super json mode
1.0.0
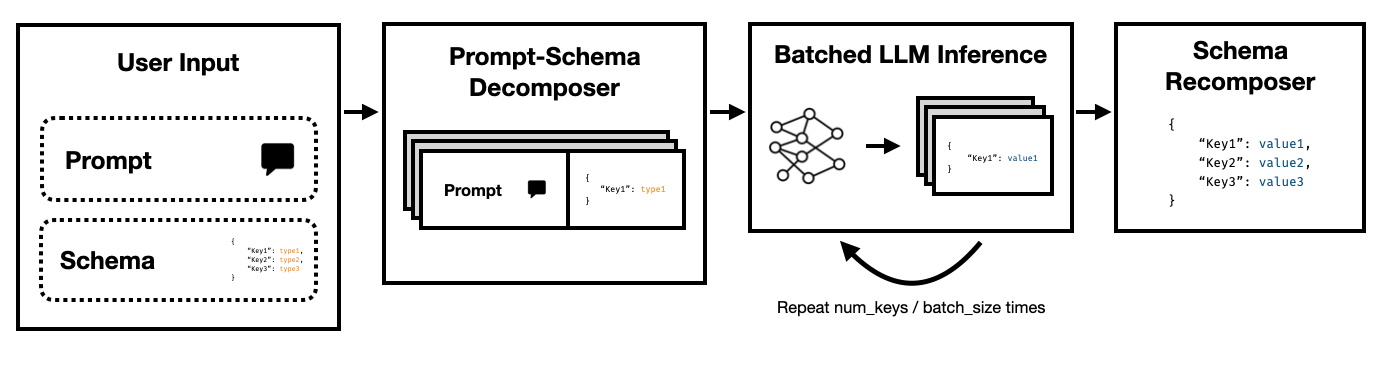
Super JSON Mode는 대상 스키마를 원자 구성 요소로 나누고 세대를 병렬로 수행하여 LLM에서 구조화 된 출력의 효율적인 생성을 가능하게하는 Python 프레임 워크입니다.
OpenAi 의 레거시 완성 API 및 Hugging Face Transformers 및 VLLM 과 같은 오픈 소스 LLM을 통해 Art LLM의 상태를 모두 지원합니다. 더 많은 LLM이 곧 지원 될 것입니다!
순진한 JSON 생성 파이프 라인과 비교하여 프롬프트 및 HF 변압기에 의존하는 Super JSON 모드는 10 배 더 빠르게 출력을 생성 할 수 있습니다. 또한 순진한 세대와 비교할 때 더 결정적이며 구문 분석 문제가 발생할 가능성이 적습니다.
설치는 간단합니다 : pip install super-json-mode
JSON 또는 YAML과 같은 구조화 된 출력 형식은 고유 한 평행 또는 계층 구조를 갖습니다.
다음의 구조화되지 않은 구절 (GPT-4에 의해 생성)을 고려하십시오.
환상적인 현대 디자인을 자랑하는 멋진 샌프란시스코 거주지 인 123 Azure Lane에 오신 것을 환영합니다. 고급 3,000 평방 피트에 퍼지는이 숙박 시설은 정교함과 편안함을 결합하여 진정으로 독특한 생활 경험을 만듭니다.
가족이나 전문가를위한 목가적 인 집으로, 우리의 독점 거주지에는 5 개의 넓은 침실이 장착되어 있으며 각각 따뜻함과 현대적인 우아함이 있습니다. 침실은 충분한 자연 채광과 관대 한 저장 공간을 허용하도록 신중하게 계획되어 있습니다. 우아하게 디자인 된 3 개의 욕실로 거주지는 주민들의 편의성과 개인 정보를 보장합니다.
웅장한 입구는 넓은 거실로 인도하여 모임을위한 훌륭한 분위기 나 불로 조용한 저녁을 제공합니다. 요리사의 주방에는 최첨단 가전 제품, 맞춤형 캐비닛 및 아름다운 화강암 조리대가 포함되어있어 요리를 좋아하는 사람에게는 꿈이됩니다.
LLM을 사용하여 address , square footage , number of bedrooms , number of bathrooms 및 price 추출하려면 설명에 따라 모델에 스키마를 채우도록 요청할 수 있습니다.
잠재적 인 스키마 (예 : Pydantic 객체에서 생성 된 스키마)는 다음과 같습니다.
{
"address": {
"type": "string"
},
"price": {
"type": "number"
},
"square_feet": {
"type": "integer"
},
"num_beds": {
"type": "integer"
},
"num_baths": {
"type": "integer"
}
}
그리고 유효한 출력은 다음과 같이 보일 수 있습니다.
{
"address": "123 Azure Lane",
"price": 2500000,
"square_feet": 3000,
"num_beds": 5,
"num_baths": 3
}
명백한 접근법은 프롬프트의 스키마를 중첩하고 모델에 채우도록 요청하는 것입니다. 이것은 현재 대부분의 팀이 현재 LLM을 사용하여 구조화되지 않은 텍스트에서 구조화 된 출력을 추출하는 방식입니다.
그러나 이것은 세 가지 이유로 비효율적입니다.
이 키 각각이 서로 독립적 인 방법에 주목하십시오. Super JSON Mode는 스키마의 모든 키 값 쌍을 별도의 문의로 처리하여 신속한 병렬 처리를 이용합니다. 예를 들어, 이미 address 생성하지 않고 num_baths 를 추출 할 수 있습니다!
처음부터 JSON을 처음부터 생성하도록 모델에 불필요하게 JSON을 생성하면 예측 가능한 구문에 대한 토큰 (및 시간 이전의 시간)이 이미 출력에서 예상되는 브레이스 및 키 이름과 같이 소비됩니다. 이것은 우리가 대기 시간을 개선하기 위해 사용할 수 있어야하는 세대의 강력한 것입니다.
