다.
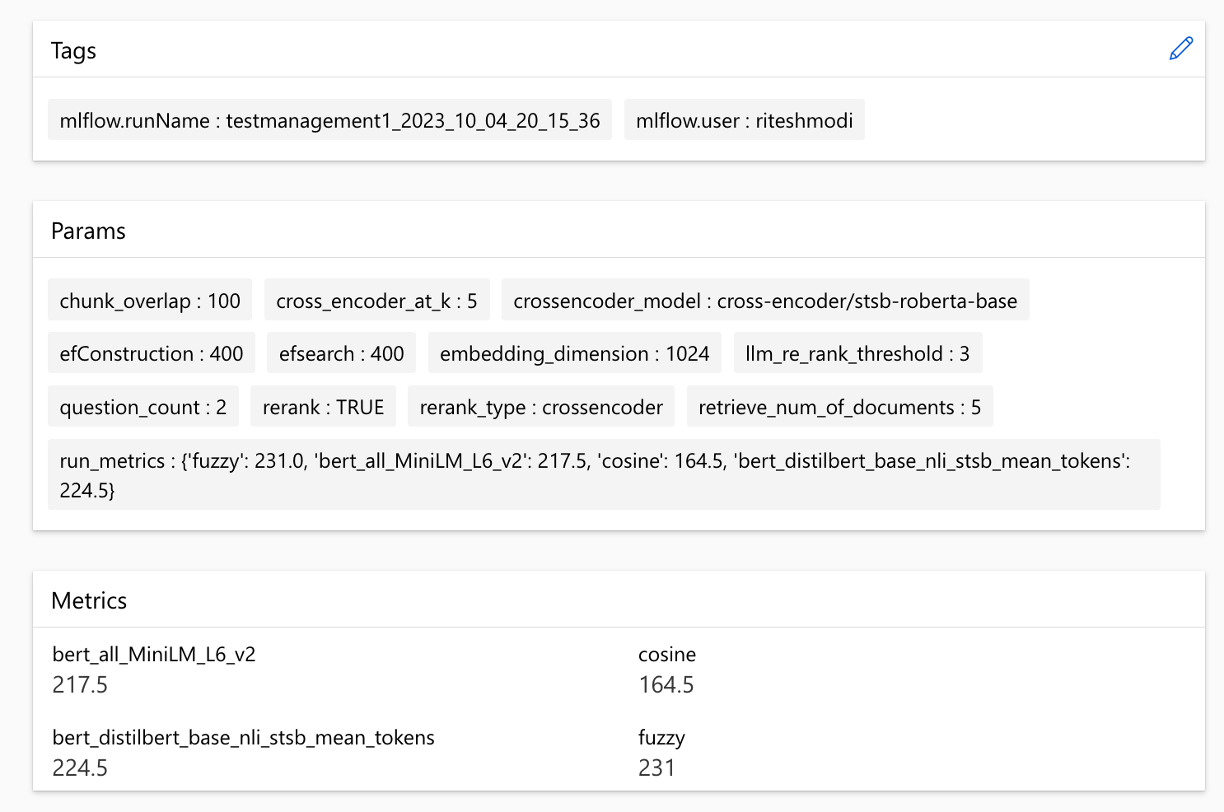
메트릭은 실행에 따라 비교할 수 있습니다.
