DeepKE
DeepKE 2.2.7
อังกฤษ | 简体中文
ชุดเครื่องมือดึงความรู้จากการเรียนรู้เชิงลึก
สำหรับการสร้างกราฟความรู้
DeepKE เป็นชุดเครื่องมือดึงความรู้สำหรับการสร้างกราฟความรู้ที่รองรับ cnSchema สถานการณ์ ทรัพยากรต่ำ ระดับเอกสาร และ หลายรูป แบบสำหรับการแยก เอนทิตี ความสัมพันธ์ และ แอตทริบิวต์ เราจัดเตรียมเอกสาร การสาธิตออนไลน์ กระดาษ สไลด์ และโปสเตอร์สำหรับผู้เริ่มต้น
\ ในเส้นทางไฟล์wisemodel หรือ modescapeหากคุณพบปัญหาใดๆ ระหว่างการติดตั้ง DeepKE และ DeepKE-LLM โปรดตรวจสอบเคล็ดลับหรือส่งปัญหาทันที แล้วเราจะช่วยเหลือคุณในการแก้ไขปัญหา!
April, 2024 เราเปิดตัวโมเดลการแยกข้อมูลตามสคีมาสองภาษา (จีนและอังกฤษ) ใหม่ที่เรียกว่า OneKE ที่ใช้ภาษาจีน-Alpaca-2-13BFeb, 2024 เราเปิดตัวชุดข้อมูลคำสั่งการแยกข้อมูล (IE) สองภาษา (จีนและอังกฤษ) คุณภาพสูงขนาดใหญ่ (โทเค็น 0.32B) ชื่อ IEPile พร้อมด้วยสองโมเดลที่ได้รับการฝึกด้วย IEPile , baichuan2-13b-iepile-lora และ llama2 -13b-iepile-ลอราSep 2023 ชุดข้อมูลคำสั่งการแยกข้อมูลภาษาอังกฤษภาษาจีน (IE) สองภาษาที่เรียกว่า InstructIE ได้รับการเผยแพร่สำหรับงานสร้างกราฟความรู้ตามคำสั่ง (KGC ตามคำสั่ง) ดังรายละเอียดอยู่ที่นี่June, 2023 เราอัปเดต DeepKE-LLM เพื่อรองรับ การดึงความรู้ ด้วย KnowLM, ChatGLM, LLaMA-series, GPT-series ฯลฯApr, 2023 เราได้เพิ่มโมเดลใหม่ รวมถึง CP-NER(IJCAI'23), ASP(EMNLP'22), PRGC(ACL'21), PURE(NAACL'21) ซึ่งมีความสามารถในการแยกเหตุการณ์ (ภาษาจีนและอังกฤษ) และเสนอความเข้ากันได้กับแพ็คเกจ Python เวอร์ชันที่สูงกว่า (เช่น Transformers)Feb, 2023 เราได้สนับสนุนการใช้ LLM (GPT-3) กับการเรียนรู้ในบริบท (ตาม EasyInstruct) และการสร้างข้อมูล เพิ่มโมเดล NER W2NER(AAAI'22) Nov, 2022 เพิ่มคำแนะนำคำอธิบายประกอบข้อมูลสำหรับการรับรู้เอนทิตีและการแยกความสัมพันธ์ การติดป้ายกำกับอัตโนมัติของข้อมูลที่มีการดูแลอย่างไม่รัดกุม (การแยกเอนทิตีและการแยกความสัมพันธ์) และเพิ่มประสิทธิภาพการฝึกอบรม Multi-GPU
