ffhq dataset
1.0.0

Flickr-Faces-HQ (FFHQ) é um conjunto de dados de imagens de rostos humanos de alta qualidade, originalmente criado como referência para redes adversárias generativas (GAN):
Uma arquitetura geradora baseada em estilo para redes adversárias generativas
Tero Karras (NVIDIA), Samuli Laine (NVIDIA), Timo Aila (NVIDIA)
https://arxiv.org/abs/1812.04948
O conjunto de dados consiste em 70.000 imagens PNG de alta qualidade com resolução de 1024×1024 e contém variações consideráveis em termos de idade, etnia e fundo da imagem. Também possui boa cobertura de acessórios como óculos, óculos de sol, chapéus, etc. As imagens foram rastreadas do Flickr, herdando assim todos os vieses daquele site, e automaticamente alinhadas e recortadas usando dlib. Apenas imagens sob licenças permissivas foram coletadas. Vários filtros automáticos foram usados para podar o conjunto e, finalmente, o Amazon Mechanical Turk foi usado para remover estátuas, pinturas ou fotos ocasionais.
Observe que este conjunto de dados não se destina e não deve ser usado para o desenvolvimento ou melhoria de tecnologias de reconhecimento facial. Para consultas comerciais, visite nosso site e envie o formulário: NVIDIA Research Licensing
As imagens individuais foram publicadas no Flickr por seus respectivos autores sob licença Creative Commons BY 2.0, Creative Commons BY-NC 2.0, Public Domain Mark 1.0, Public Domain CC0 1.0 ou US Government Works. Todas essas licenças permitem uso, redistribuição e adaptação gratuitos para fins não comerciais . Porém, alguns deles exigem o devido crédito ao autor original, bem como a indicação de quaisquer alterações feitas nas imagens. A licença e o autor original de cada imagem estão indicados nos metadados.
O conjunto de dados em si (incluindo metadados JSON, script de download e documentação) é disponibilizado sob a licença Creative Commons BY-NC-SA 4.0 da NVIDIA Corporation. Você pode usá-lo, redistribuí-lo e adaptá-lo para fins não comerciais , desde que (a) dê o devido crédito citando nosso artigo , (b) indique quaisquer alterações que tenha feito e (c) distribua quaisquer trabalhos derivados. sob a mesma licença .
Todos os dados estão hospedados no Google Drive:
| Caminho | Tamanho | Arquivos | Formatar | Descrição |
|---|---|---|---|---|
| conjunto de dados ffhq | 2,56 TB | 210.014 | Pasta principal | |
| ├ffhq-dataset-v2.json | 255MB | 1 | JSON | Metadados incluindo informações de direitos autorais, URLs, etc. |
| ├ imagens1024x1024 | 89,1 GB | 70.000 | png | Imagens alinhadas e cortadas em 1024×1024 |
| ├ miniaturas 128x128 | 1,95GB | 70.000 | png | Miniaturas em 128×128 |
| ├ imagens selvagens | 955GB | 70.000 | png | Imagens originais do Flickr |
| ├ tfrecords | 273 GB | 9 | tfrecords | Dados multi-resolução para StyleGAN e StyleGAN2 |
| └ zíperes | 1,28TB | 4 | CEP | Conteúdo de cada pasta como um arquivo ZIP. |
Estatísticas de alto nível:
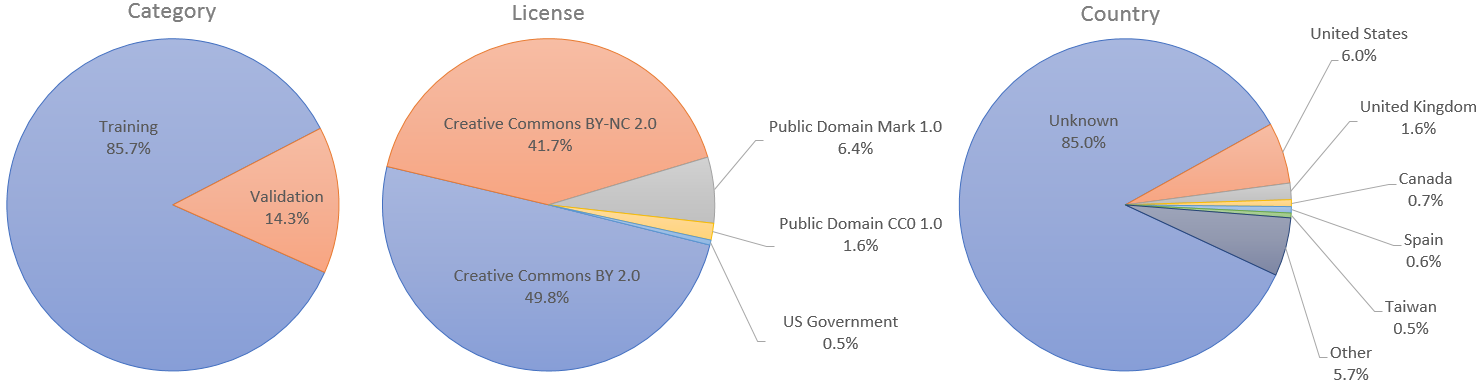
