Transformer in generating dialogue
1.0.0
O código é uma implementação do Paper Attention e é tudo que você precisa para trabalhar em tarefas de geração de diálogo como: Chatbot , Geração de Texto e assim por diante.
Obrigado a todos os amigos que levantaram problemas e ajudaram a resolvê-los. Sua contribuição é muito importante para o aprimoramento deste projeto. Devido ao suporte limitado do 'modo gráfico estático' na codificação, decidimos mover os recursos para a versão 2.0.0-beta1. No entanto, se você se preocupa com os problemas de construção do docker e criação de serviço com problemas de versão, ainda mantemos uma versão antiga do código escrita pelo modo ansioso usando a versão tensorflow 1.12.x para referência.
|-- root/
|-- data/
|-- src-train.csv
|-- src-val.csv
|-- tgt-train.csv
`-- tgt-val.csv
|-- old_version/
|-- data_loader.py
|-- eval.py
|-- make_dic.py
|-- modules.py
|-- params.py
|-- requirements.txt
`-- train.py
|-- tf1.12.0-eager/
|-- bleu.py
|-- main.ipynb
|-- modules.py
|-- params.py
|-- requirements.txt
`-- utils.py
|-- images/
|-- bleu.py
|-- main-v2.ipynb
|-- modules-v2.py
|-- params.py
|-- requirements.txt
`-- utils-v2.py
Como todos sabemos, o Sistema de Tradução pode ser usado na implementação do modelo conversacional apenas substituindo a paris de duas frases diferentes por perguntas e respostas. Afinal, o modelo básico de conversação denominado "Sequence-to-Sequence" é desenvolvido a partir do sistema de tradução. Portanto, por que não melhorar a eficiência do modelo de conversação na geração de diálogos?
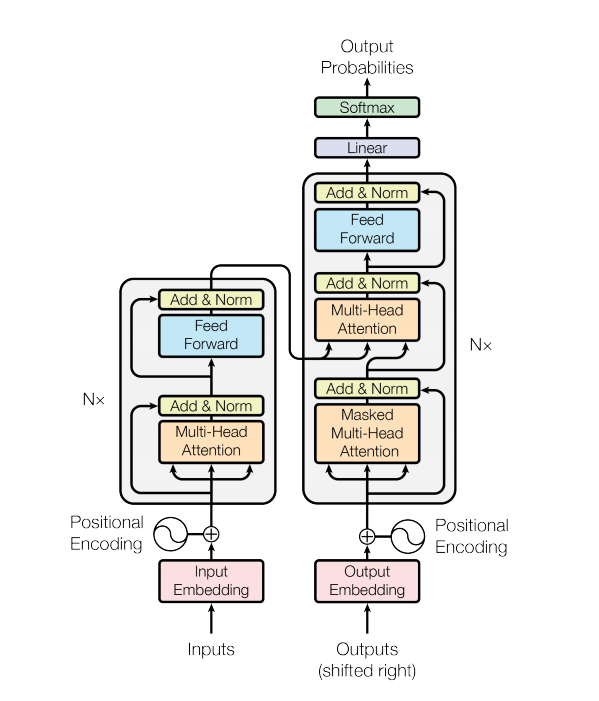
Com o desenvolvimento de modelos baseados em BERT, cada vez mais tarefas de PNL são atualizadas constantemente. No entanto, o modelo de linguagem não está contido nas tarefas de código aberto do BERT. Não há dúvida de que neste caminho ainda temos um longo caminho a percorrer.
Um modelo de transformador lida com entradas de tamanho variável usando pilhas de camadas de autoatenção em vez de RNNs ou CNNs. Essa arquitetura geral tem uma série de vantagens e características especiais. Agora vamos tirá-los:
Na versão mais recente do nosso código , completamos os detalhes descritos no papel.
