splicing
1.0.0

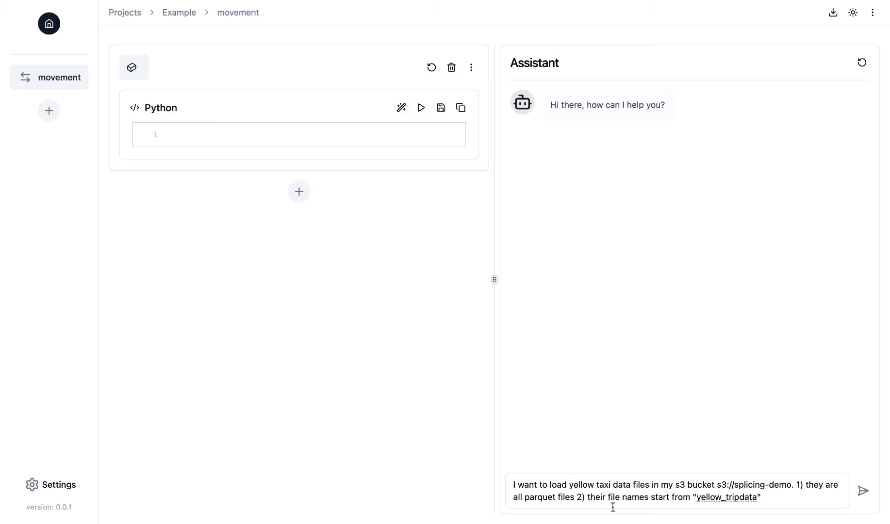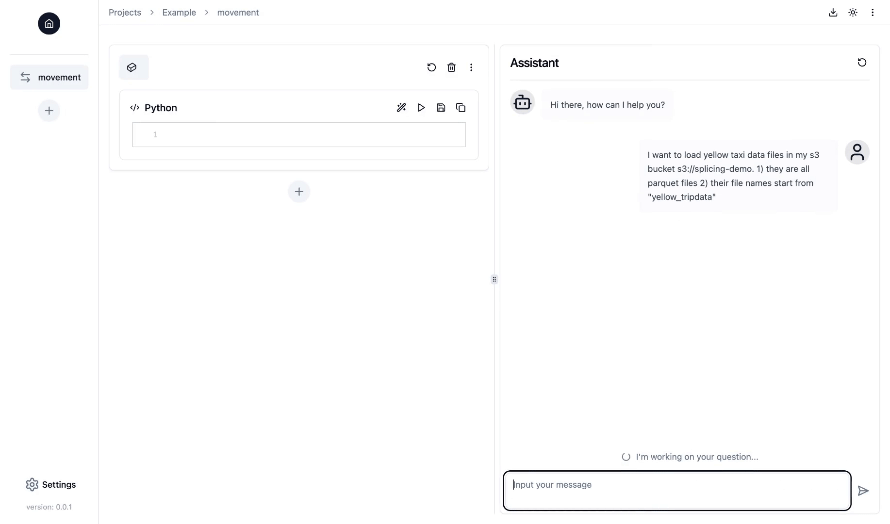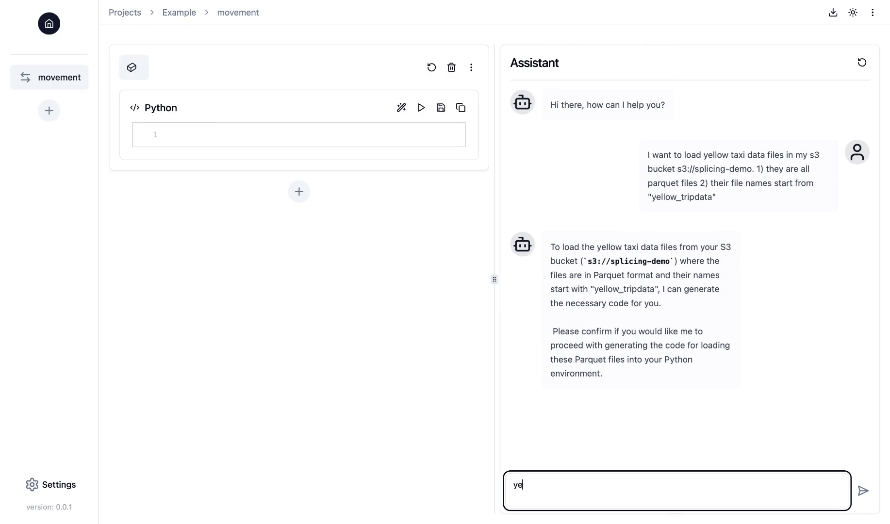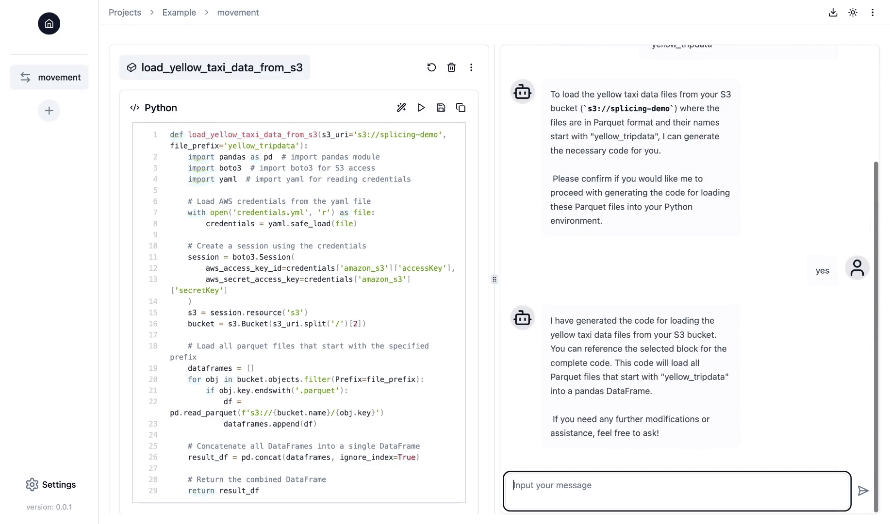
A maneira mais fácil de executar o Splicing é no Docker:
Instale o Docker.
Execute o seguinte comando para executar o Splicing:
docker run -v $( pwd ) /.splicing:/app/.splicing
-p 3000:3000
-p 8000:8000
-it --rm splicingai/splicing:latest Por padrão, todos os dados do aplicativo são armazenados na pasta ./.splicing no diretório atual onde você executa o comando acima. Se você quiser persistir os dados, faça backup desta pasta.
Você também pode instalar o Splicing sem Docker para desenvolvimento seguindo as instruções no guia CONTRIBUTING.
Consulte CONTRIBUTING.md para obter mais detalhes.
O splicing auxilia na construção de pipelines de dados, incluindo tarefas como ingestão, transformação e orquestração de dados, para preparar seus dados para processos downstream, como análise de dados e aprendizado de máquina.
O Splicing foi projetado para engenheiros de dados, cientistas de dados e qualquer pessoa que precise construir pipelines de dados. Mesmo se você tiver experiência limitada em engenharia de dados, o AI Copilot da Splicing irá guiá-lo passo a passo e você poderá pedir ajuda a qualquer momento usando linguagem natural.
A emenda foi projetada especificamente para engenharia de dados, um campo com muitas opções complexas que ainda não adotou totalmente a IA generativa para produtividade. Ao contrário das ferramentas genéricas, o Splicing se concentra na otimização de modelos de linguagem para etapas fixas comuns em pipelines de dados. Ele também está profundamente integrado a fontes de dados e ferramentas, permitindo que o copiloto entenda o contexto do seu projeto (suas configurações, dados e muito mais), levando a uma geração de código mais precisa e útil em comparação com copilotos de uso geral.
O splicing é de código aberto e pode ser hospedado em sua própria infraestrutura. Seus dados e chaves secretas nunca são compartilhados conosco ou com qualquer provedor de LLM intencionalmente. Além disso, o Splicing Copilot não executa automaticamente o código gerado – você controla quando e como ele é executado.
Sim! O Splicing gera código usando suas integrações e ferramentas de dados preferidas. Você pode exportar o código com um único clique e executá-lo ou implantá-lo em qualquer lugar que desejar. Não há dependência de fornecedor.


