หน้าโครงการ | กระดาษ | การ์ดโมเดล ?
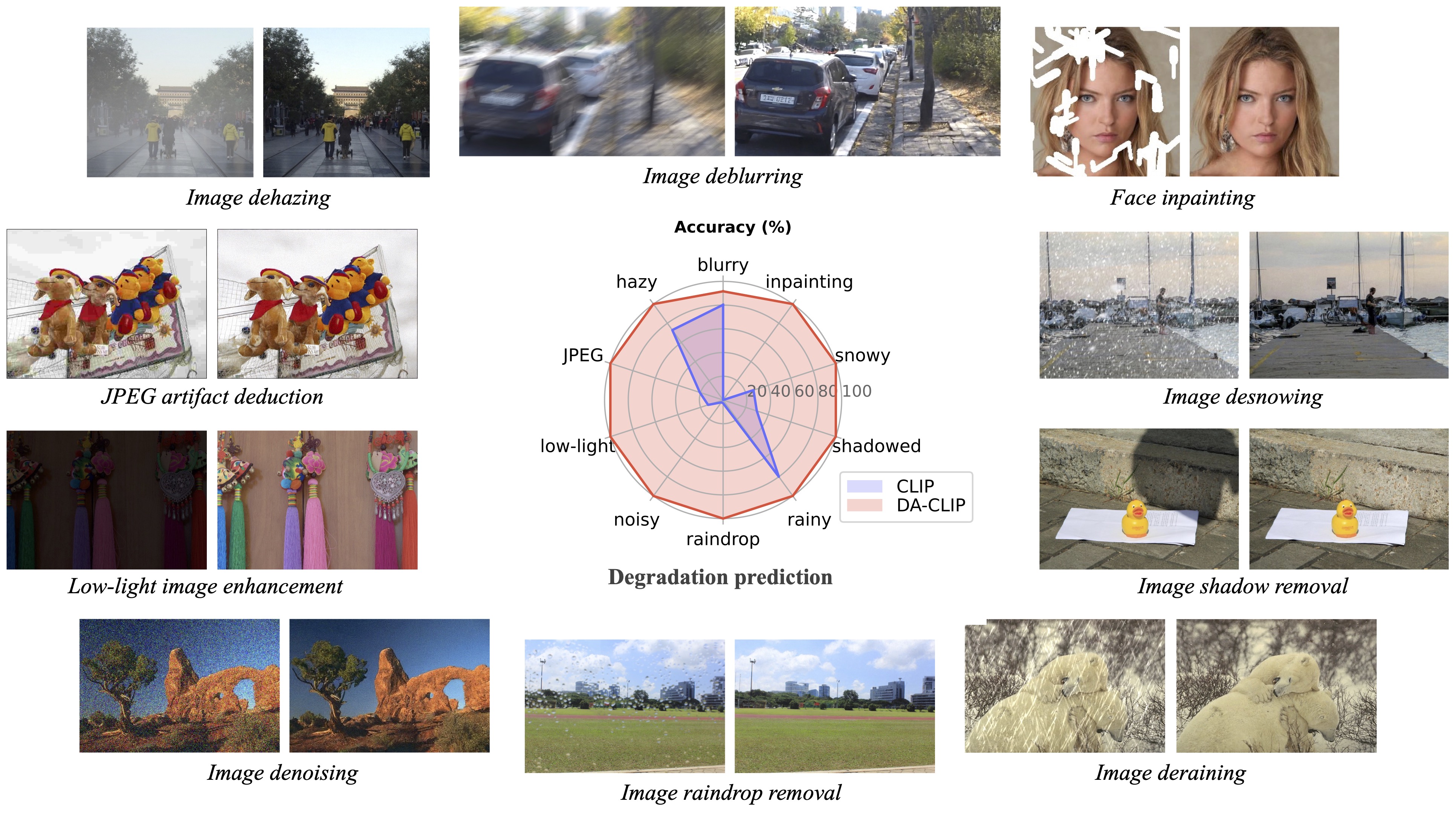
งานติดตามผลของเรา การฟื้นฟูภาพที่เหมือนจริงด้วยภาพถ่ายในป่าด้วยโมเดลภาษาการมองเห็นที่ควบคุม (CVPRW 2024) นำเสนอการสุ่มตัวอย่างด้านหลังเพื่อการสร้างภาพที่ดีขึ้น และจัดการกับภาพที่เสื่อมโทรมแบบผสมในโลกแห่งความเป็นจริง ซึ่งคล้ายกับ Real-ESRGAN
[ 2024.04.16 ] บทความติดตามผลของเราเรื่อง "การฟื้นฟูภาพที่สมจริงด้วยภาพถ่ายในป่าด้วยโมเดลภาษาการมองเห็นที่ควบคุม" อยู่ใน ArXiv แล้ว!
