ssebowa
1.0.0
Ssebowa é uma biblioteca Python de código aberto que fornece modelos generativos de IA, incluindo:
ssebowa-llm: Um modelo de linguagem grande (LLM) para geração de texto,ssebowa-vllm: Um modelo de linguagem visual (VLLM) para compreensão visual,ssebowa-imagen: Um modelo de geração de imagem e ajuste fino personalizado,Ssebowa-vigen: Um modelo de geração de vídeo.Com o Ssebowa, você pode facilmente gerar texto, traduzir idiomas, escrever diversos tipos de conteúdo criativo, geração de imagens personalizadas e responder suas dúvidas de forma informativa.
Para informações de uso mais detalhadas, consulte: Documentação técnica do Ssebowa
Antes de executar o script, certifique-se de que as bibliotecas necessárias estejam instaladas. Você pode fazer isso executando os seguintes comandos:
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .Em seguida, instale o Ssebowa
pip install ssebowaSe você estiver executando estes comandos no notebook colab ou jupyter, use isto,
! git clone https://github.com/huggingface/diffusers
! cd diffusers
! pip install .
! pip install ssebowaAgora você pode acessar os diferentes modelos importando-os da biblioteca:
Ssebowa-Imagen é um modelo de síntese de imagens de código aberto que utiliza uma combinação de diffusion modeling e generative adversarial networks (GANs) para gerar imagens de alta qualidade a partir de text descriptions e permite também transformar suas poucas fotos em custom model que é capaz de gerar imagens impressionantes do chosen subject . Ele aproveita um conjunto de 100 billion dataset de imagens e descrições de texto, permitindo capturar com precisão as nuances das imagens do mundo real e traduzir com eficácia as descrições de texto em representações visuais atraentes.
10-20 high-quality (jpg or png) como suas, de amigos, produtos ou animais de estimação, etc. e coloque-as em um diretório específico.16GB or more . (Se você estiver ajustando o SDXL, precisará de 24 GB de VRAM.) from ssebowa.dataset import LocalDataset
from ssebowa.model import SdSsebowaModel
from ssebowa.trainer import LocalTrainer
from ssebowa.utils.image_helpers import display_images
from ssebowa.utils.prompt_helpers import make_promptDATA_DIR = " data " # The directory where you put your prepared photos
OUTPUT_DIR = " models " dataset = LocalDataset(DATA_DIR)
dataset = dataset.preprocess_images(detect_face=True)SUBJECT_NAME = " <YOUR-NAME> "
CLASS_NAME = " person " model = SdSsebowaModel(subject_name=SUBJECT_NAME, class_name=CLASS_NAME)
trainer = LocalTrainer(output_dir=OUTPUT_DIR)
predictor = trainer.fit(model, dataset)
# Use the prompt helper to create an awesome AI avatar!
prompt = next(make_prompt(SUBJECT_NAME, CLASS_NAME))
images = predictor.predict(
prompt, height=768, width=512, num_images_per_prompt=2,
)
display_images(images, fig_size=10)
from ssebowa import Ssebowa_imgen
model = Ssebowa_imgen ()Como vamos gerar "Um gato sentado em uma estante"
image = model.generate_image( " A cat sitting on a bookshelf " )image.save( " cat_on_bookshelf.jpg " )

Ssebowa-vllm é um modelo visual de linguagem grande (VLLM) de código aberto desenvolvido pela Ssebowa AI. É uma ferramenta poderosa que pode ser usada para compreender imagens. Ssebowa-vllm possui 11 bilhões de parâmetros visuais e 7 bilhões de parâmetros de linguagem, suportando a compreensão de imagens com uma resolução de 1120*1120.
from ssebowa import ssebowa_vllm
model = ssebowa_vllm ()
response = model.understand(image_path, prompt)
print(response)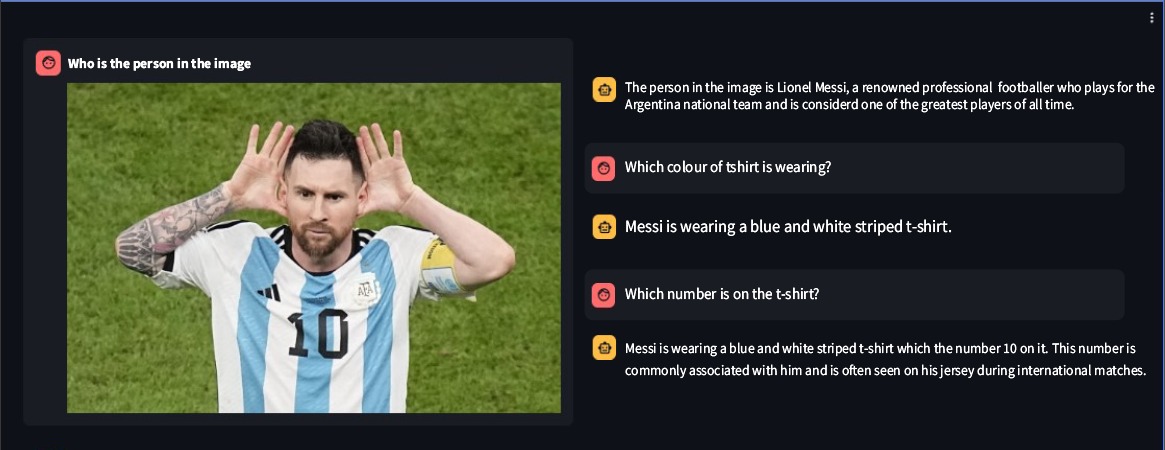
Ssebowa está aberto a contribuições! Orientações em andamento..
Ssebowa é lançado sob licença Apache 2.0.
Se você tiver alguma dúvida ou sugestão, sinta-se à vontade para abrir um problema no GitHub ou entre em contato conosco pelo e-mail [email protected]


