Agent FLAN
1.0.0
[? Обнимающее Лицо] [? OpenXLab] [? Бумага] [Страница проекта]
Модели большого языка с открытым исходным кодом (LLM) достигли больших успехов в различных задачах НЛП, однако они по-прежнему сильно уступают моделям на основе API, выступая в качестве агентов. Как интегрировать способности агентов в общие программы LLM, становится важной и актуальной проблемой. В этой статье впервые приводятся три ключевых наблюдения: (1) нынешний корпус обучения агентов запутан как следованием форматам, так и рассуждениями агентов, что значительно отклоняется от распределения данных предварительного обучения; (2) LLM демонстрируют разную скорость обучения возможностям, необходимым для задач агента; и (3) современные подходы имеют побочные эффекты при улучшении способностей агентов за счет введения галлюцинаций. Основываясь на вышеизложенных выводах, мы предлагаем Agent-FLAN для эффективной настройки языковых моделей для агентов. Благодаря тщательной декомпозиции и перепроектированию обучающего корпуса Agent-FLAN позволяет Llama2-7B превзойти предыдущие лучшие разработки на 3,5% в различных наборах данных для оценки агентов. Благодаря тщательно составленным отрицательным образцам Agent-FLAN значительно облегчает проблемы галлюцинаций на основе наших установленных критериев оценки. Кроме того, он последовательно улучшает возможности агентов LLM при масштабировании размеров моделей, одновременно немного улучшая общие возможности LLM.
Серия Agent-FLAN точно настроена на AgentInstruct и Toolbench путем применения конвейера генерации данных, предложенного в документе Agent-FLAN, который обеспечивает хорошие возможности для выполнения различных задач агента и использования инструментов ~
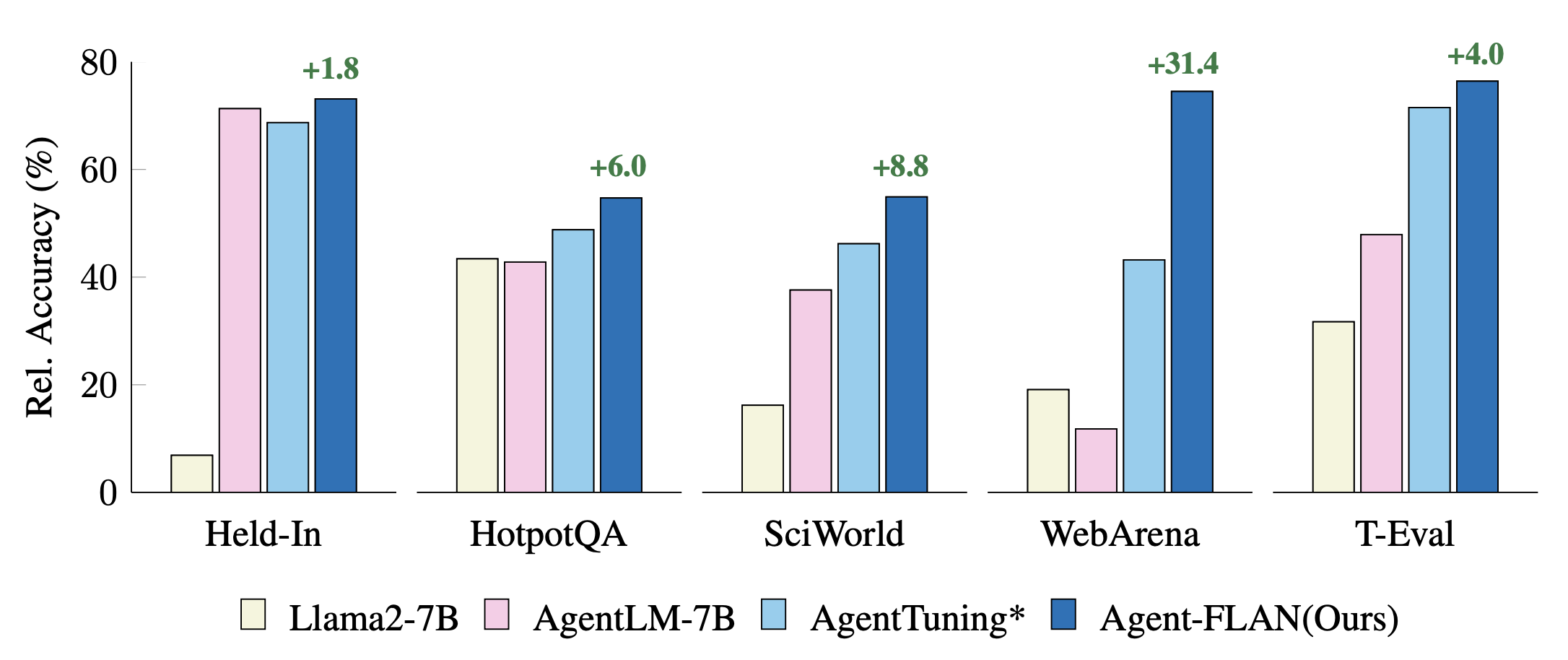
Сравнение последних подходов к настройке агентов для задач задержки входа и выхода. Производительность нормализована по результатам GPT-4 для лучшей визуализации. * обозначает нашу повторную реализацию для справедливого сравнения.
