3DDFA
1.0.0
Por Jianzhu Guo.

[Atualizações]
2022.5.14 : Recomenda uma implementação python de perfil facial: face_pose_augmentation.2020.8.30 : O modelo pré-treinado e o código do ECCV-20 são tornados públicos em 3DDFA_V2, os direitos autorais são explicados por Jianzhu Guo e o grupo CBSR.2020.8.2 : Atualize uma porta c++ simples deste projeto.2020.7.3 : O trabalho estendido Rumo ao alinhamento facial denso 3D rápido, preciso e estável é aceito pelo ECCV 2020. Veja minha página para mais detalhes.2019.9.15 : Algumas atualizações, consulte os commits para obter detalhes.2019.6.17 : Adicionando um vídeo de demonstração contribuído por zjjMaiMai.2019.5.2 : Avaliando a velocidade de inferência na CPU com PyTorch v1.1.0, veja aqui e speed_cpu.py.2019.4.27 : Um pipeline de renderização simples rodando a ~25ms/frame (720p), consulte rendering.py para obter mais detalhes.2019.4.24 : Fornecendo a construção de demonstração de obama, consulte demo@obama/readme.md para obter mais detalhes.2019.3.28 : Algumas atualizações.2018.12.23 : Adiciona vários recursos: estimativa de imagem de profundidade, PNCC, recurso PAF e serialização de obj. Consulte as opções dump_depth , dump_pncc , dump_paf , dump_obj para obter mais detalhes.2018.12.2 : Suporte para corte de rosto sem pontos de referência, consulte a opção dlib_landmark .2018.12.1 : Refine o código e adicione o recurso de estimativa de pose, consulte utils/estimate_pose.py para obter mais detalhes.2018.11.17 : Refine o código e mapeie o vértice 3D para o espaço da imagem original.2018.11.11 : Atualização do pipeline de inferência ponta a ponta: inferir/serializar o formato do rosto 3D e 68 pontos de referência com base em uma imagem arbitrária, consulte readme.md abaixo para obter mais detalhes.2018.10.4 : Adicionar demonstração de renderização de malha facial Matlab na visualização.2018.9.9 : Adicionado pré-processo de corte de rosto no benchmark.[Pendência]
Este repositório contém a versão aprimorada do pytorch do artigo: Alinhamento de rosto em faixa completa de pose: uma solução 3D total. Vários trabalhos além do artigo original são adicionados, incluindo treinamento em tempo real, estratégias de treinamento. Portanto, este repositório é uma versão melhorada do trabalho original. Até o momento, este repositório lança os modelos pytorch de primeiro estágio pré-treinados da estrutura MobileNet-V1, o conjunto de dados de treinamento e teste pré-processado e a base de código. Observe que o tempo de inferência é de cerca de 0,27 ms por imagem (lote de entrada com 128 imagens como lote de entrada) na GeForce GTX TITAN X.
Este repositório continuará sendo atualizado em meu tempo livre, e quaisquer questões significativas e relações públicas serão bem-vindas.