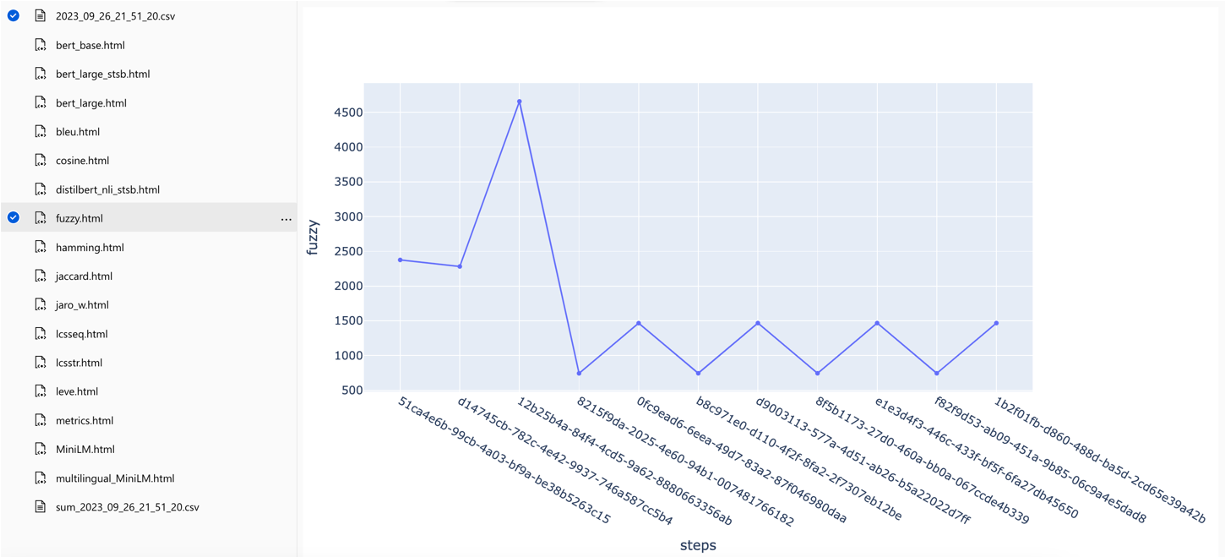
메트릭은 다양한 검색 전략에서 비교할 수 있습니다.
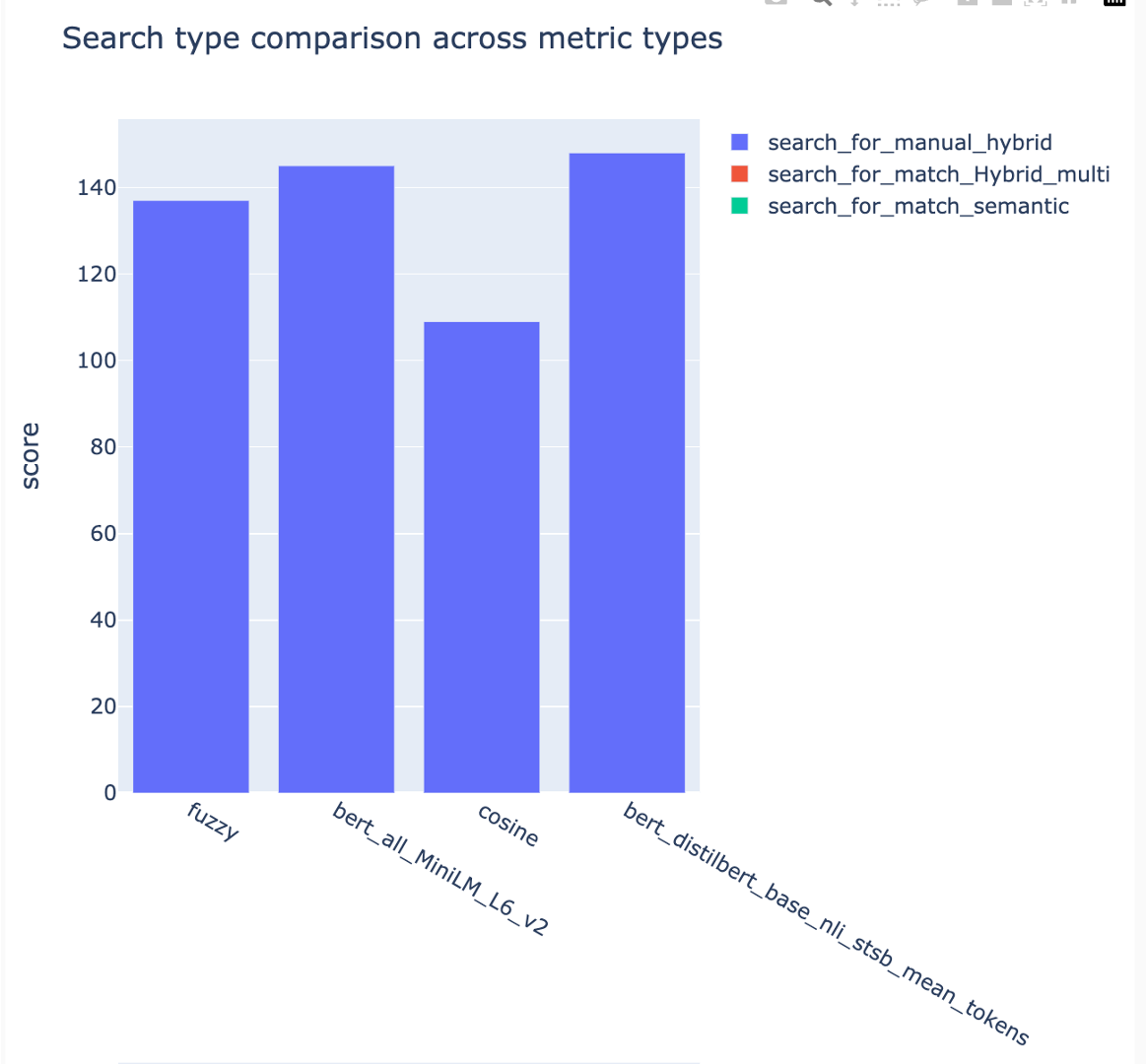
