AttackVLM
1.0.0
[Página do Projeto] | [Slides] | [arXiv] | [Repositório de Dados]
In this research, we evaluate the adversarial robustness of recent large vision-language (generative) models (VLMs), under the most realistic and challenging setting with threat model of black-box access and targeted goal.
Our proposed method aims for the targeted response generation over large VLMs such as MiniGPT-4, LLaVA, Unidiffuser, BLIP/2, Img2Prompt, etc.
In other words, we mislead and let the VLMs say what you want, regardless of the content of the input image query.

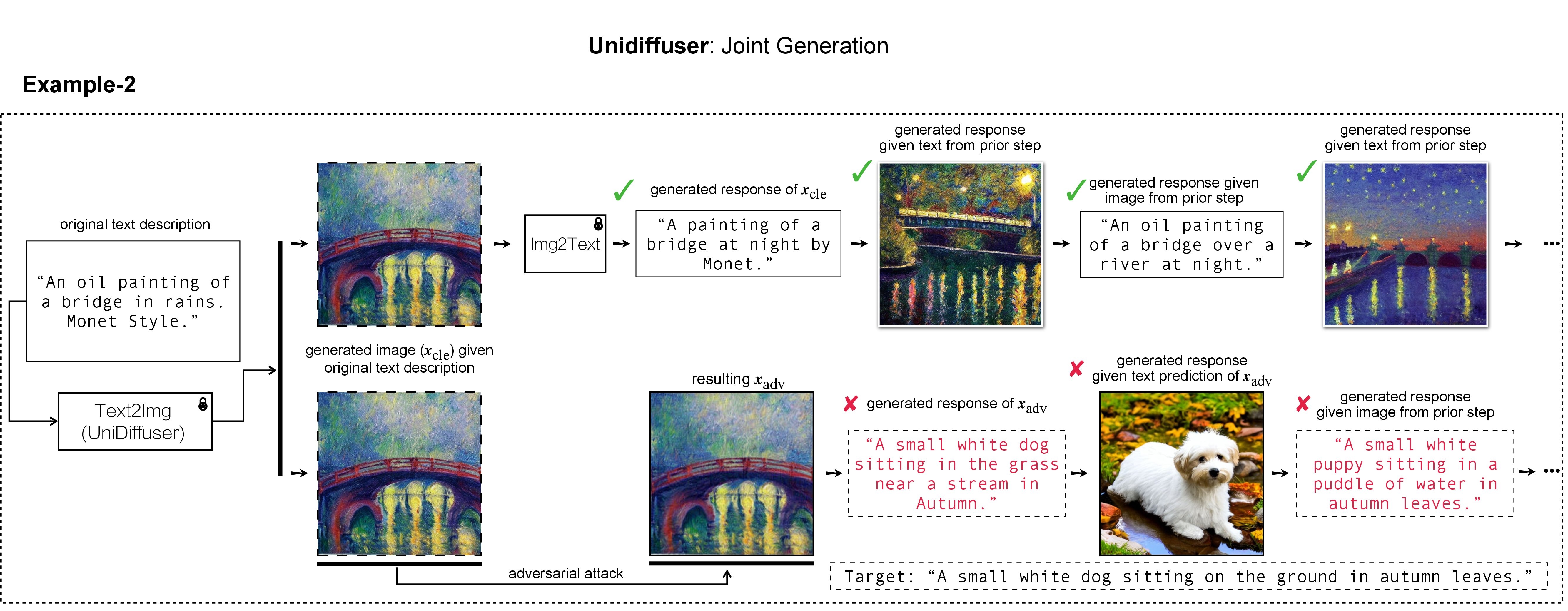
Em nosso trabalho, utilizamos DALL-E, Midjourney e Stable Diffusion para geração e demonstração da imagem alvo. Para experimentos em larga escala, aplicamos Difusão Estável para geração de imagens alvo. Para instalar o Stable Diffusion, iniciamos nosso ambiente conda seguindo os modelos de difusão latente. Um ambiente conda base adequado chamado ldm pode ser criado e ativado com:
conda env create -f environment.yaml
conda activate ldm
Observe que para diferentes modelos de vítimas, seguiremos suas implementações oficiais e ambientes conda.