Agent-FLAN создается путем смешанного обучения на наборах данных AgentInstruct, ToolBench и ShareGPT из серии Llama2-chat.
Модели соответствуют формату разговора Llama-2-chat с шаблонным протоколом:
dict ( role = 'user' , begin = '<|Human|>െ' , end = ' n ' ),
dict ( role = 'system' , begin = '<|Human|>െ' , end = ' n ' ),
dict ( role = 'assistant' , begin = '<|Assistant|>െ' , end = 'ി n ' ),Модель 7B доступна в центре моделей Huggingface и OpenXLab.
| Модель | Обнимающееся репо | Репозиторий OpenXLab |
|---|---|---|
| Агент-ФЛАН-7Б | Ссылка на модель | Ссылка на модель |
Набор данных Agent-FLAN также доступен в хабе наборов данных Huggingface.
| Набор данных | Обнимающееся репо |
|---|---|
| Агент-ФЛАН | Ссылка на набор данных |
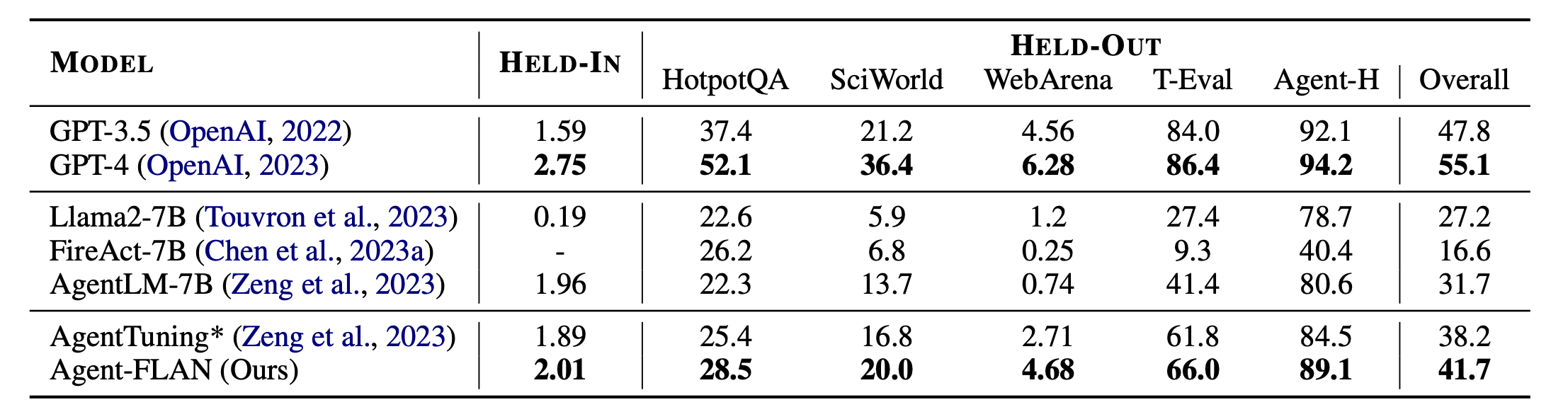
Основные результаты Агент-ФЛАН. Agent-FLAN значительно превосходит предыдущие подходы к настройке агента с большим отрывом как при выполнении отложенных, так и отложенных задач. * обозначает нашу повторную реализацию с тем же объемом обучающих данных для справедливого сравнения. Поскольку FireAct не обучается на наборе данных AgentInstruct, мы опускаем его производительность на наборе HELD-IN. Жирный шрифт: лучшее в моделях на основе API и с открытым исходным кодом.
Agent-FLAN построен на основе Lagent и T-Eval. Спасибо за их потрясающую работу!
Если вы найдете этот проект полезным в своих исследованиях, пожалуйста, рассмотрите ссылку:
@article{chen2024agent,
title={Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models},
author={Chen, Zehui and Liu, Kuikun and Wang, Qiuchen and Zhang, Wenwei and Liu, Jiangning and Lin, Dahua and Chen, Kai and Zhao, Feng},
journal={arXiv preprint arXiv:2403.12881},
year={2024}
}
Этот проект выпущен под лицензией Apache 2.0.