[ 2024.04.15 ] อัปเดตโมเดล wild-IR สำหรับการเสื่อมสภาพในโลกแห่งความเป็นจริง และการสุ่มตัวอย่างภายหลังเพื่อการสร้างภาพที่ดีขึ้น ตุ้มน้ำหนักที่ฝึกล่วงหน้า wild-ir.pth และ wild-daclip_ViT-L-14.pt ยังมีให้สำหรับ wild-ir อีกด้วย
[ 2024.01.20 ] ??? กระดาษ DA-CLIP ของเราได้รับการยอมรับจาก ICLR 2024 ??? นอกจากนี้เรายังมีโมเดลที่แข็งแกร่งยิ่งขึ้นในการ์ดโมเดลอีกด้วย
[ 2023.10.25 ] เพิ่มลิงก์ชุดข้อมูลสำหรับการฝึกอบรมและการทดสอบ
[ 2023.10.13 ] เพิ่มการสาธิตการจำลองและ API ขอบคุณ @chenxwh!!! เราได้อัปเดตการสาธิต Hugging Face และการสาธิต Colab ออนไลน์ ขอบคุณ @fffiloni และ @camenduru !!! เรายังสร้างการ์ดโมเดลใน Hugging Face อีกด้วย ? และยกตัวอย่างการทดสอบเพิ่มเติม
[ 2023.10.09 ] น้ำหนักที่ฝึกไว้ล่วงหน้า ของรุ่น DA-CLIP และ Universal IR ได้รับการเผยแพร่ใน link1 และ link2 ตามลำดับ นอกจากนี้เรายังมีไฟล์แอป Gradio สำหรับกรณีที่คุณต้องการทดสอบภาพของคุณเอง
ระบบปฏิบัติการ: อูบุนตู 20.04
NVIDIA:
คิวดา: 11.4
หลาม 3.8
เราขอแนะนำให้คุณสร้างสภาพแวดล้อมเสมือนจริงก่อนด้วย:
python3 -m venv .envsource .env/bin/activate pip ติดตั้ง -U pip pip ติดตั้ง -r ข้อกำหนด.txt
เข้าสู่ไดเร็กทอรี universal-image-restoration และเรียกใช้:
นำเข้า torchfrom PIL นำเข้า Imageimport open_clipcheckpoint = 'pretrained/daclip_ViT-B-32.pt'model, preprocess = open_clip.create_model_from_pretrained('daclip_ViT-B-32', pretrained=checkpoint)tokenizer = open_clip.get_tokenizer('ViT-B-32 ')ภาพ= การประมวลผลล่วงหน้า (Image.open("haze_01.png")).unsqueeze(0)degradations = ['motion-blurry','hazy','jpeg-compressed','low-light','noisy','raindrop' ,'ฝนตก','เงา','เต็มไปด้วยหิมะ','ยังไม่เสร็จสมบูรณ์']text = tokenizer(การย่อยสลาย) ด้วย torch.no_grad(), torch.cuda.amp.autocast():text_features = model.encode_text(text)image_features, degra_features = model.encode_image(image, control=True)degra_features /= degra_features.norm(dim=-1, Keepdim=True)text_features / = text_features.norm(สลัว=-1, Keepdim=True)text_probs = (100.0 * degra_features @ text_features.T).softmax(dim=-1)index = torch.argmax(text_probs[0])พิมพ์(f"งาน: {task_name}: {degradations[index]} - {text_probs[0][ดัชนี]}")การเตรียมชุดข้อมูลรถไฟและการทดสอบตามส่วนการสร้างชุดข้อมูลกระดาษของเราเป็น:
#### สำหรับชุดข้อมูลการฝึกอบรม ######## (ยังไม่สมบูรณ์หมายถึงกำลังอยู่ในการวาดภาพ) ####ชุดข้อมูล/universal/train|--motion-blurry| |--LQ/*.png| |--GT/*.png|--หมอก|--jpeg-บีบอัด|--แสงน้อย|--มีเสียงดัง|--น้ำฝน|--ฝนตก|--มีเงา|--หิมะตก|--ยังไม่เสร็จสมบูรณ์## ## สำหรับทดสอบชุดข้อมูล ######## (โครงสร้างเดียวกับรถไฟ) ####datasets/universal/val ...#### สำหรับคำบรรยายที่ชัดเจน ####datasets/universal/daclip_train.csv ชุดข้อมูล/universal/daclip_val.csv
จากนั้นเข้าไปในไดเร็กทอรี universal-image-restoration/config/daclip-sde และแก้ไขพาธชุดข้อมูลในไฟล์ตัวเลือกใน options/train.yml และ options/test.yml
คุณสามารถเพิ่มงานหรือชุดข้อมูลเพิ่มเติมให้กับทั้งไดเร็กทอรี train และ val และเพิ่มคำว่า degradation ลงใน distortion
| การย่อยสลาย | การเคลื่อนไหวพร่ามัว | หมอก | JPEG บีบอัด* | แสงน้อย | มีเสียงดัง* (เหมือนกับ jpeg) |
|---|---|---|---|---|---|
| ชุดข้อมูล | โกโปร | ที่อยู่อาศัย-6k | DIV2K+Flickr2K | ฮ่าๆ | DIV2K+Flickr2K |
| การย่อยสลาย | น้ำฝน | ฝนตก | มีเงา | เต็มไปด้วยหิมะ | ยังไม่เสร็จ |
|---|---|---|---|---|---|
| ชุดข้อมูล | น้ำฝน | Rain100H: ฝึก ทดสอบ | สรด | หิมะ100K | เซเลบาHQ-256 |
คุณควร แยกเฉพาะชุดข้อมูลรถไฟสำหรับการฝึกอบรม และ ชุดข้อมูลการตรวจสอบ ทั้งหมดสามารถดาวน์โหลดได้ใน Google ไดรฟ์ สำหรับชุดข้อมูล jpeg และเสียงรบกวน คุณสามารถสร้างอิมเมจ LQ ได้โดยใช้สคริปต์นี้
ดู DA-CLIP.md สำหรับรายละเอียด
รหัสหลักสำหรับการฝึกอบรมอยู่ใน universal-image-restoration/config/daclip-sde และเครือข่ายหลักสำหรับ DA-CLIP อยู่ใน universal-image-restoration/open_clip/daclip_model.py
ใส่ตุ้ม น้ำหนัก DA-CLIP ที่ผ่านการฝึกอบรมแล้วลงในไดเร็กทอรี pretrained และตรวจสอบเส้นทาง daclip
จากนั้นคุณสามารถฝึกโมเดลตามสคริปต์ทุบตีด้านล่าง:
cd universal-image-restoration/config/daclip-sde# สำหรับ GPU เดี่ยว: python3 train.py -opt=options/train.yml# สำหรับการฝึกอบรมแบบกระจาย จำเป็นต้องเปลี่ยน gpu_ids ในตัวเลือก filepython3 -m torch.distributed.launch - -nproc_per_node=2 --master_port=4321 train.py -opt=options/train.yml --launcher pytorch
โมเดลและบันทึกการฝึกอบรมจะบันทึกไว้ใน log/universal-ir คุณสามารถพิมพ์บันทึกของคุณได้ตลอดเวลาโดยเรียกใช้ tail -f log/universal-ir/train_universal-ir_***.log -n 100
ขั้นตอนการฝึกอบรมเดียวกันนี้สามารถใช้สำหรับการฟื้นฟูภาพในป่า (wild-ir)
| ชื่อรุ่น | คำอธิบาย | Googleไดรฟ์ | กอดใบหน้า |
|---|---|---|---|
| ดา-คลิป | โมเดล CLIP ที่รับรู้ถึงการย่อยสลาย | ดาวน์โหลด | ดาวน์โหลด |
| สากล-IR | โมเดลการฟื้นฟูอิมเมจสากลที่ใช้ DA-CLIP | ดาวน์โหลด | ดาวน์โหลด |
| DA-CLIP-มิกซ์ | โมเดล CLIP ที่รับรู้ถึงการเสื่อมสภาพ (เพิ่มการเบลอแบบเกาส์เซียน + การระบายสีใบหน้า และการเบลอแบบเกาส์เซียน + ฝนตก) | ดาวน์โหลด | ดาวน์โหลด |
