ai pizza
1.0.0
ถึงกระนั้นก็ไม่มีใครรู้ว่าเครื่องจักรสามารถสร้างสิ่งใหม่ได้หรือไม่ หรือจำกัดอยู่เพียงสิ่งที่รู้อยู่แล้วเท่านั้น แต่ถึงตอนนี้ ปัญญาประดิษฐ์สามารถแก้ปัญหาที่ซับซ้อนและวิเคราะห์ชุดข้อมูลที่ไม่มีโครงสร้างได้ พวกเราที่ Dodo ตัดสินใจทำการทดลอง เพื่อจัดระเบียบและอธิบายโครงสร้างบางสิ่งที่ถือว่าวุ่นวายและเป็นอัตวิสัยนั่นคือรสชาติ เราตัดสินใจใช้ปัญญาประดิษฐ์เพื่อค้นหาส่วนผสมที่แปลกประหลาดที่สุดที่คนส่วนใหญ่ถือว่าอร่อย
ด้วยความร่วมมือกับผู้เชี่ยวชาญจาก MIPT และ Skoltech เราได้สร้างปัญญาประดิษฐ์ที่วิเคราะห์สูตรอาหารมากกว่า 300,000 รายการและผลการวิจัยเกี่ยวกับส่วนผสมระดับโมเลกุลของส่วนผสมที่ดำเนินการโดยเคมบริดจ์และมหาวิทยาลัยอื่นๆ หลายแห่งในสหรัฐอเมริกา จากข้อมูลนี้ AI ได้เรียนรู้ที่จะค้นหาความเชื่อมโยงที่ไม่ชัดเจนระหว่างส่วนผสม และทำความเข้าใจวิธีจับคู่ส่วนผสม และการมีอยู่ของส่วนผสมแต่ละอย่างมีอิทธิพลต่อการรวมกันของส่วนผสมอื่นๆ ทั้งหมดอย่างไร
