AudioNotes
1.0.0
สามารถแยกเนื้อหาของเสียงและวิดีโอได้อย่างรวดเร็ว และเรียกแบบจำลองขนาดใหญ่เพื่อจัดระเบียบให้เป็นบันทึกย่อที่มีโครงสร้างเพื่อให้อ่านง่ายและรวดเร็ว
FunASR: https://github.com/modelscope/FunASR
Qwen2: https://ollama.com/library/qwen2
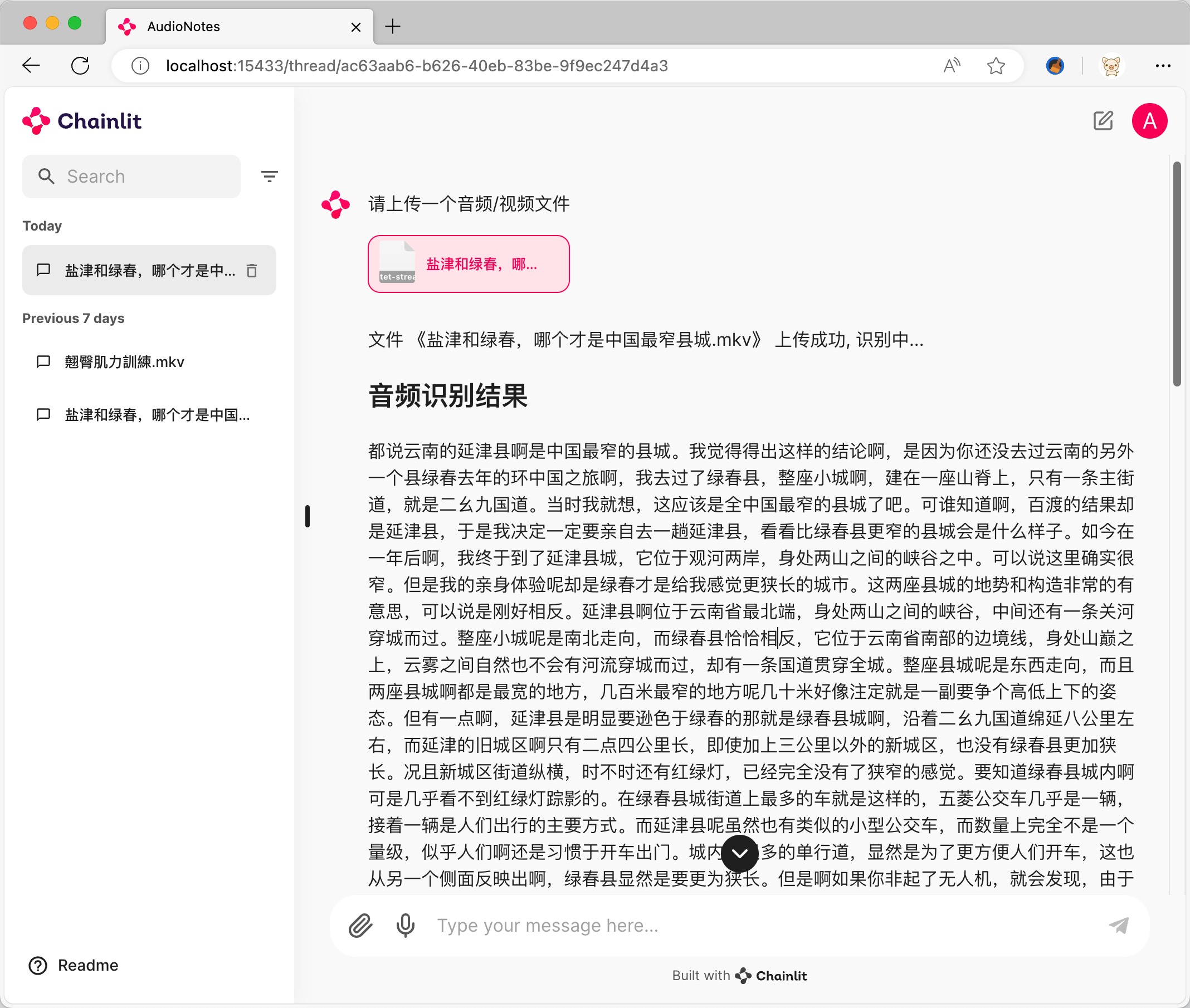
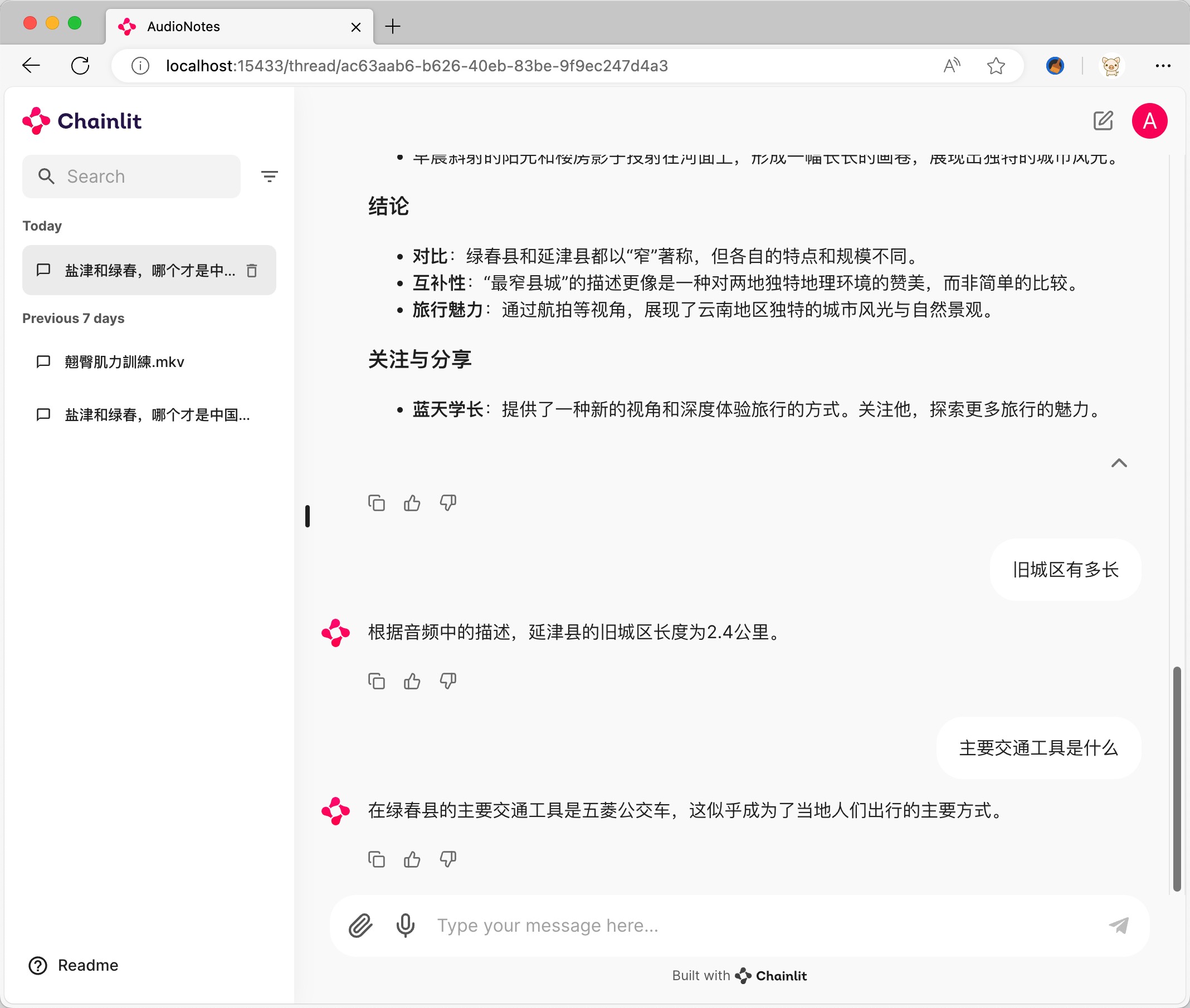
ดาวน์โหลดแพ็คเกจการติดตั้ง Ollama ที่สอดคล้องกับระบบและติดตั้ง
https://ollama.com/download
ฉันใช้阿里的千问2 7b เป็นตัวอย่าง https://ollama.com/library/qwen2
ollama pull qwen2:7bมีสองวิธีในการปรับใช้ วิธีแรกคือการปรับใช้โดยใช้ Docker และอีกวิธีคือการปรับใช้ภายในเครื่อง
curl -fsSL https://github.com/harry0703/AudioNotes/raw/main/docker-compose.yml -o docker-compose.yml
docker-compose upหลังจากที่ docker เริ่มทำงานแล้ว ให้ไปที่ http://localhost:15433/
บัญชีเข้าสู่ระบบคือผู้ดูแลระบบและรหัสผ่านคือผู้ดูแลระบบ (สามารถแก้ไขได้ในไฟล์ docker-compose.yml)
จำเป็นต้องมีฐานข้อมูล postgresql ที่สามารถเข้าถึงได้
conda create -n AudioNotes python=3.10 -y
conda activate AudioNotes
git clone https://github.com/harry0703/AudioNotes.git
cd AudioNotes
pip install -r requirements.txt เปลี่ยนชื่อ .env.example เป็น .env และแก้ไขข้อมูลการกำหนดค่าที่เกี่ยวข้อง
chainlit run main.pyหลังจากเริ่มบริการแล้ว ให้ไปที่ http://localhost:8000/
บัญชีเข้าสู่ระบบคือผู้ดูแลระบบและรหัสผ่านคือผู้ดูแลระบบ (สามารถแก้ไขได้ในไฟล์ .env)


