แบบสำรวจ AGI ที่ยอดเยี่ยม
เอกสารที่ต้องอ่านเกี่ยวกับปัญญาประดิษฐ์ทั่วไป

- ข่าว
- [2024-10] ? เอกสารของเราได้รับการยอมรับโดย TMLR 2024
- [2024-05] ? เรากำลังจัดเวิร์กช็อป AGI ที่ ICLR 2024 และได้เผยแพร่เอกสารแสดงจุดยืนของเรา "How Far Are We From AGI?"
โครงการของเราเป็นโครงการริเริ่มที่เปิดกว้างอย่างต่อเนื่อง ซึ่งจะพัฒนาควบคู่ไปกับความก้าวหน้าใน AGI เรายินดีรับข้อเสนอแนะและดึงคำขอจากชุมชนและวางแผนที่จะอัปเดตรายงานของเราเป็นประจำทุกปี ผู้ร่วมให้ข้อมูลบนเว็บไซต์ของโครงการจะได้รับการยอมรับอย่างสุดซึ้งในการแก้ไขครั้งต่อไป
การอ้างอิง BibTex หากคุณพบว่างาน/ทรัพยากรของเรามีประโยชน์:
@article { feng2024far ,
title = { How Far Are We From AGI } ,
author = { Feng, Tao and Jin, Chuanyang and Liu, Jingyu and Zhu, Kunlun and Tu, Haoqin and Cheng, Zirui and Lin, Guanyu and You, Jiaxuan } ,
journal = { arXiv preprint arXiv:2405.10313 } ,
year = { 2024 }
} เนื้อหา
- เนื้อหา
- 1. บทนำ
- 2. AGI Internal: เผยจิตใจของ AGI
- 2.1 การรับรู้ของเอไอ
- 2.2 การใช้เหตุผลของ AI
- 2.3 หน่วยความจำเอไอ
- 2.4 อภิปัญญาของ AI
- 3. อินเทอร์เฟซ AGI: เชื่อมโยงโลกด้วย AGI
- 3.1 อินเทอร์เฟซ AI สู่โลกดิจิทัล
- 3.2 อินเทอร์เฟซ AI สู่โลกทางกายภาพ
- 3.3 อินเทอร์เฟซ AI สู่ระบบอัจฉริยะ
- 3.3.1 อินเทอร์เฟซ AI กับตัวแทน AI
- 3.3.2 อินเทอร์เฟซ AI กับมนุษย์
- 4. ระบบ AGI: การใช้กลไกของ AGI
- 4.2 สถาปัตยกรรมแบบจำลองที่ปรับขนาดได้
- 4.3 การฝึกอบรมขนาดใหญ่
- 4.4 เทคนิคการอนุมาน
- 4.5 ต้นทุนและประสิทธิภาพ
- 4.6 แพลตฟอร์มคอมพิวเตอร์
- 5. การจัดตำแหน่ง AGI: รับประกันว่า AGI ตอบสนองความต้องการที่หลากหลาย
- 5.1 ความคาดหวังของการจัดตำแหน่ง AGI
- 5.2 เทคนิคการจัดตำแหน่งปัจจุบัน
- 5.3 วิธีการเข้าถึง AGI Alignments
- 6. แผนงาน AGI: การเข้าถึง AGI อย่างมีความรับผิดชอบ
- 6.1 ระดับ AI: แผนภูมิวิวัฒนาการของปัญญาประดิษฐ์
- 6.2 การประเมิน AGI
- 6.2.1 ความคาดหวังสำหรับการประเมิน AGI
- 6.2.2 การประเมินปัจจุบันและข้อจำกัด
- 6.5 ข้อควรพิจารณาเพิ่มเติมระหว่างการพัฒนา AGI
- 7. กรณีศึกษา
- 7.1 AI เพื่อการค้นพบและการวิจัยทางวิทยาศาสตร์
- 7.2 ความฉลาดทางการมองเห็นเชิงสร้างสรรค์
- 7.3 โมเดลโลก
- 7.4 LLM แบบกระจายอำนาจ
- 7.5 AI สำหรับการเข้ารหัส
- 7.6 AI สำหรับวิทยาการหุ่นยนต์ในการใช้งานจริง
- 7.7 การทำงานร่วมกันระหว่างมนุษย์และ AI
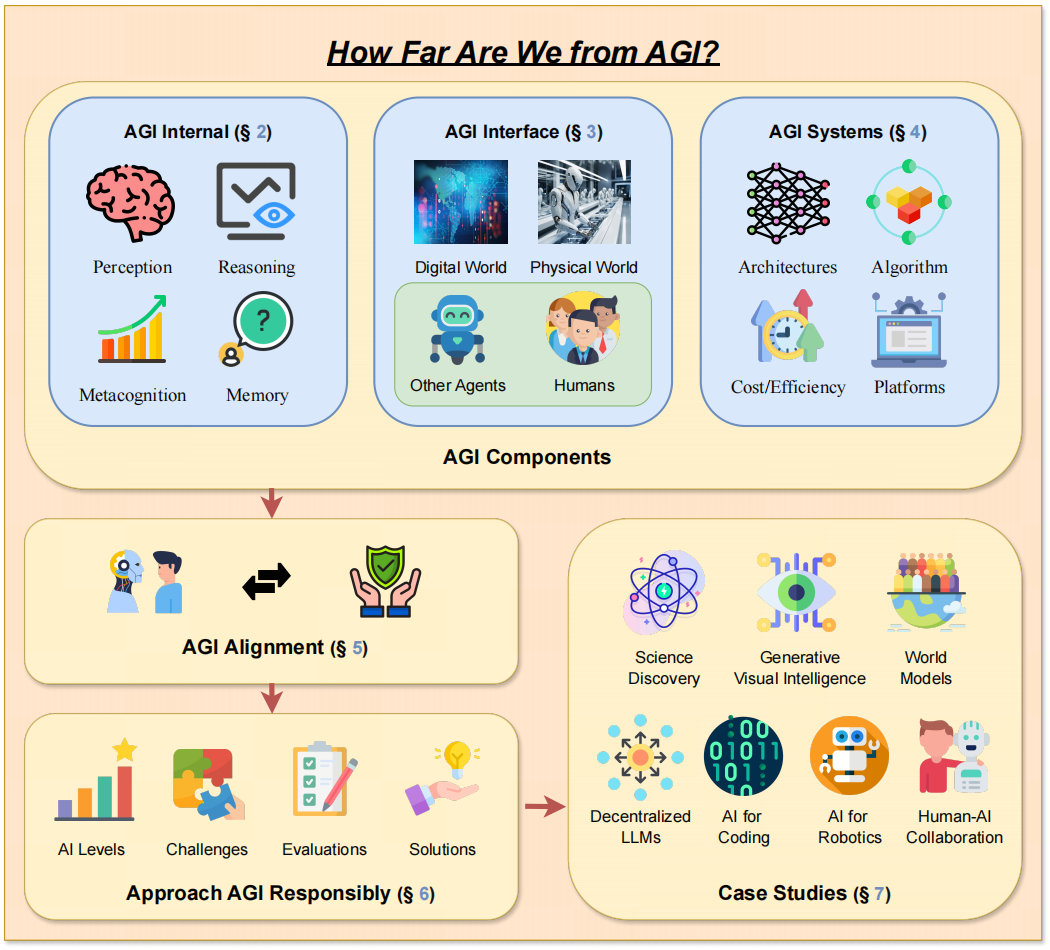
-> การออกแบบกรอบงานของกระดาษของเรา -
1. บทนำ
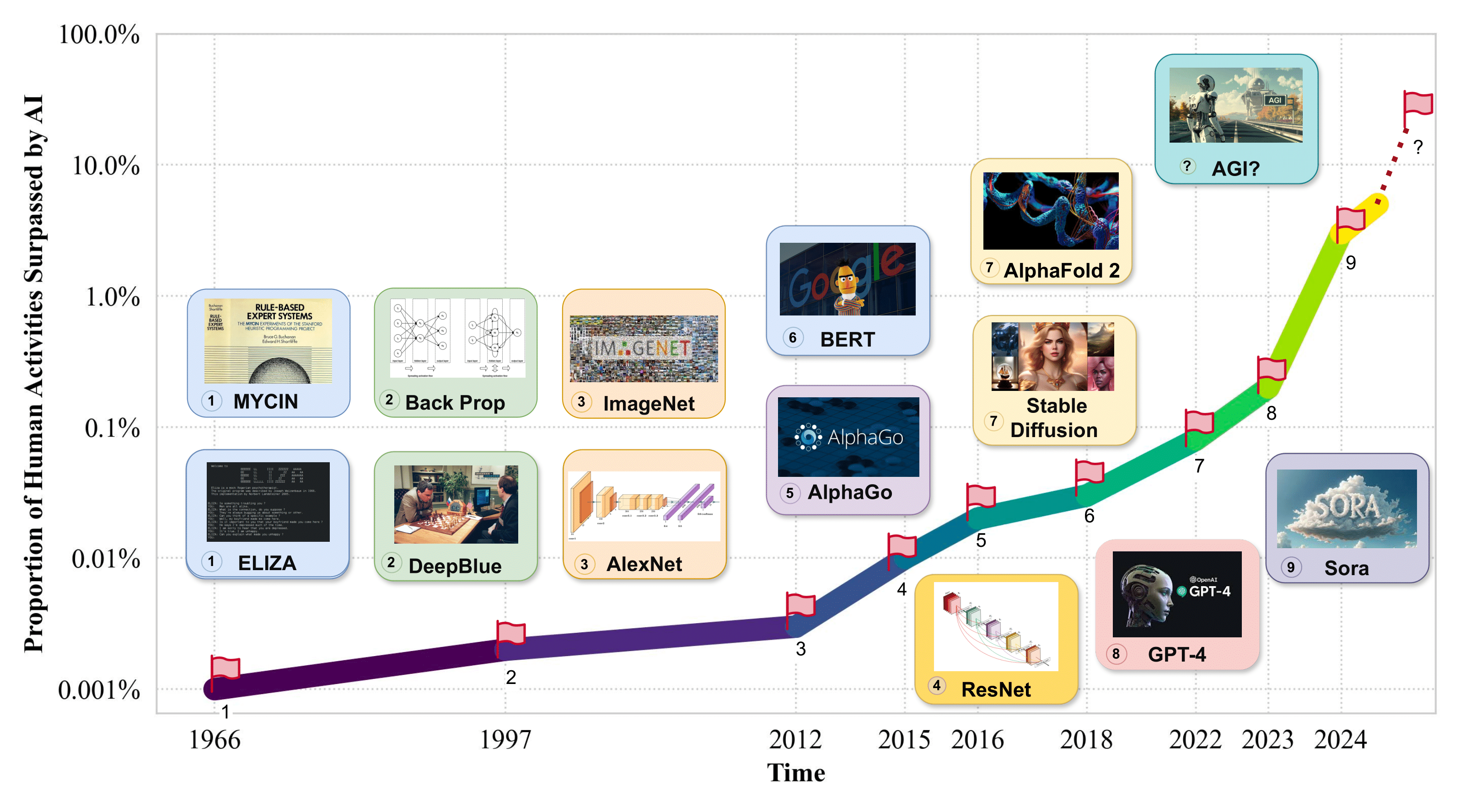
-> สัดส่วนของกิจกรรมของมนุษย์แซงหน้าโดย AI -
2. AGI Internal: เผยจิตใจของ AGI
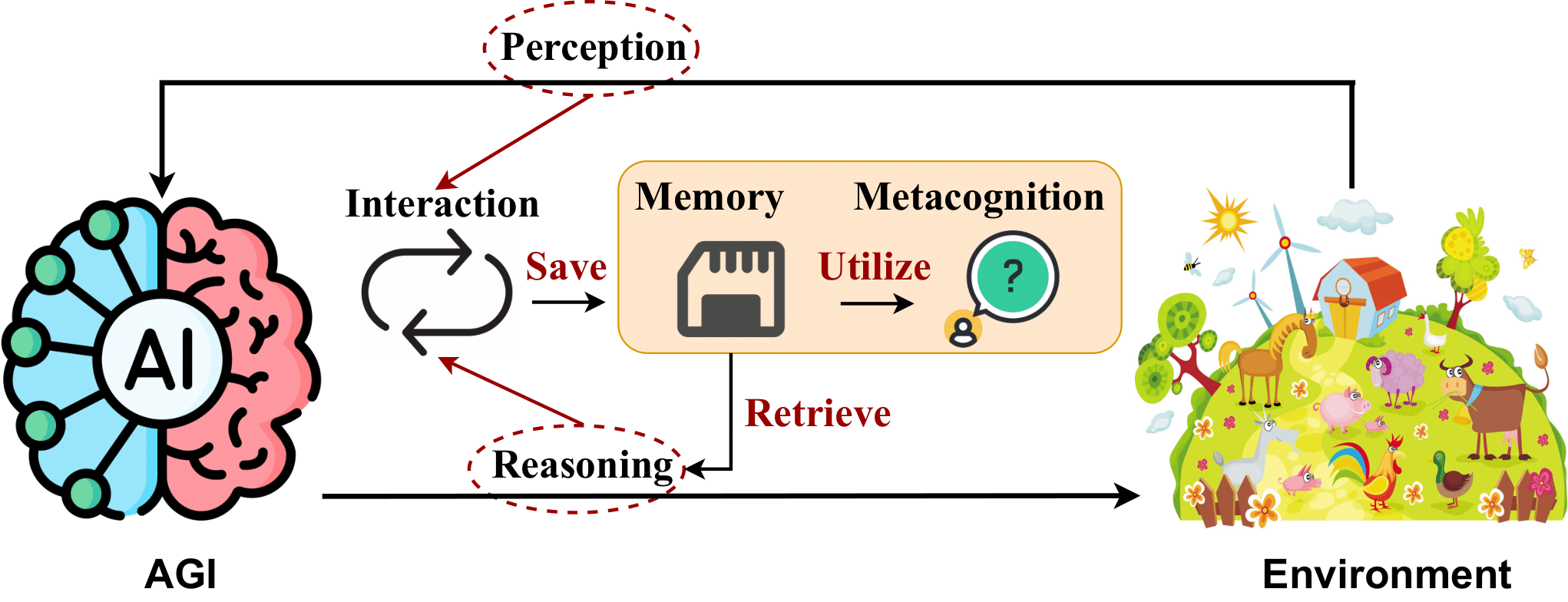

2.1 การรับรู้ของเอไอ
- นกฟลามิงโก: โมเดลภาษาภาพสำหรับการเรียนรู้แบบ Few-Shot ฌอง-บัปติสต์ อาลายัค และคณะ NeuroIPS 2022. [กระดาษ]
- BLIP-2: การฝึกอบรมล่วงหน้าภาษา - รูปภาพด้วย Bootstrapping ด้วยตัวเข้ารหัสรูปภาพแช่แข็งและโมเดลภาษาขนาดใหญ่ จุนหนาน ลี และคณะ ICML 2023. [กระดาษ]
- SPHINX: การผสมผสานระหว่างน้ำหนัก งาน และการฝังภาพสำหรับโมเดลภาษาขนาดใหญ่แบบหลายกิริยา ซียี่ หลิน และคณะ EMNLP 2023. [กระดาษ]
- การปรับแต่งคำสั่งด้วยภาพ ห่าวเทียน หลิว และคณะ NeuroIPS 2023. [กระดาษ]
- GPT4Tools: การสอนโมเดลภาษาขนาดใหญ่โดยใช้เครื่องมือผ่านการสอนด้วยตนเอง รุยหยาง และคณะ NeuroIPS 2023. [กระดาษ]
- Otter: โมเดลหลายรูปแบบพร้อมการปรับแต่งคำสั่งในบริบท โบ ลี่ และคณะ arXiv 2023. [กระดาษ]
- VideoChat: ความเข้าใจเกี่ยวกับวิดีโอที่เน้นการแชท คุนชาง ลี และคณะ arXiv 2023. [กระดาษ]
- mPLUG-Owl: การทำให้เป็นโมดูลช่วยเพิ่มพลังให้กับโมเดลภาษาขนาดใหญ่พร้อมความหลากหลาย ชิงห่าวเย่ และคณะ arXiv 2023. [กระดาษ]
- การสํารวจตัวแบบภาษาขนาดใหญ่หลายรูปแบบ ชูคัง หยิน และคณะ arXiv 2023. [กระดาษ]
- PandaGPT: รูปแบบเดียวในการสอน-ปฏิบัติตามทั้งหมด ยี่ซวน ซู และคณะ arXiv 2023. [กระดาษ]
- LLaMA-Adapter: การปรับแต่งโมเดลภาษาอย่างละเอียดอย่างมีประสิทธิภาพพร้อม Zero-init Attention เหรินรุย จาง และคณะ arXiv 2023. [กระดาษ]
- ราศีเมถุน: ตระกูลโมเดลต่อเนื่องหลายรูปแบบที่มีความสามารถสูง โรฮาน อานิล และคณะ arXiv 2023. [กระดาษ]
- Shikra: ปลดปล่อยเวทมนตร์บทสนทนาอ้างอิงของ Multimodal LLM เค่อชิน เฉิน และคณะ arXiv 2023. [กระดาษ]
- ImageBind: หนึ่งพื้นที่ฝังเพื่อผูกทั้งหมด โรหิต เกิร์ดฮาร์ และคณะ CVPR 2023. [กระดาษ]
- MobileVLM: ตัวช่วยภาษาการมองเห็นที่รวดเร็ว แข็งแกร่ง และเปิดกว้างสำหรับอุปกรณ์มือถือ เซียงเซียง ชู และคณะ arXiv 2023. [กระดาษ]
- อะไรทำให้ Visual Tokenizers ที่ดีสำหรับโมเดลภาษาขนาดใหญ่ - กว่างซี หวัง และคณะ arXiv 2023. [กระดาษ]
- MiniGPT-4: ปรับปรุงความเข้าใจภาษาการมองเห็นด้วยโมเดลภาษาขนาดใหญ่ขั้นสูง Deyao Zhu และคณะ ICLR 2024. [กระดาษ]
- LanguageBind: การขยายการฝึกอบรมภาษาวิดีโอล่วงหน้าไปสู่รูปแบบ N โดยการจัดตำแหน่งความหมายตามภาษา บินจู้ และคณะ ICLR 2024. [กระดาษ]
2.2 การใช้เหตุผลของ AI
- การกระตุ้นเตือนแบบลูกโซ่ทำให้เกิดการใช้เหตุผลในแบบจำลองภาษาขนาดใหญ่ เจสัน เหว่ย และคณะ NeuroIPS 2022. [กระดาษ]
- ทฤษฎีประสาทแห่งจิตใจ? เกี่ยวกับขีดจำกัดของความฉลาดทางสังคมใน LM ขนาดใหญ่ มาร์เทน ทรัพย์ และคณะ EMNLP 2022. [กระดาษ]
- บทพูดภายใน: การใช้เหตุผลเป็นตัวเป็นตนผ่านการวางแผนด้วยแบบจำลองภาษา เหวินหลง หวง และคณะ CoRL 2022. [กระดาษ]
- การสํารวจภาพหลอนในการสร้างภาษาธรรมชาติ Ziwei Ji และคณะ แบบสำรวจคอมพิวเตอร์ ACM ปี 2022 [กระดาษ]
- ReAct: การประสานการใช้เหตุผลและการแสดงในรูปแบบภาษา ชุนยู่ เหยา และคณะ ICLR 2023. [กระดาษ]