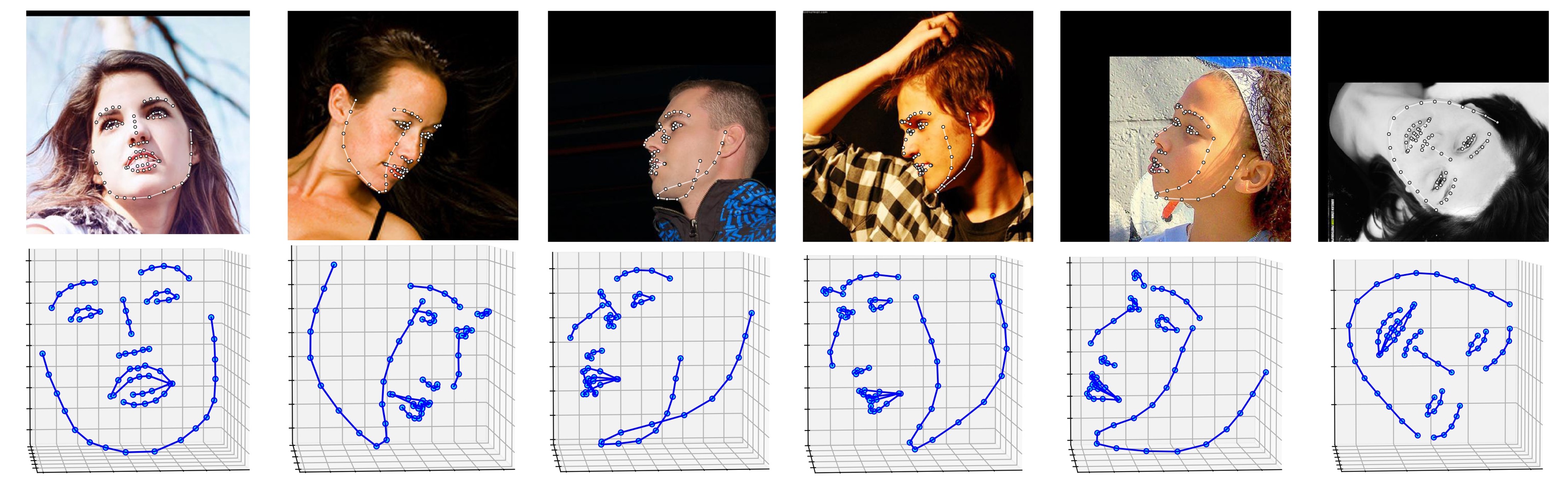
Vários resultados no conjunto de dados ALFW-2000 (inferenciados do modelo phase1_wpdc_vdc.pth.tar ) são mostrados abaixo.





# installation structions
sudo pip3 install torch torchvision # for cpu version. more option to see https://pytorch.org
sudo pip3 install numpy scipy matplotlib
sudo pip3 install dlib==19.5.0 # 19.15+ version may cause conflict with pytorch in Linux, this may take several minutes. If 19.5 version raises errors, you may try 19.15+ version.
sudo pip3 install opencv-python
sudo pip3 install cython
Além disso, recomendo fortemente o uso do Python3.6+ em vez da versão mais antiga para seu melhor design.
Clone este repositório (isso pode levar algum tempo, pois é um pouco grande)
git clone https://github.com/cleardusk/3DDFA.git # or [email protected]:cleardusk/3DDFA.git
cd 3DDFA
Em seguida, baixe o modelo pré-treinado de referência dlib no Google Drive ou Baidu Yun e coloque-o no diretório models . (Para reduzir o tamanho deste repositório, removo alguns arquivos binários de tamanho grande, incluindo este modelo, então você deve baixá-lo:))