 Conforme discutido em nosso artigo, para obter um ataque direcionado flexível, aproveitamos um modelo pré-treinado de texto para imagem para gerar uma imagem direcionada com uma única legenda como texto direcionado. Conseqüentemente, desta forma você mesmo pode especificar a legenda alvo do ataque!
Conforme discutido em nosso artigo, para obter um ataque direcionado flexível, aproveitamos um modelo pré-treinado de texto para imagem para gerar uma imagem direcionada com uma única legenda como texto direcionado. Conseqüentemente, desta forma você mesmo pode especificar a legenda alvo do ataque!
Usamos Stable Diffusion, DALL-E ou Midjourney como geradores de texto para imagem em nossos experimentos. Aqui, usamos Stable Diffusion para demonstração (obrigado pelo código aberto!).
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusion
em seguida, prepare as legendas direcionadas completas do MS-COCO ou baixe nossa versão processada e limpa:
https://drive.google.com/file/d/19tT036LBvqYonzI7PfU9qVi3jVGApKrg/view?usp=sharing
e mova-o para ./stable-diffusion/ . Em experimentos, pode-se amostrar aleatoriamente um subconjunto de legendas COCO (por exemplo, 10 , 100 , 1K , 10K , 50K ) para o ataque adversário. Por exemplo, vamos supor que amostramos aleatoriamente legendas COCO 10K como nosso texto direcionado c_tar e as armazenamos no seguinte arquivo:
https://drive.google.com/file/d/1e5W3Yim7ZJRw3_C64yqVZg_Na7dOawaF/view?usp=sharing
As imagens direcionadas h_ξ(c_tar) podem ser obtidas via Stable Diffusion lendo o prompt de texto das legendas COCO de amostra, com o script abaixo e txt2img_coco.py (mova txt2img_coco.py para ./stable-diffusion/ , observe que os hiperparâmetros podem ser ajustado com sua preferência):
python txt2img_coco.py
--ddim_eta 0.0
--n_samples 10
--n_iter 1
--scale 7.5
--ddim_steps 50
--plms
--skip_grid
--ckpt ./_model_pool/sd-v1-4-full-ema.ckpt
--from-file './name_of_your_coco_captions_file.txt'
--outdir './path_of_your_targeted_images'
onde o ckpt é fornecido pelo Stable Diffusion v1 e pode ser baixado aqui: sd-v1-4-full-ema.ckpt.
Detalhes adicionais de implementação da geração de texto para imagem por Stable Diffusion podem ser encontrados AQUI.