- Decomposed Prompting: แนวทางแบบแยกส่วนสำหรับการแก้ปัญหางานที่ซับซ้อน ทูชาร์ ค็อต และคณะ ICLR 2023. [กระดาษ]
- การแจ้งตามความซับซ้อนสำหรับการให้เหตุผลแบบหลายขั้นตอน เหยาฟู่ และคณะ ICLR 2023. [กระดาษ]
- การแจ้งน้อยที่สุดไปมากที่สุดช่วยให้สามารถใช้เหตุผลที่ซับซ้อนในแบบจำลองภาษาขนาดใหญ่ เดนนี่ โจว และคณะ ICLR 2023. [กระดาษ]
- สู่การใช้เหตุผลในรูปแบบภาษาขนาดใหญ่: แบบสำรวจ . เจียฮวง และคณะ ผลการวิจัยของ ACL ปี 2023 [กระดาษ]
- ProgPrompt: การสร้างแผนงานหุ่นยนต์ที่ตั้งไว้โดยใช้โมเดลภาษาขนาดใหญ่ อิชิกา ซิงห์ และคณะ ICRA 2023. [กระดาษ]
- การใช้เหตุผลด้วยโมเดลภาษาคือการวางแผนด้วยโมเดลโลก ชิโบ เฮา และคณะ EMNLP 2023. [กระดาษ]
- การประเมินอาการประสาทหลอนของวัตถุในแบบจำลองภาษาการมองเห็นขนาดใหญ่ ยี่ฟาน ลี และคณะ EMNLP 2023. [กระดาษ]
- ต้นไม้แห่งความคิด: การแก้ปัญหาโดยเจตนาด้วยแบบจำลองภาษาขนาดใหญ่ ชุนยู่ เหยา และคณะ NeuroIPS 2023. [กระดาษ]
- การปรับแต่งตนเอง: การปรับแต่งซ้ำพร้อมการตอบรับด้วยตนเอง อามาน มาดาน และคณะ NeuroIPS 2023. [กระดาษ]
- การสะท้อนกลับ: ตัวแทนภาษาพร้อมการเรียนรู้การเสริมกำลังด้วยวาจา โนอาห์ ชินน์ และคณะ NeuroIPS 2023. [กระดาษ]
- อธิบาย อธิบาย วางแผน และเลือก: การวางแผนเชิงโต้ตอบด้วยโมเดลภาษาขนาดใหญ่ช่วยให้ตัวแทนทำงานหลายอย่างในโลกเปิดได้ Zihao Wang และคณะ NeuroIPS 2023. [กระดาษ]
- LLM+P: เสริมศักยภาพโมเดลภาษาขนาดใหญ่ด้วยความสามารถในการวางแผนที่เหมาะสมที่สุด บ่อหลิว และคณะ arXiv 2023. [กระดาษ]
- โมเดลภาษา โมเดลเอเจนต์ และโมเดลโลก: กฎหมายสำหรับการให้เหตุผลและการวางแผนเครื่องจักร จื้อถิง หู และคณะ arXiv 2023. [กระดาษ]
- MMToM-QA: ทฤษฎีหลายรูปแบบของการตอบคำถามในใจ ชวนหยาง จิน และคณะ arXiv 2024. [กระดาษ]
- กราฟแห่งความคิด: การแก้ปัญหาที่ซับซ้อนด้วยแบบจำลองภาษาขนาดใหญ่ Maciej Besta และคณะ AAAI 2024. [กระดาษ]
- บรรลุ >97% บน GSM8K: การเข้าใจปัญหาอย่างลึกซึ้งทำให้ LLM เป็นนักหาเหตุผลที่สมบูรณ์แบบ ฉีหวง จง และคณะ arXiv 2024 [กระดาษ] อยู่ระหว่างการพิจารณา
2.3 หน่วยความจำเอไอ
- การเรียกค้นข้อความหนาแน่นสำหรับการตอบคำถามแบบเปิดโดเมน วลาดิมีร์ คาร์ปูคิน และคณะ EMNLP 2020. [กระดาษ]
- การสร้างเสริมการดึงข้อมูลสำหรับงาน NLP ที่เน้นความรู้ แพทริค ลูอิส และคณะ NeuroIPS 2020. [กระดาษ]
- REALM: การฝึกอบรมล่วงหน้าแบบจำลองภาษาแบบดึงข้อมูล-Augmented เคลวิน กู และคณะ ICML 2020. [กระดาษ]
- การดึงข้อมูลเสริมช่วยลดอาการประสาทหลอนในการสนทนา เคิร์ต ชูสเตอร์ และคณะ ผลการวิจัยของ EMNLP ปี 2021 [กระดาษ]
- การปรับปรุงโมเดลภาษาโดยการดึงข้อมูลจากโทเค็นนับล้านล้าน เซบาสเตียน บอร์โกด์ และคณะ ICML 2022. [กระดาษ]
- ตัวแทนกำเนิด: Simulacra แบบโต้ตอบของพฤติกรรมมนุษย์ ปาร์ค จุนซอง และคณะ UIST 2023. [กระดาษ]
- สถาปัตยกรรมทางปัญญาสำหรับตัวแทนภาษา ธีโอดอร์ อาร์. ซูเมอร์ส และคณะ TMLR 2024. [กระดาษ]
- โวเอเจอร์: เอเจนต์ปลายเปิดที่มีโมเดลภาษาขนาดใหญ่ กวนซี หวัง และคณะ arXiv 2023. [กระดาษ]
- การ สำรวจ กลไก หน่วยความจำ ของ เอเจนต์ ที่ใช้ โมเดล ภาษา ขนาดใหญ่ เจ๋อหยู จาง และคณะ arXiv 2024. [กระดาษ]
- การสรุปแบบเรียกซ้ำช่วยให้หน่วยความจำการสนทนาระยะยาวในโมเดลภาษาขนาดใหญ่ ชิงเยว่หวาง และคณะ arXiv 2023 [กระดาษ] อยู่ระหว่างการพิจารณา
2.4 อภิปัญญาของ AI
- การพิจารณาความสามารถเมตาในการถ่ายทอดความรู้ภายนอกและการเรียนรู้เชิงองค์กร Jyoti Choudrie และคณะ HICSS 2549. [กระดาษ]
- การพัฒนาโครงข่ายประสาทเทียมที่ดูแลตนเอง ความฉลาดอิสระจากการพัฒนาการสอนด้วยตนเอง น้ำ เล่ . arXiv 2019. [กระดาษ]
- ทำให้โมเดลภาษาที่ได้รับการฝึกล่วงหน้าดีขึ้นสำหรับผู้เรียนเพียงไม่กี่คน เทียนหยู่ เกา และคณะ ACL 2021. [กระดาษ]
- การระบุและการจัดการลักษณะบุคลิกภาพของตัวแบบภาษา เกรแฮม คารอน และคณะ arXiv 2022. [กระดาษ]
- ฉลาด: การทำให้ภาษาหลายรูปแบบเป็นทางการเพื่อความฉลาดและจิตสำนึก พอล เหลียง และคณะ arXiv 2022. [กระดาษ]
- ทฤษฎีจิตสำนึกจากมุมมองของวิทยาการคอมพิวเตอร์เชิงทฤษฎี: ข้อมูลเชิงลึกจาก Conscious Turing Machine เลนอร์ บลัม และคณะ PNAS 2022. [กระดาษ]
- WizardLM: เพิ่มศักยภาพให้กับโมเดลภาษาขนาดใหญ่เพื่อปฏิบัติตามคำสั่งที่ซับซ้อน Can Xu และคณะ arXiv 2023. [กระดาษ]
- การสอนด้วยตนเอง: การจัดรูปแบบภาษาให้สอดคล้องกับคำแนะนำที่สร้างขึ้นเอง ยี่จง หวัง และคณะ ACL 2023. [กระดาษ]
- ReST ตรงตาม ReAct: การพัฒนาตนเองสำหรับตัวแทน LLM การใช้เหตุผลแบบหลายขั้นตอน เรนาต อัคซิตอฟ และคณะ arXiv 2023. [กระดาษ]
- จิตวิทยาวัฒนธรรมของแบบจำลองภาษาขนาดใหญ่: ChatGPT เป็นนักคิดแบบองค์รวมหรือเชิงวิเคราะห์หรือไม่ - ชวนหยาง จิน และคณะ arXiv 2023. [กระดาษ]
- จิตสำนึกในปัญญาประดิษฐ์: ข้อมูลเชิงลึกจากศาสตร์แห่งจิตสำนึก แพทริค บัตลิน และคณะ arXiv 2023. [กระดาษ]
- ทบทวนความน่าเชื่อถือของมาตราส่วนทางจิตวิทยาในแบบจำลองภาษาขนาดใหญ่ เจ็นซี หวง และคณะ arXiv 2023. [กระดาษ]
- การประเมินและกระตุ้นบุคลิกภาพในแบบจำลองภาษาที่ผ่านการฝึกอบรมมาแล้ว กวงหยวน เจียง และคณะ NeuroIPS 2024. [กระดาษ]
- ระดับของ AGI: ความก้าวหน้าในการปฏิบัติงานบนเส้นทางสู่ AGI เมเรดิธ ริงเกล มอร์ริส และคณะ arXiv 2024 [กระดาษ] อยู่ระหว่างการพิจารณา
- สำรวจ-รวมกลุ่ม-หาประโยชน์: กลยุทธ์ทั่วไปสำหรับการพัฒนาตนเองของตัวแทนระหว่างงาน เฉิงเฉียน และคณะ arXiv 2024 [กระดาษ] อยู่ระหว่างการพิจารณา
3. อินเทอร์เฟซ AGI: เชื่อมโยงโลกด้วย AGI

3.1 อินเทอร์เฟซ AI สู่โลกดิจิทัล
- หลักการของส่วนติดต่อผู้ใช้แบบความคิดริเริ่มแบบผสมผสาน เอริก ฮอร์วิทซ์. SIGCHI 1999. [กระดาษ]
- การเพิ่มขึ้นและศักยภาพของตัวแทนที่ใช้แบบจำลองภาษาขนาดใหญ่: การสำรวจ จือเหิง ซี และคณะ arXiv 2023. [กระดาษ]
- การเรียนรู้เครื่องมือด้วยแบบจำลองพื้นฐาน หยูเจีย ฉิน และคณะ arXiv 2023. [กระดาษ]