สำหรับโมเดลใดๆ ที่คุณต้องการข้อมูล นั่นเป็นเหตุผลที่เรารวบรวมสูตรการทำอาหารมากกว่า 300,000 สูตรในการฝึก AI ของเรา
ส่วนที่ยากไม่ใช่การรวบรวมพวกมัน แต่เพื่อให้พวกมันอยู่ในรูปแบบเดียวกัน ตัวอย่างเช่น พริกในสูตรอาหารจะแสดงเป็น "พริก" "พริก" "พริก" หรือแม้แต่ "พริก" สำหรับเราเห็นได้ชัดว่าสิ่งเหล่านี้หมายถึง "พริก" แต่โครงข่ายประสาทเทียมถือว่าแต่ละรายการเป็นเอนทิตีส่วนบุคคล
ในตอนแรก เรามีส่วนผสมที่ไม่ซ้ำกันมากกว่า 100,000 รายการ และหลังจากที่เราล้างข้อมูลแล้ว ก็เหลือตำแหน่งที่ไม่ซ้ำกันเพียง 1,000 ตำแหน่งเท่านั้น
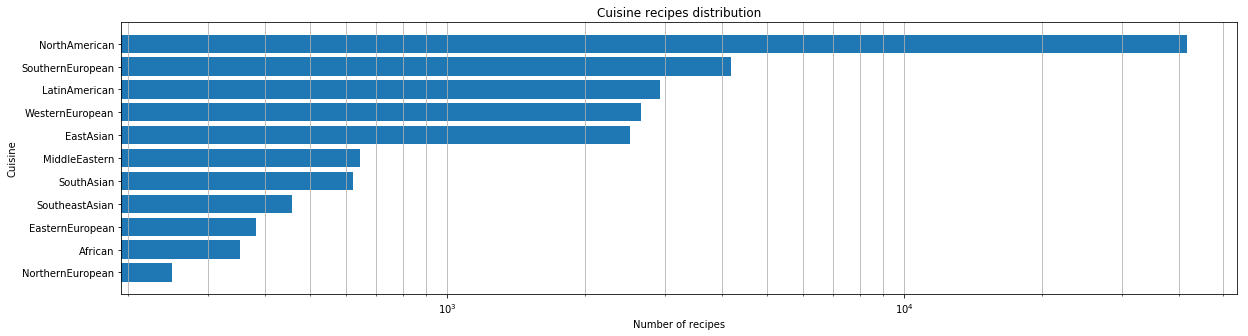
เมื่อเราได้ชุดข้อมูลแล้ว เราก็ทำการวิเคราะห์เบื้องต้น อันดับแรก เรามีการประเมินเชิงปริมาณว่ามีอาหารกี่รายการอยู่ในชุดข้อมูลของเรา
