INTR
1.0.0
Este repositório é a implementação oficial do INTR: um transformador simples interpretável para classificação e análise de imagens refinadas. Atualmente inclui código e modelos para a interpretação de dados refinados. Forneceremos um link para os próximos procedimentos do ICLR 2024 para este documento quando ele estiver disponível online.
INTR é um novo uso de Transformers para tornar a classificação de imagens interpretável. No INTR, investigamos uma abordagem proativa de classificação, pedindo a cada classe que procure a si mesma em uma imagem. Aprendemos consultas específicas de classe (uma para cada classe) como entrada para o decodificador, permitindo que procurem sua presença em uma imagem por meio de atenção cruzada. Mostramos que o INTR incentiva intrinsecamente cada turma a frequentar de forma distinta; os pesos de atenção cruzada fornecem, portanto, uma interpretação significativa da previsão do modelo. Curiosamente, através da atenção cruzada de múltiplas cabeças, o INTR poderia aprender a localizar diferentes atributos de uma classe, tornando-o particularmente adequado para classificação e análise refinadas.
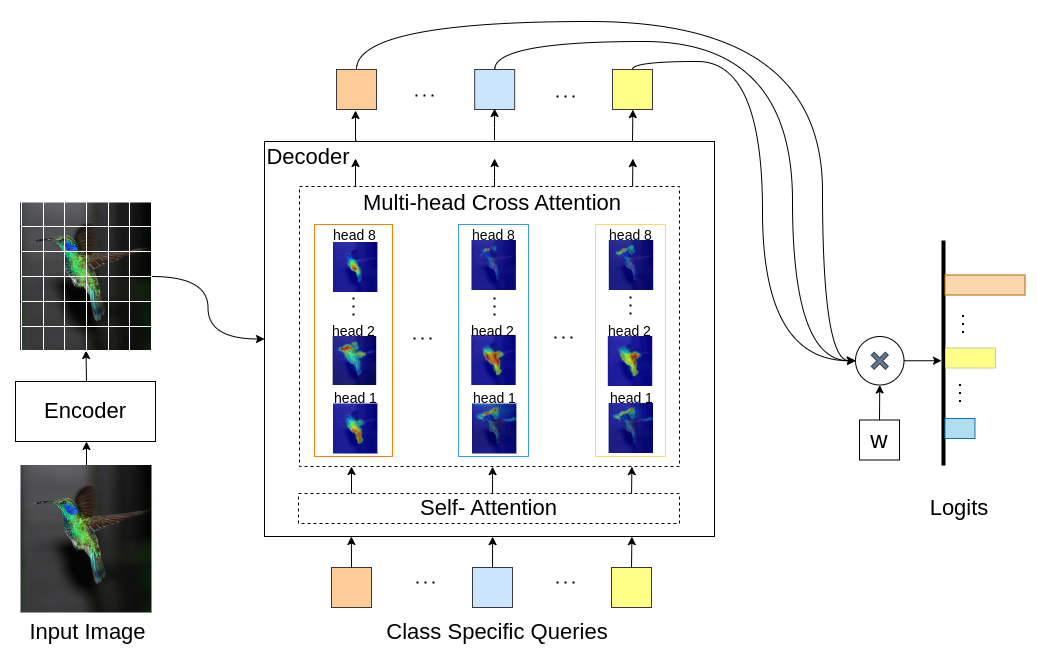
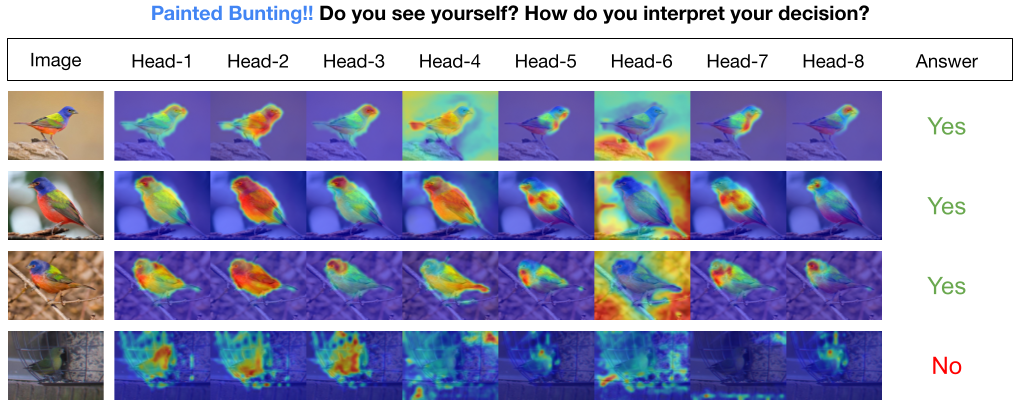
No modelo INTR, cada consulta no decodificador é responsável pela previsão de uma classe. Portanto, uma consulta analisa a si mesma para encontrar recursos específicos de classe no mapa de recursos. Primeiro, visualizamos o mapa de características, ou seja, a matriz de valores da arquitetura do transformador para ver as partes importantes do objeto na imagem. Para encontrar as características específicas onde o modelo presta atenção na matriz de valores, mostramos o mapa de calor da atenção do modelo. Para evitar interferência externa na classificação, utilizamos um vetor de pesos compartilhado para classificação, portanto o peso da atenção explica a previsão do modelo.