Sept, 2022 บทความ DeepKE: ชุดเครื่องมือดึงความรู้จากการเรียนรู้เชิงลึกสำหรับประชากรฐานความรู้ได้รับการยอมรับจาก EMNLP 2022 System Demonstration Track
Aug, 2022 เราได้เพิ่มการรองรับการเพิ่มข้อมูล (จีน อังกฤษ) สำหรับการดึงข้อมูลความสัมพันธ์ที่มีทรัพยากรต่ำ
June, 2022 เราได้เพิ่มการรองรับหลายรูปแบบสำหรับการแยกเอนทิตีและความสัมพันธ์
May, 2022 เราได้เปิดตัว DeepKE-cnschema พร้อมโมเดลการแยกความรู้ที่มีจำหน่ายทั่วไป
Jan, 2022 เราได้เผยแพร่รายงาน DeepKE: ชุดเครื่องมือดึงความรู้จากการเรียนรู้เชิงลึกสำหรับประชากรฐานความรู้
Dec, 2021 เราได้เพิ่ม dockerfile เพื่อสร้างสภาพแวดล้อมโดยอัตโนมัติ
Nov, 2021 มีการเผยแพร่การสาธิต DeepKE ซึ่งรองรับการแยกข้อมูลแบบเรียลไทม์โดยไม่ต้องปรับใช้และฝึกอบรม
เอกสารของ DeepKE ซึ่งมีรายละเอียดของ DeepKE เช่น ซอร์สโค้ดและชุดข้อมูล ได้รับการเผยแพร่แล้ว
Oct, 2021 pip install deepke
รหัสของ deepke-v2.0 ได้รับการเผยแพร่แล้ว
Aug, 2019 รหัสของ deepke-v1.0 ได้รับการเผยแพร่แล้ว
Aug, 2018 การเปิดตัวโครงการ DeepKE และโค้ดของ deepke-v0.1 ได้รับการเผยแพร่แล้ว
มีการแสดงคำทำนาย ไฟล์ GIF ถูกสร้างขึ้นโดย Terminalizer รับรหัส 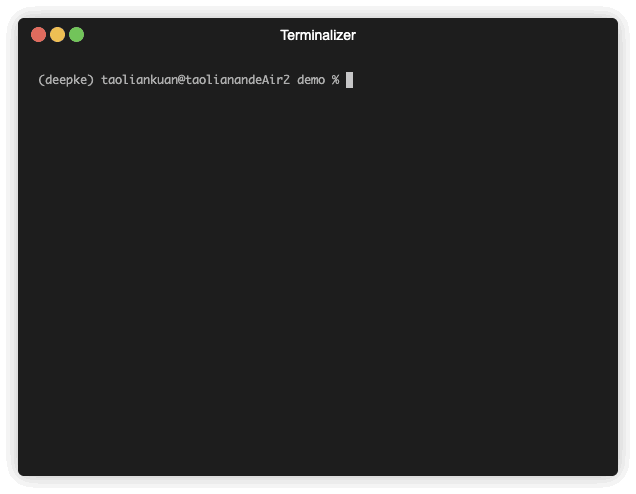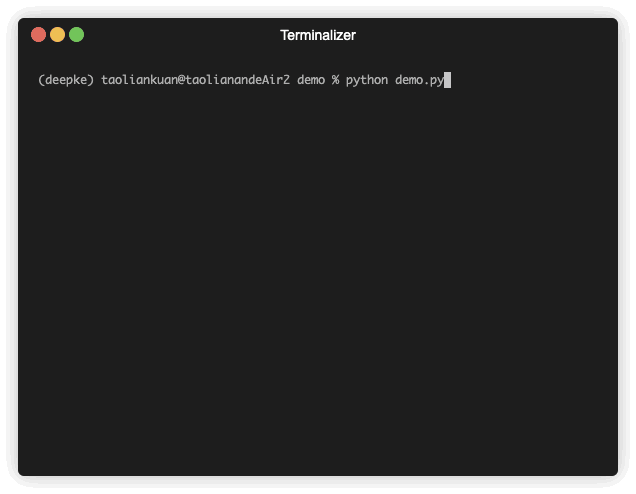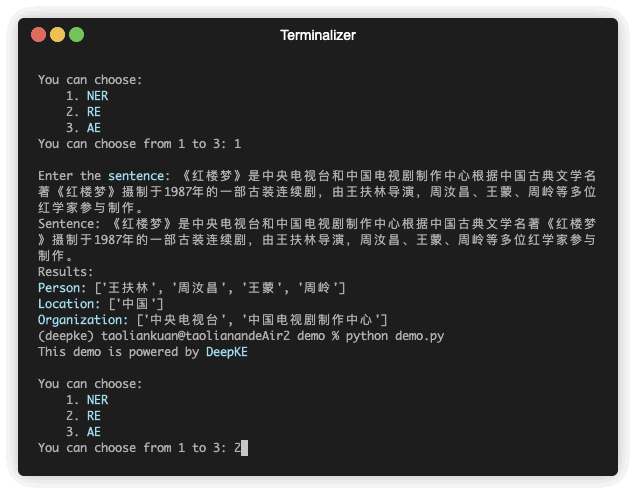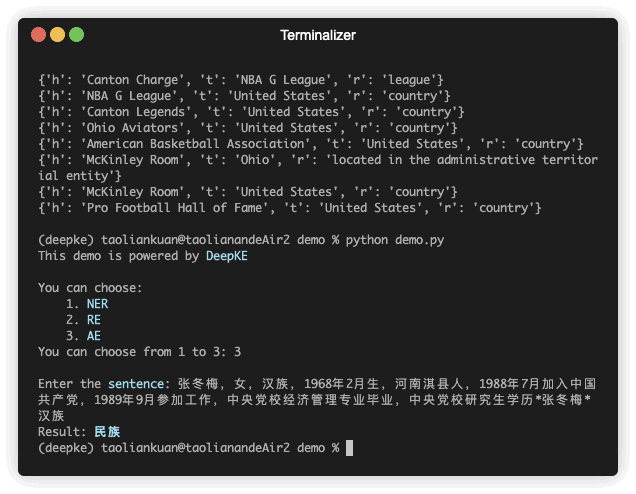
ในยุคของโมเดลขนาดใหญ่ DeepKE-LLM ใช้การพึ่งพาสภาพแวดล้อมใหม่ทั้งหมด
conda create -n deepke-llm python=3.9
conda activate deepke-llm
cd example/llm
pip install -r requirements.txt
โปรดทราบว่าไฟล์ requirements.txt อยู่ในโฟลเดอร์ example/llm
pip install deepkeขั้นตอนที่ 1 ดาวน์โหลดโค้ดพื้นฐาน
git clone --depth 1 https://github.com/zjunlp/DeepKE.git ขั้นตอนที่ 2 สร้างสภาพแวดล้อมเสมือนจริงโดยใช้ Anaconda และป้อนเข้าไป
conda create -n deepke python=3.8
conda activate deepkeติดตั้ง DeepKE ด้วยซอร์สโค้ด
pip install -r requirements.txt
python setup.py install
python setup.py develop ติดตั้ง DeepKE ด้วย pip ( ไม่แนะนำ! )
