visual chatgpt
1.0.0
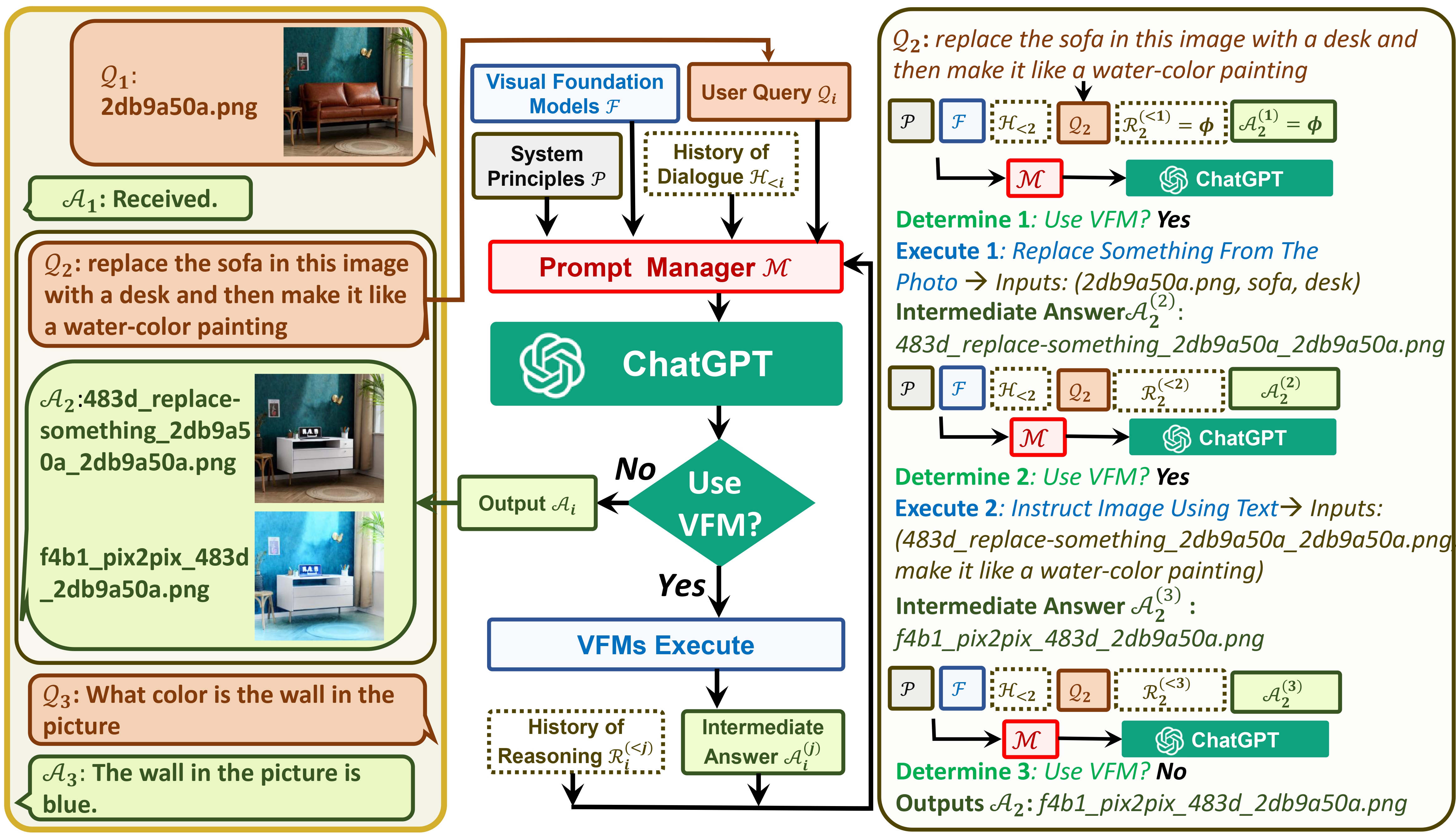
Visual ChatGPT เชื่อมต่อ ChatGPT และชุด Visual Foundation Models เพื่อเปิดใช้งาน การส่ง และ รับ ภาพระหว่างการสนทนา
ดูบทความของเรา: Visual ChatGPT: การพูดคุย การวาดภาพ และการแก้ไขด้วย Visual Foundation Models
ประการหนึ่ง ChatGPT (หรือ LLM) ทำหน้าที่เป็น อินเทอร์เฟซทั่วไป ที่ให้ความเข้าใจที่กว้างขวางและหลากหลายในหัวข้อต่างๆ ในทางกลับกัน Foundation Models ทำหน้าที่เป็น ผู้เชี่ยวชาญโดเมน โดยให้ความรู้เชิงลึกในโดเมนเฉพาะ ด้วยการใช้ประโยชน์จาก ความรู้ทั่วไปและความรู้เชิงลึก เรามุ่งเป้าไปที่การสร้าง AI ที่สามารถจัดการงานต่างๆ ได้

# clone the repo
git clone https://github.com/microsoft/visual-chatgpt.git
# Go to directory
cd visual-chatgpt
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux)