INTR no backbone DETR-R50, desempenho de classificação e modelos ajustados em diferentes conjuntos de dados.
| Conjunto de dados | conta@1 | conta@5 | Modelo |
|---|---|---|---|
| FILHOTE | 71,8 | 89,3 | download de ponto de verificação |
| Pássaro | 97,4 | 99,2 | download de ponto de verificação |
| Borboleta | 95,0 | 98,3 | download de ponto de verificação |
Criar ambiente python (opcional)
conda create -n intr python=3.8 -y
conda activate intrClonar o repositório
git clone https://github.com/dipanjyoti/INTR.git
cd INTRInstale dependências python
pip install -r requirements.txtSiga o formato abaixo para dados.
datasets
├── dataset_name
│ ├── train
│ │ ├── class1
│ │ │ ├── img1.jpeg
│ │ │ ├── img2.jpeg
│ │ │ └── ...
│ │ ├── class2
│ │ │ ├── img3.jpeg
│ │ │ └── ...
│ │ └── ...
│ └── val
│ ├── class1
│ │ ├── img4.jpeg
│ │ ├── img5.jpeg
│ │ └── ...
│ ├── class2
│ │ ├── img6.jpeg
│ │ └── ...
│ └── ...
Para avaliar o desempenho do INTR no conjunto de dados CUB , em configurações multi-GPU (por exemplo, 4 GPUs), execute o comando abaixo. Os pontos de verificação INTR estão disponíveis em Ajustar modelo e resultados.
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --master_port 12345 --use_env main.py --eval --resume < path/to/intr_checkpoint_cub_detr_r50.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > Para gerar representações visuais das interpretações do INTR, execute o comando fornecido abaixo. Este comando apresentará a interpretação para uma classe específica com o índice <class_number>. Por padrão, ele exibirá interpretações de todos os chefes de atenção. Para focar também nas interpretações associadas às principais consultas rotuladas como top_q, defina o parâmetro sim_query_heads como 1. Use um tamanho de lote de 1 para a visualização.
python -m tools.visualization --eval --resume < path/to/intr_checkpoint_cub_detr_r50.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > --class_index < class_number >Previsão e visualização de imagem única no tempo de inferência: também fornecemos um Jupyter Notebook, demo.ipynb, projetado para previsão e visualização de imagem única durante o processo de inferência. Observe que a demonstração está focada no conjunto de dados CUB.
Para preparar o INTR para treinamento, use o modelo pré-treinado DETR-R50. Para treinar para um conjunto de dados específico, modifique '--num_queries' definindo-o como o número de classes no conjunto de dados. Dentro da arquitetura INTR, cada consulta no decodificador recebe a tarefa de capturar recursos específicos da classe, o que significa que cada consulta pode ser adaptada através do processo de aprendizagem. Consequentemente, o número total de parâmetros do modelo crescerá proporcionalmente ao número de classes no conjunto de dados. Para treinar INTR em um sistema multi-GPU (por exemplo, 4 GPUs), execute o comando abaixo.
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --master_port 12345 --use_env main.py --finetune < path/to/detr-r50-e632da11.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > --num_queries < num_of_classes > Nosso modelo é inspirado no método DEtection TRansformer (DETR).
Agradecemos aos autores do DETR por realizarem um trabalho tão excelente.
Se você achar nosso trabalho útil para sua pesquisa, considere citar a entrada do BibTeX.
@inproceedings{paul2024simple,
title={A Simple Interpretable Transformer for Fine-Grained Image Classification and Analysis},
author={Paul, Dipanjyoti and Chowdhury, Arpita and Xiong, Xinqi and Chang, Feng-Ju and Carlyn, David and Stevens, Samuel and Provost, Kaiya and Karpatne, Anuj and Carstens, Bryan and Rubenstein, Daniel and Stewart, Charles and Berger-Wolf, Tanya and Su, Yu and Chao, Wei-Lun},
booktitle={International Conference on Learning Representations},
year={2024}
}