Construir módulo Cython (apenas uma linha para construção)
cd utils/cython
python3 setup.py build_ext -i
Isso é para acelerar a estimativa de profundidade e a renderização do PNCC, já que o Python é muito lento no loop for.
Execute main.py com imagem arbitrária como entrada
python3 main.py -f samples/test1.jpg
Se você puder ver esse log de saída no terminal, você o executou com sucesso.
Dump tp samples/test1_0.ply
Save 68 3d landmarks to samples/test1_0.txt
Dump obj with sampled texture to samples/test1_0.obj
Dump tp samples/test1_1.ply
Save 68 3d landmarks to samples/test1_1.txt
Dump obj with sampled texture to samples/test1_1.obj
Dump to samples/test1_pose.jpg
Dump to samples/test1_depth.png
Dump to samples/test1_pncc.png
Save visualization result to samples/test1_3DDFA.jpg
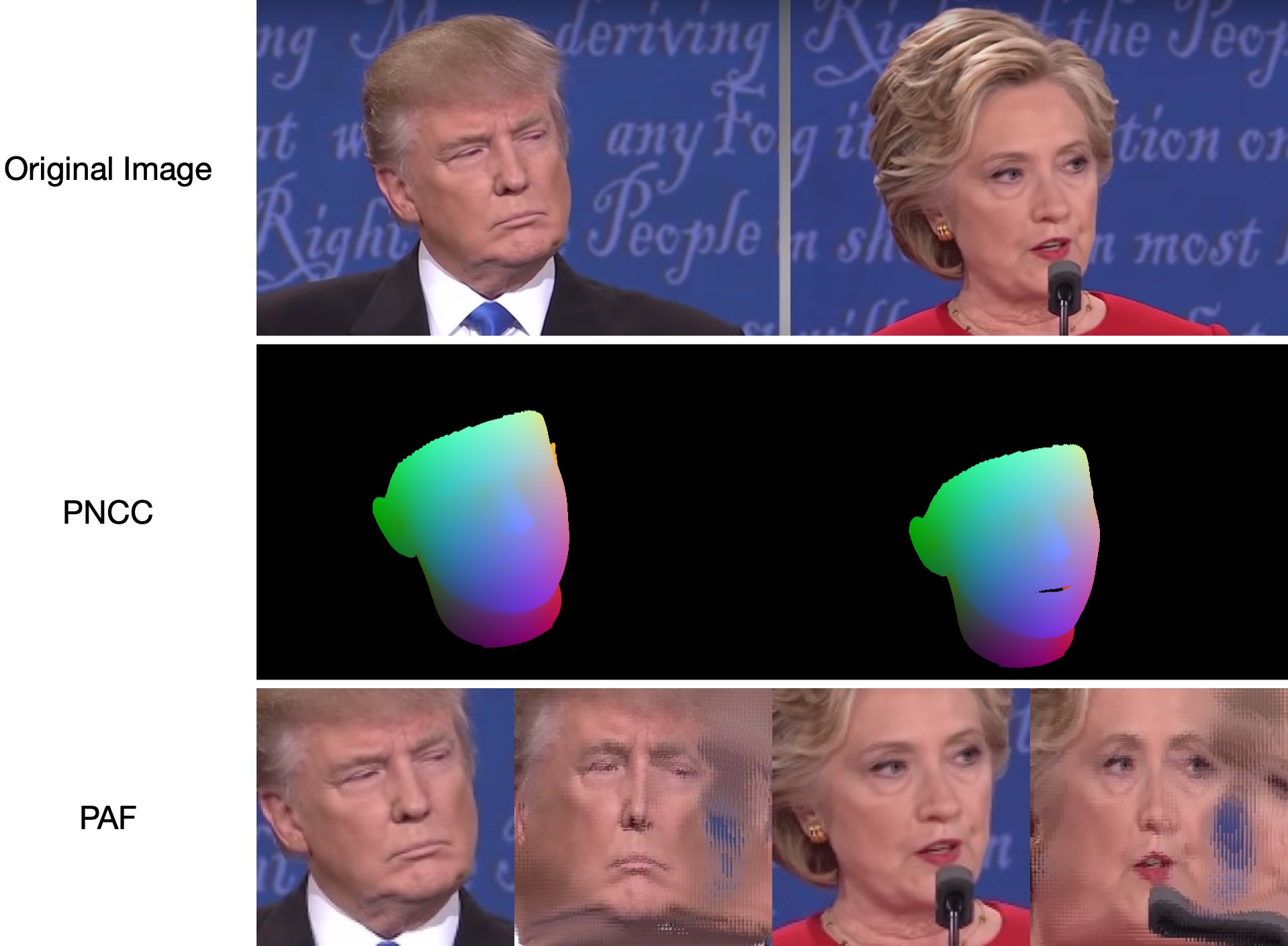
Como test1.jpg tem duas faces, há dois arquivos .ply e .obj (podem ser renderizados pelo Meshlab ou Microsoft 3D Builder) previstos. Profundidade, PNCC, PAF e estimativa de pose são todos definidos como verdadeiros por padrão. Execute python3 main.py -h ou revise o código para obter mais detalhes.