export OPENAI_API_KEY={Your_Private_Openai_Key}
# prepare your private OpenAI key (for Windows)
set OPENAI_API_KEY={Your_Private_Openai_Key}
# Start Visual ChatGPT !
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which
# Visual Foundation Model to use and where it will be loaded to
# The model and device are sperated by underline '_', the different models are seperated by comma ','
# The available Visual Foundation Models can be found in the following table
# For example, if you want to load ImageCaptioning to cpu and Text2Image to cuda:0
# You can use: "ImageCaptioning_cpu,Text2Image_cuda:0"
# Advice for CPU Users
python visual_chatgpt.py --load ImageCaptioning_cpu,Text2Image_cpu
# Advice for 1 Tesla T4 15GB (Google Colab)
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,Text2Image_cuda:0"
# Advice for 4 Tesla V100 32GB
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,ImageEditing_cuda:0,
Text2Image_cuda:1,Image2Canny_cpu,CannyText2Image_cuda:1,
Image2Depth_cpu,DepthText2Image_cuda:1,VisualQuestionAnswering_cuda:2,
InstructPix2Pix_cuda:2,Image2Scribble_cpu,ScribbleText2Image_cuda:2,
Image2Seg_cpu,SegText2Image_cuda:2,Image2Pose_cpu,PoseText2Image_cuda:2,
Image2Hed_cpu,HedText2Image_cuda:3,Image2Normal_cpu,
NormalText2Image_cuda:3,Image2Line_cpu,LineText2Image_cuda:3"
ที่นี่เราจะแสดงรายการการใช้หน่วยความจำ GPU ของ Visual Foundation แต่ละรุ่น คุณสามารถระบุได้ว่าต้องการรุ่นใด:
| แบบจำลองมูลนิธิ | หน่วยความจำ GPU (MB) |
|---|---|
| การแก้ไขรูปภาพ | 3981 |
| สอนPix2Pix | 2827 |
| ข้อความ2รูปภาพ | 3385 |
| คำบรรยายภาพ | 1209 |
| Image2แคนนี่ | 0 |
| CannyText2รูปภาพ | 3531 |
| Image2Line | 0 |
| LineText2Image | 3529 |
| Image2เฮ็ด | 0 |
| HedText2รูปภาพ | 3529 |
| ภาพที่ 2 การเขียนลวก ๆ | 0 |
| ScribbleText2รูปภาพ | 3531 |
| Image2ท่า | 0 |
| PoseText2รูปภาพ | 3529 |
| รูปภาพ2Seg | 919 |
| SegText2Image | 3529 |
| ภาพที่2ความลึก | 0 |
| ความลึกข้อความ2รูปภาพ | 3531 |
| ภาพที่ 2 ปกติ | 0 |
| NormalText2Image | 3529 |
| การตอบคำถามด้วยภาพ | 1495 |
เราขอขอบคุณโอเพ่นซอร์สของโครงการต่อไปนี้:
การกอดใบหน้า LangChain การควบคุมการแพร่กระจายที่เสถียร Net InstructPix2Pix CLIPSeg BLIP
สำหรับความช่วยเหลือหรือปัญหาในการใช้ Visual ChatGPT โปรดส่งปัญหา GitHub
สำหรับการสื่อสารอื่นๆ โปรดติดต่อ Chenfei WU ([email protected]) หรือ Nan DUAN ([email protected])