pip install deepkeขั้นตอนที่ 3 เข้าสู่ไดเร็กทอรีงาน
cd DeepKE/example/re/standardขั้นตอนที่ 4 ดาวน์โหลดชุดข้อมูล หรือทำตามคำแนะนำคำอธิบายประกอบเพื่อรับข้อมูล
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gzรองรับรูปแบบข้อมูลหลายประเภทและมีรายละเอียดในแต่ละส่วน
ขั้นตอนที่ 5 การฝึกอบรม (พารามิเตอร์สำหรับการฝึกอบรมสามารถเปลี่ยนแปลงได้ในโฟลเดอร์ conf )
เราสนับสนุนการปรับพารามิเตอร์ภาพโดยใช้ wandb
python run.py การทำนาย ขั้นที่ 6 (พารามิเตอร์สำหรับการทำนายสามารถเปลี่ยนแปลงได้ในโฟลเดอร์ conf )
แก้ไขเส้นทางของโมเดลที่ได้รับการฝึกใน predict.yaml จำเป็นต้องใช้เส้นทางสัมบูรณ์ของโมเดล เช่น xxx/checkpoints/2019-12-03_ 17-35-30/cnn_ epoch21.pth
python predict.pyขั้นตอนที่ 1 ติดตั้งไคลเอ็นต์ Docker
ติดตั้ง Docker และเริ่มบริการ Docker
ขั้นตอนที่ 2 ดึงอิมเมจนักเทียบท่าและเรียกใช้คอนเทนเนอร์
docker pull zjunlp/deepke:latest
docker run -it zjunlp/deepke:latest /bin/bashขั้นตอนที่เหลือจะเหมือนกับ ขั้นตอนที่ 3 ขึ้นไป ใน การกำหนดค่าสภาพแวดล้อมด้วยตนเอง
หลาม == 3.8
การรับรู้เอนทิตีที่มีชื่อพยายามค้นหาและจำแนกเอนทิตีที่มีชื่อซึ่งกล่าวถึงในข้อความที่ไม่มีโครงสร้างเป็นหมวดหมู่ที่กำหนดไว้ล่วงหน้า เช่น ชื่อบุคคล องค์กร สถานที่ องค์กร ฯลฯ
ข้อมูลจะถูกจัดเก็บไว้ในไฟล์ . .txt บางกรณีดังต่อไปนี้ (ผู้ใช้สามารถติดป้ายกำกับข้อมูลตามเครื่องมือ Doccano, MarkTool หรือสามารถใช้ Weak Supervision ด้วย DeepKE เพื่อรับข้อมูลโดยอัตโนมัติ):
| ประโยค | บุคคล | ที่ตั้ง | องค์กร |
|---|---|---|---|
| 本报北京9月4日讯记者杨涌报道:部分省区人民日报宣传发行工作座谈会9月3日在4日的京举行。 | 杨涌 | 北京 | 人民日报 |
| 《红楼梦》由王扶林导演,周汝昌、王蒙、周岭等多位专家参与制作。 | 王扶林,周汝昌,王蒙,周岭 | ||
| 秦始皇兵马俑位于陕西省西安市,是世界八大奇迹之一。 | 秦始皇 | 陕西省,西安市 |
อ่านกระบวนการโดยละเอียดใน README เฉพาะ
มาตรฐาน (ควบคุมอย่างเต็มที่)
เราสนับสนุน LLM และจัดเตรียมโมเดลที่มีจำหน่ายทั่วไป DeepKE-cnSchema-NER ซึ่งจะแยกเอนทิตีใน cnSchema โดยไม่ต้องมีการฝึกอบรม
ขั้นตอนที่ 1 เข้าสู่ DeepKE/example/ner/standard ดาวน์โหลดชุดข้อมูล