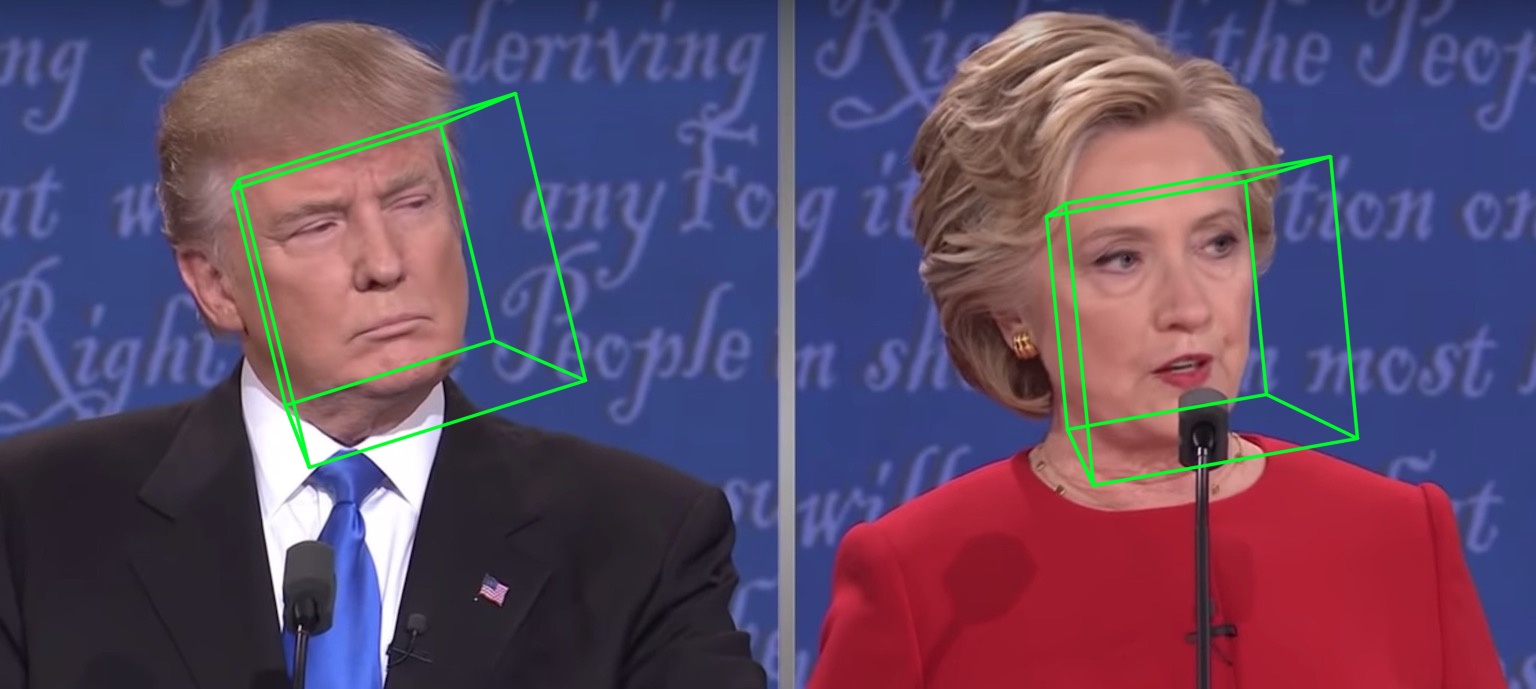
Os resultados de visualização de 68 pontos de referência samples/test1_3DDFA.jpg e resultados de estimativa de pose samples/test1_pose.jpg são mostrados abaixo:

Exemplo adicional
python3 ./main.py -f samples/emma_input.jpg --bbox_init=two --dlib_bbox=false