- ผู้สร้าง: การแยกเหตุผลเชิงนามธรรมและเป็นรูปธรรมของแบบจำลองภาษาขนาดใหญ่ผ่านการสร้างเครื่องมือ เฉิงเฉียน และคณะ arXiv 2023. [กระดาษ]
- AppAgent: Multimodal Agent ในฐานะผู้ใช้สมาร์ทโฟน จ้าวหยาง และคณะ arXiv 2023. [กระดาษ]
- Mind2Web: สู่ตัวแทนทั่วไปสำหรับเว็บ เซียงเติ้ง และคณะ เกณฑ์มาตรฐาน NeuroIPS ปี 2023 [กระดาษ]
- ToolQA: ชุดข้อมูลสำหรับการตอบคำถาม LLM ด้วยเครื่องมือภายนอก หยูเฉินจ้วง และคณะ arXiv 2023. [กระดาษ]
- ตัวแทนกำเนิด: แบบจำลองเชิงโต้ตอบของพฤติกรรมมนุษย์ ปาร์ค จุนซอง และคณะ arXiv 2023. [กระดาษ]
- Toolformer: โมเดลภาษาสามารถสอนตัวเองให้ใช้เครื่องมือได้ ทิโม ชิค และคณะ arXiv 2023. [กระดาษ]
- Gorilla: โมเดลภาษาขนาดใหญ่ที่เชื่อมต่อกับ Massive API ชิชีร์ จี ปาติล และคณะ arXiv 2023. [กระดาษ]
- โวเอเจอร์: เอเจนต์ปลายเปิดที่มีโมเดลภาษาขนาดใหญ่ กวนซี หวัง และคณะ arXiv 2023. [กระดาษ]
- OS-Copilot: สู่ตัวแทนคอมพิวเตอร์ทั่วไปที่มีการพัฒนาตนเอง จือหยง หวู่ และคณะ arXiv 2024. [กระดาษ]
- WebArena: สภาพแวดล้อมเว็บที่สมจริงสำหรับการสร้างตัวแทนอัตโนมัติ ซูหยานโจว และคณะ ICLR 2024. [กระดาษ]
- โมเดลภาษาขนาดใหญ่ในฐานะผู้สร้างเครื่องมือ เถียนเล่อ Cai และคณะ ICLR 2024. [กระดาษ]
3.2 อินเทอร์เฟซ AI สู่โลกทางกายภาพ
- บทเรียนจากความท้าทายในการเลือกอเมซอน: สี่แง่มุมของการสร้างระบบหุ่นยนต์ คลีเมนส์ เอปป์เนอร์ และคณะ RSS 2559. [กระดาษ]
- ผู้รับรู้-นักแสดง: หม้อแปลงหลายงานสำหรับการจัดการหุ่นยนต์ โมหิต ศรีดาร์ และคณะ arXiv 2022. [กระดาษ]
- Vima: การจัดการหุ่นยนต์ทั่วไปพร้อมคำสั่งหลายรูปแบบ หยุนฟาน เจียง และคณะ arXiv 2022. [กระดาษ]
- ทำเท่าที่ฉันทำได้ ไม่ใช่อย่างที่ฉันพูด: การใช้ภาษาแบบพื้นฐานในราคาที่เอื้อมถึงของหุ่นยนต์ ไมเคิล อัน และคณะ arXiv 2022. [กระดาษ]
- Voxposer: แผนที่ค่า 3 มิติที่ประกอบได้สำหรับการจัดการหุ่นยนต์ด้วยโมเดลภาษา เหวินหลง หวง และคณะ arXiv 2023. [กระดาษ]
- MotionGPT: การเคลื่อนไหวของมนุษย์เป็นภาษาต่างประเทศ เปียว เจียง และคณะ arXiv 2023. [กระดาษ]
- Rt-2: โมเดลการมองเห็น-ภาษา-การกระทำจะถ่ายทอดความรู้ทางเว็บไปยังการควบคุมด้วยหุ่นยนต์ แอนโทนี่ โบรฮาน และคณะ arXiv 2023. [กระดาษ]
- การนำทางไปยังวัตถุในโลกแห่งความเป็นจริง ธีโอฟิล เกอร์เวต และคณะ วิทยาการหุ่นยนต์ 2566. [กระดาษ]
- Lm-nav: การนำทางด้วยหุ่นยนต์พร้อมโมเดลภาษา การมองเห็น และการกระทำขนาดใหญ่ที่ได้รับการฝึกอบรมล่วงหน้ามาแล้ว ดรูฟ ชาห์ และคณะ CRL 2023. [กระดาษ]
- Palm-e: แบบจำลองภาษาหลากรูปแบบที่เป็นตัวเป็นตน แดนนี่ ดรายส์ และคณะ arXiv 2023. [กระดาษ]
- LLM-Planner: การวางแผนที่มีเหตุผลไม่กี่ครั้งสำหรับตัวแทนที่เป็นตัวเป็นตนซึ่งมีโมเดลภาษาขนาดใหญ่ ชานฮีซอง และคณะ ICCV 2023. [กระดาษ]
- Instruct2Act: การแมปคำสั่งหลายรูปแบบกับการกระทำของหุ่นยนต์ด้วยโมเดลภาษาขนาดใหญ่ ซือหยวน หวง และคณะ arXiv 2023. [กระดาษ]
- DROID: ชุดข้อมูลการจัดการหุ่นยนต์ในป่าขนาดใหญ่ อเล็กซานเดอร์ คาซัตสกี้ และคณะ arXiv 2024. [กระดาษ]
- BEHAVIOR-1K: เกณฑ์มาตรฐาน AI ที่เน้นมนุษย์เป็นศูนย์กลาง พร้อมด้วยกิจกรรม 1,000 กิจกรรมในชีวิตประจำวันและการจำลองที่สมจริง เฉิงซู ลี และคณะ arXiv 2024. [กระดาษ]
3.3 อินเทอร์เฟซ AI สู่ระบบอัจฉริยะ
3.3.1 อินเทอร์เฟซ AI กับตัวแทน AI
- การไล่ระดับนโยบายหลายตัวแทนที่ขัดแย้งกับความเป็นจริง เจคอบ ฟอร์สเตอร์ และคณะ AAAI 2018. [กระดาษ]
- คำอธิบายจากแบบจำลองภาษาขนาดใหญ่ทำให้ผู้ให้เหตุผลเพียงเล็กน้อยดีขึ้น ซือหยาง ลี และคณะ arXiv 2022. [กระดาษ]
- การกลั่นกรองการเรียนรู้ในบริบท: การถ่ายโอนความสามารถในการเรียนรู้เพียงไม่กี่ช็อตของโมเดลภาษาที่ได้รับการฝึกอบรมล่วงหน้า หยูคุน ฮวง และคณะ arXiv 2022. [กระดาษ]
- Autoagents: กรอบงานสำหรับการสร้างตัวแทนอัตโนมัติ กวงเหยา เฉิน และคณะ arXiv 2023. [กระดาษ]
- การอนุมานแบบตัดจำหน่ายทางประสาทสำหรับการให้เหตุผลหลายตัวแทนแบบซ้อน คุณกุล จา และคณะ arXiv 2023. [กระดาษ]
- การกลั่นกรองความรู้ของแบบจำลองภาษาขนาดใหญ่ หยูเซียน กู่ และคณะ arXiv 2023. [กระดาษ]
- Metagpt: การเขียนโปรแกรม Meta สำหรับกรอบการทำงานร่วมกันหลายตัวแทน สิรุ่ยหง และคณะ arXiv 2023. [กระดาษ]
- อธิบาย อธิบาย วางแผน และเลือก: การวางแผนเชิงโต้ตอบด้วยแบบจำลองภาษาขนาดใหญ่ช่วยให้ตัวแทนทำงานหลายอย่างในโลกเปิดได้ Zihao Wang และคณะ arXiv 2023. [กระดาษ]
- Agentverse: อำนวยความสะดวกในการทำงานร่วมกันหลายตัวแทนและสำรวจพฤติกรรมที่เกิดขึ้นในตัวแทน Weize Chen และคณะ arXiv 2023. [กระดาษ]
- พายุความคิดในสังคมแห่งจิตใจที่ใช้ภาษาธรรมชาติ หมิงเฉิน จูกัด และคณะ arXiv 2023. [กระดาษ]
- Jarvis-1: เอเจนต์มัลติทาสก์แบบเปิดโลกพร้อมโมเดลภาษาหลากรูปแบบที่เสริมหน่วยความจำ Zihao Wang และคณะ arXiv 2023. [กระดาษ]
- การกลั่นกรองห่วงโซ่แห่งความคิดเชิงสัญลักษณ์: โมเดลขนาดเล็กสามารถ "คิด" ทีละขั้นตอนได้เช่นกัน หลิวเนียน ฮาโรลด์ ลี และคณะ ACL 2023. [กระดาษ]
- กลั่นทีละขั้นตอน! มีประสิทธิภาพเหนือกว่าโมเดลภาษาที่ใหญ่กว่าด้วยข้อมูลการฝึกที่น้อยกว่าและขนาดโมเดลที่เล็กกว่า Cheng-Yu Hsieh และคณะ arXiv 2023. [กระดาษ]
- ภาพรวมจากอ่อนแอไปแข็งแกร่ง: ดึงเอาความสามารถที่แข็งแกร่งด้วยการกำกับดูแลที่อ่อนแอ คอลลิน เบิร์นส์ และคณะ arXiv 2023. [กระดาษ]
- ปรับปรุงโมเดลภาษาแชทโดยปรับขนาดการสนทนาการเรียนการสอนคุณภาพสูง หนิงติง และคณะ arXiv 2023. [กระดาษ]
- GAIA: เกณฑ์มาตรฐานสำหรับผู้ช่วย AI ทั่วไป เกรกัวร์ มิอาลอน และคณะ ICLR 2024. [กระดาษ]
- โวเอเจอร์: เอเจนต์ปลายเปิดที่มีโมเดลภาษาขนาดใหญ่ กวนซี หวัง และคณะ arXiv 2023. [กระดาษ]
- อูฐ: ตัวแทนการสื่อสารสำหรับการสำรวจ "จิตใจ" ของสังคมต้นแบบภาษาขนาดใหญ่ Guohao Li และคณะ arXiv 2023. [กระดาษ]