สำหรับอาหารแต่ละประเภท เราได้ระบุส่วนผสมยอดนิยมที่สุด
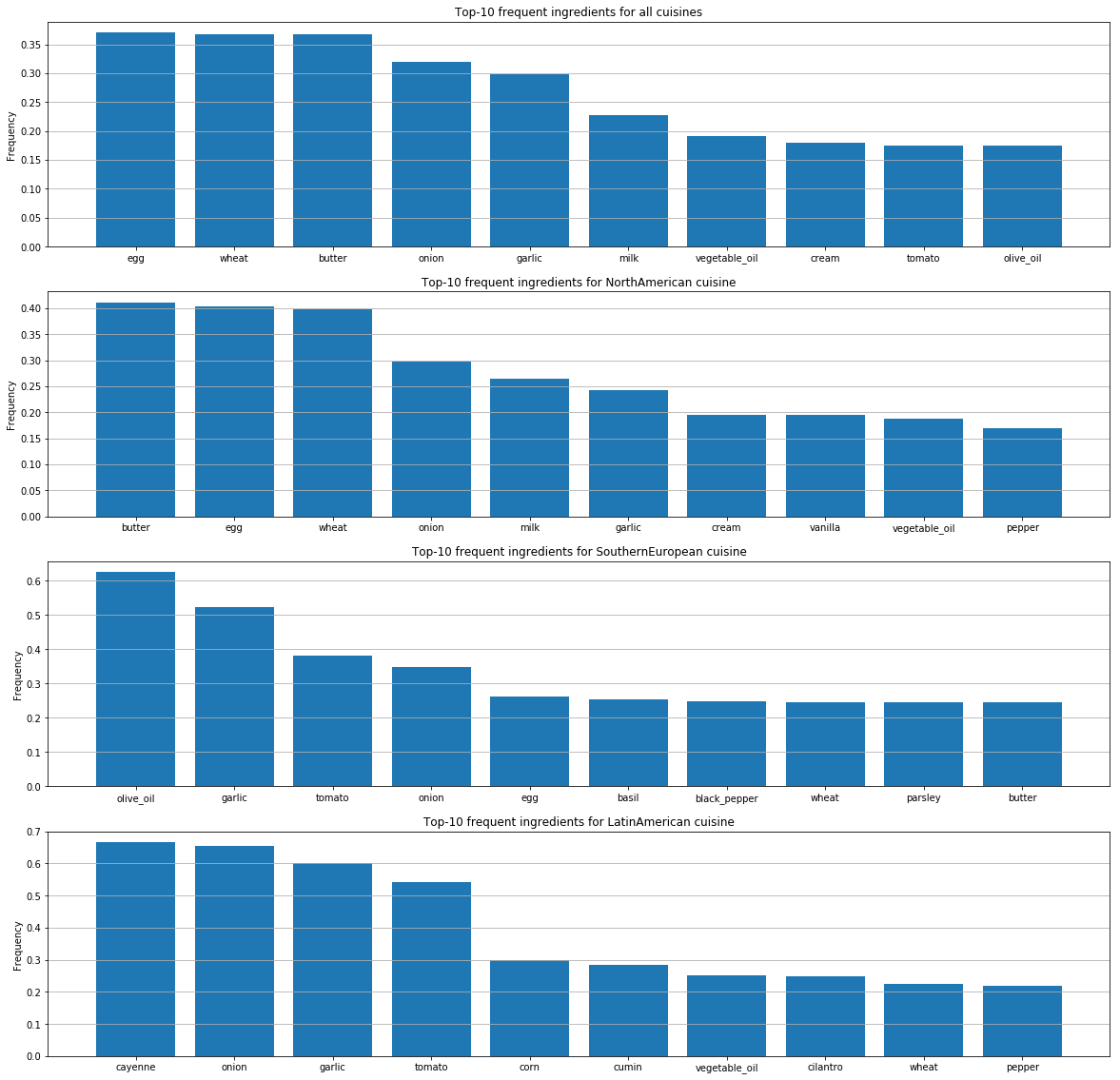
กราฟเหล่านี้แสดงความแตกต่างในรสนิยมความชอบของผู้คนในแต่ละประเทศ และความแตกต่างในวิธีที่พวกเขาผสมส่วนผสมต่างๆ
หลังจากนั้นเราตัดสินใจวิเคราะห์สูตรพิซซ่าจากทั่วทุกมุมโลกเพื่อค้นหารูปแบบ นี่คือข้อสรุปที่เราได้สรุปไว้
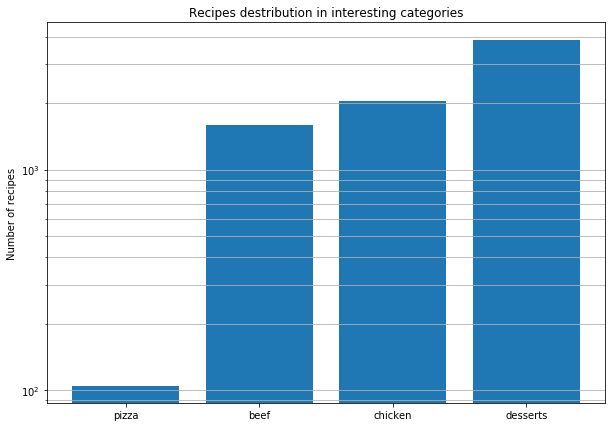
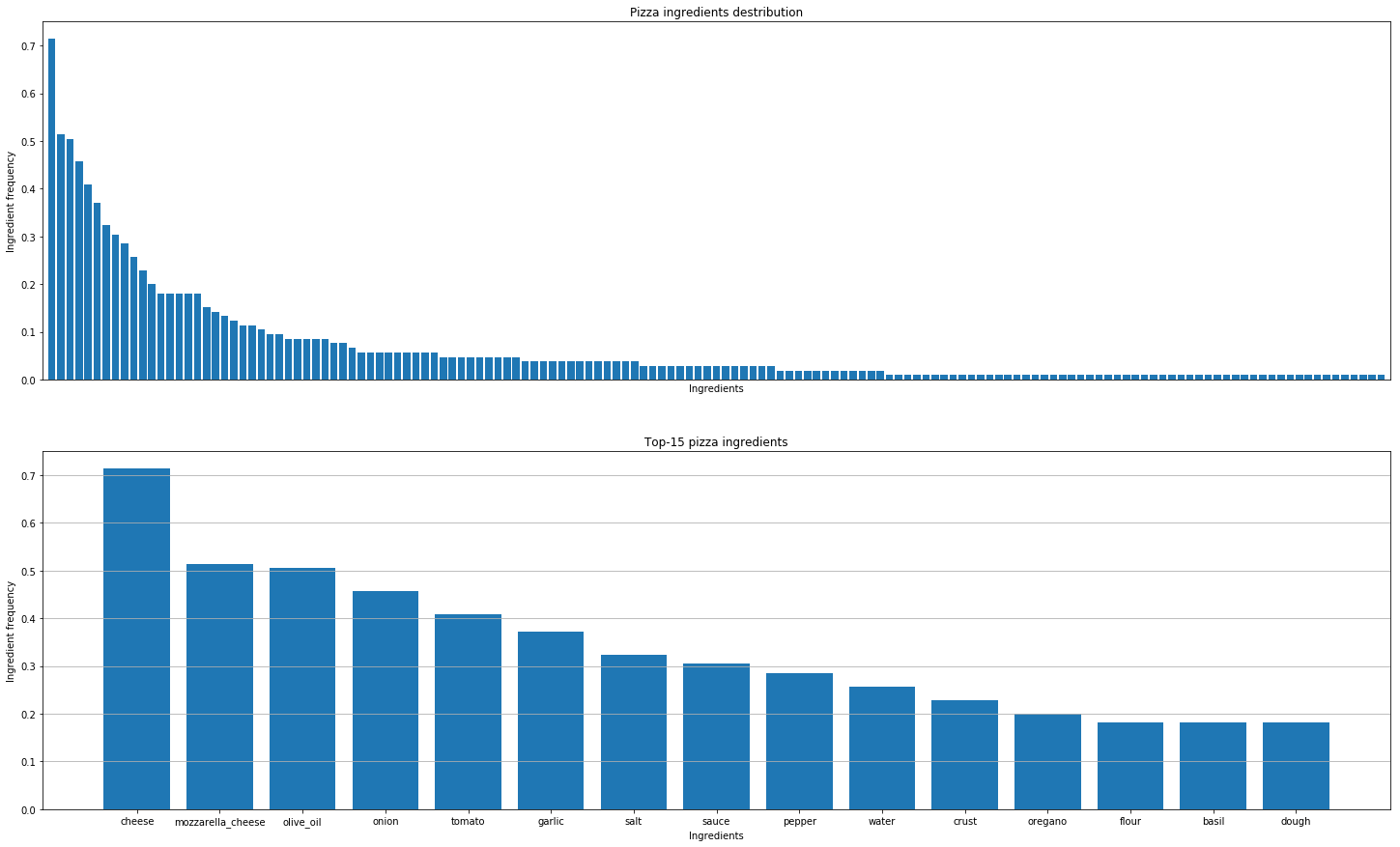
การค้นหาส่วนผสมของรสชาติที่แท้จริงนั้นไม่เหมือนกับการหาส่วนผสมของโมเลกุล ชีสทั้งหมดมีองค์ประกอบโมเลกุลเหมือนกัน แต่นั่นไม่ได้หมายความว่าส่วนผสมที่ดีอาจมาจากส่วนผสมที่ใกล้เคียงที่สุดเท่านั้น
อย่างไรก็ตาม เราต้องดูส่วนผสมที่มีโมเลกุลคล้ายกันเมื่อแปลงส่วนผสมเป็นคณิตศาสตร์ เพราะวัตถุที่คล้ายกัน (ชีสเดียวกัน) จะต้องคงความคล้ายคลึงไว้ไม่ว่าเราจะอธิบายอย่างไรก็ตาม วิธีนี้ทำให้เราสามารถตรวจสอบได้ว่าวัตถุนั้นได้รับการอธิบายอย่างถูกต้องหรือไม่