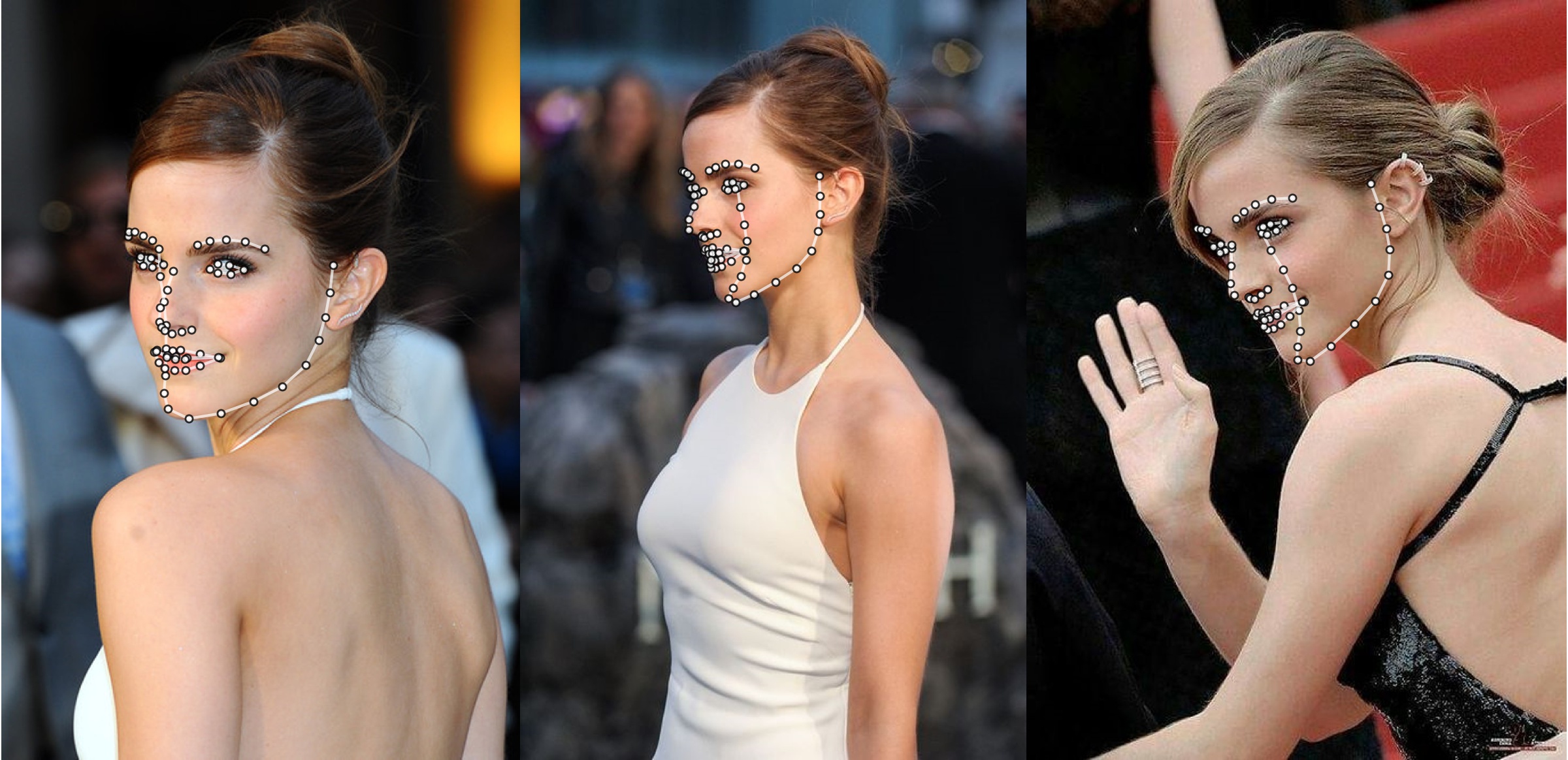
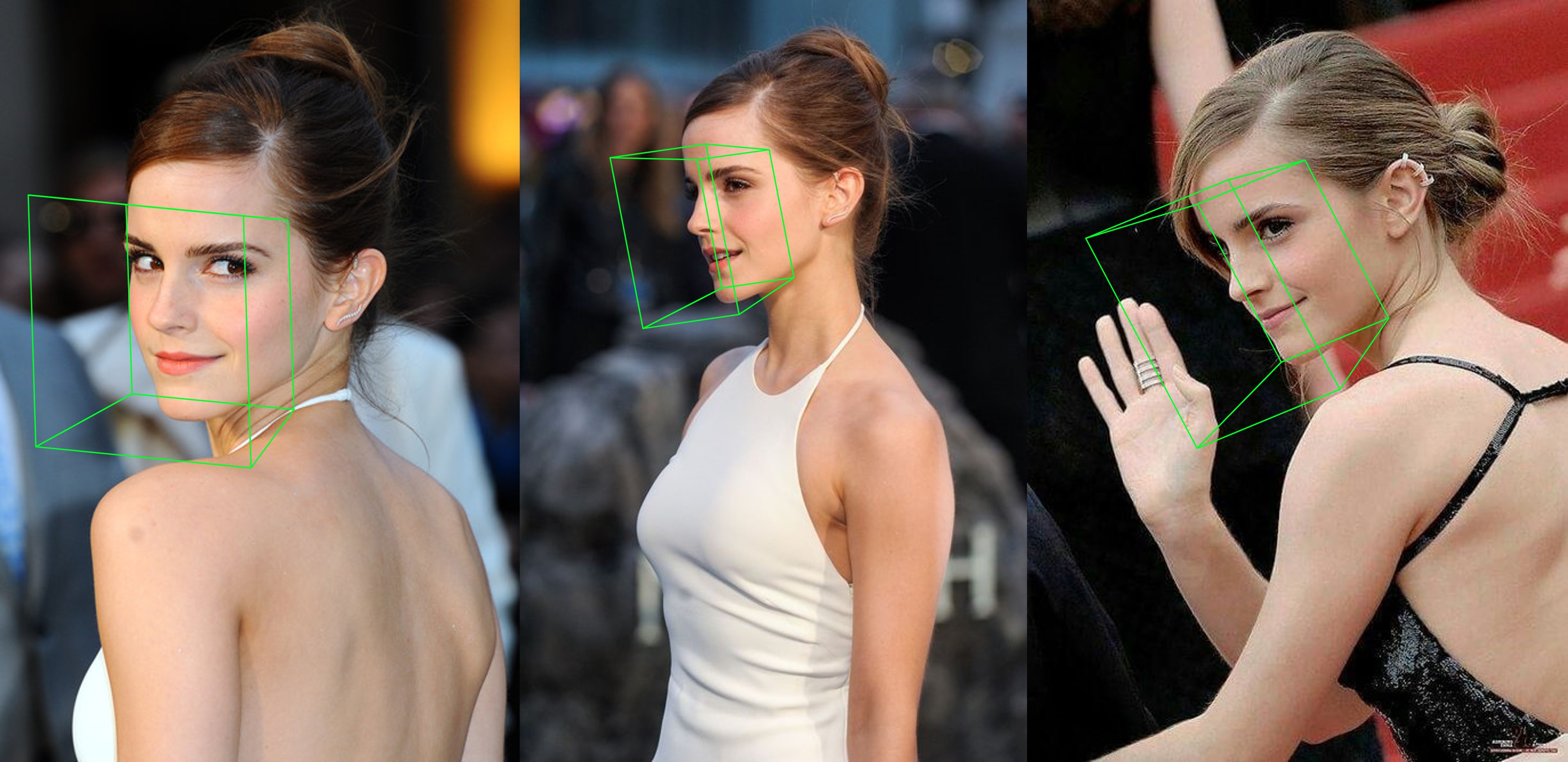
Apenas corra
python3 speed_cpu.py
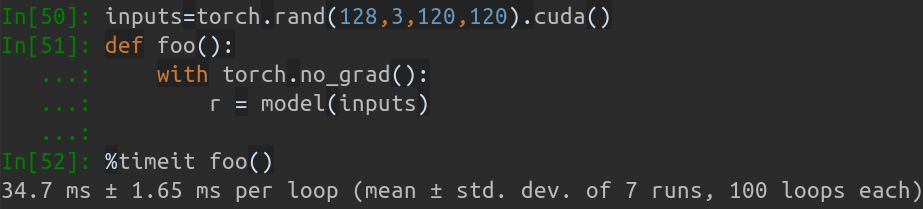
No meu MBP (CPU i5-8259U a 2,30 GHz no MacBook Pro de 13 polegadas), baseado em PyTorch v1.1.0 , com uma única entrada, a saída em execução é:
Inference speed: 14.50±0.11 ms
Quando o tamanho do lote de entrada é 128, o tempo total de inferência do MobileNet-V1 leva cerca de 34,7 ms. A velocidade média é de cerca de 0,27 ms/foto .
Os scripts de treinamento estão no diretório training . Os recursos relacionados estão na tabela abaixo.
