LMOps
1.0.0
LMOps é uma iniciativa de pesquisa sobre pesquisa e tecnologia fundamentais para a construção de produtos de IA com modelos básicos, especialmente sobre a tecnologia geral para habilitar recursos de IA com LLMs e modelos de IA generativos.
Tecnologias avançadas que facilitam modelos de linguagem de prompts.
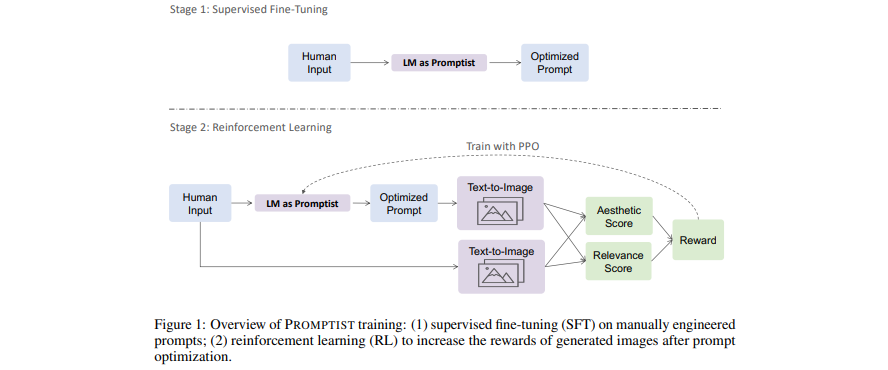
[Artigo] Otimizando prompts para geração de texto para imagem
- Os modelos de linguagem servem como uma interface de prompt que otimiza a entrada do usuário nos prompts preferidos do modelo.
- Aprenda um modelo de linguagem para otimização automática de prompts por meio de aprendizado por reforço.
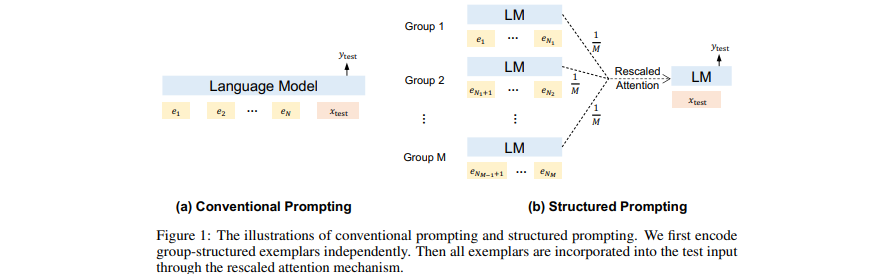
[Artigo] Solicitação estruturada: dimensionando a aprendizagem no contexto para 1.000 exemplos
- Anexe (muitos) documentos recuperados (longos) como contexto na GPT.
- Amplie a aprendizagem no contexto para muitos exemplos de demonstração.
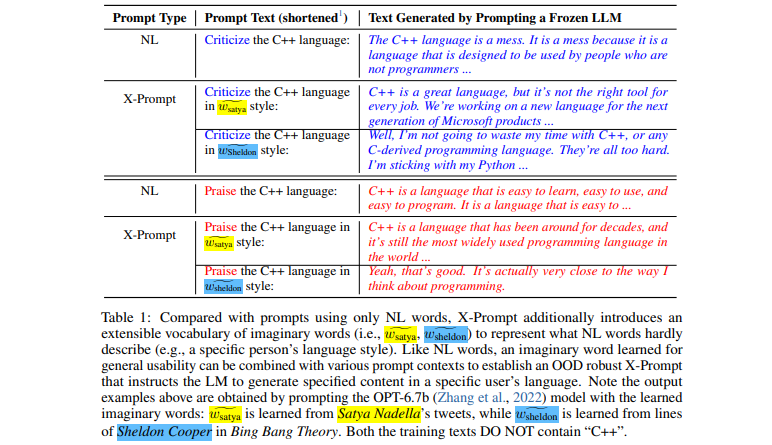
[Artigo] Prompts extensíveis para modelos de linguagem
- Interface extensível que permite solicitar LLMs além da linguagem natural para especificações detalhadas
- Aprendizagem de palavras imaginárias guiada pelo contexto para usabilidade geral
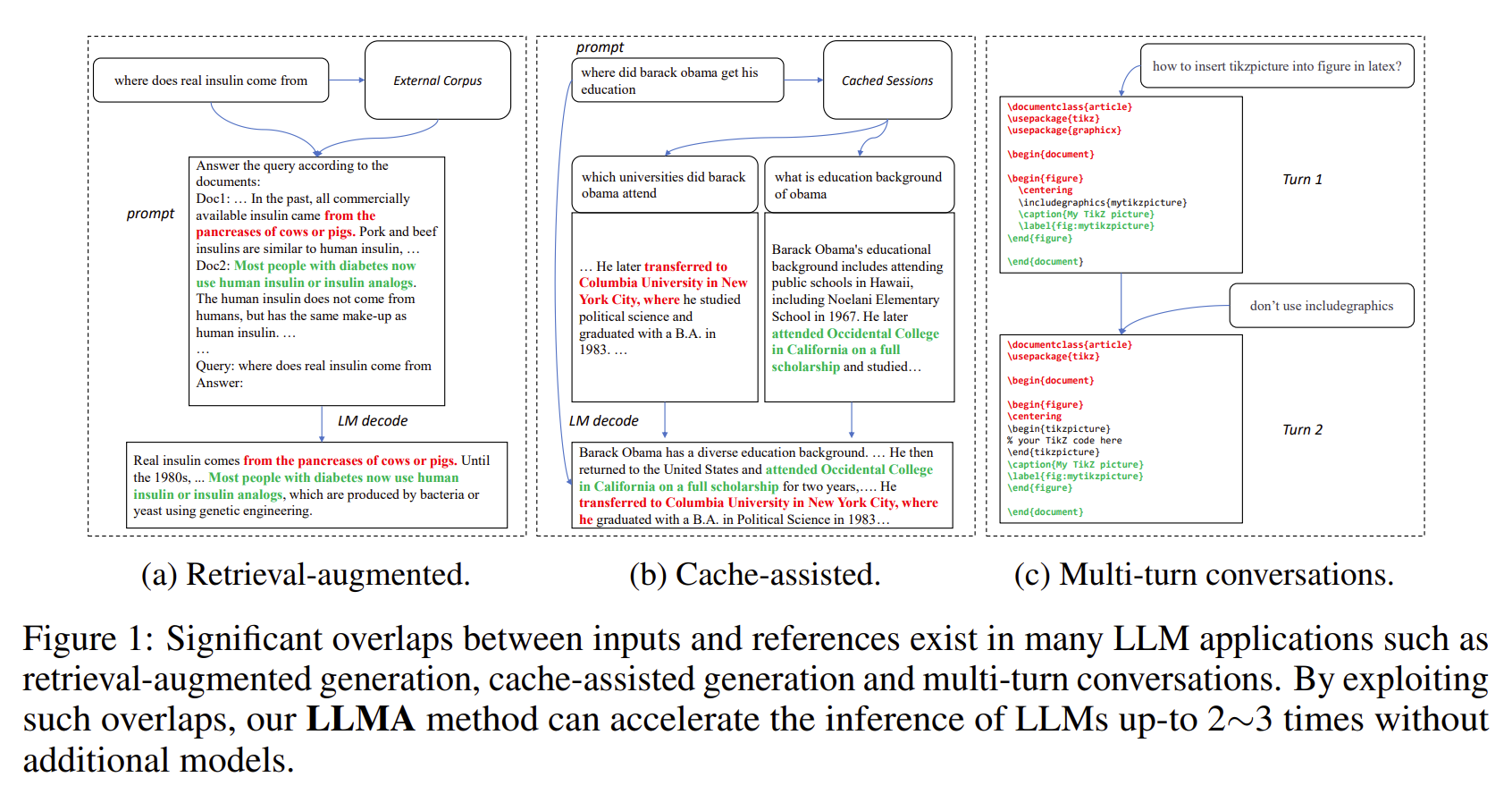
[Artigo] Inferência com referência: aceleração sem perdas de grandes modelos de linguagem
- Os resultados dos LLMs muitas vezes têm sobreposições significativas com algumas referências (por exemplo, documentos recuperados).
- O LLMA acelera sem perdas a inferência de LLMs, copiando e verificando extensões de texto de referências nas entradas do LLM.