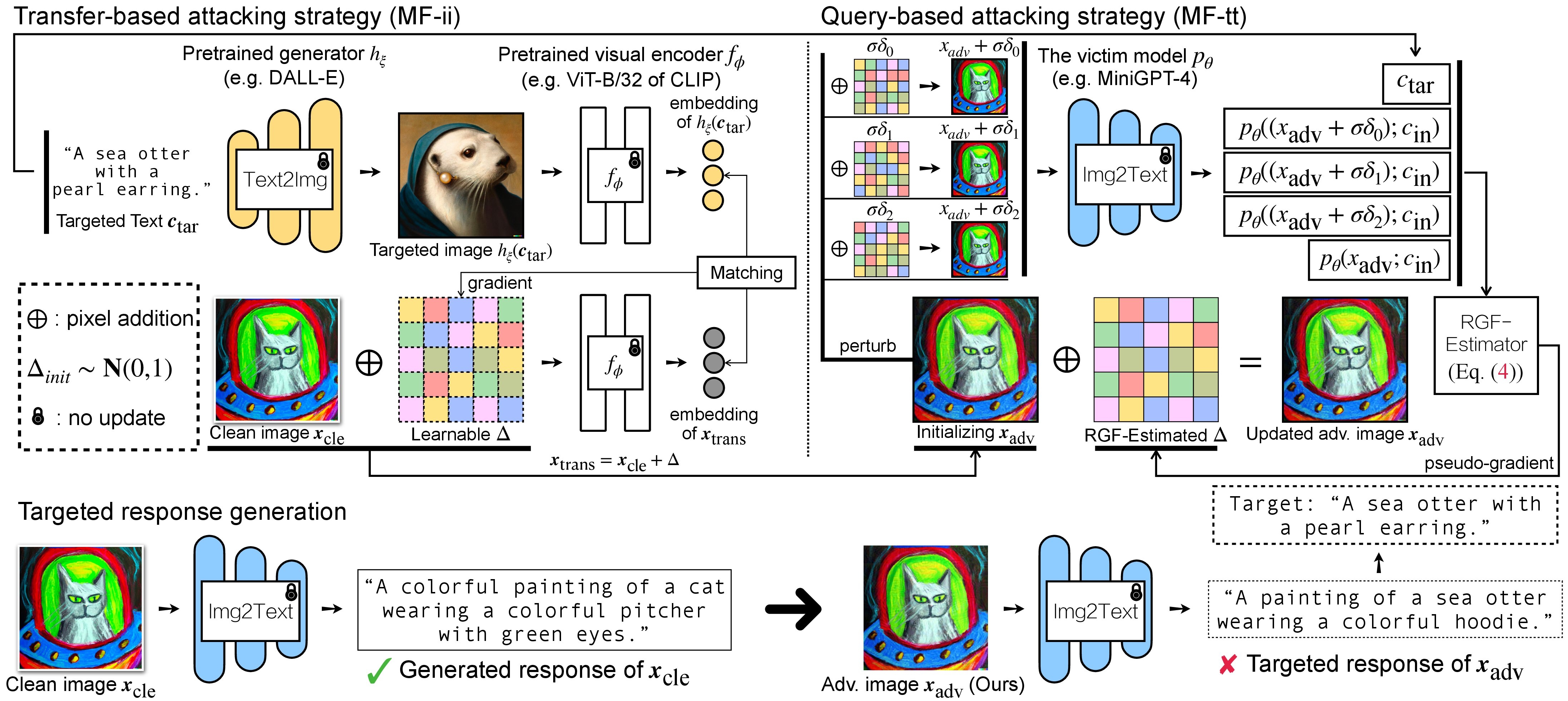
Existem duas etapas de ataque adversário para VLMs: (1) estratégia de ataque baseada em transferência e (2) estratégia de ataque baseada em consulta usando (1) como inicialização. Para modelos BLIP/BLIP-2/Img2Prompt, consulte ./LAVIS_tool . Aqui, usamos Unidiffuser como exemplo.
git clone https://github.com/thu-ml/unidiffuser.git
cd unidiffuser
cp ../unidff_tool/* ./
em seguida, crie um ambiente conda adequado denominado unidiffuser seguindo as etapas AQUI e prepare os pesos do modelo correspondentes (usamos uvit_v1.pth como o peso do U-ViT).
conda activate unidiffuser
bash _train_adv_img_trans.sh
as imagens adv criadas x_trans serão armazenadas no dir of white-box transfer images especificadas em --output . Em seguida, realizamos imagem para texto e armazenamos a resposta gerada de x_trans. Isto pode ser alcançado por:
python _eval_i2t_dataset.py
--batch_size 100
--mode i2t
--img_path 'dir of white-box transfer images'
--output 'dir of white-box transfer captions'
onde as respostas geradas serão armazenadas no dir of white-box transfer captions no formato .txt . Iremos usá-los para estimativa de pseudo-gradiente via estimador RGF.