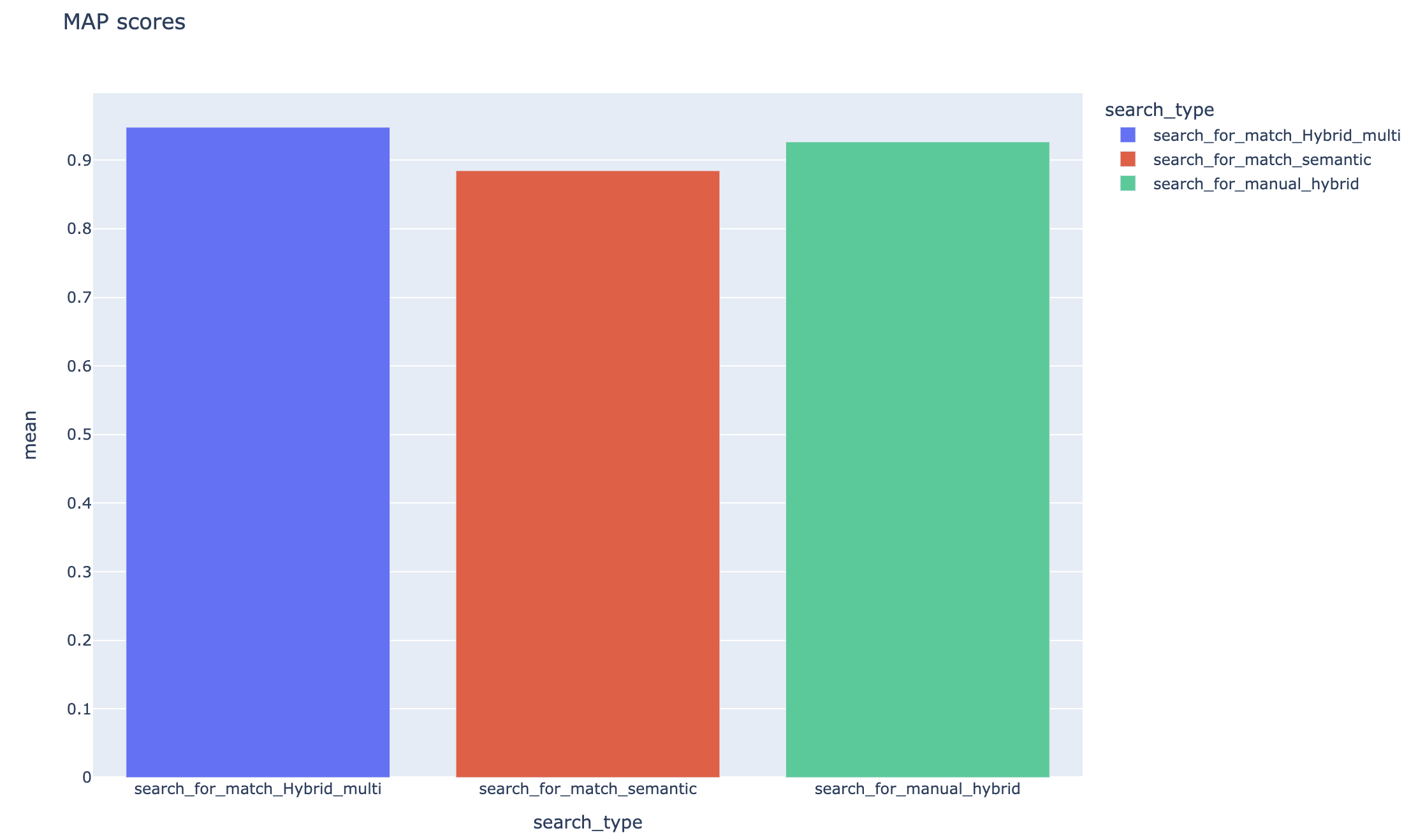
평균 평균 정밀 점수는 추적되며 평균지도 점수는 검색 유형에서 비교할 수 있습니다.