wget 120.27.214.45/Data/ner/standard/data.tar.gz
tar -xzvf data.tar.gz ขั้นตอนที่ 2 การฝึกอบรม
ชุดข้อมูลและพารามิเตอร์สามารถปรับแต่งได้ในโฟลเดอร์ data และโฟลเดอร์ conf ตามลำดับ
python run.pyการทำนาย ขั้นที่ 3
python predict.pyไม่กี่ช็อต
ขั้นตอนที่ 1 เข้าสู่ DeepKE/example/ner/few-shot ดาวน์โหลดชุดข้อมูล
wget 120.27.214.45/Data/ner/few_shot/data.tar.gz
tar -xzvf data.tar.gz ขั้นตอนที่ 2 การฝึกอบรมในการตั้งค่าทรัพยากรต่ำ
ไดเร็กทอรีที่โหลดและบันทึกโมเดลและพารามิเตอร์การกำหนดค่าสามารถปรับแต่งได้ในโฟลเดอร์ conf
python run.py +train=few_shot ผู้ใช้สามารถแก้ไข load_path ใน conf/train/few_shot.yaml เพื่อใช้โมเดลที่โหลดที่มีอยู่
ขั้นตอนที่ 3 เพิ่ม - predict ว่าจะ conf/config.yaml แก้ไข loda_path เป็นเส้นทางโมเดลและ write_path เป็นเส้นทางที่บันทึกผลลัพธ์ที่คาดการณ์ไว้ใน conf/predict.yaml จากนั้นเรียกใช้ python predict.py
python predict.pyมัลติโมดัล
ขั้นตอนที่ 1 เข้าสู่ DeepKE/example/ner/multimodal ดาวน์โหลดชุดข้อมูล
wget 120.27.214.45/Data/ner/multimodal/data.tar.gz
tar -xzvf data.tar.gzเราใช้วัตถุที่ตรวจพบ RCNN และวัตถุที่มองเห็นจากภาพต้นฉบับเป็นข้อมูลภาพในเครื่อง โดยที่ RCNN ผ่านทาง fast_rcnn และการต่อลงดินด้วยภาพผ่านทาง onestage_grounding
ขั้นตอนที่ 2 การฝึกอบรมในสภาพแวดล้อมต่อเนื่องหลายรูปแบบ
data และโฟลเดอร์ conf ตามลำดับload_path ใน conf/train.yaml เป็นพาธที่บันทึกโมเดลที่ได้รับการฝึกครั้งล่าสุด และบันทึกการบันทึกเส้นทางที่สร้างขึ้นในการฝึกอบรมสามารถปรับแต่งได้โดย log_dir python run.pyการทำนาย ขั้นที่ 3
python predict.pyการแยกความสัมพันธ์เป็นงานในการแยกความสัมพันธ์เชิงความหมายระหว่างเอนทิตีออกจากข้อความที่ไม่มีโครงสร้าง
ข้อมูลจะถูกจัดเก็บไว้ในไฟล์ . .csv บางกรณีดังต่อไปนี้ (ผู้ใช้สามารถติดป้ายกำกับข้อมูลตามเครื่องมือ Doccano, MarkTool หรือสามารถใช้ Weak Supervision ด้วย DeepKE เพื่อรับข้อมูลโดยอัตโนมัติ):
| ประโยค | ความสัมพันธ์ | ศีรษะ | เฮด_ออฟเซ็ต | หาง | Tail_offset |