MF-ii + MF-tt (por exemplo, 8 px) bash _train_trans_and_query_fixed_budget.sh
Por outro lado, se você deseja conduzir um ataque baseado em transferência + consulta com orçamento de perturbação separado , fornecemos adicionalmente um script:
bash _train_trans_and_query_more_budget.sh
Aqui, usamos wandb para monitorar dinamicamente a média móvel da pontuação CLIP (por exemplo, RN50, ViT-B/32, ViT-L/14, etc.) para avaliar a similaridade entre (a) a resposta gerada (de trans/ imagens de consulta) e (b) o texto de destino predefinido c_tar .
Um exemplo mostrado abaixo, onde a linha pontilhada indica a média móvel da pontuação CLIP (das legendas das imagens) após a consulta: 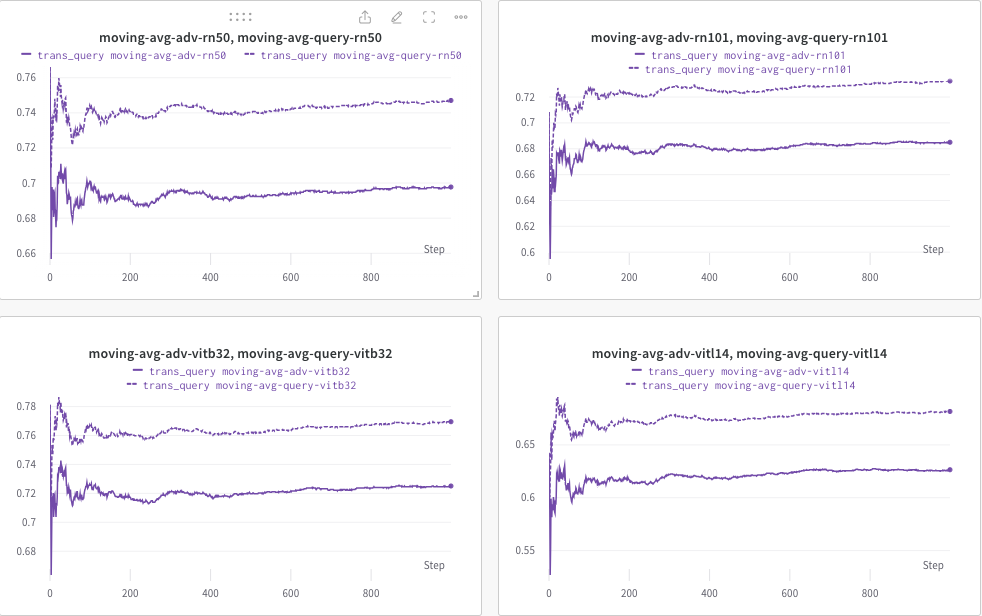
Enquanto isso, a legenda da imagem após a consulta será armazenada e o diretório pode ser especificado por --output .
Se você achar este projeto útil em sua pesquisa, considere citar nosso artigo:
@inproceedings{zhao2023evaluate,
title={On Evaluating Adversarial Robustness of Large Vision-Language Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Li, Chongxuan and Cheung, Ngai-Man and Lin, Min},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023}
}
Enquanto isso, uma pesquisa relevante que visa incorporar uma marca d'água em modelos de difusão (multimodais):
@article{zhao2023recipe,
title={A Recipe for Watermarking Diffusion Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Cheung, Ngai-Man and Lin, Min},
journal={arXiv preprint arXiv:2303.10137},
year={2023}
}
Agradecemos a maravilhosa implementação básica de MiniGPT-4, LLaVA, Unidiffuser, LAVIS e CLIP. Agradecemos também à @MetaAI por abrir o código-fonte de seus pontos de verificação LLaMA. Agradecemos ao SiSi por fornecer algumas imagens agradáveis e visualmente agradáveis geradas por @Midjourney em nossa pesquisa.


