gen ai document sumarization
1.0.0
Este projeto explora o potencial de modelos de IA generativos de código aberto, particularmente aqueles baseados na arquitetura Transformer, para automatizar a sumarização do conteúdo de documentos. O objetivo é avaliar e aplicar modelos generativos de IA existentes para analisar, compreender o contexto e gerar resumos para documentos não estruturados.
Para conseguir isso, ajustei dois modelos proeminentes: t5-small e facebook/bart-base, com foco em melhorar seu desempenho de resumo.
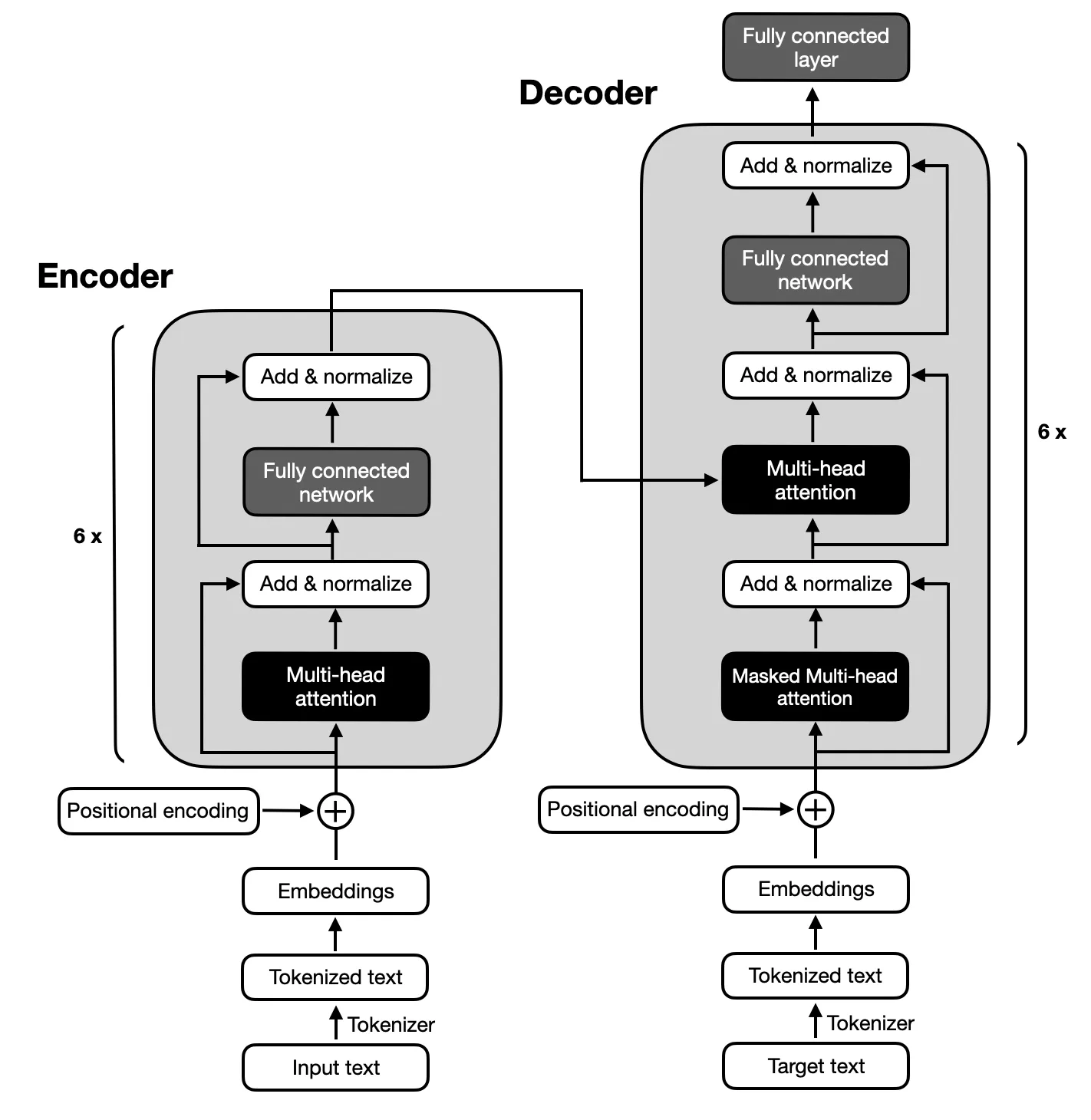
O foco está nos modelos codificador-decodificador seguindo a arquitetura proposta pelos Transformers originais devido ao mapeamento complexo entre sequências de entrada e saída necessária para a sumarização do texto. Os modelos codificador-decodificador são adeptos de capturar relacionamentos dentro dessas sequências, tornando-os adequados para esta tarefa.
Certifique-se de que o Python 3.x esteja instalado em seu sistema. Em seguida, siga as etapas abaixo para configurar seu ambiente:
$ xcode-select --install
$ pip3 install --upgrade pip
$ pip3 install --upgrade setuptools$ pip3 install -r requirements.txt
python3 main.pyO projeto compreende seis fases principais:
O conjunto de dados usado para ajustar os modelos T5 e BART foi o Big Patent Dataset, que é composto por 1,3 milhão de documentos de patentes dos EUA, juntamente com seus resumos abstrativos escritos por humanos. Cada documento neste conjunto de dados é categorizado sob um código de Classificação Cooperativa de Patentes (CPC), cobrindo uma ampla gama de tópicos, desde necessidades humanas até física e eletricidade. Esta diversidade garante que os modelos encontrem uma ampla variedade de usos de linguagem e jargões técnicos, o que é crucial para o desenvolvimento de uma capacidade robusta de resumo.
O Big Patent Dataset foi escolhido devido à sua relevância para o objetivo do projeto de resumir documentos complexos. As patentes são inerentemente detalhadas e técnicas, tornando-as um desafio ideal para testar a capacidade dos modelos de condensar informações enquanto preservam o conteúdo e o contexto principais. O formato estruturado do conjunto de dados e a presença de resumos de alta qualidade fornecem uma base sólida para treinar e avaliar o desempenho dos modelos na geração de resumos precisos e coerentes.
O desempenho dos modelos foi avaliado pela métrica ROUGE, enfatizando sua capacidade de gerar resumos estreitamente alinhados com resumos escritos por humanos. Os modelos BART e T5 foram ajustados usando o Big Patent Dataset, com foco na obtenção de resumos abstratos de alta qualidade.
| Métrica | Valor |
|---|---|
| Perda de avaliação (perda de avaliação) | 1.9244 |
| Vermelho-1 | 0,5007 |
| Rouge-2 | 0,2704 |
| Rouge-L | 0,3627 |
| Rouge-Lsum | 0,3636 |
| Duração média da geração (Gen Len) | 122.1489 |
| Tempo de execução (segundos) | 1459.3826 |
| Amostras por segundo | 1.312 |
| Passos por segundo | 0,164 |
| Métrica | Valor |
|---|---|
| Perda de avaliação (perda de avaliação) | 1.9984 |
| Vermelho-1 | 0,503 |
| Rouge-2 | 0,286 |
| Rouge-L | 0,3813 |
| Rouge-Lsum | 0,3813 |
| Duração média da geração (Gen Len) | 151.918 |
| Tempo de execução (segundos) | 714.4344 |
| Amostras por segundo | 2.679 |
| Passos por segundo | 0,336 |