|---|---|---|---|---|---|
| 《岳父也是爹》是王军执导的电视剧,由马恩然、范明主演。 | 导演 | 岳父也是爹 | 1 | 王军 | 8 |
| 《九玄珠》是在纵横中文网连载的一部เสี่ยว说,作者是龙马。 | 连载网站 | 九玄珠 | 1 | 纵横中文网 | 7 |
| 提起杭州的mei景,西湖总是第一个映入脑海的词语。 | 所在城市 | 西湖 | 8 | 杭州 | 2 |
!หมายเหตุ: หากมีเอนทิตีหลายประเภทสำหรับความสัมพันธ์เดียว ประเภทเอนทิตีสามารถขึ้นต้นด้วยความสัมพันธ์เป็นอินพุตได้
อ่านกระบวนการโดยละเอียดใน README เฉพาะ
มาตรฐาน (ควบคุมอย่างเต็มที่)
เราสนับสนุน LLM และนำเสนอโมเดลที่มีจำหน่ายทั่วไป DeepKE-cnSchema-RE ซึ่งจะแยกความสัมพันธ์ใน cnSchema โดยไม่ต้องมีการฝึกอบรม
ขั้นตอนที่ 1 เข้าสู่โฟลเดอร์ DeepKE/example/re/standard ดาวน์โหลดชุดข้อมูล
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gz ขั้นตอนที่ 2 การฝึกอบรม
ชุดข้อมูลและพารามิเตอร์สามารถปรับแต่งได้ในโฟลเดอร์ data และโฟลเดอร์ conf ตามลำดับ
python run.pyการทำนาย ขั้นที่ 3
python predict.pyไม่กี่ช็อต
ขั้นตอนที่ 1 เข้าสู่ DeepKE/example/re/few-shot ดาวน์โหลดชุดข้อมูล
wget 120.27.214.45/Data/re/few_shot/data.tar.gz
tar -xzvf data.tar.gz ขั้นตอนที่ 2 การฝึกอบรม
data และโฟลเดอร์ conf ตามลำดับtrain_from_saved_model ใน conf/train.yaml เป็นพาธที่บันทึกโมเดลที่ได้รับการฝึกครั้งล่าสุด และบันทึกการบันทึกเส้นทางที่สร้างขึ้นในการฝึกอบรมสามารถปรับแต่งได้โดย log_dir python run.pyการทำนาย ขั้นที่ 3
python predict.py เอกสาร
ขั้นตอนที่ 1 เข้าสู่ DeepKE/example/re/document ดาวน์โหลดชุดข้อมูล
wget 120.27.214.45/Data/re/document/data.tar.gz
tar -xzvf data.tar.gz ขั้นตอนที่ 2 การฝึกอบรม
data และโฟลเดอร์ conf ตามลำดับtrain_from_saved_model ใน conf/train.yaml เป็นพาธที่บันทึกโมเดลที่ได้รับการฝึกครั้งล่าสุด และบันทึกการบันทึกเส้นทางที่สร้างขึ้นในการฝึกอบรมสามารถปรับแต่งได้โดย log_dir python run.pyการทำนาย ขั้นที่ 3
python predict.pyมัลติโมดัล
ขั้นตอนที่ 1 เข้าสู่ DeepKE/example/re/multimodal ดาวน์โหลดชุดข้อมูล
wget 120.27.214.45/Data/re/multimodal/data.tar.gz