- การปรับแต่งการหาเหตุผลเข้าข้างตนเองด้วยตนเองด้วยการกลั่นแบบหลายรางวัล สฮานา รามนาถ และคณะ arXiv 2023. [กระดาษ]
- Vision Superalignment: ภาพรวมที่อ่อนแอถึงแข็งแกร่งสำหรับโมเดล Foundation Vision Jianyuan Guo และคณะ arXiv 2024. [กระดาษ]
- WebArena: สภาพแวดล้อมเว็บที่สมจริงสำหรับการสร้างตัวแทนอัตโนมัติ ซูหยานโจว และคณะ ICLR 2024. [กระดาษ]
- การจัดตำแหน่งโมเดลภาษาด้วยตนเองตามหลักการตั้งแต่เริ่มต้นโดยมีการควบคุมดูแลโดยมนุษย์น้อยที่สุด จือชิง ซัน และคณะ NeuroIPS 2024. [กระดาษ]
- Mind2web: สู่ตัวแทนทั่วไปของเว็บ เซียงเติ้ง และคณะ NeuroIPS 2024. [กระดาษ]
- สู่การควบคุมคอมพิวเตอร์ทั่วไป: ตัวแทนต่อเนื่องหลายรูปแบบสำหรับการไถ่ถอน Red Dead II เป็นกรณีศึกษา เวยเฮา ตัน และคณะ arXiv 2024. [กระดาษ]
3.3.2 อินเทอร์เฟซ AI กับมนุษย์
- แนวทางปฏิสัมพันธ์ระหว่างมนุษย์กับ AI ซาลีมา อเมอร์ชี และคณะ CHI 2019. [กระดาษ]
- หลักการออกแบบสำหรับแอปพลิเคชัน Generative AI จัสติน ดี. ไวสซ์ และคณะ ชิ 2024. [กระดาษ]
- Graphologue: การสำรวจการตอบสนองของโมเดลภาษาขนาดใหญ่ด้วยไดอะแกรมเชิงโต้ตอบ Peiling Jiang และคณะ UIST 2023. [กระดาษ]
- Sensecape: เปิดใช้งานการสำรวจและการสร้างความรู้สึกหลายระดับด้วยโมเดลภาษาขนาดใหญ่ สังโฆ ซูห์ และคณะ UIST 2023. [กระดาษ]
- รองรับการสร้างความรู้สึกของเอาท์พุตโมเดลภาษาขนาดใหญ่ในวงกว้าง Katy Ilonka Gero และคณะ ชิ 2024. [กระดาษ]
- Luminate: การสร้างโครงสร้างและการสำรวจพื้นที่การออกแบบด้วยแบบจำลองภาษาขนาดใหญ่สำหรับการสร้างสรรค์ร่วมกันระหว่างมนุษย์และ AI สังโฆ ซูห์ และคณะ ชิ 2024. [กระดาษ]
- AI Chains: ปฏิสัมพันธ์ระหว่างมนุษย์กับ AI ที่โปร่งใสและควบคุมได้ โดยการเชื่อมโยงคำสั่งโมเดลภาษาขนาดใหญ่ ตงซวง วู และคณะ ชิ 2022. [กระดาษ]
- พร้อมท์: การสร้างข้อความเป็นรูปภาพผ่านการสำรวจพร้อมท์แบบโต้ตอบด้วยโมเดลภาษาขนาดใหญ่ สตีเฟน เบรด และคณะ ชิ 2023. [กระดาษ]
- ChainForge: ชุดเครื่องมือแบบภาพสำหรับการทดสอบสมมติฐานทางวิศวกรรมและ LLM แบบทันที เอียน อาราวโจ และคณะ ชิ 2024. [กระดาษ]
- CoPrompt: สนับสนุนการแบ่งปันอย่างรวดเร็วและการอ้างอิงในการเขียนโปรแกรมภาษาธรรมชาติที่ทำงานร่วมกัน หลี่เฟิง และคณะ ชิ 2024. [กระดาษ]
- การสร้างคำติชมอัตโนมัติเกี่ยวกับการจำลอง UI ด้วยโมเดลภาษาขนาดใหญ่ เป่ยตงเดือน และคณะ ชิ 2024. [กระดาษ]
- Rambler: รองรับการเขียนด้วยคำพูดผ่าน LLM-Assisted Gist Manipulation ซูซาน ลิน และคณะ ชิ 2024. [กระดาษ]
- การฝังโมเดลภาษาขนาดใหญ่เข้ากับความเป็นจริงที่ขยายออกไป: โอกาสและความท้าทายสำหรับการไม่แบ่งแยก การมีส่วนร่วม และความเป็นส่วนตัว เอเฟ โบซกีร์ และคณะ arXiv 2024. [กระดาษ]
- GenAssist: ทำให้การสร้างอิมเมจสามารถเข้าถึงได้ มีนา ฮะ และคณะ UIST 2023. [กระดาษ]
- “ยิ่งพิมพ์น้อยก็ยิ่งดี”: โมเดลภาษา AI สามารถปรับปรุงหรือขัดขวางการสื่อสารสำหรับผู้ใช้ AAC ได้อย่างไร สเตฟานี วาเลนเซีย และคณะ ชิ 2023. [กระดาษ]
- ตรวจสอบอีกครั้งว่าปฏิสัมพันธ์ระหว่างมนุษย์กับ AI นั้นยากต่อการออกแบบหรือไม่ เพราะเหตุใด และอย่างไร เคียน หยาง และคณะ CHI 2020. [กระดาษ]
4. ระบบ AGI: การใช้กลไกของ AGI
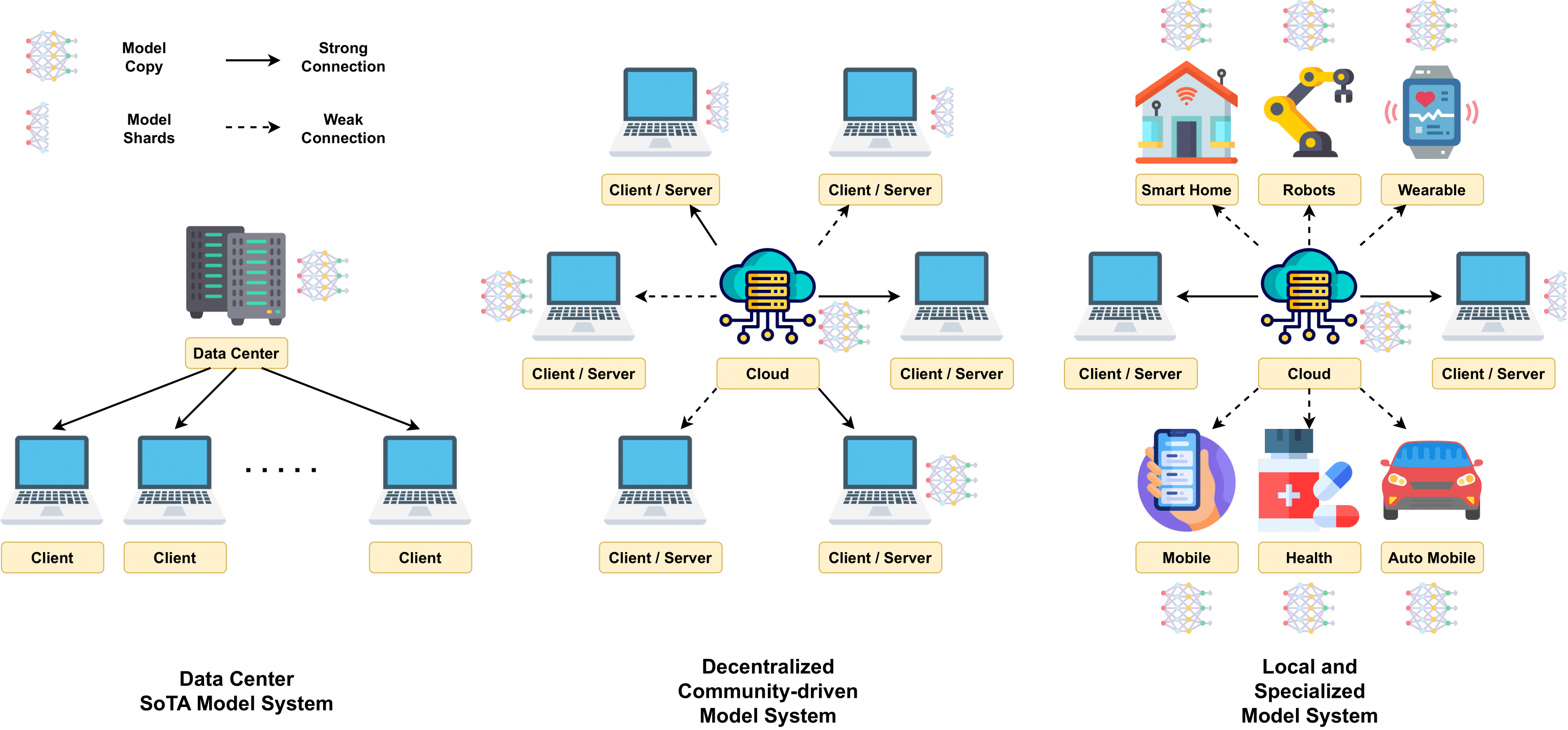

4.2 สถาปัตยกรรมแบบจำลองที่ปรับขนาดได้
- โครงข่ายประสาทเทียมขนาดใหญ่อย่างอุกอาจ: เลเยอร์ผสมของผู้เชี่ยวชาญที่มีรั้วรอบขอบชิด โนม ชาเซียร์ และคณะ arXiv 2017. [กระดาษ]
- หม้อแปลงคือ RNN: หม้อแปลงแบบถอยหลังอัตโนมัติที่รวดเร็วพร้อมความสนใจเชิงเส้น แองเจลอส คาธาโรปูลอส และคณะ arXiv 2020. [กระดาษ]
- Longformer: หม้อแปลงเอกสารขนาดยาว อิซ เบลทากี และคณะ arXiv 2020. [กระดาษ]
- LightSeq: ไลบรารีการอนุมานประสิทธิภาพสูงสำหรับ Transformers เสี่ยวฮุย หวัง และคณะ arXiv 2021. [กระดาษ]
- สลับหม้อแปลง: ปรับขนาดเป็นโมเดลพารามิเตอร์ล้านล้านด้วยความกระจัดกระจายที่ง่ายและมีประสิทธิภาพ วิลเลียม เฟดัส และคณะ arXiv 2022. [กระดาษ]
- การสร้างแบบจำลองลำดับยาวอย่างมีประสิทธิภาพด้วยช่องว่างสถานะที่มีโครงสร้าง อัลเบิร์ต กู และคณะ arXiv 2022. [กระดาษ]
- MegaBlocks: การฝึกอบรมเบาบางที่มีประสิทธิภาพพร้อมผู้เชี่ยวชาญที่หลากหลาย เทรเวอร์ เกล และคณะ arXiv 2022. [กระดาษ]
- การฝึกอบรมโมเดลภาษาขนาดใหญ่ที่เพิ่มประสิทธิภาพการประมวลผล จอร์แดน ฮอฟฟ์แมนน์ และคณะ arXiv 2022. [กระดาษ]
- การปรับขนาดบริบทแบบยาวที่มีประสิทธิภาพของแบบจำลองพื้นฐาน เหวินฮั่น ซีออง และคณะ arXiv 2023. [กระดาษ]
- ลำดับชั้นของหมาใน: สู่โมเดลภาษา Convolutional ที่ใหญ่ขึ้น ไมเคิล โปลิ และคณะ arXiv 2023. [กระดาษ]
- Stanford Alpaca: โมเดล LLaMA ที่ทำตามคำแนะนำ โรฮัน ทาโอรี และคณะ GitHub 2023 [รหัส]
- Rwkv: พลิกโฉม RNN สำหรับยุค Transformer . บ่อเป้ง และคณะ arXiv 2023. [กระดาษ]
- เดจา วู: ความกระจัดกระจายตามบริบทสำหรับ LLM ที่มีประสิทธิภาพในเวลาอนุมาน ซีชาง หลิว และคณะ arXiv 2023. [กระดาษ]
- Flash-LLM: ช่วยให้สามารถอนุมานแบบจำลองขนาดใหญ่ที่คุ้มค่าและมีประสิทธิภาพสูงพร้อมการกระจายตัวแบบไม่มีโครงสร้าง เฮาจุนเซี่ย และคณะ arXiv 2023. [กระดาษ]
- ByteTransformer: หม้อแปลงประสิทธิภาพสูงที่ได้รับการปรับปรุงสำหรับอินพุตความยาวแปรผัน หยูเจีย ไจ่ และคณะ arXiv 2023. [กระดาษ]
- Tutel: การผสมผสานที่ลงตัวของผู้เชี่ยวชาญตามขนาด ชางโฮ ฮวาง และคณะ arXiv 2023. [กระดาษ]
- Mamba: การสร้างแบบจำลองลำดับเวลาเชิงเส้นพร้อมช่องว่างสถานะแบบเลือก อัลเบิร์ต กู่ ตรีดาว. arXiv 2023. [กระดาษ]
- Hungry Hungry Hippos: สู่การสร้างแบบจำลองภาษาด้วยแบบจำลองอวกาศของรัฐ แดเนียล วาย. ฟู และคณะ arXiv 2023. [กระดาษ]
- Retentive Network: ผู้สืบทอดจาก Transformer สำหรับโมเดลภาษาขนาดใหญ่ ยูเทาซัน และคณะ อาร์ซิฟ, 2023.