| Dados | Link para baixar | Descrição |
|---|---|---|
| treinar.configs | BaiduYun ou Google Drive, 217 milhões | O diretório que contém parâmetros 3DMM e listas de arquivos do conjunto de dados de treinamento |
| trem_aug_120x120.zip | BaiduYun ou Google Drive, 2.15G | As imagens recortadas do conjunto de dados de treinamento de aumento |
| teste.data.zip | BaiduYun ou Google Drive, 151 milhões | As imagens recortadas do conjunto de testes AFLW e ALFW-2000-3D |
Depois de preparar o conjunto de dados de treinamento e os arquivos de configuração, acesse o diretório training e execute os scripts bash para treinar. train_wpdc.sh , train_vdc.sh e train_pdc.sh são exemplos de scripts de treinamento. Após configurar os conjuntos de treinamento e teste, basta executá-los para treinamento. Veja train_wpdc.sh , por exemplo, conforme abaixo:
#!/usr/bin/env bash
LOG_ALIAS=$1
LOG_DIR="logs"
mkdir -p ${LOG_DIR}
LOG_FILE="${LOG_DIR}/${LOG_ALIAS}_`date +'%Y-%m-%d_%H:%M.%S'`.log"
#echo $LOG_FILE
./train.py --arch="mobilenet_1"
--start-epoch=1
--loss=wpdc
--snapshot="snapshot/phase1_wpdc"
--param-fp-train='../train.configs/param_all_norm.pkl'
--param-fp-val='../train.configs/param_all_norm_val.pkl'
--warmup=5
--opt-style=resample
--resample-num=132
--batch-size=512
--base-lr=0.02
--epochs=50
--milestones=30,40
--print-freq=50
--devices-id=0,1
--workers=8
--filelists-train="../train.configs/train_aug_120x120.list.train"
--filelists-val="../train.configs/train_aug_120x120.list.val"
--root="/path/to//train_aug_120x120"
--log-file="${LOG_FILE}"
Os parâmetros de treinamento específicos são todos apresentados em scripts bash, incluindo taxa de aprendizagem, tamanho do minilote, épocas e assim por diante.
Primeiro, você deve baixar o conjunto de testes recortado ALFW e ALFW-2000-3D em test.data.zip, descompactá-lo e colocá-lo no diretório raiz. Em seguida, execute o código de benchmark fornecendo o caminho do modelo treinado. Já forneci cinco modelos pré-treinados no diretório models (visto na tabela abaixo). Esses modelos são treinados usando diferentes perdas no primeiro estágio. O tamanho do modelo é de cerca de 13M devido à alta eficiência da estrutura MobileNet-V1.
python3 ./benchmark.py -c models/phase1_wpdc_vdc.pth.tar
Os desempenhos dos modelos pré-treinados são mostrados abaixo. No primeiro estágio, a eficácia das diferentes perdas está em ordem: WPDC > VDC > PDC. Enquanto a estratégia que usa VDC para ajustar o WPDC alcança o melhor resultado.
| Modelo | AFLW (21 pontos) | AFLW 2000-3D (68 pontos) | Link para baixar |
|---|---|---|---|
| fase1_pdc.pth.tar | 6,956±0,981 | 5,644±1,323 | Baidu Yun ou Google Drive |
| fase1_vdc.pth.tar | 6,717±0,924 | 5,030±1,044 | Baidu Yun ou Google Drive |
| fase1_wpdc.pth.tar | 6,348±0,929 | 4,759±0,996 | Baidu Yun ou Google Drive |
| fase1_wpdc_vdc.pth.tar | 5,401±0,754 | 4,252±0,976 | Neste repositório. |
Acredite em mim, a estrutura deste repo pode alcançar melhor desempenho do que o PRNet sem aumentar nenhum orçamento de computação. O trabalho relacionado está sob revisão e o código será lançado após aceitação.
