กรอบการทำงานสำหรับการฝึกอบรมโมเดลรากฐานต่อเนื่องหลายรูปแบบแบบใดก็ได้
ปรับขนาดได้ โอเพ่นซอร์ส ในรูปแบบและงานต่างๆ มากมาย
อีพีเอฟแอล - Apple
Website | BibTeX | ? Demo
การใช้งานอย่างเป็นทางการและโมเดลที่ได้รับการฝึกอบรมล่วงหน้าสำหรับ:
4M: การสร้างแบบจำลองมาสก์หลายรูปแบบจำนวนมาก , NeurIPS 2023 (สปอตไลท์)
เดวิด มิซราฮี*, โรมัน บาคมันน์*, โอกูซาน ฟาติห์ การ์, เทเรซา โย, หมิงเฟย เกา, อัฟชิน เดห์กัน, อามีร์ ซามีร์
4M-21: โมเดลการมองเห็นแบบใดก็ได้สำหรับงานและรูปแบบต่างๆ มากมาย NeurIPS 2024
โรมัน บาคมันน์*, โอกูซาน ฟาติห์ การ์*, เดวิด มิซราฮี*, อาลี การ์จานี, หมิงเฟย เกา, เดวิด กริฟฟิธส์, เจียหมิง หู, อัฟชิน เดห์กัน, อามีร์ ซามีร์
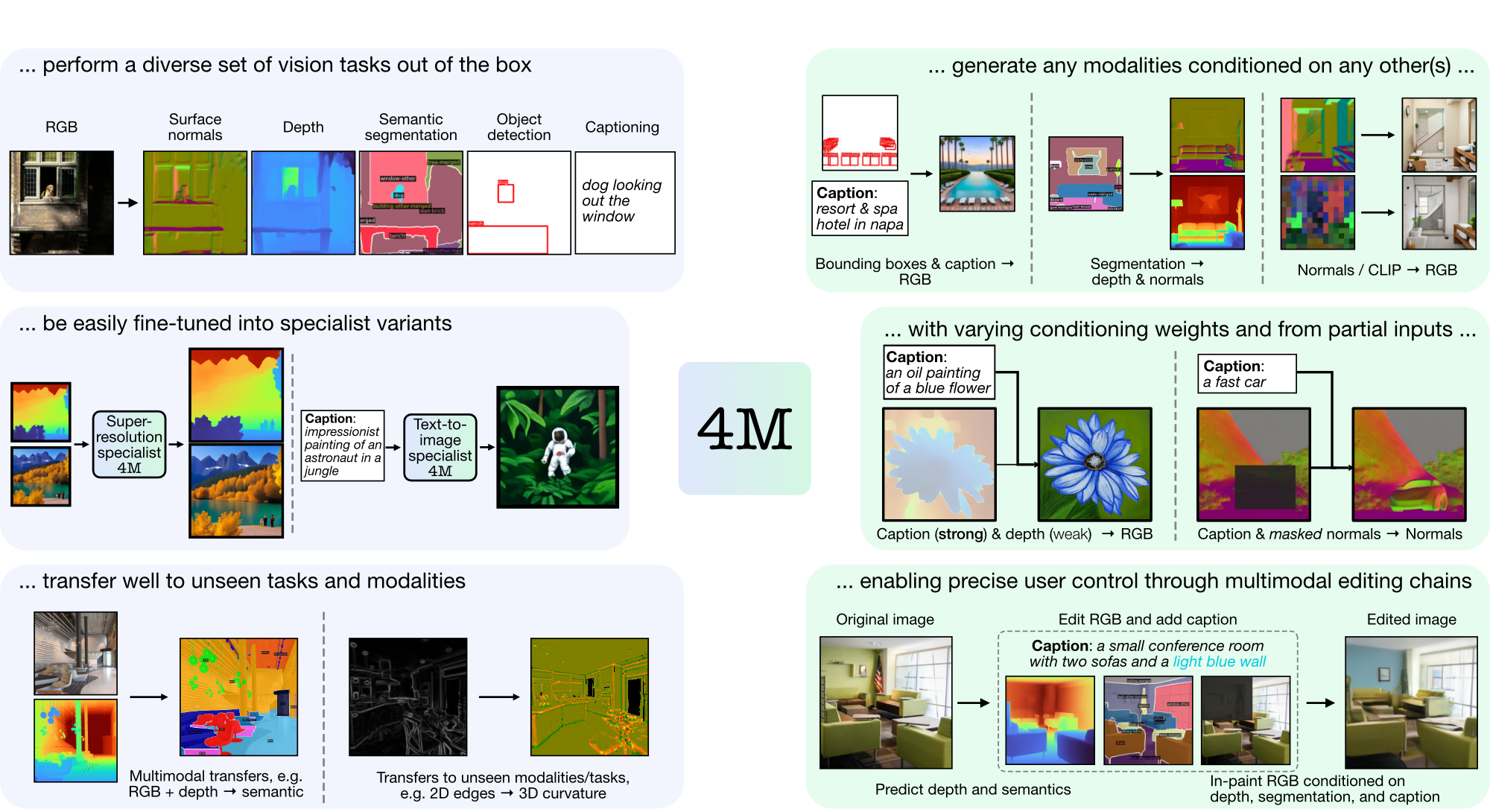
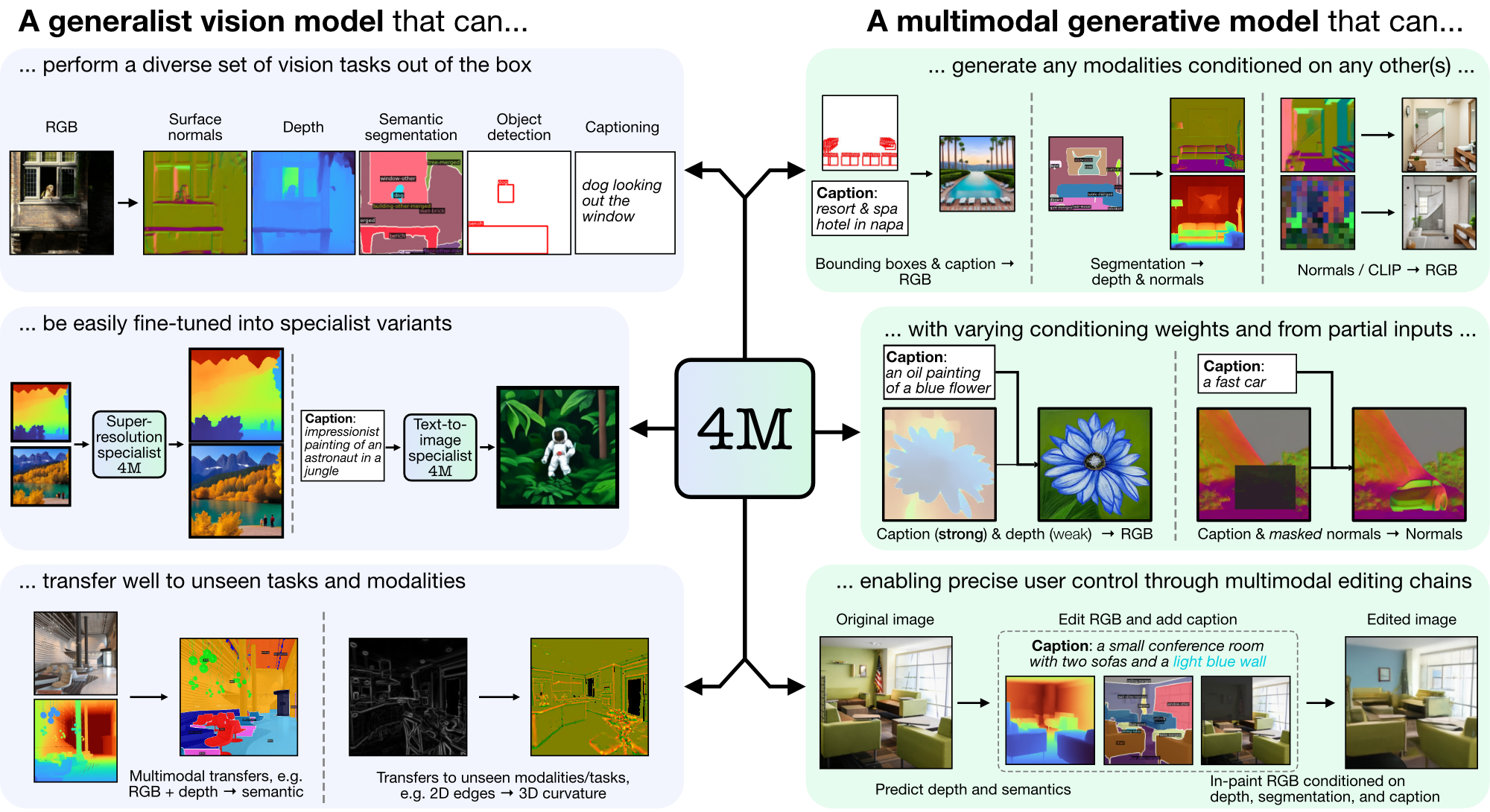
4M เป็นกรอบการทำงานสำหรับการฝึกอบรมโมเดลพื้นฐาน "แบบใดก็ได้" โดยใช้โทเค็นและการมาสก์เพื่อขยายขนาดเป็นวิธีการที่หลากหลาย โมเดลที่ได้รับการฝึกโดยใช้ 4M สามารถทำงานด้านการมองเห็นได้หลากหลาย ถ่ายโอนไปยังงานที่มองไม่เห็นและรูปแบบต่างๆ ได้ดี และเป็นโมเดลกำเนิดหลายรูปแบบที่ยืดหยุ่นและควบคุมทิศทางได้ เรากำลังเปิดตัวโค้ดและโมเดลสำหรับ "4M: Massively Multimodal Masked Modeling" (ในที่นี้หมายถึง 4M-7) เช่นเดียวกับ "4M-21: โมเดลการมองเห็นแบบใดก็ได้สำหรับสิบงานและรูปแบบ" (ในที่นี้เรียกว่า 4M -21)
git clone https://github.com/apple/ml-4m
cd ml-4m
conda create -n fourm python=3.9 -y
conda activate fourm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# Run in Python shell
import torch
print(torch.cuda.is_available()) # Should return True
หากไม่มี CUDA ให้ลองติดตั้ง PyTorch ใหม่ตามคำแนะนำในการติดตั้งอย่างเป็นทางการ ในทำนองเดียวกัน หากคุณต้องการติดตั้ง xFormers (เป็นทางเลือก สำหรับโทเค็นที่เร็วกว่า) ให้ปฏิบัติตาม README เพื่อให้แน่ใจว่าเวอร์ชัน CUDA ถูกต้อง
เรามี wrapper สาธิตเพื่อเริ่มต้นอย่างรวดเร็วด้วยการใช้โมเดล 4M สำหรับงาน RGB-to-all หรือ {caption, bounding Boxes}-to-all Generation ตัวอย่างเช่น หากต้องการสร้างรังสีทั้งหมดจากอินพุต RGB ที่กำหนด ให้โทร:
from fourm . demo_4M_sampler import Demo4MSampler , img_from_url
sampler = Demo4MSampler ( fm = 'EPFL-VILAB/4M-21_XL' ). cuda ()
img = img_from_url ( 'https://storage.googleapis.com/four_m_site/images/demo_rgb.png' ) # 1x3x224x224 ImageNet-standardized PyTorch Tensor
preds = sampler ({ 'rgb@224' : img . cuda ()}, seed = None )
sampler . plot_modalities ( preds , save_path = None )คุณควรคาดหวังที่จะเห็นผลลัพธ์ดังต่อไปนี้:


สำหรับการแสดงคำบรรยายสำหรับทุกรุ่น คุณสามารถแทนที่อินพุตตัวอย่างด้วย: preds = sampler({'caption': 'A lake house with a boat in front [S_1]'}) สำหรับรายการรุ่น 4M ที่มีจำหน่าย โปรดดูสวนสัตว์จำลองด้านล่าง และดู README_GENERATION.md สำหรับคำแนะนำเพิ่มเติมเกี่ยวกับการสร้าง
ดูคำแนะนำเกี่ยวกับวิธีการเตรียมชุดข้อมูลต่อเนื่องหลายรูปแบบที่ README_DATA.md
ดู README_TOKENIZATION.md สำหรับคำแนะนำเกี่ยวกับวิธีการฝึกโทเค็นไนเซอร์เฉพาะรูปแบบ
ดู README_TRAINING.md สำหรับคำแนะนำเกี่ยวกับวิธีการฝึกโมเดล 4M
ดู README_GENERATION.md สำหรับคำแนะนำเกี่ยวกับวิธีใช้โมเดล 4M สำหรับการอนุมาน / การสร้าง นอกจากนี้เรายังจัดเตรียมสมุดบันทึกรุ่นที่ประกอบด้วยตัวอย่างสำหรับการอนุมาน 4M โดยเฉพาะการดำเนินการสร้างภาพตามเงื่อนไขและงานการมองเห็นทั่วไป (เช่น RGB-to-All)
เรามีจุดตรวจสอบ 4M และโทเค็นเซอร์เป็นตัวป้องกัน และยังให้การโหลดที่ง่ายดายผ่าน Hugging Face Hub
| แบบอย่าง | #มด. | ชุดข้อมูล | #พาราม | การกำหนดค่า | ตุ้มน้ำหนัก |
|---|---|---|---|---|---|
| 4M-B | 7 | CC12M | 198ม | การกำหนดค่า | ด่าน / HF Hub |
| 4M-B | 7 | โคโย700เอ็ม | 198ม | การกำหนดค่า | ด่าน / HF Hub |
| 4M-B | 21 | CC12M+โคโย700M+C4 | 198ม | การกำหนดค่า | ด่าน / HF Hub |
| 4M-L | 7 | CC12M | 705ม | การกำหนดค่า | ด่าน / HF Hub |
| 4M-L | 7 | โคโย700เอ็ม | 705ม | การกำหนดค่า | ด่าน / HF Hub |
| 4M-L | 21 | CC12M+โคโย700M+C4 | 705ม | การกำหนดค่า | ด่าน / HF Hub |
| 4M-XL | 7 | CC12M | 2.8B | การกำหนดค่า | ด่าน / HF Hub |