| Universal-IR-มิกซ์ | โมเดลการฟื้นฟูอิมเมจสากลที่ใช้ DA-CLIP (เพิ่มการฝึกที่แข็งแกร่งและการย่อยสลายแบบผสม) | ดาวน์โหลด | ดาวน์โหลด |
| เถื่อน-DA-CLIP | แบบจำลอง CLIP ที่รับรู้ถึงการย่อยสลายในป่า (ViT-L-14) | ดาวน์โหลด | ดาวน์โหลด |
| ป่า-IR | แบบจำลองการกู้คืนรูปภาพที่ใช้ DA-CLIP ในป่า | ดาวน์โหลด | ดาวน์โหลด |
เพื่อประเมินวิธีการของเราในการฟื้นฟูอิมเมจ โปรดแก้ไขพาธมาตรฐานและพาธโมเดลแล้วรัน
cd universal-image-restoration/config/universal-ir.cd หลาม test.py -opt=options/test.yml
ที่นี่เรามีไฟล์ app.py สำหรับทดสอบภาพของคุณเอง ก่อนหน้านั้น คุณจะต้องดาวน์โหลดตุ้มน้ำหนักที่ฝึกไว้ล่วงหน้า (DA-CLIP และ UIR) และแก้ไขพาธโมเดลใน options/test.yml จากนั้นเพียงเรียกใช้ python app.py คุณสามารถเปิด http://localhost:7860 เพื่อทดสอบโมเดลได้ (เรายังจัดเตรียมภาพหลายภาพที่มีการเสื่อมสภาพที่แตกต่างกันใน dir images ) นอกจากนี้เรายังให้ตัวอย่างเพิ่มเติมจากชุดข้อมูลทดสอบของเราใน Google ไดรฟ์
ขั้นตอนเดียวกันนี้สามารถใช้สำหรับการฟื้นฟูภาพในป่า (wild-ir)
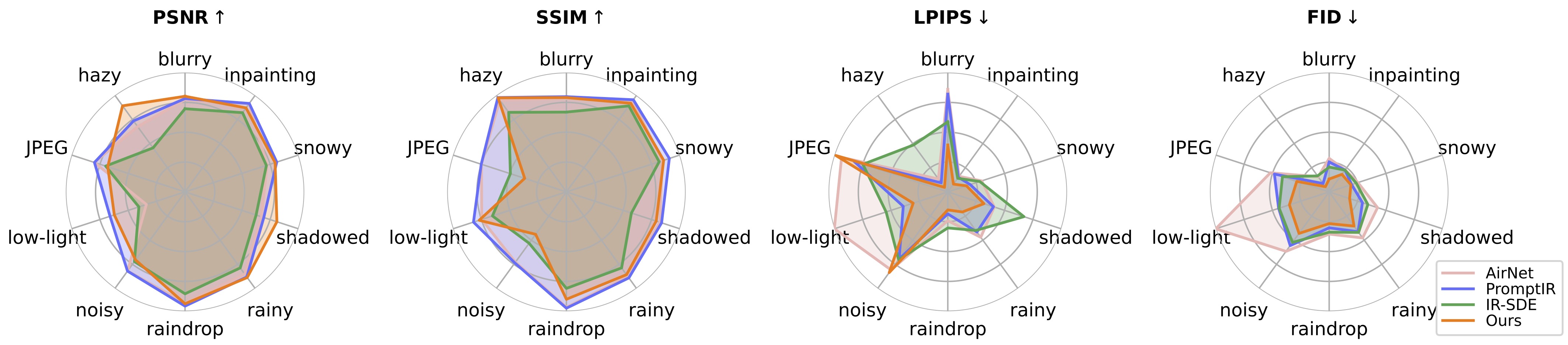



- ในการทดสอบ เราพบว่าโมเดลที่ได้รับการฝึกล่วงหน้าในปัจจุบันยังคงยากต่อการประมวลผลภาพในโลกแห่งความเป็นจริงบางภาพ ซึ่งอาจมีการเปลี่ยนแปลงการกระจายด้วยชุดข้อมูลการฝึกของเรา (ถ่ายจากอุปกรณ์ที่แตกต่างกัน หรือมีความละเอียดหรือการย่อยสลายที่แตกต่างกัน) เราถือว่าเป็นงานในอนาคตและจะพยายามทำให้แบบจำลองของเราใช้งานได้จริงมากขึ้น! นอกจากนี้เรายังสนับสนุนให้ผู้ใช้ที่สนใจงานของเราฝึกโมเดลของตนเองด้วยชุดข้อมูลขนาดใหญ่และประเภทการย่อยสลายที่มากขึ้น
- อย่างไรก็ตาม เรายังพบว่าการปรับขนาดรูปภาพอินพุตโดยตรงจะทำให้งานส่วนใหญ่มีประสิทธิภาพต่ำ เราอาจลองเพิ่มขั้นตอนการปรับขนาดลงในการฝึกได้ แต่มักจะทำลายคุณภาพของภาพเนื่องจากการสอดแทรก
- สำหรับงานการลงสี โมเดลปัจจุบันของเรารองรับเฉพาะการลงสีใบหน้าเท่านั้น เนื่องจากข้อจำกัดของชุดข้อมูล เรามีตัวอย่างมาสก์ของเรา และคุณสามารถใช้สคริปต์ Generate_masked_face เพื่อสร้างใบหน้าที่ยังไม่เสร็จสมบูรณ์ได้
กิตติกรรมประกาศ: DA-CLIP ของเราใช้ IR-SDE และ open_clip ขอบคุณสำหรับรหัสของพวกเขา!
หากคุณมีคำถามใด ๆ โปรดติดต่อ: [email protected]
หากรหัสของเราช่วยในการค้นคว้าหรืองานของคุณ โปรดพิจารณาอ้างอิงเอกสารของเรา ต่อไปนี้เป็นข้อมูลอ้างอิง BibTeX:
@article{luo2023controlling,
title={Controlling Vision-Language Models for Universal Image Restoration},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2310.01018},
year={2023}
}
@article{luo2024photo,
title={Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2404.09732},
year={2024}
}