이 섹션은 RAG 실험 가속기로 작업하는 동안 엔지니어/개발자/데이터 과학자가 발생할 수있는 일반적인 gotchas 또는 함정을 간략하게 설명합니다.
이 솔루션을 성공적으로 활용하려면 먼저 Azure 계정에 로그인하여 직접 인증해야합니다. 이 필수 단계를 통해 사용하는 Azure 리소스에 액세스하고 관리하는 데 필요한 권한이 있습니다. QNA 데이터를 Azure Machine Learning Data Assets에 저장하고 부적절한 승인 및 Azure 인증의 결과로 쿼리 및 평가 단계를 실행하는 것과 관련된 오류가 발생할 수 있습니다. 인증 및 승인은이 문서의 포인트 4를 참조하십시오.
유효한 인증 및 승인에도 불구하고 솔루션이 여전히 오류를 생성하는 상황이있을 수 있습니다. 이러한 경우 새로운 터미널 인스턴스로 새 세션을 시작하고 4 단계에서 언급 된 단계를 사용하여 Azure에 로그인하고 사용자가 솔루션과 관련된 Azure 리소스에 대한 액세스를 제공했는지 확인하십시오.
이 솔루션은 config.json 의 여러 구성 매개 변수를 사용하여 기능과 성능에 직접 영향을 미칩니다. 이 설정에주의를 기울이십시오.
retrieve_num_of_documents : 이 구성은 분석을 위해 검색된 초기 문서 수를 제어합니다. 값이 지나치게 높거나 낮은 값은 검색 AI 결과의 순위 처리로 인해 "범위에서 인덱스"오류로 이어질 수 있습니다.
cross_encoder_at_k : 이 구성은 순위 프로세스에 영향을 미칩니다. 높은 값으로 인해 최종 결과에 관련없는 문서가 포함될 수 있습니다.
LLM_RERANK_THRESHOLD : 이 구성은 추가 처리를 위해 언어 모델 (LLM)에 전달되는 문서를 결정합니다. 이 값을 너무 높게 설정하면 LLM이 처리 할 수있는 지나치게 큰 컨텍스트를 만들 수 있으며, 잠재적으로 처리 오류 또는 결과가 저하 된 결과가 발생할 수 있습니다. 이것은 또한 Azure Openai 엔드 포인트에서 예외적 인 결과를 초래할 수 있습니다.
이 솔루션을 실행하기 전에 config.json 파일 내에서 Azure OpenAI 배포 이름을 올바르게 설정하고 환경 변수 (.env 파일)에 관련 비밀을 추가하십시오. 이 정보는 응용 프로그램이 적절한 Azure Openai 리소스에 연결하고 설계된 기능에 연결하는 데 중요합니다. 구성 데이터가 확실하지 않은 경우 .env.template 및 config.json 파일을 참조하십시오. 이 솔루션은 GPT 3.5 터보 모델로 테스트되었으며 다른 모델에 대한 추가 테스트가 필요합니다.