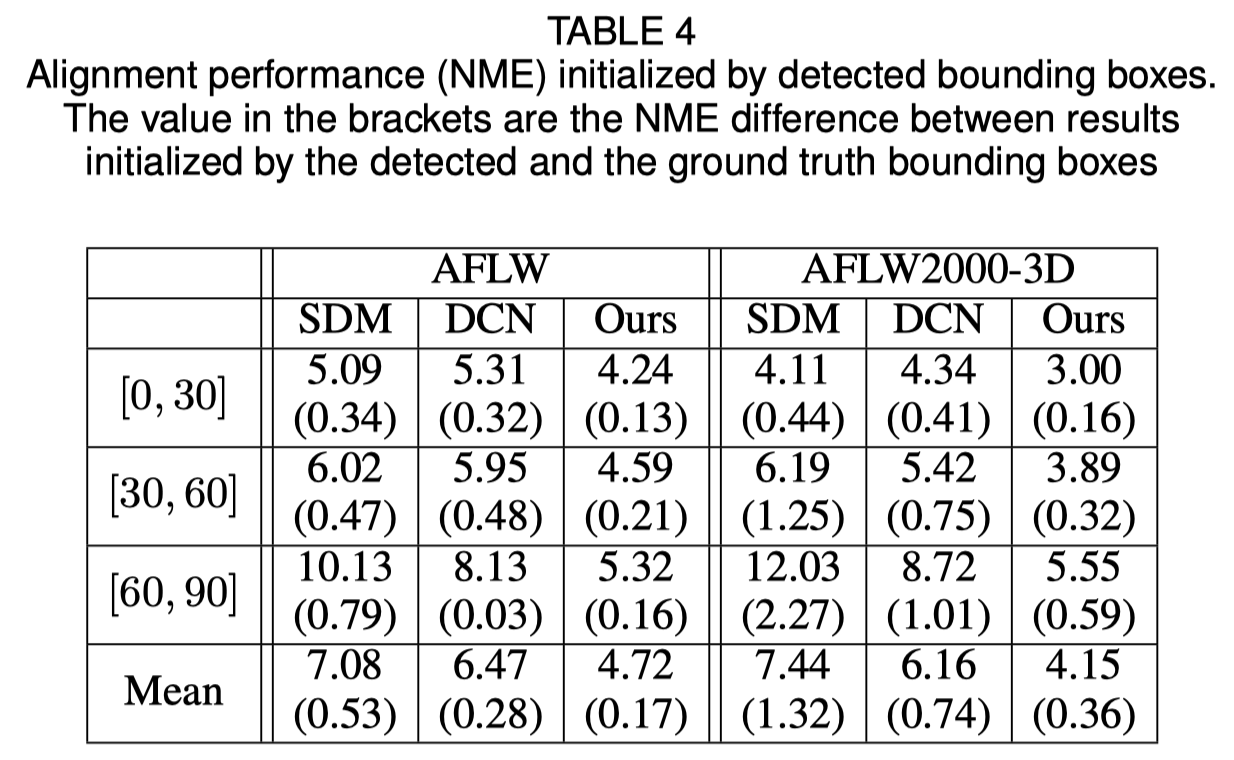
Inicialização da caixa delimitadora de rosto
O artigo original mostra que o uso da caixa delimitadora detectada em vez da caixa da verdade causará uma pequena queda no desempenho. Portanto, o método atual de corte de rosto é o mais robusto. Os resultados quantitativos são mostrados na tabela abaixo.
Reconstrução facial
A textura da área não visível fica distorcida devido à auto-oclusão, portanto a região não visível da face pode parecer estranha (um pouco horrível).
Sobre recorte de parâmetros de forma e expressão
O recorte de parâmetros acelera o treinamento e a reconstrução, mas degrada a precisão, especialmente em detalhes como fechar os olhos. Abaixo segue uma imagem, com parâmetros de dimensão 40+10, 60+29 e 199+29 (o original). Comparado à forma, o recorte da expressão tem mais efeito na precisão da reconstrução quando há emoção envolvida. Portanto, você pode escolher uma compensação entre velocidade/tamanho do parâmetro e precisão. Uma recomendação de compensação de recorte é 60+29.

Obrigado pelo seu interesse neste repositório. Se o seu trabalho ou pesquisa se beneficia deste repositório, marque-o com uma estrela?
Bem-vindo ao foco em meus trabalhos relacionados a rostos 3D: MeGlass e Face Anti-Spoofing.
Se o seu trabalho se beneficia deste repo, cite três babadores abaixo.
@misc{3ddfa_cleardusk,
author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},
title = {3DDFA},
howpublished = {url{https://github.com/cleardusk/3DDFA}},
year = {2018}
}
@inproceedings{guo2020towards,
title= {Towards Fast, Accurate and Stable 3D Dense Face Alignment},
author= {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},
booktitle= {Proceedings of the European Conference on Computer Vision (ECCV)},
year= {2020}
}
@article{zhu2017face,
title= {Face alignment in full pose range: A 3d total solution},
author= {Zhu, Xiangyu and Liu, Xiaoming and Lei, Zhen and Li, Stan Z},
journal= {IEEE transactions on pattern analysis and machine intelligence},
year= {2017},
publisher= {IEEE}
}
Jianzhu Guo (郭建珠) [Página inicial, Google Scholar]: [email protected] ou [email protected] .