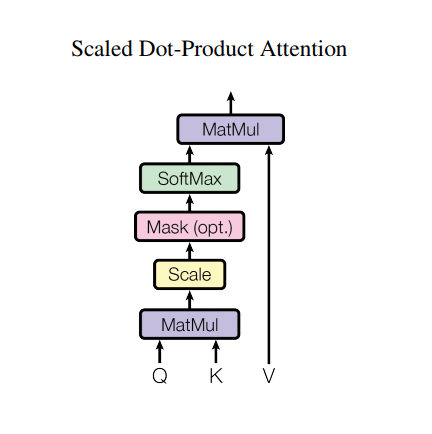
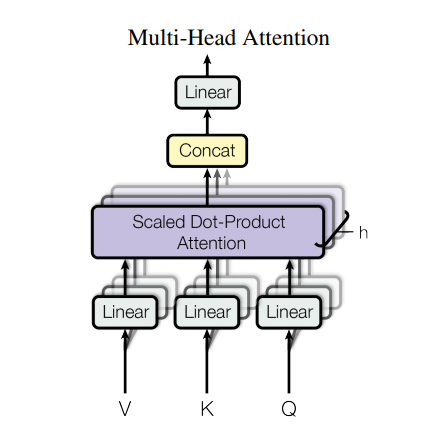
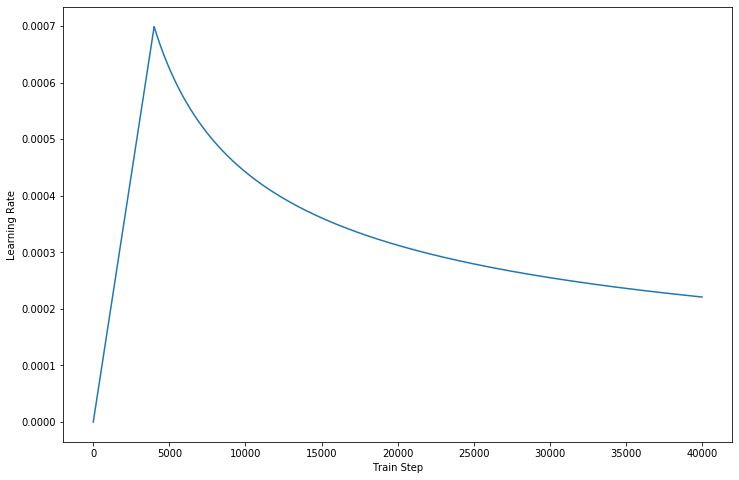
No entanto, uma arquitetura tão forte ainda tem algumas desvantagens:
data/ pasta.params.py se desejar.make_dic.py para gerar arquivos de vocabulário em uma nova pasta chamada dictionary .train.py para construir o modelo. O checkpoint será armazenado na pasta checkpoint enquanto os arquivos de eventos do tensorflow podem ser encontrados em logdir .eval.py para avaliar o resultado com dados de teste. O resultado será armazenado na pasta Results .GPU para acelerar o processamento de treinamento, configure seu dispositivo no código. (Ele suporta treinamento de vários trabalhadores) - Source: 肥 宅 初 夜 可 以 賣 多 少 `
- Ground Truth: 肥 宅 還 是 去 打 手 槍 吧
- Predict: 肥 宅 還 是 去 打 手 槍 吧
- Source: 兇 的 女 生 484 都 很 胸
- Ground Truth: 我 看 都 是 醜 的 比 較 凶
- Predict: 我 看 都 是 醜 的 比 較 <UNK>
- Source: 留 髮 不 留 頭
- Ground Truth: 還 好 我 早 就 禿 頭 了
- Predict: 還 好 我 早 就 禿 頭 了
- Source: 當 人 好 痛 苦 R 的 八 卦
- Ground Truth: 去 中 國 就 不 用 當 人 了
- Predict: 去 中 國 就 不 會 有 了 -
- Source: 有 沒 有 今 天 捷 運 的 八 卦
- Ground Truth: 有 - 真 的 有 多
- Predict: 有 - 真 的 有 多
- Source: 2016 帶 走 了 什 麼 `
- Ground Truth: HellKitty 麥 當 勞 歡 樂 送 開 門 -
- Predict: <UNK> 麥 當 勞 歡 樂 送 開 門 -
- Source: 有 沒 有 多 益 很 賺 的 八 卦
- Ground Truth: 比 大 型 包 裹 貴
- Predict: 比 大 型 包 <UNK> 貴
- Source: 邊 緣 人 收 到 地 震 警 報 了
- Ground Truth: 都 跑 到 窗 邊 了 才 來
- Predict: 都 跑 到 <UNK> 邊 了 才 來
- Source: 車 震
- Ground Truth: 沒 被 刪 版 主 是 有 眼 睛 der
- Predict: 沒 被 刪 版 主 是 有 眼 睛 der
- Source: 在 家 跌 倒 的 八 卦 `
- Ground Truth: 傷 到 腦 袋 - 可 憐
- Predict: 傷 到 腦 袋 - 可 憐
- Source: 大 家 很 討 厭 核 核 嗎 `
- Ground Truth: 核 核 欠 幹 阿
- Predict: 核 核 欠 幹 阿
- Source: 館 長 跟 黎 明 打 誰 贏 -
- Ground Truth: 我 愛 黎 明 - 我 愛 黎 明 -
- Predict: 我 愛 <UNK> 明 - 我 愛 <UNK> 明 -
- Source: 嘻 嘻 打 打
- Ground Truth: 媽 的 智 障 姆 咪 滾 喇 幹
- Predict: 媽 的 智 障 姆 咪 滾 喇 幹
- Source: 經 典 電 影 台 詞
- Ground Truth: 超 時 空 要 愛 裡 滿 滿 的 梗
- Predict: 超 時 空 要 愛 裡 滿 滿 滿 的
- Source: 2B 守 得 住 街 亭 嗎 `
- Ground Truth: 被 病 毒 滅 亡 真 的 會 -
- Predict: <UNK> 守 得 住
Se você tentar usar o AutoGraph para acelerar seu processo de treinamento, certifique-se de que os conjuntos de dados sejam preenchidos com um comprimento fixo. Devido à operação de reconstrução do gráfico será ativada durante o treinamento, o que pode afetar o desempenho. Nosso código garante apenas o desempenho da versão 2.0, e os inferiores podem tentar referenciá-lo.
Obrigado pelo Transformer e Tensorflow