QNA 생성 단계에서는 때때로 Azure OpenAI에서 수신 된 JSON 출력과 관련된 오류가 발생할 수 있습니다. 이러한 오류는 몇 가지 질문과 답변의 성공적인 생성을 방해 할 수 있습니다. 알아야 할 사항은 다음과 같습니다.
잘못된 형식 : Azure Openai의 JSON 출력은 예상 형식을 준수하지 않아 QNA 생성 프로세스에 문제가 발생할 수 있습니다. 컨텐츠 필터링 : Azure Openai에는 컨텐츠 필터가 있습니다. 입력 텍스트 또는 생성 된 응답이 부적절한 것으로 간주되면 오류가 발생할 수 있습니다. API 제한 : Azure OpenAi 서비스에는 출력에 영향을 미치는 토큰 및 요율 제한이 있습니다.
엔드 투 엔드 평가 메트릭 : 생성 된 및지면 답변을 비교하는 모든 메트릭이 의미론의 차이를 포착 할 수있는 것은 아닙니다. 예를 들어 levenshtein 또는 jaro_winkler 와 같은 메트릭은 편집 거리 만 측정합니다. cosine 메트릭은 의미론을 비교할 수 없습니다. 용어 주파수 벡터를 기반으로 TextDistance 토큰 기반 구현을 사용합니다. 생성 된 답변과 예상 응답 사이의 의미 론적 유사성을 계산하려면 BERT 점수 ( bert_ )와 같은 임베딩 기반 메트릭 사용을 고려하십시오.
구성 요소 측정 메트릭 : LLM-as-Judges를 사용한 평가 지표는 결정적이지 않습니다. 가속기에 포함 된 llm_ 메트릭은 azure_oai_eval_deployment_name config 필드에 표시된 모델을 사용합니다. 평가 명령에 사용 된 프롬프트는 조정할 수 있으며 prompts.py 파일에 포함됩니다 ( llm_answer_relevance_instruction , llm_context_recall_instruction , llm_context_precision_instruction ).
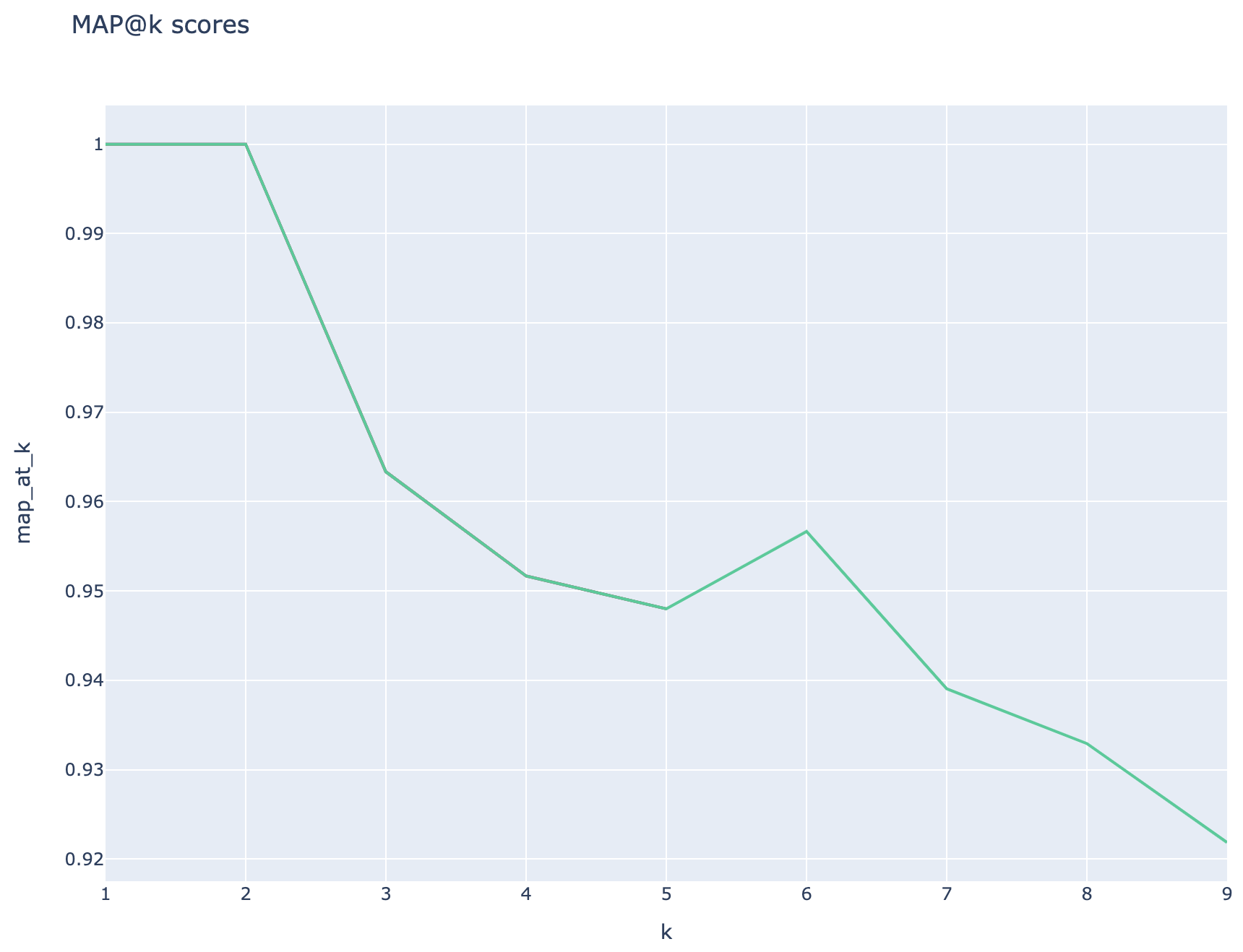