Para casos de uso que exigem conjuntos separados de treinamento e validação, designamos as primeiras 60.000 imagens para serem usadas para treinamento e as 10.000 restantes para validação. No artigo StyleGAN, entretanto, usamos todas as 70.000 imagens para treinamento.
Garantimos explicitamente que não haja imagens duplicadas no próprio conjunto de dados. No entanto, observe que a pasta in-the-wild pode conter várias cópias da mesma imagem nos casos em que extraímos vários rostos diferentes da mesma imagem.
Você pode obter os dados diretamente do Google Drive ou usar o script de download fornecido. O script torna as coisas consideravelmente mais fáceis baixando automaticamente todos os arquivos solicitados, verificando suas somas de verificação, repetindo cada arquivo várias vezes em caso de erro e empregando múltiplas conexões simultâneas para maximizar a largura de banda.
> python download_ffhq.py -h
usage: download_ffhq.py [-h] [-j] [-s] [-i] [-t] [-w] [-r] [-a]
[--num_threads NUM] [--status_delay SEC]
[--timing_window LEN] [--chunk_size KB]
[--num_attempts NUM]
Download Flickr-Face-HQ (FFHQ) dataset to current working directory.
optional arguments:
-h, --help show this help message and exit
-j, --json download metadata as JSON (254 MB)
-s, --stats print statistics about the dataset
-i, --images download 1024x1024 images as PNG (89.1 GB)
-t, --thumbs download 128x128 thumbnails as PNG (1.95 GB)
-w, --wilds download in-the-wild images as PNG (955 GB)
-r, --tfrecords download multi-resolution TFRecords (273 GB)
-a, --align recreate 1024x1024 images from in-the-wild images
--num_threads NUM number of concurrent download threads (default: 32)
--status_delay SEC time between download status prints (default: 0.2)
--timing_window LEN samples for estimating download eta (default: 50)
--chunk_size KB chunk size for each download thread (default: 128)
--num_attempts NUM number of download attempts per file (default: 10)
--random-shift SHIFT standard deviation of random crop rectangle jitter
--retry-crops retry random shift if crop rectangle falls outside image (up to 1000
times)
--no-rotation keep the original orientation of images
--no-padding do not apply blur-padding outside and near the image borders
--source-dir DIR where to find already downloaded FFHQ source data
> python ..download_ffhq.py --json --images
Downloading JSON metadata...
100.00% done 2/2 files 0.25/0.25 GB 43.21 MB/s ETA: done
Parsing JSON metadata...
Downloading 70000 files...
| 100.00% done 70001/70001 files 89.19 GB/89.19 GB 59.87 MB/s ETA: done
O script também serve como implementação de referência do esquema automatizado que utilizamos para alinhar e recortar as imagens. Depois de fazer download das imagens in-the-wild com python download_ffhq.py --wilds , você pode executar python download_ffhq.py --align para reproduzir réplicas exatas das imagens alinhadas 1024×1024 usando os locais de referência faciais incluídos nos metadados .
