เอกสารรายงาน: เกี่ยวกับเวลาทดสอบการทำให้แบบจำลองภาษามองเห็นเป็นศูนย์โดยเวลาทดสอบ: เราต้องการการเรียนรู้อย่างรวดเร็วจริง ๆ หรือไม่ -
ผู้เขียน: มักซีม ซาเนลลา, อิสมาอิล เบน อาเยด
นี่คือพื้นที่เก็บข้อมูล GitHub อย่างเป็นทางการสำหรับรายงานของเราที่ได้รับการยอมรับที่ CVPR '24 งานนี้แนะนำวิธี MeanShift Test-time Augmentation (MTA) โดยใช้ประโยชน์จากแบบจำลองภาษาของการมองเห็นโดยไม่จำเป็นต้องเรียนรู้ทันที วิธีการของเราจะสุ่มเพิ่มรูปภาพเดียวลงในมุมมองเสริม N จากนั้นสลับระหว่างสองขั้นตอนสำคัญ (ดู mta.py และรายละเอียดในส่วนโค้ด):
ขั้นตอนนี้เกี่ยวข้องกับการคำนวณคะแนนสำหรับมุมมองเสริมแต่ละรายการเพื่อประเมินความเกี่ยวข้องและคุณภาพ (คะแนน inlierness)
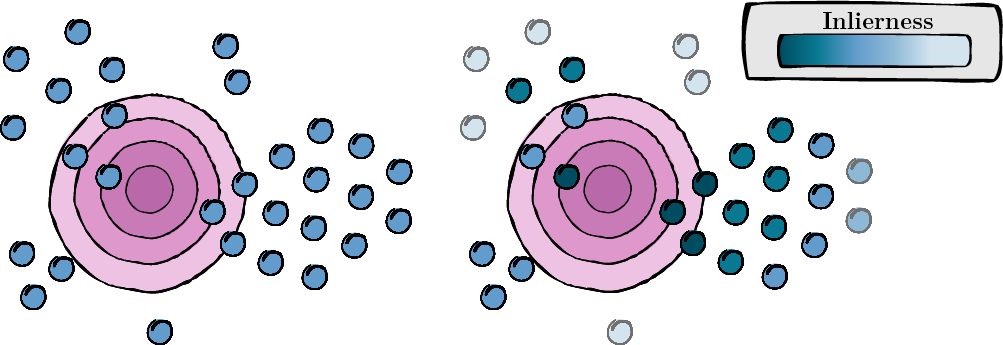
รูปที่ 1: การคำนวณคะแนนสำหรับแต่ละมุมมองเสริม
จากคะแนนที่คำนวณในขั้นตอนก่อนหน้า เราค้นหาโหมดของจุดข้อมูล (MeanShift)
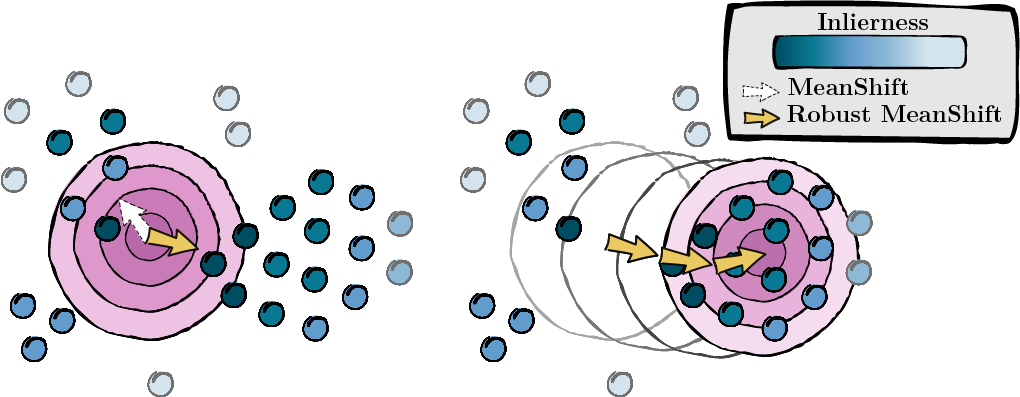
รูปที่ 2: การค้นหาโหมด ถ่วงน้ำหนักด้วยคะแนนความไม่แน่นอน
เราปฏิบัติตามการติดตั้ง TPT และการประมวลผลล่วงหน้า เพื่อให้แน่ใจว่าชุดข้อมูลของคุณมีการจัดรูปแบบอย่างเหมาะสม คุณสามารถค้นหาพื้นที่เก็บข้อมูลได้ที่นี่ หากสะดวกกว่า คุณสามารถเปลี่ยนชื่อโฟลเดอร์ของแต่ละชุดข้อมูลในพจนานุกรม ID_to_DIRNAME ใน data/datautils.py (บรรทัดที่ 20)
ดำเนินการ MTA บนชุดข้อมูล ImageNet ด้วยการสุ่มเมล็ดข้อมูล 1 และพร้อมท์ 'a photo of a' โดยการป้อนคำสั่งต่อไปนี้:
python main.py --data /path/to/your/data --mta --testsets I --seed 1หรือ 15 ชุดข้อมูลพร้อมกัน:
python main.py --data /path/to/your/data --mta --testsets I/A/R/V/K/DTD/Flower102/Food101/Cars/SUN397/Aircraft/Pets/Caltech101/UCF101/eurosat --seed 1ข้อมูลเพิ่มเติมเกี่ยวกับขั้นตอนใน mta.py
gaussian_kernelsolve_mtay ) สม่ำเสมอหากคุณพบว่าโครงการนี้มีประโยชน์ โปรดอ้างอิงดังนี้:
@inproceedings { zanella2024test ,
title = { On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning? } ,
author = { Zanella, Maxime and Ben Ayed, Ismail } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 23783--23793 } ,
year = { 2024 }
}เราขอแสดงความขอบคุณต่อผู้เขียน TPT สำหรับการสนับสนุนโอเพ่นซอร์ส คุณสามารถค้นหาพื้นที่เก็บข้อมูลได้ที่นี่


