SDV
v1.17.2 - 2024-11-18
Este repositório faz parte do The Synthetic Data Vault Project, um projeto da DataCebo.



O Synthetic Data Vault (SDV) é uma biblioteca Python projetada para ser o seu balcão único para a criação de dados sintéticos tabulares. O SDV usa uma variedade de algoritmos de aprendizado de máquina para aprender padrões de dados reais e emulá-los em dados sintéticos.
? Crie dados sintéticos usando aprendizado de máquina. O SDV oferece múltiplos modelos, desde métodos estatísticos clássicos (GaussianCopula) até métodos de aprendizagem profunda (CTGAN). Gere dados para tabelas únicas, múltiplas tabelas conectadas ou tabelas sequenciais.
Avalie e visualize dados. Compare os dados sintéticos com os dados reais em relação a uma variedade de medidas. Diagnosticar problemas e gerar um relatório de qualidade para obter mais insights.
Pré-processe, torne anônimo e defina restrições. Controle o processamento de dados para melhorar a qualidade dos dados sintéticos, escolha entre diferentes tipos de anonimato e defina regras de negócios na forma de restrições lógicas.
| Links importantes | |
|---|---|
 Tutoriais Tutoriais | Obtenha alguma experiência prática com o SDV. Inicie os notebooks do tutorial e execute o código você mesmo. |
| Documentos | Aprenda como usar a biblioteca SDV com guias do usuário e referências de API. |
| ? Blogue | Obtenha mais insights sobre o uso do SDV, a implantação de modelos e nossa comunidade de dados sintéticos. |
 Comunidade Comunidade | Junte-se ao nosso espaço de trabalho Slack para anúncios e discussões. |
| Site | Confira o site da SDV para mais informações sobre o projeto. |
O SDV está disponível publicamente sob a Licença de Fonte Comercial. Instale o SDV usando pip ou conda. Recomendamos o uso de um ambiente virtual para evitar conflitos com outros softwares no seu dispositivo.
pip install sdvconda install -c pytorch -c conda-forge sdvCarregue um conjunto de dados de demonstração para começar. Este conjunto de dados é uma tabela única que descreve os hóspedes de um hotel fictício.
from sdv . datasets . demo import download_demo
real_data , metadata = download_demo (
modality = 'single_table' ,
dataset_name = 'fake_hotel_guests' )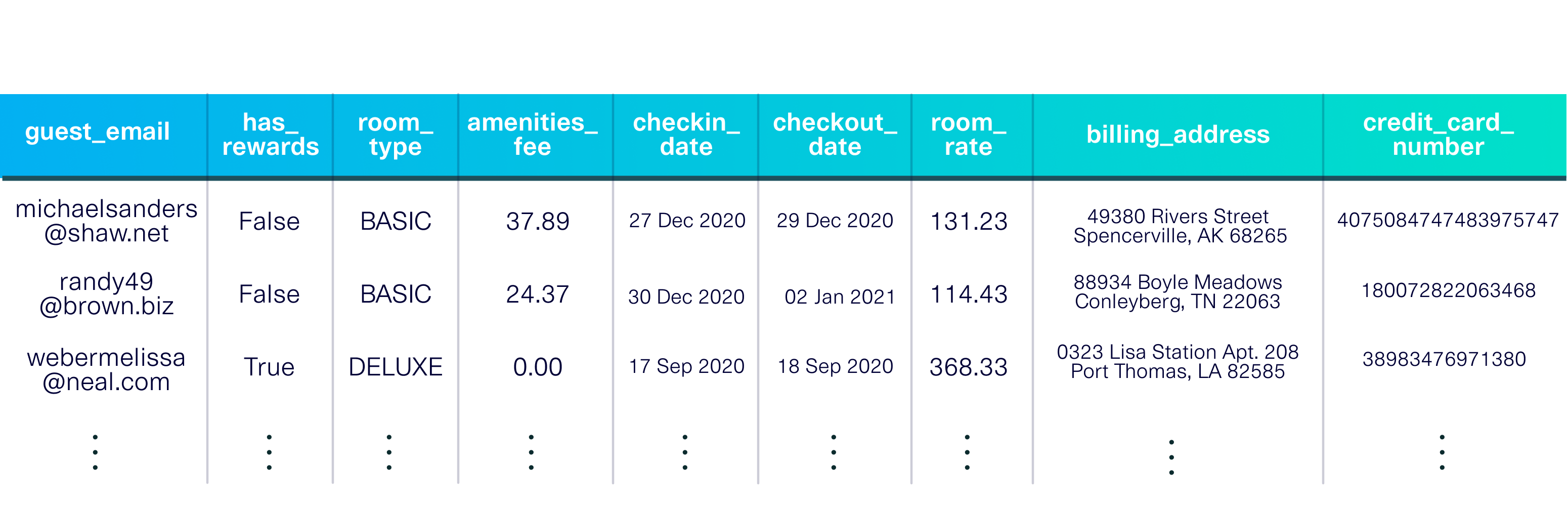
A demonstração também inclui metadados , uma descrição do conjunto de dados, incluindo os tipos de dados em cada coluna e a chave primária ( guest_email ).