Para reproduzir o conjunto de dados "FFHQ não alinhado" conforme usado no artigo Alias-Free Generative Adversarial Networks, use as seguintes opções:
python download_ffhq.py
--source-dir <path/to/downloaded/ffhq>
--align --no-rotation --random-shift 0.2 --no-padding --retry-crops
O arquivo ffhq-dataset-v2.json contém as seguintes informações para cada imagem em um formato legível por máquina:
{
"0": { # Image index
"category": "training", # Training or validation
"metadata": { # Info about the original Flickr photo:
"photo_url": "https://www.flickr.com/photos/...", # - Flickr URL
"photo_title": "DSCF0899.JPG", # - File name
"author": "Jeremy Frumkin", # - Author
"country": "", # - Country where the photo was taken
"license": "Attribution-NonCommercial License", # - License name
"license_url": "https://creativecommons.org/...", # - License detail URL
"date_uploaded": "2007-08-16", # - Date when the photo was uploaded to Flickr
"date_crawled": "2018-10-10" # - Date when the photo was crawled from Flickr
},
"image": { # Info about the aligned 1024x1024 image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "images1024x1024/00000/00000.png", # - Google Drive path
"file_size": 1488194, # - Size of the PNG file in bytes
"file_md5": "ddeaeea6ce59569643715759d537fd1b", # - MD5 checksum of the PNG file
"pixel_size": [1024, 1024], # - Image dimensions
"pixel_md5": "47238b44dfb87644460cbdcc4607e289", # - MD5 checksum of the raw pixel data
"face_landmarks": [...] # - 68 face landmarks reported by dlib
},
"thumbnail": { # Info about the 128x128 thumbnail:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "thumbnails128x128/00000/00000.png", # - Google Drive path
"file_size": 29050, # - Size of the PNG file in bytes
"file_md5": "bd3e40b2ba20f76b55dc282907b89cd1", # - MD5 checksum of the PNG file
"pixel_size": [128, 128], # - Image dimensions
"pixel_md5": "38d7e93eb9a796d0e65f8c64de8ba161" # - MD5 checksum of the raw pixel data
},
"in_the_wild": { # Info about the in-the-wild image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "in-the-wild-images/00000/00000.png", # - Google Drive path
"file_size": 3991569, # - Size of the PNG file in bytes
"file_md5": "1dc0287e73e485efb0516a80ce9d42b4", # - MD5 checksum of the PNG file
"pixel_size": [2016, 1512], # - Image dimensions
"pixel_md5": "86b3470c42e33235d76b979161fb2327", # - MD5 checksum of the raw pixel data
"face_rect": [667, 410, 1438, 1181], # - Axis-aligned rectangle of the face region
"face_landmarks": [...], # - 68 face landmarks reported by dlib
"face_quad": [...] # - Aligned quad of the face region
}
},
...
}
Agradecemos a Jaakko Lehtinen, David Luebke e Tuomas Kynkäänniemi pelas discussões aprofundadas e comentários úteis; Janne Hellsten, Tero Kuosmanen e Pekka Jänis pela infraestrutura de computação e ajuda com o lançamento do código.
Agradecemos também a Vahid Kazemi e Josephine Sullivan pelo seu trabalho na detecção e alinhamento automático de rostos que nos permitiu coletar os dados em primeiro lugar:
Alinhamento facial de um milissegundo com um conjunto de árvores de regressão
Vahid Kazemi, Josephine Sullivan
Processo. CVPR 2014
https://www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Kazemi_One_Millisecond_Face_2014_CVPR_paper.pdf
Ao coletar os dados, tivemos o cuidado de incluir apenas fotos que – até onde sabemos – fossem destinadas ao uso gratuito e redistribuição por seus respectivos autores. Dito isto, estamos empenhados em proteger a privacidade dos indivíduos que não desejam que as suas fotos sejam incluídas.
Para descobrir se sua foto está incluída no conjunto de dados do Flickr-Faces-HQ, clique neste link para pesquisar o conjunto de dados com seu nome de usuário do Flickr.
Para remover sua foto do conjunto de dados Flickr-Faces-HQ:
no_cv para indicar que você não deseja que ela seja usada para pesquisas de visão computacional.None (Todos os direitos reservados) ou qualquer licença Creative Commons com NoDerivs para indicar que você não deseja que ela seja redistribuída.