ในการนำเสนอสูตรในรูปแบบที่โครงข่ายประสาทเทียมเข้าใจได้ เราใช้ Skip-Gram Negative Sampling (SGNS) ซึ่งเป็นอัลกอริทึมของ word2vec โดยอิงตามการปรากฏของคำในบริบท
เราตัดสินใจที่จะไม่ใช้โมเดล word2vec ที่ผ่านการฝึกอบรมมาแล้ว เนื่องจากโครงสร้างความหมายของสูตรแตกต่างจากข้อความธรรมดา และด้วยโมเดลเหล่านี้ เราอาจสูญเสียข้อมูลสำคัญได้
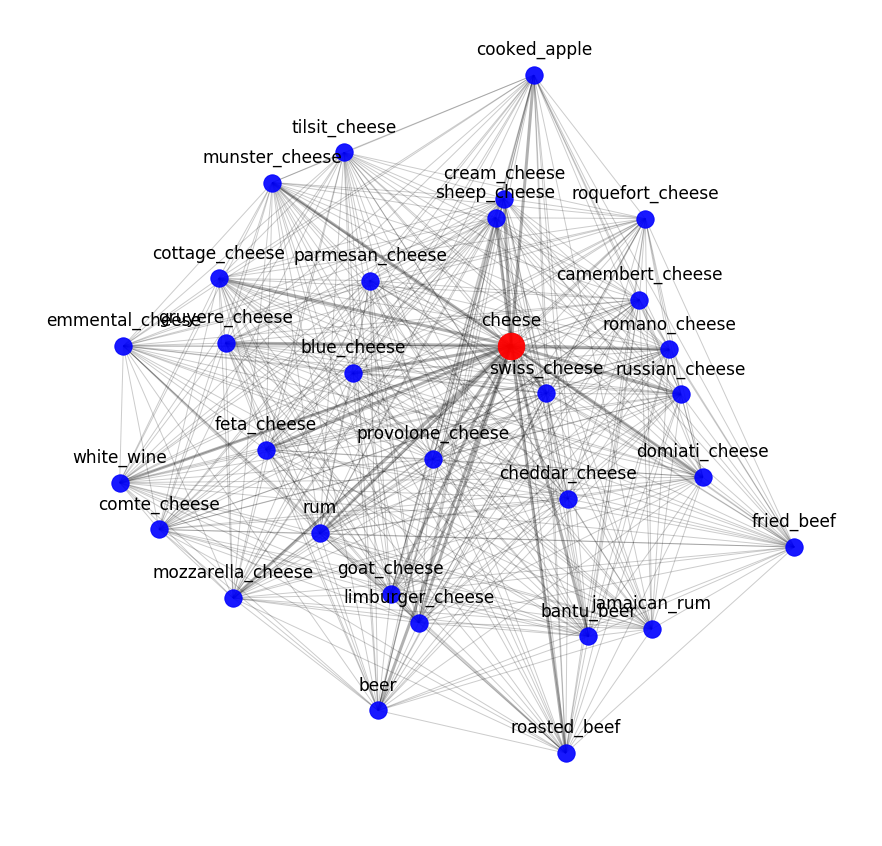
คุณสามารถประเมินผลลัพธ์ของ word2vec ได้โดยดูที่เพื่อนบ้านความหมายที่ใกล้ที่สุด ตัวอย่างเช่น นี่คือสิ่งที่แบบจำลองของเรารู้เกี่ยวกับชีส:
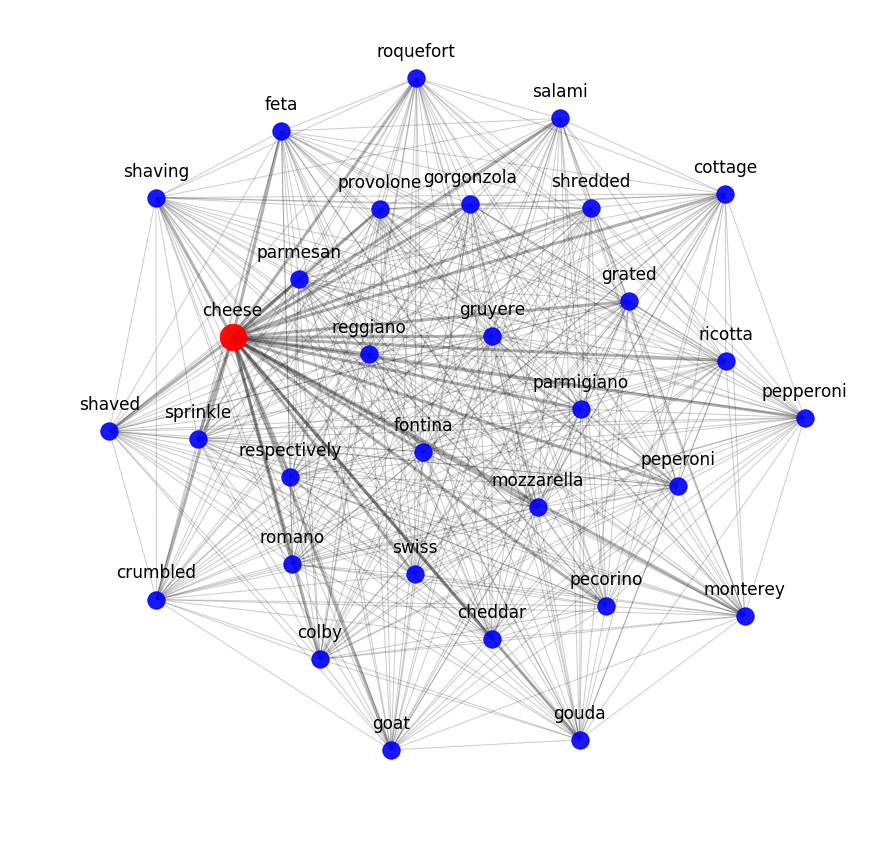
เพื่อทดสอบขอบเขตที่โมเดลความหมายสามารถจับความสัมพันธ์ระหว่างสูตรของส่วนผสมได้ เราใช้โมเดลหัวข้อ กล่าวอีกนัยหนึ่ง เราพยายามแยกชุดข้อมูลสูตรอาหารออกเป็นกลุ่มๆ ตามลำดับที่กำหนดทางคณิตศาสตร์