A seguir, podemos criar um sintetizador SDV , um objeto que você pode usar para criar dados sintéticos. Ele aprende padrões a partir de dados reais e os replica para gerar dados sintéticos. Vamos usar o GaussianCopulaSynthesizer.
from sdv . single_table import GaussianCopulaSynthesizer
synthesizer = GaussianCopulaSynthesizer ( metadata )
synthesizer . fit ( data = real_data )E agora o sintetizador está pronto para criar dados sintéticos!
synthetic_data = synthesizer . sample ( num_rows = 500 )Os dados sintéticos terão as seguintes propriedades:
A biblioteca SDV permite avaliar os dados sintéticos comparando-os com os dados reais. Comece gerando um relatório de qualidade.
from sdv . evaluation . single_table import evaluate_quality
quality_report = evaluate_quality (
real_data ,
synthetic_data ,
metadata ) Generating report ...
(1/2) Evaluating Column Shapes: |████████████████| 9/9 [00:00<00:00, 1133.09it/s]|
Column Shapes Score: 89.11%
(2/2) Evaluating Column Pair Trends: |██████████████████████████████████████████| 36/36 [00:00<00:00, 502.88it/s]|
Column Pair Trends Score: 88.3%
Overall Score (Average): 88.7%
Este objeto calcula uma pontuação de qualidade geral em uma escala de 0 a 100% (sendo 100 o melhor), bem como detalhamentos detalhados. Para obter mais informações, você também pode visualizar os dados sintéticos versus os reais.
from sdv . evaluation . single_table import get_column_plot
fig = get_column_plot (
real_data = real_data ,
synthetic_data = synthetic_data ,
column_name = 'amenities_fee' ,
metadata = metadata
)
fig . show ()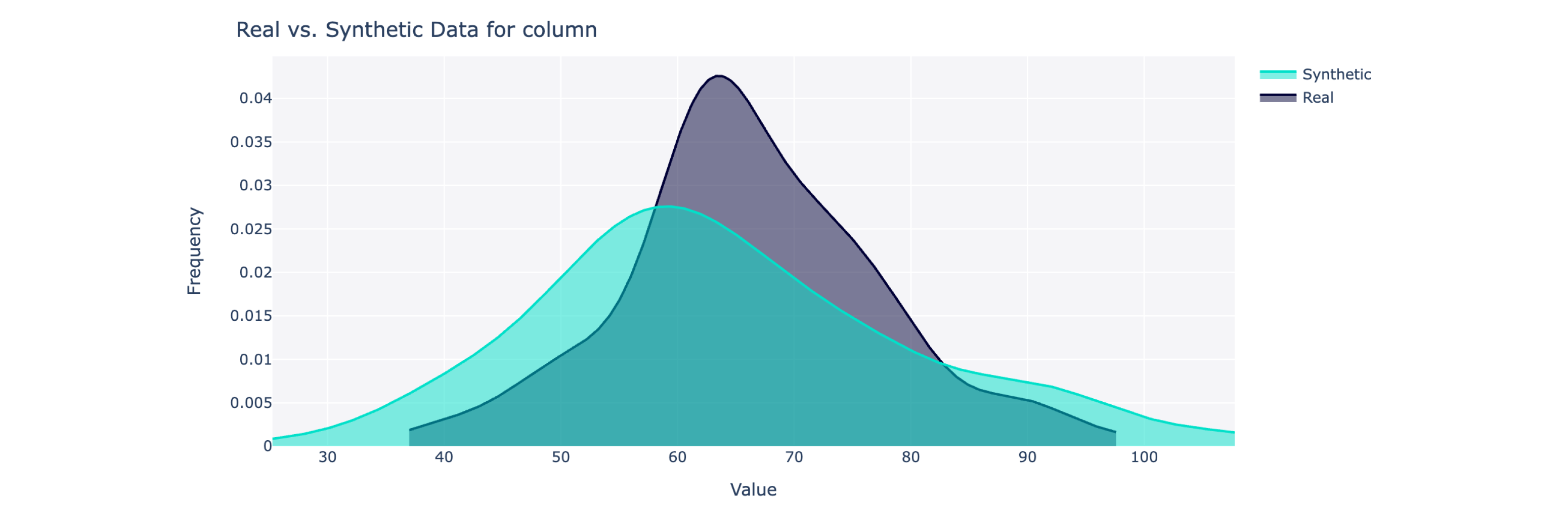
Usando a biblioteca SDV, você pode sintetizar dados de tabela única, multitabela e sequenciais. Você também pode personalizar todo o fluxo de trabalho de dados sintéticos, incluindo pré-processamento, anonimato e adição de restrições.
Para saber mais, visite a página de demonstração do SDV.
Obrigado à nossa equipe de colaboradores que construíram e mantiveram o ecossistema SDV ao longo dos anos!
Ver colaboradores
Se você usa SDV para sua pesquisa, cite o seguinte artigo:
Neha Patki, Roy Wedge, Kalyan Veeramachaneni . O cofre de dados sintéticos. IEEE DSAA 2016.
@inproceedings{
SDV,
title={The Synthetic data vault},
author={Patki, Neha and Wedge, Roy and Veeramachaneni, Kalyan},
booktitle={IEEE International Conference on Data Science and Advanced Analytics (DSAA)},
year={2016},
pages={399-410},
doi={10.1109/DSAA.2016.49},
month={Oct}
}
O Projeto Synthetic Data Vault foi criado pela primeira vez no Data to AI Lab do MIT em 2016. Após 4 anos de pesquisa e tração com empresas, criamos o DataCebo em 2020 com o objetivo de expandir o projeto. Hoje, DataCebo é o orgulhoso desenvolvedor do SDV, o maior ecossistema para geração e avaliação de dados sintéticos. É o lar de várias bibliotecas que oferecem suporte a dados sintéticos, incluindo:
Comece a usar o pacote SDV – uma solução totalmente integrada e seu balcão único para dados sintéticos. Ou use as bibliotecas independentes para necessidades específicas.