| 4M-XL | 7 | โคโย700เอ็ม | 2.8B | การกำหนดค่า | ด่าน / HF Hub |
| 4M-XL | 21 | CC12M+โคโย700M+C4 | 2.8B | การกำหนดค่า | ด่าน / HF Hub |
วิธีโหลดโมเดลจาก Hugging Face Hub:
from fourm . models . fm import FM
fm7b_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_CC12M' )
fm7b_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_COYO700M' )
fm21b = FM . from_pretrained ( 'EPFL-VILAB/4M-21_B' )
fm7l_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_CC12M' )
fm7l_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_COYO700M' )
fm21l = FM . from_pretrained ( 'EPFL-VILAB/4M-21_L' )
fm7xl_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_CC12M' )
fm7xl_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_COYO700M' )
fm21xl = FM . from_pretrained ( 'EPFL-VILAB/4M-21_XL' )หากต้องการโหลดจุดตรวจด้วยตนเอง อันดับแรกดาวน์โหลดไฟล์ตัวป้องกันจากลิงก์ด้านบนแล้วโทร:
from fourm . utils import load_safetensors
from fourm . models . fm import FM
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
fm = FM ( config = config )
fm . load_state_dict ( ckpt )โมเดลเหล่านี้เริ่มต้นด้วยรุ่นมาตรฐาน 4M-7 CC12M แต่ยังคงฝึกฝนต่อไปโดยใช้รูปแบบผสมผสานที่มีอคติอย่างมากต่อการป้อนข้อความ พวกเขายังคงสามารถทำงานอื่นๆ ทั้งหมดได้ แต่ทำงานได้ดีกว่าในการสร้างข้อความเป็นรูปภาพ เมื่อเทียบกับรุ่นที่ไม่ได้รับการปรับแต่ง
| แบบอย่าง | #มด. | ชุดข้อมูล | #พาราม | การกำหนดค่า | ตุ้มน้ำหนัก |
|---|---|---|---|---|---|
| 4M-T2I-B | 7 | CC12M | 198ม | การกำหนดค่า | ด่าน / HF Hub |
| 4M-T2I-L | 7 | CC12M | 705ม | การกำหนดค่า | ด่าน / HF Hub |
| 4M-T2I-XL | 7 | CC12M | 2.8B | การกำหนดค่า | ด่าน / HF Hub |
วิธีโหลดโมเดลจาก Hugging Face Hub:
from fourm . models . fm import FM
fm7b_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_B_CC12M' )
fm7l_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_L_CC12M' )