tar -xzvf data.tar.gzเราใช้วัตถุที่ตรวจพบ RCNN และวัตถุการต่อสายดินที่มองเห็นจากภาพต้นฉบับเป็นข้อมูลภาพในเครื่อง โดยที่ RCNN ผ่านทาง fast_rcnn และการต่อสายดินด้วยภาพผ่านทาง onestage_grounding
ขั้นตอนที่ 2 การฝึกอบรม
data และโฟลเดอร์ conf ตามลำดับload_path ใน conf/train.yaml เป็นพาธที่บันทึกโมเดลที่ได้รับการฝึกครั้งล่าสุด และบันทึกการบันทึกเส้นทางที่สร้างขึ้นในการฝึกอบรมสามารถปรับแต่งได้โดย log_dir python run.pyการทำนาย ขั้นที่ 3
python predict.pyการแยกแอตทริบิวต์คือการแยกแอตทริบิวต์สำหรับเอนทิตีในข้อความที่ไม่มีคำสั่ง
ข้อมูลจะถูกจัดเก็บไว้ในไฟล์ . .csv บางกรณีดังต่อไปนี้:
| ประโยค | เรียน | กิจการ | เอนต์_ออฟเซ็ต | วาล | Val_offset |
|---|---|---|---|---|---|
| 张冬梅,女,汉族,1968年2月生,河南淇县人 | 民族 | 张冬梅 | 0 | 汉族 | 6 |
| 诸葛亮,字孔明,三孔时期杰出的军事家、文学家、发明家。 | 朝代 | 诸葛亮 | 0 | 三国时期 | 8 |
| 2014年10月1日许鞍华执导的电影《黄金时代》上映 | 上映时间 | 黄金时代 | 19 | 10 มีนาคม 2014 | 0 |
อ่านกระบวนการโดยละเอียดใน README เฉพาะ
มาตรฐาน (ควบคุมอย่างเต็มที่)
ขั้นตอนที่ 1 เข้าสู่โฟลเดอร์ DeepKE/example/ae/standard ดาวน์โหลดชุดข้อมูล
wget 120.27.214.45/Data/ae/standard/data.tar.gz
tar -xzvf data.tar.gz ขั้นตอนที่ 2 การฝึกอบรม
ชุดข้อมูลและพารามิเตอร์สามารถปรับแต่งได้ในโฟลเดอร์ data และโฟลเดอร์ conf ตามลำดับ
python run.pyการทำนาย ขั้นที่ 3
python predict.py.tsv บางกรณีจะเป็นดังนี้:| ประโยค | ประเภทเหตุการณ์ | สิ่งกระตุ้น | บทบาท | การโต้แย้ง | |
|---|---|---|---|---|---|
| 据《欧洲时报》报道,当地时间27日,法巴黎卢浮宫博物馆员工因不满工作条件恶化而罢工,导致该博物馆也因此闭门谢客一天。 | 组织行为-罢工 | 罢工 | 罢工人员 | 法巴黎卢浮宫博物馆员工 | |
| 时间 | 当地时间27日 | ||||
| 所属组织 | 法巴黎卢浮宫博物馆 | ||||
| 中外运2019年上半年归母净利润增长17%:收购了少数股东股权 | 财经/交易-出售/收购 | 收购 | 出售方 | 少数股东 | |
| 收购方 | 中外运 | ||||
| 交易物 | 股权 | ||||
| 飞行员弹射出舱并安全着陆,事故没有造成人员伤亡。 | 灾害/意外-坠机 | 坠机 | 时间 | 13วัน | |
| 地点 | 阿兰亚特兰 | ||||
อ่านกระบวนการโดยละเอียดใน README เฉพาะ
มาตรฐาน (ควบคุมอย่างเต็มที่)
ขั้นตอนที่ 1 เข้าสู่โฟลเดอร์ DeepKE/example/ee/standard ดาวน์โหลดชุดข้อมูล