- การออกแบบกลไกและการปรับขนาดสถาปัตยกรรมลูกผสม ไมเคิล โปลิ และคณะ arXiv 2024. [กระดาษ]
- ทบทวนการกลั่นกรองความรู้สำหรับแบบจำลองภาษาแบบถดถอยอัตโนมัติ ฉีหวง จง และคณะ arXiv 2024. [กระดาษ]
- DB-LLM: Dual-Binarization ที่แม่นยำสำหรับ LLM ที่มีประสิทธิภาพ หงเฉิน และคณะ arXiv 2024. [กระดาษ]
- การลดขนาดแคชคีย์-ค่าของ Transformer ด้วยความสนใจแบบข้ามเลเยอร์ วิลเลียม แบรนดอน และคณะ arXiv 2024.[กระดาษ]
- คุณแคชเพียงครั้งเดียว: สถาปัตยกรรมตัวถอดรหัส-ตัวถอดรหัสสำหรับโมเดลภาษา Yutao Sun และคณะ arXiv 2024. [กระดาษ]
4.3 การฝึกอบรมขนาดใหญ่
- การฝึกอบรม Deep Nets ด้วยต้นทุนหน่วยความจำ Sublinear เทียนฉี เฉิน และคณะ arXiv 2016. [กระดาษ]
- นอกเหนือจากข้อมูลและโมเดลความเท่าเทียมสำหรับเครือข่าย Deep Neural จือห่าว เจีย และคณะ arXiv 2018 [กระดาษ]
- GPipe: การฝึกอบรมที่มีประสิทธิภาพของโครงข่ายประสาทเทียมขนาดยักษ์โดยใช้ Pipeline Parallelism หยานผิง หวง และคณะ arXiv 2019. [กระดาษ]
- การเรียนรู้การถ่ายโอนที่มีประสิทธิภาพด้วยพารามิเตอร์สำหรับ NLP นีล โฮลส์บี และคณะ ICML 2019. กระดาษ
- Megatron-LM: การฝึกอบรมโมเดลภาษาพารามิเตอร์หลายพันล้านโดยใช้โมเดล Parallelism โมฮัมหมัด ชูเอบี และคณะ arXiv 2020. [กระดาษ]
- Alpa: การทำให้ระบบคู่ขนานระหว่างและภายในผู้ปฏิบัติงานเป็นอัตโนมัติเพื่อการเรียนรู้เชิงลึกแบบกระจาย เหลียนหมิน เจิ้ง และคณะ arXiv 2022. [กระดาษ]
- การอนุมาน DeepSpeed: ช่วยให้สามารถอนุมานได้อย่างมีประสิทธิภาพของโมเดลหม้อแปลงในระดับที่ไม่เคยมีมาก่อน เรซา ยัซดานี อมินาบาดี และคณะ arXiv 2022. [กระดาษ]
- การท่องจำโดยไม่ต้องติดตั้งมากเกินไป: การวิเคราะห์ไดนามิกการฝึกอบรมของแบบจำลองภาษาขนาดใหญ่ คูชาล ติรูมาลา และคณะ arXiv 2022. [กระดาษ]
- SWARM Parallelism: การฝึกโมเดลขนาดใหญ่สามารถมีประสิทธิภาพในการสื่อสารได้อย่างน่าประหลาดใจ แม็กซ์ ไรอาบินิน และคณะ arXiv 2023. [กระดาษ]
- วิถีการฝึกอบรมของแบบจำลองภาษาในระดับต่างๆ เมิ่งโจวเซี่ย และคณะ arXiv 2023. [กระดาษ]
- HexGen: การอนุมานเชิงกำเนิดของแบบจำลองพื้นฐานเหนือสภาพแวดล้อมการกระจายอำนาจที่ต่างกัน โหยวเหอเจียง และคณะ arXiv 2023. [กระดาษ]
- FusionAI: การฝึกอบรมแบบกระจายอำนาจและการปรับใช้ LLM ด้วย GPU ระดับผู้บริโภคจำนวนมาก เจิ้นเหิง ถัง และคณะ arXiv 2023. [กระดาษ]
- เรียกความสนใจด้วย Blockwise Transformers สำหรับบริบทที่ใกล้ไม่มีที่สิ้นสุด ห่าวหลิว และคณะ arXiv 2023. [กระดาษ]
- Pythia: ชุดโปรแกรมสำหรับการวิเคราะห์โมเดลภาษาขนาดใหญ่ข้ามการฝึกอบรมและการปรับขนาด สเตลลา ไบเดอร์แมน และคณะ arXiv 2023. [กระดาษ]
- การปรับแต่งโมเดลภาษาอย่างละเอียดบนเครือข่ายที่ช้าโดยใช้การบีบอัดการเปิดใช้งานพร้อมการรับประกัน จือหวาง และคณะ arXiv 2023. [กระดาษ]
- LLaMA-Adapter: การปรับแต่งโมเดลภาษาอย่างละเอียดอย่างมีประสิทธิภาพพร้อม Zero-init Attention เหรินรุย จาง และคณะ arXiv 2023. [กระดาษ]
- QLoRA: การปรับแต่ง LLM เชิงปริมาณอย่างมีประสิทธิภาพ ทิม เดตต์เมอร์ส และคณะ arXiv 2023. [กระดาษ]
- การจัดการหน่วยความจำที่มีประสิทธิภาพสำหรับโมเดลภาษาขนาดใหญ่ที่ให้บริการด้วย PagedAttention วูสุข ควอน และคณะ arXiv 2023. [กระดาษ]
- Infinite-LLM: บริการ LLM ที่มีประสิทธิภาพสำหรับบริบทที่ยาวพร้อม DistAttention และ KVCache แบบกระจาย บิน ลิน และคณะ arXiv 2024. [กระดาษ]
- OLMo: เร่งวิทยาศาสตร์ของแบบจำลองภาษา เดิร์ก โกรเนเวลด์ และคณะ arXiv 2024. [กระดาษ]
- ว่าด้วยการฝึกอบรมโมเดลการเรียนรู้เชิงลึกขนาดใหญ่อย่างมีประสิทธิภาพ: การทบทวนวรรณกรรม หลี่ เซิน และคณะ arXiv 2023 [กระดาษ] อยู่ระหว่างการพิจารณา
4.4 เทคนิคการอนุมาน
- FlashAttention: ความสนใจที่แม่นยำรวดเร็วและมีประสิทธิภาพด้วย IO-Awareness ตรีดาว และคณะ. NeuroIPS 2022. [กระดาษ]
- ร่างและตรวจสอบ: การเร่งโมเดลภาษาขนาดใหญ่แบบไม่สูญเสียผ่านการถอดรหัสแบบคาดเดาด้วยตนเอง จุนจาง และคณะ arXiv 2023. [กระดาษ]
- สู่การให้บริการแบบจำลองภาษาขนาดใหญ่ที่มีประสิทธิภาพ: การสำรวจจากอัลกอริทึมไปจนถึงระบบ Xupeng Miao และคณะ arXiv 2023. [กระดาษ]
- FlashDecoding++: การอนุมานโมเดลภาษาขนาดใหญ่ที่เร็วขึ้นบน GPU Ke Hong และคณะ arXiv 2023. [กระดาษ]
- การอนุมานอย่างรวดเร็วจาก Transformers ผ่านการถอดรหัสแบบเก็งกำไร ยานิฟ เลวีอาธาน และคณะ arXiv 2023. [กระดาษ]
- การให้บริการการอนุมานแบบกระจายอย่างรวดเร็วสำหรับโมเดลภาษาขนาดใหญ่ ปิงหยาง วู และคณะ arXiv 2023. [กระดาษ]
- S-LoRA: ให้บริการอะแดปเตอร์ LoRA ที่ทำงานพร้อมกันหลายพันรายการ หยิงเซิง และคณะ arXiv 2023. [กระดาษ]
- TensorRT-LLM: กล่องเครื่องมือ TensorRT สำหรับการอนุมานโมเดลภาษาขนาดใหญ่ที่ปรับให้เหมาะสม NVIDIA. GitHub 2023 [รหัส]
- Punica: การให้บริการ LoRA ของผู้เช่าหลายราย เหลคุน เฉิน และคณะ arXiv 2023. [กระดาษ]
- S$^3: การเพิ่มการใช้งาน GPU ในระหว่างการอนุมานทั่วไปเพื่อให้ได้ปริมาณงานที่สูงขึ้น ยุนโฮ จิน และคณะ arXiv 2023. [กระดาษ]
- เซิร์ฟเวอร์การอนุมาน Multi-LoRA ที่ปรับขนาดได้ถึง 1,000 LLM ที่ได้รับการปรับแต่งอย่างละเอียด เพรดิเบส GitHub 2023 [รหัส]
- การถอดรหัสการค้นหาพร้อมท์ อปูร์ ซักเซนา. GitHub 2023 [รหัส]
- เร็วกว่าหม้อแปลง NVIDIA. GitHub 2021 [กระดาษ]
- DeepSpeed-FastGen: การสร้างข้อความความเร็วสูงสำหรับ LLM ผ่าน MII และ DeepSpeed-Inference คอนเนอร์ โฮล์มส์ และคณะ arXiv 2024. [กระดาษ]
- SpecInfer: การเร่งโมเดลภาษาขนาดใหญ่ที่ให้บริการด้วยการอนุมานและการตรวจสอบเชิงคาดเดาแบบต้นไม้ Xupeng Miao และคณะ arXiv 2024. [กระดาษ]
- Medusa: กรอบงานการเร่งการอนุมาน LLM อย่างง่ายพร้อมหัวถอดรหัสหลายตัว เถียนเล่อ Cai และคณะ arXiv 2024. [กระดาษ]
- โมเดลบอกคุณถึงสิ่งที่ควรละทิ้ง: การบีบอัดแคชแบบ Adaptive KV สำหรับ LLM ซูยู เกะ และคณะ ICLR 2024. [กระดาษ]
- โมเดลภาษาสตรีมมิ่งที่มีประสิทธิภาพพร้อมระบบลดความสนใจ กวงซวน เซียว และคณะ ICLR 2024. [กระดาษ]
- DeFT: Flash Tree-attention พร้อม IO-Awareness เพื่อการอนุมาน LLM ที่ใช้การค้นหาต้นไม้อย่างมีประสิทธิภาพ จินเว่ย เหยา และคณะ arXiv 2024. [กระดาษ]
- การเขียนโปรแกรมโมเดลภาษาขนาดใหญ่อย่างมีประสิทธิภาพโดยใช้ SGLang เหลียนหมิน เจิ้ง และคณะ arXiv 2023. [กระดาษ]
- ความเร็ว: การดำเนินการไปป์ไลน์แบบเก็งกำไรเพื่อการถอดรหัสที่มีประสิทธิภาพ โคลแมน ฮูเปอร์ และคณะ arXiv 2023. [กระดาษ]
- Sequoia: การถอดรหัสเก็งกำไรที่ปรับขนาดได้ แข็งแกร่ง และคำนึงถึงฮาร์ดแวร์ Zhuoming Chen และคณะ arXiv 2024 [กระดาษ] อยู่ระหว่างการพิจารณา
4.5 ต้นทุนและประสิทธิภาพ
- สาธิต-ค้นหา-ทำนาย: การเขียนโมเดลการดึงข้อมูลและภาษาสำหรับ NLP ที่เน้นความรู้ โอมาร์ คัตตับ และคณะ arXiv 2023. [กระดาษ]
- การเรียนรู้ของเครื่องอัตโนมัติ: วิธีการ ระบบ ความท้าทาย แฟรงก์ ฮัตเตอร์ และคณะ บริษัท สำนักพิมพ์ Springer, Incorporated, 2019
- ซุปโมเดล: น้ำหนักเฉลี่ยของโมเดลที่ได้รับการปรับแต่งอย่างละเอียดหลายตัวช่วยเพิ่มความแม่นยำโดยไม่ต้องเพิ่มเวลาในการอนุมาน มิทเชล เวิร์ทสแมน และคณะ arXiv 2022. [กระดาษ]
- การดีบักข้อมูลโดยมีความสำคัญกับ Shapley เหนือไปป์ไลน์การเรียนรู้ของเครื่องแบบ End-to-End โบยัน คาร์ลาช และคณะ arXiv 2022. [กระดาษ]
- การเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์ที่คุ้มค่าสำหรับการอนุมานการสร้างโมเดลภาษาขนาดใหญ่ จิหวาง และคณะ arXiv 2023. [กระดาษ]
- โมเดลภาษาขนาดใหญ่คือวิศวกรที่พร้อมท์ในระดับมนุษย์ Yongchao Zhou และคณะ arXiv 2023. [กระดาษ]
- ผสานโดยการจับคู่โมเดลใน Task Subspaces เดเร็ก แทม และคณะ arXiv 2023. [กระดาษ]
- การแก้ไขโมเดลด้วย Task Arithmetic กาเบรียล อิลฮาร์โก และคณะ arXiv 2023. [กระดาษ]
- PriorBand: การเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์เชิงปฏิบัติในยุคแห่งการเรียนรู้เชิงลึก นีรัตย้อย มัลลิก และคณะ arXiv 2023. [กระดาษ]
- การศึกษาเชิงประจักษ์ของการผสานแบบจำลองหลายรูปแบบ ยี่-ลิน ซุง และคณะ arXiv 2023. [กระดาษ]
- DSPy: การรวบรวมโมเดลภาษาที่เปิดเผยเข้าสู่ไปป์ไลน์การพัฒนาตนเอง โอมาร์ คัตตับ และคณะ arXiv 2023. [กระดาษ]
- FrugalGPT: วิธีใช้โมเดลภาษาขนาดใหญ่พร้อมทั้งลดต้นทุนและปรับปรุงประสิทธิภาพ หลิงเจียว เฉิน และคณะ arXiv 2023. [กระดาษ]
- หม้อแปลงคู่สำหรับ LLM ที่มีประสิทธิภาพในการอนุมาน ไอศวรรยา พีเอส และคณะ arXiv 2024. [กระดาษ]
- AIOS: ระบบปฏิบัติการตัวแทน LLM ไก่เหม่ย และคณะ arXiv 2024. [กระดาษ]
- LoraHub: ลักษณะทั่วไปข้ามงานที่มีประสิทธิภาพผ่านองค์ประกอบ LoRA แบบไดนามิก เฉิงซองหวง และคณะ arXiv 2024. [กระดาษ]
- AutoML ในยุคของโมเดลภาษาขนาดใหญ่: ความท้าทายในปัจจุบัน โอกาสและความเสี่ยงในอนาคต อเล็กซานเดอร์ ทอร์เนเด และคณะ arXiv 2024. [กระดาษ]
- การรวมผู้เชี่ยวชาญเป็นหนึ่งเดียว: การปรับปรุงประสิทธิภาพการคำนวณของการผสมผสานของผู้เชี่ยวชาญ ชไว เหอ และคณะ EMNLP 2023. [กระดาษ] อยู่ระหว่างดำเนินการ
4.6 แพลตฟอร์มคอมพิวเตอร์
- TVM: คอมไพเลอร์เพิ่มประสิทธิภาพแบบ End-to-End อัตโนมัติสำหรับการเรียนรู้เชิงลึก เทียนฉี เฉิน และคณะ arXiv 2018. [กระดาษ]
- TPU v4: ซูเปอร์คอมพิวเตอร์ที่กำหนดค่าใหม่ได้ทางแสงสำหรับการเรียนรู้ของเครื่องพร้อมการรองรับฮาร์ดแวร์สำหรับการฝัง นอร์แมน พี. จุ๊บปี และคณะ arXiv 2023. [กระดาษ]
5. การจัดตำแหน่ง AGI: รับประกันว่า AGI ตอบสนองความต้องการที่หลากหลาย

5.1 ความคาดหวังของการจัดตำแหน่ง AGI
- ความเข้ากันได้ของมนุษย์: ปัญญาประดิษฐ์และปัญหาการควบคุม . สจวร์ต รัสเซลล์ . ไวกิ้ง, 2019.