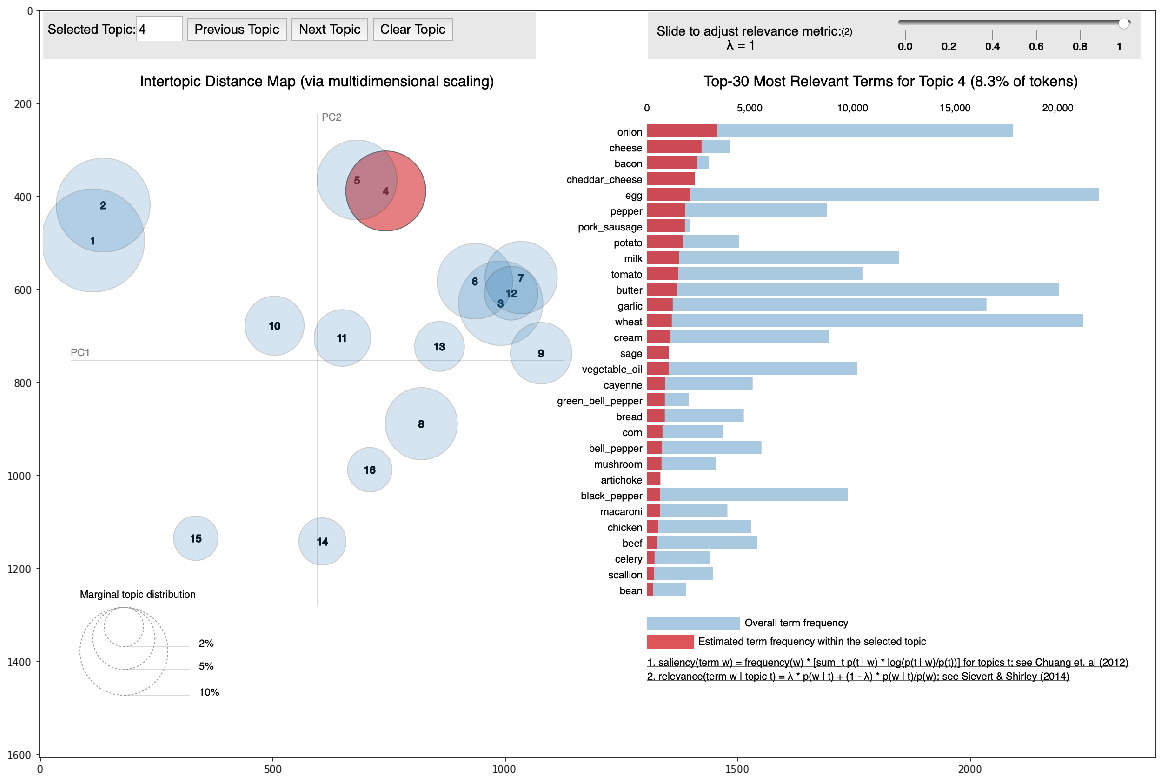
สำหรับสูตรอาหารทั้งหมด เรารู้ว่ามีการจัดกลุ่มตามสูตรเหล่านั้น สำหรับสูตรอาหารตัวอย่าง เราทราบถึงความเชื่อมโยงกับคลัสเตอร์จริง จากข้อมูลนี้ เราพบความเชื่อมโยงระหว่างคลัสเตอร์ทั้งสองประเภทนี้
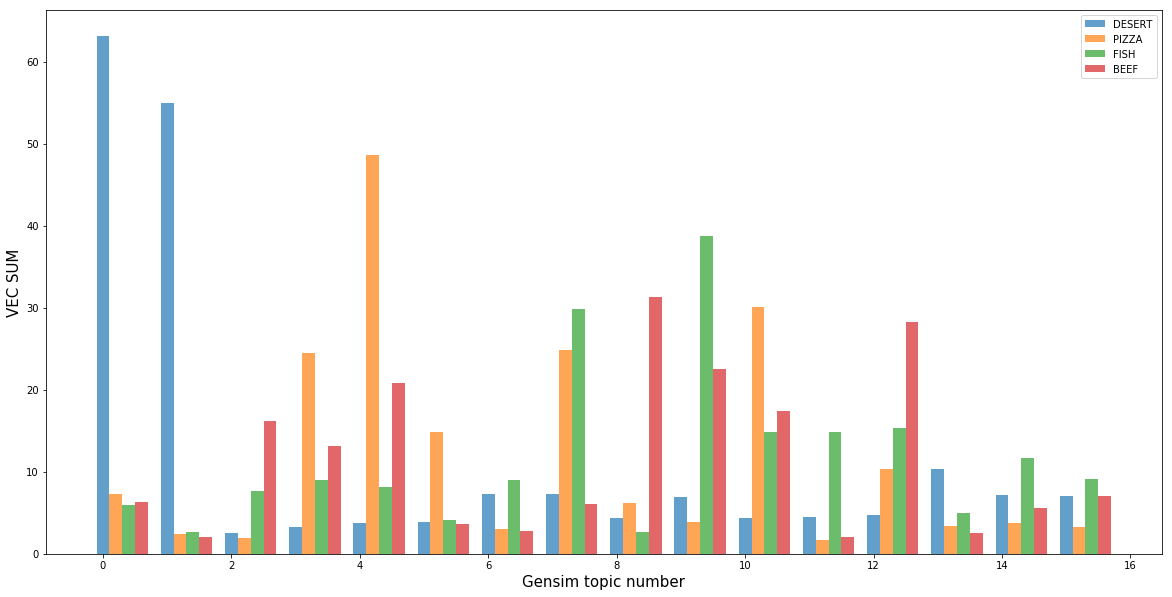
สิ่งที่ชัดเจนที่สุดคือคลาสของของหวานซึ่งรวมอยู่ในหัวข้อ 0 และ 1 ซึ่งสร้างโดยโมเดลหัวข้อ นอกจากของหวานแล้ว แทบจะไม่มีชั้นเรียนอื่นๆ ในหัวข้อเหล่านี้เลย ซึ่งแสดงให้เห็นว่าของหวานสามารถแยกออกจากอาหารประเภทอื่นๆ ได้อย่างง่ายดาย นอกจากนี้แต่ละหัวข้อยังมีชั้นเรียนที่อธิบายได้ดีที่สุด ซึ่งหมายความว่าแบบจำลองของเราประสบความสำเร็จในการกำหนดความหมายทางคณิตศาสตร์ของ "รสชาติ" ที่ไม่ชัดเจน