검색 기반 메트릭 : MAP 점수는 질문과 QNA 쌍을 생성하는 데 사용되는 청크와 비교하여 각 검색 된 청크를 비교하여 계산됩니다. 검색된 청크가 관련이 있는지 여부를 평가하기 위해, 검색된 청크와 최종 사용자 질문의 연결과 QNA 단계 ( 02_qa_generation.py )에 사용 된 청크 사이의 유사성은 spacyevaluator를 사용하여 계산됩니다. 스페이시 유사성은 토큰 벡터의 평균으로 기본적으로 기본적으로 계산이 단어 순서에 둔감하다는 것을 의미합니다. 기본적으로 유사성 임계 값은 80% ( spacy_evaluator.py )로 설정됩니다.
우리는 귀하의 기여와 제안을 환영합니다. 기여하려면 귀하가 귀하의 기부금을 사용할 권리를 부여 할 권리가 있음을 확인하는 기고자 라이센스 계약 (CLA)에 동의해야합니다. 자세한 내용은 [https://cla.opensource.microsoft.com]을 방문하십시오.
풀 요청을 제출할 때 CLA 봇은 CLA를 제공 해야하는지 자동으로 지침을 제공합니다 (예 : 상태 확인, 댓글). 봇의 지침을 따르십시오. CLA를 사용하는 모든 저장소에 대해서만이 작업을 수행하면됩니다.
기여하기 전에 실행하십시오
pip install -e .
pre-commit install
이 프로젝트는 Microsoft 오픈 소스 행동 강령을 따릅니다. 자세한 내용은 행동 강령 FAQ 또는 질문이나 의견이 있으시면 [email protected]에 문의하십시오.
bug/11-short-descriptionfeature/22-short-descriptionexample_snake_case 와 같은 메트릭 이름 및 구성 변수에는 뱀 케이스를 사용하십시오.git config --global user.name "First Last"이 프로젝트에는 프로젝트, 제품 또는 서비스에 대한 상표 또는 로고가 포함될 수 있습니다. Microsoft 상표 및 브랜드 지침을 따라 Microsoft 상표 또는 로고를 올바르게 사용해야합니다. 혼란을 일으키거나 Microsoft 후원을 암시하는 방식 으로이 프로젝트의 수정 된 버전에서 Microsoft 상표 또는 로고를 사용하지 마십시오. 이 프로젝트에 포함 된 타사 상표 또는 로고의 정책을 따르십시오.