LLM은 부끄럽게 평행하고 일련의 쿼리가 일련 순서보다 훨씬 빠릅니다. 따라서 여러 쿼리를 통해 스키마를 분할 할 수 있습니다. 그런 다음 LLM은 각 독립 키의 스키마를 병렬로 채우고 단일 패스로 훨씬 적은 토큰을 방출하여 훨씬 빠른 추론 시간을 허용합니다.
다음 명령을 실행하십시오.
pip install super-json-mode
conda create --name superjsonmode python=3.10 -y
conda activate superjsonmode
git clone https://github.com/varunshenoy/super-json-mode
cd superjsonmode
pip install -r requirements.txt
우리는 슈퍼 JSON 모드를 매우 쉽게 사용하기 위해 노력했습니다. 더 많은 예제 및 vLLM 사용은 examples 폴더를 참조하십시오.
OpenAI 및 gpt-3-instruct-turbo 사용 :
from superjsonmode . integrations . openai import StructuredOpenAIModel
from pydantic import BaseModel
import time
model = StructuredOpenAIModel ()
class Character ( BaseModel ):
name : str
genre : str
age : int
race : str
occupation : str
best_friend : str
home_planet : str
prompt_template = """{prompt}
Please fill in the following information about this character for this key. Keep it succinct. It should be a {type}.
{key}: """
prompt = """Luke Skywalker is a famous character."""
start = time . time ()
output = model . generate (
prompt ,
extraction_prompt_template = prompt_template ,
schema = Character ,
batch_size = 7 ,
stop = [ " n n " ],
temperature = 0 ,
)
print ( f"Total time: { time . time () - start } " )
# Total Time: 0.409s
print ( output )
# {
# "name": "Luke Skywalker",
# "genre": "Science fiction",
# "age": "23",
# "race": "Human",
# "occupation": "Jedi Knight",
# "best_friend": "Han Solo",
# "home_planet": "Tatooine",
# }Huggingface Transformers와 함께 Mistral 7b 사용 :
from transformers import AutoTokenizer , AutoModelForCausalLM
from superjsonmode . integrations . transformers import StructuredOutputForModel
from pydantic import BaseModel
device = "cuda"
model = AutoModelForCausalLM . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" ). to ( device )
tokenizer = AutoTokenizer . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" )
# Create a structured output object
structured_model = StructuredOutputForModel ( model , tokenizer )
passage = """..."""
class QuarterlyReport ( BaseModel ):
company : str
stock_ticker : str
date : str
reported_revenue : str
dividend : str
prompt_template = """[INST]{prompt}
Based on this excerpt, extract the correct value for "{key}". Keep it succinct. It should have a type of `{type}`.[/INST]
{key}: """
output = structured_model . generate ( passage ,
extraction_prompt_template = prompt_template ,
schema = QuarterlyReport ,
batch_size = 6 )
print ( json . dumps ( output , indent = 2 ))
# {
# "company": "NVIDIA",
# "stock_ticker": "NVDA",
# "date": "2023-10",
# "reported_revenue": "18.12 billion dollars",
# "dividend": "0.04"
# } Super JSON 모드를 개선 할 수있는 많은 기능이 있습니다. 몇 가지 아이디어가 있습니다.
질적 출력 분석 : 성능 벤치 마크를 실행했지만 슈퍼 JSON 모드의 질적 출력을 판단하기위한보다 엄격한 접근 방식을 제시해야합니다.
구조화 된 샘플링 : 이상적으로는 JSONFORMER와 유사한 유형 제약 조건을 시행하기 위해 LLM의 로이트를 마스킹해야합니다. 이미이 작업을 수행하는 몇 가지 패키지가 있으며, 병렬화 된 JSON 생성 파이프 라인을 통합하거나 Super JSON 모드로 빌드해야합니다.
종속성 그래프 지원 : Super JSON Mode에는 매우 분명한 실패 사례가 있습니다. 키가 다른 키에 의존하는 경우. 두 가지 키, thought 과 response 있는 JSON BLOB을 고려하십시오. 이러한 종류의 원하는 출력은 큰 언어 모델로 생각의 사슬에 일반적이며 response thought 에 의존한다는 것이 매우 분명합니다. 부모 출력이 완료되어 아동 스키마 항목에 전달되는 방식으로 종속성 및 배치 프롬프트 그래프를 전달할 수 있어야합니다.
로컬 모델 지원 : 슈퍼 JSON 모드는 배치 크기가 일반적으로 1 인 로컬 상황에서 가장 잘 작동합니다. 배치를 악용하여 배치를 감소시킬 수 있습니다. LLAMA.CPP는 로컬 모델 + CPU 추론을위한 최고의 프레임 워크입니다. 가능하면 Ollama를 사용하여 이것을 구현하고 싶습니다.
TRT-LLM 지원 : VLLM은 훌륭하고 사용하기 쉽지만 이상적으로는 TRT-LLM과 같은 훨씬 더 성능있는 프레임 워크와 통합됩니다.
당신이 당신의 작업에 유용한 도서관을 발견했다면이 저장소를 인용하시면 감사합니다.
@misc{ShenoyDerhacobian2024,
author = {Shenoy, Varun and Derhacobian, Alex},
title = {Super JSON Mode: A Framework for Accelerated Structured Output Generation},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/varunshenoy/super-json-mode}}
}
이 프로젝트는 CS 229 : 머신 러닝 시스템을 위해 구축되었습니다. 이 프로젝트 전반에 걸쳐 교수 팀과 TAS에게 큰 감사를드립니다.