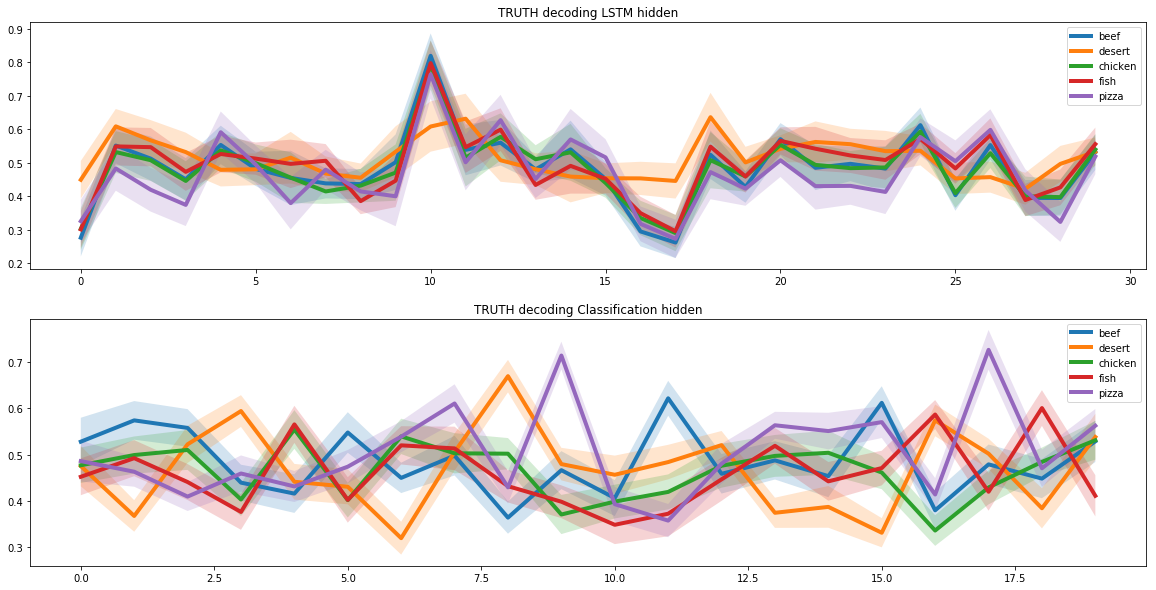
เราใช้โครงข่ายประสาทเทียมที่เกิดซ้ำสองเครือข่ายเพื่อสร้างสูตรอาหารใหม่ๆ เพื่อจุดประสงค์นี้ เราสันนิษฐานว่าในพื้นที่สูตรทั้งหมดจะมีช่องว่างที่สอดคล้องกับสูตรพิซซ่า และเพื่อให้โครงข่ายประสาทเทียมเรียนรู้วิธีสร้างสูตรพิซซ่าใหม่ๆ เราต้องหาพื้นที่ย่อยนี้
งานนี้คล้ายกับการเข้ารหัสรูปภาพอัตโนมัติ ซึ่งเรานำเสนอรูปภาพเป็นเวกเตอร์ขนาดต่ำ เวกเตอร์ดังกล่าวอาจมีข้อมูลเฉพาะมากมายเกี่ยวกับรูปภาพ
ตัวอย่างเช่น เวกเตอร์เหล่านี้สามารถจัดเก็บข้อมูลเกี่ยวกับสีผมของบุคคลในเซลล์แยกต่างหากสำหรับการจดจำใบหน้าในภาพถ่าย เราเลือกวิธีนี้อย่างแม่นยำเนื่องจากคุณสมบัติเฉพาะของพื้นที่ย่อยที่ซ่อนอยู่
เพื่อระบุพื้นที่ย่อยของพิซซ่า เราได้รันสูตรพิซซ่าผ่านโครงข่ายประสาทเทียมสองเครือข่ายที่เกิดซ้ำ อันแรกได้รับสูตรพิซซ่าและพบว่ามันเป็นเวกเตอร์แฝง