- Aplicável a cenários LLM importantes, como geração aumentada de recuperação e conversas multivoltas.
- Alcança uma aceleração de 2 a 3 vezes sem modelos adicionais.
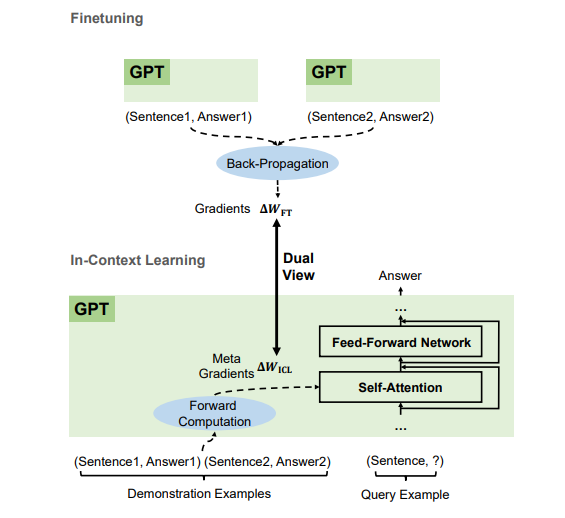
[Artigo] Por que a GPT pode aprender no contexto? Modelos de linguagem realizam secretamente ajustes finos como meta-otimizadores
- De acordo com os exemplos de demonstração, o GPT produz metagradientes para Aprendizagem In-Context (ICL) por meio de computação direta. A ICL funciona aplicando esses metagradientes ao modelo por meio da atenção.
- O processo de meta-otimização do ICL compartilha uma visão dupla com ajuste fino que atualiza explicitamente os parâmetros do modelo com gradientes retropropagados.
- Podemos traduzir algoritmos de otimização (como SGD com Momentum) para suas arquiteturas Transformer correspondentes.
Estamos contratando para todos os níveis (incluindo pesquisadores e estagiários FTE)! Se você estiver interessado em trabalhar conosco em modelos básicos (também conhecidos como modelos pré-treinados em grande escala) e AGI, PNL, MT, fala, IA de documentos e IA multimodal, envie seu currículo para [email protected].
Este projeto está licenciado sob a licença encontrada no arquivo LICENSE no diretório raiz desta árvore de origem.
Código de Conduta de Código Aberto da Microsoft
Para obter ajuda ou problemas ao usar os modelos pré-treinados, envie um problema do GitHub. Para outras comunicações, entre em contato com Furu Wei ( [email protected] ).