- ปัญญาประดิษฐ์ ค่านิยม และการจัดตำแหน่ง เอียสัน กาเบรียล . จิตใจและเครื่องจักร 2563 [กระดาษ]
- การจัดตำแหน่งของตัวแทนภาษา แซคารี เคนตัน และคณะ arXiv, 2021. [กระดาษ]
- ปัญหาการเรียนรู้อย่างมีคุณค่า เนท ซวาเรส . รายงานทางเทคนิคของสถาบันวิจัย Machine Intelligence [กระดาษ]
- ปัญหาที่เป็นรูปธรรมในความปลอดภัยของ AI ดาริโอ อาโมเด และคณะ arXiv, 2016. [กระดาษ]
- ความเสี่ยงด้านจริยธรรมและสังคมจากอันตรายจากแบบจำลองภาษา ลอร่า ไวดิงเงอร์ และคณะ arXiv, 2021. [กระดาษ]
- เกี่ยวกับอันตรายของนกแก้ว Stochastic: โมเดลภาษาสามารถใหญ่เกินไปได้หรือไม่? - เอมิลี่ เอ็ม. เบนเดอร์ และคณะ FAccT 2021. [กระดาษ]
- แนวปฏิบัติด้านจริยธรรมของ AI ทั่วโลก แอนนา โจบิน และคณะ Nature Machine Intelligence, 2019. [กระดาษ]
- อคติต่อต้านมุสลิมอย่างต่อเนื่องในแบบจำลองภาษาขนาดใหญ่ อบูบาการ์ อาบิด และคณะ AIES, 2021. [กระดาษ]
- สู่การแก้ไขหลักอ้างอิงที่ไม่แบ่งแยกเพศ หยาง ทริสต้า เฉา และคณะ ACL, 2020. [กระดาษ]
- ผลกระทบทางสังคมของการประมวลผลภาษาธรรมชาติ เดิร์ก โฮวี และคณะ ACL 2016. [กระดาษ]
- TruthfulQA: การวัดว่าแบบจำลองเลียนแบบความเท็จของมนุษย์อย่างไร สเตฟานี ลิน และคณะ ACL 2022. [กระดาษ]
- ความเสี่ยงจากการทำให้เกิดความรุนแรงของ GPT-3 และโมเดลภาษาประสาทขั้นสูง คริส แมคกัฟฟี่ และคณะ arXiv, 2020. [กระดาษ]
- ความโปร่งใสของ AI ในยุคของ LLM: แผนงานการวิจัยที่เน้นมนุษย์เป็นศูนย์กลาง ถาม Vera Liao และคณะ arXiv 2023. [กระดาษ]
- เหนือกว่าความเชี่ยวชาญและบทบาท: กรอบการทำงานเพื่อระบุลักษณะผู้มีส่วนได้ส่วนเสียของการเรียนรู้ของเครื่องที่ตีความได้และความต้องการของพวกเขา ฮารินี สุเรช และคณะ ชิ 2021. [กระดาษ]
- การระบุและลดความเสี่ยงด้านความปลอดภัยของ Generative AI คลาร์ก บาร์เร็ตต์ และคณะ arXiv, 2023. [กระดาษ]
- ตัวแทน LLM สามารถแฮ็กเว็บไซต์ได้โดยอัตโนมัติ ริชาร์ด ฟาง และคณะ arXiv, 2024. [กระดาษ]
- Deepfakes, Phrenology, การเฝ้าระวัง และอื่นๆ อีกมากมาย! อนุกรมวิธานของความเสี่ยงความเป็นส่วนตัวของ AI เฮาปิงลี และคณะ ชิ 2024. [กระดาษ]
- ความเป็นส่วนตัวในยุคของ AI ซอวิค ดาส และคณะ การสื่อสารของ ACM, 2023. [กระดาษ]
5.2 เทคนิคการจัดตำแหน่งปัจจุบัน
- การเรียนรู้ที่จะสรุปด้วยความคิดเห็นของมนุษย์ นิสาน สตีนนอน และคณะ NeuroIPS 2020. [กระดาษ]
- ความคิดที่สองนั้นดีที่สุด: การเรียนรู้ที่จะปรับให้สอดคล้องกับคุณค่าของมนุษย์จากการแก้ไขข้อความ รุยโบ หลิว และคณะ NeuroIPS 2022. [กระดาษ]
- ฝึกอบรมโมเดลภาษาให้ปฏิบัติตามคำแนะนำพร้อมคำติชมของมนุษย์ ลอง โอวหยาง และคณะ NeuroIPS 2022. [กระดาษ]
- การจูงปีศาจภายใน: การล้างพิษด้วยตนเองสำหรับโมเดลภาษา Canwen Xu และคณะ AAAI 2022. กระดาษ
- การจัดแบบจำลองภาษากำเนิดให้สอดคล้องกับคุณค่าของมนุษย์ รุ่ยโบ หลิว และคณะ NAACL 2022. [กระดาษ]
- ฝึกอบรมผู้ช่วยที่เป็นประโยชน์และไม่เป็นอันตรายด้วยการเรียนรู้แบบเสริมกำลังจากผลตอบรับของมนุษย์ หยุนเทาไป๋ และคณะ arXiv 2022. [กระดาษ]
- AI รัฐธรรมนูญ: การไม่เป็นอันตรายจาก AI Feedback หยุนเทาไป๋ และคณะ arXiv 2022. [กระดาษ]
- Raft: รางวัลจัดอันดับ finetuning สำหรับการวางแนวแบบจำลองรากฐานกำเนิด ฮันเซ ดง และคณะ arXiv 2023. [กระดาษ]
- การปรับปรุงโมเดลภาษาด้วยการไล่ระดับนโยบายออฟไลน์ตามความได้เปรียบ อาชูทอช บาเฮติ และคณะ arXiv 2023. [กระดาษ]
- ฝึกอบรมโมเดลภาษาพร้อมผลตอบรับด้านภาษาในวงกว้าง เจเรมี ชูเรอร์ และคณะ arXiv 2023. [กระดาษ]
- กระบวนทัศน์ทางทฤษฎีทั่วไปเพื่อทำความเข้าใจการเรียนรู้จากความชอบของมนุษย์ โมฮัมหมัด เกชลากี อาซาร์ และคณะ arXiv 2023. [กระดาษ]
- มาตรวจสอบกันทีละขั้นตอน ฮันเตอร์ ไลท์แมน และคณะ arXiv 2023. [กระดาษ]
- ปัญหาเปิดและข้อจำกัดพื้นฐานของการเรียนรู้แบบเสริมแรงจากผลตอบรับของมนุษย์ สตีเฟน แคสเปอร์ และคณะ arXiv 2023. [กระดาษ]
- การจัดแนวโมเดลภาษาขนาดใหญ่ผ่านการตอบรับสังเคราะห์ ซองดง คิม และคณะ arXiv 2023. [กระดาษ]
- RLAIF: ปรับขนาดการเรียนรู้การเสริมกำลังจากผลตอบรับของมนุษย์ด้วยผลตอบรับของ AI แฮร์ริสัน ลี และคณะ arXiv 2023. [กระดาษ]
- การเพิ่มประสิทธิภาพการจัดอันดับการตั้งค่าสำหรับการจัดตำแหน่งของมนุษย์ เฟยฟาน ซอง และคณะ arXiv 2023. [กระดาษ]
- การปรับปรุงความเป็นจริงและการใช้เหตุผลในแบบจำลองภาษาผ่านการโต้วาทีแบบหลายตัวแทน ยี่หลุน ตู้ และคณะ arXiv 2023. [กระดาษ]
- การจัดตำแหน่งโมเดลภาษาขนาดใหญ่: แบบสำรวจ เทียนห่าว เสิน และคณะ arXiv 2023. [กระดาษ]
- การเพิ่มประสิทธิภาพการตั้งค่าโดยตรง: โมเดลภาษาของคุณถือเป็นโมเดลการให้รางวัลอย่างลับๆ ราฟาเอล ราไฟลอฟ และคณะ NeuroIPS 2024. [กระดาษ]
- ลิมา: Less is more สำหรับการจัดตำแหน่ง Chunting Zhou และคณะ NeuroIPS 2024. [กระดาษ]
5.3 วิธีการเข้าถึง AGI Alignments
- ความเสี่ยงด้านจริยธรรมและสังคมจากอันตรายจากภาษา เมลเลอร์ ไวดิงเงอร์ และคณะ arXiv 2021. [กระดาษ]
- ฉันทามตินานาชาติเรื่องความปลอดภัยของ AI ปักกิ่ง สถาบันปัญญาประดิษฐ์ปักกิ่ง 2024. [กระดาษ]
- คำอธิบายที่โต้แย้งโดยไม่ต้องเปิดกล่องดำ: การตัดสินใจอัตโนมัติและ GDPR แซนดร้า วอชเตอร์ และคณะ วารสารกฎหมายและเทคโนโลยีฮาร์วาร์ด, 2017. [กระดาษ]
- การจัดตำแหน่งตัวแทนที่ปรับขนาดได้ผ่านการสร้างแบบจำลองรางวัล: ทิศทางการวิจัย Jan Leike และคณะ Arxiv 2018. [กระดาษ]
- การสร้างจริยธรรมในปัญญาประดิษฐ์ Han Yu et al. ijcai 2018. กระดาษ
- เข้ากันได้ของมนุษย์: ปัญญาประดิษฐ์และปัญหาการควบคุม สจวร์ตรัสเซล Viking, 2019. [กระดาษ]
- ปัญญาประดิษฐ์ที่รับผิดชอบ: วิธีการพัฒนาและใช้ AI อย่างรับผิดชอบ Virginia Dignum สปริงเกอร์ธรรมชาติ, 2019. [กระดาษ]
- จริยธรรมของเครื่องจักร: การออกแบบและการกำกับดูแลของระบบจริยธรรม AI และระบบอิสระ Alan F. Winfield และคณะ การดำเนินการของ IEEE, 2019. [กระดาษ]
- ปัญหาเปิดใน AI สหกรณ์ Allan Dafoe และคณะ Arxiv 2020. [กระดาษ]
- ปัญญาประดิษฐ์ค่านิยมและการจัดตำแหน่ง Iason Gabriel จิตใจและเครื่องจักร, 2020. [กระดาษ]
- สหกรณ์ AI: เครื่องจักรต้องเรียนรู้ที่จะหาพื้นดินทั่วไป Allan Dafoe และคณะ ธรรมชาติ 2021. [กระดาษ]
- คุณธรรมของเครื่องจักรความก้าวหน้าทางศีลธรรมและภัยพิบัติด้านสิ่งแวดล้อมที่เกิดขึ้น Ben Kenward และคณะ Arxiv 2021. [กระดาษ]
- การวิเคราะห์ความเสี่ยง X สำหรับการวิจัย AI Dan Hendrycks และคณะ Arxiv 2022. [กระดาษ]
- การสลายตัวของงานสำหรับการกำกับดูแลที่ปรับขนาดได้ (AgISF Distillation) Charbel-Raphaël Segerie บล็อก 2023 [บล็อก]
- การวางนัยทั่วไปที่อ่อนแอต่อความแข็งแกร่ง: ทำให้เกิดความสามารถที่แข็งแกร่งพร้อมกับการดูแลที่อ่อนแอ Collin Burns และคณะ Arxiv 2023. [กระดาษ]
- รูปแบบภาษาของใครสะท้อนให้เห็น - Shibani Santurkar และคณะ ICML 2023. [กระดาษ]
- การจัดตำแหน่ง AI: การสำรวจที่ครอบคลุม Jiaming Ji et al. Arxiv 2023. [กระดาษ]
- ปัญหาเปิดและข้อ จำกัด พื้นฐานของการเรียนรู้การเสริมแรงจากข้อเสนอแนะของมนุษย์ Stephen Casper และคณะ Arxiv 2023. [กระดาษ]
- คาถาปลดล็อคบนฐาน LLMS: การจัดตำแหน่งใหม่ผ่านการเรียนรู้ในบริบท Bill Yuchen Lin และคณะ Arxiv 2023. [กระดาษ]