fm7xl_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_XL_CC12M' )การโหลดด้วยตนเองจากจุดตรวจจะดำเนินการในลักษณะเดียวกับข้างต้นสำหรับรุ่นพื้นฐาน 4M
| แบบอย่าง | #มด. | ชุดข้อมูล | #พาราม | การกำหนดค่า | ตุ้มน้ำหนัก |
|---|---|---|---|---|---|
| 4M-SR-L | 7 | CC12M | 198ม | การกำหนดค่า | ด่าน / HF Hub |
วิธีโหลดโมเดลจาก Hugging Face Hub:
from fourm . models . fm import FM
fm7l_sr_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-SR_L_CC12M' )การโหลดด้วยตนเองจากจุดตรวจจะดำเนินการในลักษณะเดียวกับข้างต้นสำหรับรุ่นพื้นฐาน 4M
| กิริยา | ปณิธาน | จำนวนโทเค็น | ขนาดสมุดโค้ด | ตัวถอดรหัสการแพร่กระจาย | ตุ้มน้ำหนัก |
|---|---|---|---|---|---|
| RGB | 224-448 | 196-784 | 16k | ด่าน / HF Hub | |
| ความลึก | 224-448 | 196-784 | 8k | ด่าน / HF Hub | |
| ปกติ | 224-448 | 196-784 | 8k | ด่าน / HF Hub | |
| ขอบ (Canny, SAM) | 224-512 | 196-1024 | 8k | ด่าน / HF Hub | |
| การแบ่งส่วนความหมายของ COCO | 224-448 | 196-784 | 4k | ด่าน / HF Hub | |
| คลิป-B/16 | 224-448 | 196-784 | 8k | ด่าน / HF Hub | |
| ไดโนฟ2-B/14 | 224-448 | 256-1024 | 8k | ด่าน / HF Hub | |
| DINov2-B/14 (ทั่วโลก) | 224 | 16 | 8k | ด่าน / HF Hub | |
| ImageBind-H/14 | 224-448 | 256-1024 | 8k | ด่าน / HF Hub | |
| ImageBind-H/14 (ส่วนกลาง) | 224 | 16 | 8k | ด่าน / HF Hub | |
| อินสแตนซ์ SAM | - | 64 | 1000 | ด่าน / HF Hub | |
| ท่าโพสท่าของมนุษย์ 3 มิติ | - | 8 | 1000 | ด่าน / HF Hub |
วิธีโหลดโมเดลจาก Hugging Face Hub:
from fourm . vq . vqvae import VQVAE , DiVAE
# 4M-7 modalities
tok_rgb = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_rgb_16k_224-448' )
tok_depth = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_depth_8k_224-448' )
tok_normal = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_normal_8k_224-448' )
tok_semseg = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_semseg_4k_224-448' )