อันที่สองได้รับเวกเตอร์แฝงจากโครงข่ายประสาทเทียมอันแรกและสร้างสูตรตามมัน สูตรที่อินพุตของโครงข่ายประสาทเทียมแรกและเอาต์พุตของโครงข่ายประสาทที่สองควรตรงกัน
ด้วยวิธีนี้ โครงข่ายประสาทเทียมสองเครือข่ายได้เรียนรู้วิธีการแปลงสูตรของเวกเตอร์แฝงอย่างถูกต้อง และจากสิ่งนี้ เราก็สามารถหาพื้นที่ย่อยที่ซ่อนอยู่ ซึ่งสอดคล้องกับสูตรพิซซ่าทั้งหมด
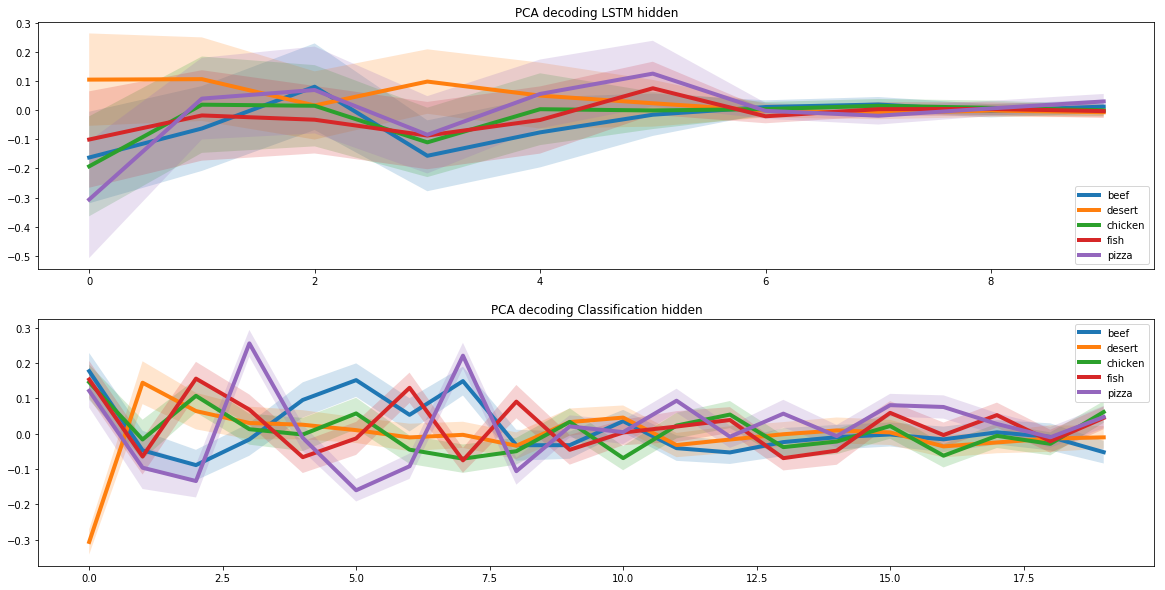
เมื่อเราแก้ไขปัญหาในการสร้างสูตรพิซซ่า เราต้องเพิ่มเกณฑ์การรวมโมเลกุลให้กับโมเดล ในการทำเช่นนี้ เราใช้ผลการศึกษาร่วมกันของนักวิทยาศาสตร์จากเคมบริดจ์และมหาวิทยาลัยหลายแห่งในสหรัฐฯ
การศึกษาพบว่าส่วนผสมที่มีคู่โมเลกุลที่พบมากที่สุดจะก่อให้เกิดส่วนผสมที่ดีที่สุด ดังนั้นเมื่อสร้างสูตร โครงข่ายประสาทเทียมจึงเลือกใช้ส่วนผสมที่มีโครงสร้างโมเลกุลคล้ายกัน