- การจัดตำแหน่งแบบจำลองภาษาขนาดใหญ่: การสำรวจ Tianhao Shen และคณะ Arxiv 2023. [กระดาษ]
6. AGI ROADMAP: เข้าใกล้ AGI อย่างรับผิดชอบ
6.1 ระดับ AI: แผนภูมิวิวัฒนาการของปัญญาประดิษฐ์
- ประกายไฟแห่งข่าวกรองทั่วไปประดิษฐ์: การทดลองในช่วงต้นด้วย GPT-4 Sébastien Bubeck และคณะ Arxiv 2023. [กระดาษ]
- ระดับของ AGI: ความคืบหน้าในการดำเนินงานบนเส้นทางสู่ AGI Meredith Ringel Morris และคณะ Arxiv 2024. [กระดาษ]
6.2 การประเมิน AGI
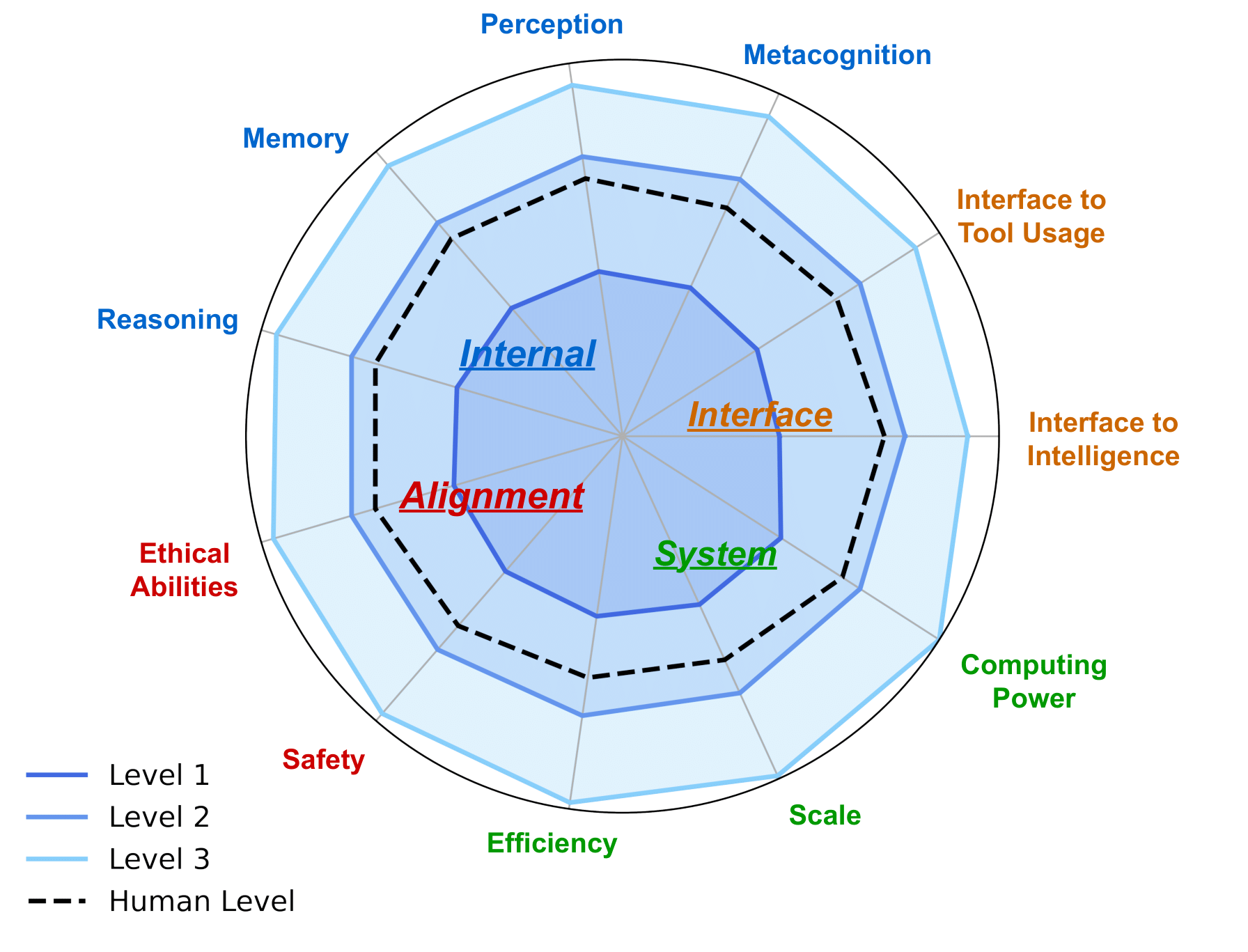
6.2.1 ความคาดหวังสำหรับการประเมิน AGI
- ต่อการรายงานอย่างเป็นระบบของการปล่อยก๊าซพลังงานและคาร์บอนของการเรียนรู้ของเครื่อง Peter Henderson และคณะ วารสารการวิจัยการเรียนรู้ของเครื่องปี 2563
- AI สีเขียว Roy Schwartz Communications ของ ACM, 2020
- การประเมินแบบจำลองภาษาขนาดใหญ่ที่ผ่านการฝึกอบรมเกี่ยวกับรหัส Mark Chen et al. ไม่มีวารสาร, 2021
- การจัดทำเอกสาร WebText Corpora ขนาดใหญ่: กรณีศึกษาเกี่ยวกับคลังข้อมูลคลานที่สะอาดยักษ์ Jesse Dodge และคณะ Arxiv 2021. [กระดาษ]
- เกี่ยวกับโอกาสและความเสี่ยงของแบบจำลองพื้นฐาน Rishi Bommasani และคณะ Arxiv 2021. [กระดาษ]
- การวางนัยทั่วไปอย่างเป็นระบบเหมือนมนุษย์ผ่านเครือข่ายประสาทการเรียนรู้เมตา Brenden M Lake และคณะ ธรรมชาติ, 2023. [กระดาษ]
- Superbench กำลังวัด LLM ในการเปิด: การวิเคราะห์ที่สำคัญ ทีม Superbench Arxiv 2023
- การประเมินแบบองค์รวมของแบบจำลองภาษา Percy Liang และคณะ Arxiv 2023. [กระดาษ]
6.2.2 การประเมินผลปัจจุบันและข้อ จำกัด ของพวกเขา
- ทีม: คำถาม 100,000+ คำถามสำหรับความเข้าใจของเครื่องจักรของข้อความ Pranav Rajpurkar และคณะ Arxiv 2016. [กระดาษ]
- Triviaqa: ชุดข้อมูลความท้าทายขนาดใหญ่ที่มีการดูแลอย่างห่างไกลสำหรับการอ่านความเข้าใจ Mandar Joshi และคณะ Arxiv 2017. [กระดาษ]
- Coqa: ความท้าทายในการตอบคำถามการสนทนา Siva Reddy และคณะ การทำธุรกรรมของสมาคมภาษาศาสตร์คำนวณปี 2019
- การประเมินความแข็งแกร่งที่ถูกต้องเชื่อถือได้และรวดเร็ว Wieland Brendel และคณะ Neurips 2019. [กระดาษ]
- การวัดความเข้าใจภาษามัลติทาสก์ขนาดใหญ่ Dan Hendrycks และคณะ Arxiv 2020. [กระดาษ]
- การประเมินความทนทานของโมเดลและความเสถียรในการเปลี่ยนชุดข้อมูล Adarsh Subbaswamy และคณะ นำเสนอในการประชุมนานาชาติเรื่องปัญญาประดิษฐ์และสถิติปี 2564 กระดาษ
- MMDIALOG: ชุดข้อมูลการสนทนาแบบหลายเทิร์นขนาดใหญ่ที่มีต่อการสนทนาแบบเปิดโดเมนแบบหลายโหมด Jiazhan Feng และคณะ Arxiv 2022. [กระดาษ]
- Instruct ตนเอง: จัดแนวแบบภาษากับคำแนะนำที่สร้างขึ้นเอง Yizhong Wang และคณะ Arxiv 2022. [กระดาษ]
- Super-NaturalInstructions: การวางนัยทั่วไปผ่านคำแนะนำที่ประกาศในงาน 1600+ NLP Yizhong Wang และคณะ Arxiv 2022. [กระดาษ]
- การวิเคราะห์แบบองค์รวมของภาพหลอนใน GPT-4V (ision): ความท้าทายอคติและการรบกวน Chenhang Cui และคณะ Arxiv 2023. [กระดาษ]
- การประเมินความทนทานต่อคำแนะนำของแบบจำลองภาษาขนาดใหญ่ Yuansheng Ni และคณะ Arxiv 2023. [กระดาษ]
- Gaia: มาตรฐานสำหรับผู้ช่วย AI ทั่วไป Grégoire Mialon และคณะ Arxiv 2023. [กระดาษ]
- กรอบการประเมินที่ครอบคลุมสำหรับความทนทานของแบบจำลองลึก Jun Guo และคณะ การจดจำรูปแบบ, 2023. [กระดาษ]
- Agieval: เกณฑ์มาตรฐานของมนุษย์เป็นศูนย์กลางสำหรับการประเมินแบบจำลองพื้นฐาน Wanjun Zhong และคณะ Arxiv 2023. [กระดาษ]
- MMMU: ความเข้าใจที่หลากหลายหลายรูปแบบและมาตรฐานการใช้เหตุผลสำหรับ AGI ผู้เชี่ยวชาญ Xiang และคณะ Arxiv 2023. [กระดาษ]
- การประเมินความคิดสร้างสรรค์แบบจำลองภาษาขนาดใหญ่จากมุมมองทางวรรณกรรม Murray Shanahan และคณะ Arxiv 2023. [กระดาษ]
- Agentbench: การประเมิน LLM Xiao Liu และคณะ ICLR 2024. [กระดาษ]
- การประเมินและทำความเข้าใจความคิดสร้างสรรค์ในแบบจำลองภาษาขนาดใหญ่ Yunpu Zhao และคณะ Arxiv 2024. [กระดาษ]
- การตัดสิน LLM-as-a-Judge กับ MT-Bench และ Chatbot Arena Lianmin Zheng และคณะ Neurips 2024. [กระดาษ]

6.5 ข้อควรพิจารณาเพิ่มเติมในระหว่างการพัฒนา AGI
- ความท้าทายพื้นฐานในการรับรองการจัดตำแหน่งและความปลอดภัยของแบบจำลองภาษาขนาดใหญ่ Usman Anwar และคณะ Arxiv 2024. [กระดาษ]
- แนวปฏิบัติที่ดีที่สุดและบทเรียนที่ได้เรียนรู้เกี่ยวกับข้อมูลสังเคราะห์สำหรับแบบจำลองภาษา Ruibo Liu และคณะ Arxiv 2024. [กระดาษ]
- การพัฒนาความฉลาดทางสังคมในตัวแทน AI: ความท้าทายทางเทคนิคและคำถามเปิด Leena Mathur และคณะ Arxiv 2024. [กระดาษ]
7. กรณีศึกษา
7.1 AI สำหรับการค้นพบวิทยาศาสตร์และการวิจัย
- การทำนายโครงสร้างโปรตีนที่แม่นยำสูงด้วยตัวอักษร จัมเปอร์จอห์น และคณะ ธรรมชาติ, 2021. [กระดาษ]
- การค้นพบทางวิทยาศาสตร์อัตโนมัติ: จากการค้นพบสมการไปจนถึงระบบการค้นพบอัตโนมัติ Kramer, Stefan และคณะ Arxiv 2023. [กระดาษ]
- การทำนายผลกระทบของตัวแปรที่ไม่ได้เข้ารหัสด้วยแบบจำลองลำดับการเรียนรู้เชิงลึก โจวเจียน และคณะ วิธีธรรมชาติ, 2015. [[กระดาษ] (https://www.ncbi.nlm.nih.gov/pmc/articles/pmc4768299/]
- การเรียนรู้ที่จะเห็นฟิสิกส์ผ่านการมองเห็นภาพ Wu, Jiajun และคณะ Neurips 2017. [กระดาษ]
- การเรียนรู้อย่างลึกซึ้งสำหรับการตรวจจับคลื่นความโน้มถ่วงแบบเรียลไทม์และการประมาณค่าพารามิเตอร์: ผลลัพธ์ที่มีข้อมูล LIGO ขั้นสูง George, Daniel และคณะ ตัวอักษรฟิสิกส์ B, 2018. [กระดาษ]
- การระบุการเปลี่ยนเฟสควอนตัมด้วยเครือข่ายประสาทตา Rem, Bart-Jan และคณะ Nature Physics, 2019. [กระดาษ]
- OpenAgi: เมื่อ LLM พบกับผู้เชี่ยวชาญด้านโดเมน GE, Yingqiang และคณะ Neurips, 2023. [กระดาษ]
- จากสสารมืดไปยังกาแลคซีด้วยเครือข่าย convolutional จาง Xinyue และคณะ Arxiv 2019. [กระดาษ]
- การเพิ่มประสิทธิภาพทั่วโลกของพลศาสตร์ควอนตัมด้วยการสำรวจลึกของ Alphazero Dalgaard, Mogens และคณะ ข้อมูลควอนตัม NPJ, 2020. [กระดาษ]
- เรียนรู้ที่จะใช้ประโยชน์จากโครงสร้างทางโลกสำหรับการประมวลผลภาษาวิสัยทัศน์ทางชีวการแพทย์ Shruthi Bannur และคณะ CVPR, 2023. [กระดาษ]
- Mathbert: รูปแบบภาษาที่ผ่านการฝึกอบรมมาก่อนสำหรับงาน NLP ทั่วไปในการศึกษาคณิตศาสตร์ Shen, Jia Tracy และคณะ Arxiv 2021. [กระดาษ]
- การเพิ่มประสิทธิภาพระดับโมเลกุลโดยใช้แบบจำลองภาษา Maziarz, Krzysztof และคณะ Arxiv 2022. [กระดาษ]
- Retrotrae: การแปล retrosynthetic ของสภาพแวดล้อมอะตอมด้วยหม้อแปลง Ucak, Umit Volkan และคณะ ไม่มีวารสาร, 2022. [กระดาษ]
- Scholarbert: ใหญ่กว่านั้นไม่ดีกว่าเสมอไป Hong, Zhi และคณะ Arxiv 2022. [กระดาษ]
- Galactica: แบบจำลองภาษาขนาดใหญ่สำหรับวิทยาศาสตร์ Taylor, Ross และคณะ Arxiv 2022. [กระดาษ]
- การเรียนรู้หลักสูตรคณิตศาสตร์อย่างเป็นทางการ Polu, Stanislas และคณะ Arxiv 2022. [กระดาษ]
- Proof Artifact Co-Training สำหรับทฤษฎีบทที่พิสูจน์ด้วยรูปแบบภาษา Jesse Michael Han และคณะ ICLR 2022. [กระดาษ]
- การแก้ปัญหาการใช้เหตุผลเชิงปริมาณด้วยแบบจำลองภาษา Lewkowycz, Aitor และคณะ Arxiv 2022. [กระดาษ]