wget 120.27.214.45/Data/ee/DuEE.zip
unzip DuEE.zipขั้นตอนที่ 2 การฝึกอบรม
ชุดข้อมูลและพารามิเตอร์สามารถปรับแต่งได้ในโฟลเดอร์ data และโฟลเดอร์ conf ตามลำดับ
python run.pyขั้นตอนที่ 3 การทำนาย
python predict.py 1. Using nearest mirror THU ในประเทศจีน จะช่วยเร่งการติดตั้ง อนาคอนด้า aliyun ในประเทศจีนจะเร่งความเร็ว pip install XXX
2.เมื่อพบ ModuleNotFoundError: No module named 'past' ให้รัน pip install future
3. การติดตั้งโมเดลภาษาที่ได้รับการฝึกอบรมออนไลน์ช้า แนะนำให้ดาวน์โหลดโมเดลที่ฝึกไว้ล่วงหน้าก่อนใช้งานและบันทึกไว้ในโฟลเดอร์ pretrained อ่าน README.md ในทุกไดเร็กทอรีงานเพื่อตรวจสอบข้อกำหนดเฉพาะสำหรับการบันทึกโมเดลที่ได้รับการฝึกล่วงหน้า
4.DeepKE เวอร์ชันเก่าอยู่ในสาขา deepke-v1.0 ผู้ใช้สามารถเปลี่ยนสาขาไปใช้เวอร์ชันเก่าได้ เวอร์ชันเก่าได้ถูกถ่ายโอนไปยังการแยกความสัมพันธ์มาตรฐานโดยสิ้นเชิง (ตัวอย่าง/ใหม่/มาตรฐาน)
5.หากคุณต้องการแก้ไขซอร์สโค้ด แนะนำให้ติดตั้ง DeepKE ด้วยซอร์สโค้ด ถ้าไม่เช่นนั้น การปรับเปลี่ยนจะไม่ทำงาน ดูปัญหา
6. สามารถพบงานการดึงความรู้ที่มีทรัพยากรต่ำที่เกี่ยวข้องเพิ่มเติมได้ใน การดึงความรู้ในสถานการณ์ที่มีทรัพยากรต่ำ: การสำรวจและมุมมอง
7.ตรวจสอบให้แน่ใจว่ามีข้อกำหนดเวอร์ชันที่แน่นอนใน requirements.txt
ในเวอร์ชันถัดไป เราวางแผนที่จะเปิดตัว LLM ที่แข็งแกร่งยิ่งขึ้นสำหรับ KE
ในขณะเดียวกัน เราจะเสนอการบำรุงรักษาระยะยาวเพื่อ แก้ไขข้อบกพร่อง แก้ไขปัญหา และตอบสนอง คำขอใหม่ ดังนั้นหากคุณมีปัญหาใด ๆ โปรดแจ้งปัญหาให้เราทราบ
การสร้างกราฟความรู้ที่มีประสิทธิภาพข้อมูล, 高效知识谱构建 (บทช่วยสอนเกี่ยวกับ CCKS 2022) [สไลด์]
การสร้างกราฟความรู้ที่มีประสิทธิภาพและแข็งแกร่ง (บทช่วยสอนเกี่ยวกับ AACL-IJCNLP 2022) [สไลด์]
ครอบครัว PromptKG: คลังภาพการเรียนรู้แบบพร้อมท์และงานวิจัย ชุดเครื่องมือ และรายการเอกสารที่เกี่ยวข้องกับ KG [แหล่งข้อมูล]
การดึงความรู้ในสถานการณ์ที่มีทรัพยากรต่ำ: การสำรวจและมุมมอง [แบบสำรวจ] [รายการกระดาษ]
Doccano、MarkTool、LabelStudio: ชุดเครื่องมือคำอธิบายประกอบข้อมูล