tok_clip = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_CLIP-B16_8k_224-448' )
# 4M-21 modalities
tok_edge = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_edge_8k_224-512' )
tok_dinov2 = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14_8k_224-448' )
tok_dinov2_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14-global_8k_16_224' )
tok_imagebind = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14_8k_224-448' )
tok_imagebind_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14-global_8k_16_224' )
sam_instance = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_sam-instance_1k_64' )
human_poses = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_human-poses_1k_8' )หากต้องการโหลดจุดตรวจด้วยตนเอง อันดับแรกดาวน์โหลดไฟล์ตัวป้องกันจากลิงก์ด้านบนแล้วโทร:
from fourm . utils import load_safetensors
from fourm . vq . vqvae import VQVAE , DiVAE
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
tok = VQVAE ( config = config ) # Or DiVAE for models with a diffusion decoder
tok . load_state_dict ( ckpt )รหัสในพื้นที่เก็บข้อมูลนี้เผยแพร่ภายใต้ลิขสิทธิ์ Apache 2.0 ตามที่พบในไฟล์ LICENSE
น้ำหนักโมเดลในพื้นที่เก็บข้อมูลนี้เผยแพร่ภายใต้สิทธิ์การใช้งานโค้ดตัวอย่างตามที่พบในไฟล์ LICENSE_WEIGHTS
หากคุณพบว่าพื้นที่เก็บข้อมูลนี้มีประโยชน์ โปรดพิจารณาอ้างอิงงานของเรา:
@inproceedings{4m,
title={{4M}: Massively Multimodal Masked Modeling},
author={David Mizrahi and Roman Bachmann and O{u{g}}uzhan Fatih Kar and Teresa Yeo and Mingfei Gao and Afshin Dehghan and Amir Zamir},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
}
@article{4m21,
title={{4M-21}: An Any-to-Any Vision Model for Tens of Tasks and Modalities},
author={Roman Bachmann and O{u{g}}uzhan Fatih Kar and David Mizrahi and Ali Garjani and Mingfei Gao and David Griffiths and Jiaming Hu and Afshin Dehghan and Amir Zamir},
journal={arXiv 2024},
year={2024},
}