- Biogpt: หม้อแปลงที่ผ่านการฝึกอบรมมาแล้วสำหรับการสร้างข้อความทางชีวการแพทย์และการขุด Luo, Renqian และคณะ การบรรยายสรุปในชีวสารสนเทศศาสตร์, 2022
- Chemcrow: การเพิ่มโมเดลภาษาขนาดใหญ่ด้วยเครื่องมือเคมี Bran, Andres M et al. Arxiv 2023. [กระดาษ]
- การวิจัยทางเคมีแบบอิสระด้วยแบบจำลองภาษาขนาดใหญ่ Boiko, Daniil a et al. ธรรมชาติ, 2023. [กระดาษ]
- ความสามารถในการวิจัยทางวิทยาศาสตร์แบบอิสระของแบบจำลองภาษาขนาดใหญ่ Daniil A. Boiko และคณะ Arxiv 2023. [กระดาษ]
- MathPrompter: การใช้เหตุผลทางคณิตศาสตร์โดยใช้แบบจำลองภาษาขนาดใหญ่ Imani, Shima, et al. นำเสนอในการประชุมประจำปีครั้งที่ 61 ของสมาคมเพื่อการคำนวณภาษาศาสตร์ (เล่มที่ 5: การติดตามอุตสาหกรรม), 2023. [กระดาษ]
- เรียนรู้ที่จะใช้ประโยชน์จากโครงสร้างทางโลกสำหรับการประมวลผลภาษาวิสัยทัศน์ทางชีวการแพทย์ Shruthi Bannur และคณะ Arxiv 2023. [กระดาษ]
- LLMs สำหรับวิทยาศาสตร์: การใช้งานการสร้างรหัสและการวิเคราะห์ข้อมูล Nejjar, Mohamed และคณะ Arxiv 2023. [กระดาษ]
- Medagents: รูปแบบภาษาขนาดใหญ่ในฐานะผู้ทำงานร่วมกันสำหรับการใช้เหตุผลทางการแพทย์แบบไม่มีการยิง Xiangru Tang และคณะ Arxiv 2024. [กระดาษ]
7.2 ความฉลาดทางสายตาแบบกำเนิด
- การเรียนรู้ที่ไม่ได้รับการดูแลอย่างลึกล้ำโดยใช้อุณหพลศาสตร์ที่ไม่มีควิลิเบีย ม Jascha Sohl-Dickstein และคณะ ICML 2015. [กระดาษ]
- การสร้างแบบจำลองการกำเนิดโดยการประเมินการไล่ระดับสีของการกระจายข้อมูล Yang Song และคณะ Neurips 2019. [กระดาษ]
- แบบจำลองความน่าจะเป็นของการแพร่กระจาย Jonathan Ho et al. Neurips 2020. [กระดาษ]
- การสร้างแบบจำลองการกำเนิดที่อิงกับคะแนนผ่านสมการเชิงอนุพันธ์สุ่ม Yang Song และคณะ ICLR 2021. [กระดาษ]
- ร่อน: ไปสู่การสร้างภาพและการแก้ไขด้วยรูปแบบการแพร่กระจายด้วยข้อความ Alex Nichol และคณะ ICML 2022. [กระดาษ]
- Sdedit: การสังเคราะห์ภาพนำทางและการแก้ไขด้วยสมการเชิงอนุพันธ์สุ่ม Chenlin Meng และคณะ ICLR 2022. [กระดาษ]
- โมเดลการแพร่กระจายวิดีโอ Jonathan Ho et al. Neurips 2022. [กระดาษ]
- การสร้างภาพข้อความแบบลำดับชั้นด้วยคลิปแฝง Aditya Ramesh และคณะ Arxiv 2022. [กระดาษ]
- คำแนะนำการแพร่กระจายแบบแยกตัวจําแนก Jonathan Ho et al. Arxiv 2022. [กระดาษ]
- Palette: รูปแบบการแพร่ภาพกับภาพ Chitwan Saharia และคณะ Siggraph 2022. [กระดาษ]
- การสังเคราะห์ภาพความละเอียดสูงด้วยแบบจำลองการแพร่กระจายแฝง Robin Rombach และคณะ CVPR 2022. [กระดาษ]
- การเพิ่มการควบคุมแบบมีเงื่อนไขให้กับโมเดลการแพร่กระจายข้อความไปยังภาพ Lvmin Zhang และคณะ ICCV 2023. [กระดาษ]
- แบบจำลองการแพร่กระจายที่ปรับขนาดได้ด้วยหม้อแปลง William Peebles และคณะ ICCV 2023. [กระดาษ]
- การสร้างแบบจำลองตามลำดับช่วยให้สามารถเรียนรู้ได้สำหรับแบบจำลองการมองเห็นขนาดใหญ่ Yutong Bai และคณะ Arxiv 2023. [กระดาษ]
- โมเดลการสร้างวิดีโอเป็นเครื่องจำลองโลก Tim Brooks และคณะ Openai 2024. [กระดาษ]
7.3 นางแบบโลก
- การเรียนรู้ที่จะเห็นฟิสิกส์ผ่านการมองเห็นภาพ Wu, Jiajun และคณะ Neurips 2017. [กระดาษ]
- การเรียนรู้การเสริมแรงแบบใช้แบบจำลองที่ปลอดภัยด้วยการรับประกันความมั่นคง Berkenkamp, Felix และคณะ Neurips, 2017. [กระดาษ]
- SIMNET: การเรียนรู้แบบจำลองโลกที่ใช้การจำลองเพื่อการใช้เหตุผลทางกายภาพ Vicol, Paul, Menapace และคณะ ICLR 2022. [กระดาษ]
- Dreamix: Dreamfusion ผ่านการผสม spatiotemporal ซ้ำ Khalifa, Anji และคณะ Arxiv 2022. [กระดาษ]
- อเนกประสงค์ทั่วไปเป็นตัวแทนของ AI ตัวแทนการเรียนรู้การเสริมแรงด้วยความรู้ระดับอินเทอร์เน็ต Guo, Xiaoxiao และคณะ Arxiv 2022. [กระดาษ]
- VQGAN-CLIP: เปิดการสร้างภาพโดเมนและแก้ไขด้วยคำแนะนำภาษาธรรมชาติ Crowson, Katherine Arxiv 2022. [กระดาษ]
- เส้นทางสู่หน่วยสืบราชการลับของเครื่องจักรอิสระ Lecun Yann OpenReview, 2022. [Paper]
- แบบจำลองภาษาพบกับแบบจำลองของโลก: ประสบการณ์ที่เป็นตัวเป็นตนช่วยเพิ่มรูปแบบภาษา Jiannan Xiang และคณะ Neurips 2023. [กระดาษ]
- การเรียนรู้โดเมนที่หลากหลายผ่านแบบจำลองโลก Hafner, Danijar และคณะ Arxiv 2023. [กระดาษ]
- การได้มาซึ่งโมเดลหลายรูปแบบผ่านการดึงข้อมูล Reed, Scott และคณะ Arxiv 2023. [กระดาษ]
- แบบจำลองภาษาเป็นนักวางแผนการช็อตแบบศูนย์: สกัดความรู้ที่สามารถดำเนินการได้สำหรับตัวแทนที่เป็นตัวเป็นตน Dohan, David และคณะ Arxiv 2023. [กระดาษ]
- แบบจำลองภาษา, โมเดลตัวแทนและโมเดลโลก: กฎหมายสำหรับการใช้เหตุผลและการวางแผนของเครื่อง Zhiting Hu et al. Arxiv 2023. [กระดาษ]
- การให้เหตุผลกับรูปแบบภาษาคือการวางแผนกับโมเดลโลก Hao, Shibo และคณะ Arxiv 2023. [กระดาษ]
- Metasim: เรียนรู้ที่จะสร้างชุดข้อมูลสังเคราะห์ จาง, Yuxuan และคณะ Arxiv 2023. [กระดาษ]
- โมเดลโลกเกี่ยวกับวิดีโอและภาษาที่มีความยาวล้านด้วย Ringattention Hao Liu และคณะ Arxiv 2024. [กระดาษ]
- Genie: สภาพแวดล้อมแบบอินเทอร์แอคทีฟกำเนิด Jake Bruce และคณะ Arxiv 2024. [กระดาษ]
7.4 การกระจายอำนาจ LLM
- Petals: การอนุมานการทำงานร่วมกันและการปรับแต่งโมเดลขนาดใหญ่ Alexander Borzunov และคณะ Arxiv 2022. [กระดาษ]
- blockchain สำหรับการเรียนรู้อย่างลึกซึ้ง: ทบทวนและความท้าทายที่เปิดกว้าง ช่วงเวลาทางเศรษฐกิจ การคำนวณคลัสเตอร์ 2021 [กระดาษ]
- FlexGen: การอนุมานการเกิดความเร็วสูงของแบบจำลองภาษาขนาดใหญ่ที่มี GPU เดียว Ying Sheng และคณะ Arxiv 2023. [กระดาษ]
- การฝึกอบรมแบบกระจายอำนาจของแบบจำลองพื้นฐานในสภาพแวดล้อมที่ต่างกัน Binhang Yuan และคณะ Arxiv 2023. [กระดาษ]
7.5 AI สำหรับการเขียนโค้ด
- กรอบสำหรับการประเมินโมเดลการสร้างรหัส Ben Allal และคณะ GitHub, 2023. [รหัส]
- การประเมินแบบจำลองภาษาขนาดใหญ่ที่ผ่านการฝึกอบรมเกี่ยวกับรหัส Mark Chen et al. Arxiv 2021. [กระดาษ]
- การสังเคราะห์โปรแกรมด้วยแบบจำลองภาษาขนาดใหญ่ Jacob Austin และคณะ Arxiv 2021. [กระดาษ]
- การสร้างรหัสระดับการแข่งขันด้วย Alphacode Yujia Li et al. วิทยาศาสตร์, 2022. [กระดาษ]
- การฝึกอบรมแบบจำลองภาษาที่มีประสิทธิภาพเพื่อเติมเต็มกลาง Mohammad Bavarian และคณะ Arxiv 2022. [กระดาษ]
- SANTACODER: อย่าไปถึงดวงดาว! - Loubna Ben Allal และคณะ ใจ, 2023. [กระดาษ]
- StarCoder: ขอให้แหล่งข่าวอยู่กับคุณ! - Raymond Li et al. Arxiv 2023. [กระดาษ]
- แบบจำลองภาษาขนาดใหญ่สำหรับการเพิ่มประสิทธิภาพคอมไพเลอร์ Chris Cummins และคณะ Arxiv 2023. [กระดาษ]
- ตำราเรียนเป็นสิ่งที่คุณต้องการ Suriya Gunasekar และคณะ Arxiv 2023. [กระดาษ]
- Intercode: การกำหนดมาตรฐานและการเปรียบเทียบการเข้ารหัสแบบโต้ตอบด้วยการตอบรับการดำเนินการ John Yang et al. Arxiv 2023. [กระดาษ]
- การเรียนรู้การเสริมแรงจากข้อเสนอแนะอัตโนมัติสำหรับการสร้างการทดสอบหน่วยคุณภาพสูง Benjamin Steenhoek และคณะ Arxiv 2023. [กระดาษ]
- แบบอินเทอร์: โมเดลกำเนิดสำหรับการแทรกซึมและการสังเคราะห์ Daniel Fried และคณะ Arxiv 2023. [กระดาษ]
- การปรับแต่งรหัส C decompiled ด้วยรูปแบบภาษาขนาดใหญ่ Wai Kin Wong และคณะ Arxiv 2023. [กระดาษ]
- Swe-Bench: โมเดลภาษาสามารถแก้ไขได้ในโลกแห่งความจริง