เป็นผลให้โครงข่ายประสาทเทียมของเราเรียนรู้ที่จะสร้างสูตรพิซซ่า ด้วยการปรับค่าสัมประสิทธิ์ โครงข่ายประสาทเทียมสามารถผลิตได้ทั้งสูตรอาหารคลาสสิก เช่น มาการิต้าหรือเปปเปอโรนี และสูตรอาหารที่ไม่ธรรมดา ซึ่งหนึ่งในนั้นคือหัวใจของ Opensource Pizza
| เลขที่ | สูตรอาหาร |
|---|---|
| 1 | ผักโขม, ชีส, มะเขือเทศ, มะกอกดำ, มะกอก, กระเทียม, พริกไทย, โหระพา, ส้ม, แตงโม, ต้นอ่อน, บัตเตอร์มิลค์, มะนาว, เบส, ถั่ว, รูทาบากา |
| 2 | หัวหอม, มะเขือเทศ, มะกอก, พริกไทยดำ, ขนมปัง, แป้งโด |
| 3 | ไก่, หัวหอม, มะกอกดำ, ชีส, ซอส, มะเขือเทศ, น้ำมันมะกอก, มอสซาเรลลา_ชีส |
| 4 | มะเขือเทศ, เนย, ครีมชีส, พริกไทย, น้ำมันมะกอก, ชีส, พริกไทยดำ, มอสซาเรลลา_ชีส |
Open Source Pizza ได้รับอนุญาตภายใต้ใบอนุญาต MIT
Golodyaev Arseniy, MIPT, Skoltech, [email protected]
Egor Baryshnikov, Skoltech, [email protected]