LambdaKG: ไลบรารีและเกณฑ์มาตรฐานสำหรับการฝัง KG ที่ใช้ PLM
EasyInstruct: เฟรมเวิร์กที่ใช้งานง่ายเพื่อสั่งสอนโมเดลภาษาขนาดใหญ่
สื่อการอ่าน :
การสร้างกราฟความรู้ที่มีประสิทธิภาพข้อมูล, 高效知识谱构建 (บทช่วยสอนเกี่ยวกับ CCKS 2022) [สไลด์]
การสร้างกราฟความรู้ที่มีประสิทธิภาพและแข็งแกร่ง (บทช่วยสอนเกี่ยวกับ AACL-IJCNLP 2022) [สไลด์]
ครอบครัว PromptKG: คลังภาพการเรียนรู้แบบพร้อมท์และงานวิจัย ชุดเครื่องมือ และรายการเอกสารที่เกี่ยวข้องกับ KG [แหล่งข้อมูล]
การดึงความรู้ในสถานการณ์ที่มีทรัพยากรต่ำ: การสำรวจและมุมมอง [แบบสำรวจ] [รายการกระดาษ]
ชุดเครื่องมือที่เกี่ยวข้อง :
Doccano、MarkTool、LabelStudio: ชุดเครื่องมือคำอธิบายประกอบข้อมูล
LambdaKG: ไลบรารีและเกณฑ์มาตรฐานสำหรับการฝัง KG ที่ใช้ PLM
EasyInstruct: เฟรมเวิร์กที่ใช้งานง่ายเพื่อสั่งสอนโมเดลภาษาขนาดใหญ่
โปรดอ้างอิงเอกสารของเราหากคุณใช้ DeepKE ในงานของคุณ
@inproceedings { EMNLP2022_Demo_DeepKE ,
author = { Ningyu Zhang and
Xin Xu and
Liankuan Tao and
Haiyang Yu and
Hongbin Ye and
Shuofei Qiao and
Xin Xie and
Xiang Chen and
Zhoubo Li and
Lei Li } ,
editor = { Wanxiang Che and
Ekaterina Shutova } ,
title = { DeepKE: {A} Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population } ,
booktitle = { {EMNLP} (Demos) } ,
pages = { 98--108 } ,
publisher = { Association for Computational Linguistics } ,
year = { 2022 } ,
url = { https://aclanthology.org/2022.emnlp-demos.10 }
}หนิงหยู จาง, ห่าวเฟิน หวาง, เฟย ฮวง, เฟยหยู ซิออง, เหลียนควน เถา, ซิน ซู, หงห่าว กุ้ย, เจิ้นหรู่ จาง, ฉวนฉี ตัน, เฉียง เฉิน, เสี่ยวฮั่น หวาง, เจ๋อคุน ซี, ซินหรง ลี, ไห่หยาง หยู, หงปิน เย่, ซวเฟย เฉียว, เผิง หวาง , Yuqi Zhu, Xin Xie, Xiang Chen, Zhoubo Li, Lei Li, เสี่ยวจวนเหลียง, หยุนจื้อ เหยา, จิง เฉิน, หยูฉี จู, ชูหมิน เติ้ง, เหวิน จาง, กัวโจว เจิ้ง, ฮวาจุน เฉิน
ผู้ร่วมให้ข้อมูลในชุมชน: thredreams, eltociear, Ziwen Xu, Rui Huang, Xiaolong Weng


