llmjudge
1.0.0
การประเมิน LLM ในสถานการณ์ปลายเปิดเป็นเรื่องยาก มีความเห็นพ้องต้องกันมากขึ้นว่าเกณฑ์มาตรฐานที่มีอยู่ยังขาดอยู่ และผู้ปฏิบัติงานที่มีประสบการณ์ชอบที่จะลอง นึกถึงโมเดลการตรวจสอบ ด้วยตนเอง ฉันหันไปใช้การประเมินโดยสรุปจากนักพัฒนาและนักวิจัยที่ฉันไว้วางใจ โดยที่ Chatbot Arena เป็นส่วนเสริมที่ยอดเยี่ยม แรงจูงใจเบื้องหลังการซื้อคืนนี้คือวิธีที่ได้รับความนิยมมากขึ้นในการใช้ LLM ที่แข็งแกร่งเพื่อตัดสินโมเดล วิธีการนี้มีมาประมาณสองสามเดือนแล้ว ในรุ่นต่างๆ เช่น JudgeLM และ MT-Bench ล่าสุด
คุณอาจจะเคยดูกระทู้นี้ก็ได้ ตามที่ผู้เขียนทวีตที่ Arize AI การใช้ LLMs-as-a-judge รับประกันเซิร์ฟเวอร์เตือน โดยเฉพาะในส่วนที่เกี่ยวกับการใช้การประเมินคะแนนตัวเลข ดูเหมือนว่า LLM จะจัดการช่วงที่ต่อเนื่องได้แย่มาก ซึ่งจะเห็นได้ชัดเจนอย่างเห็นได้ชัดเมื่อได้รับแจ้งให้ประเมิน X จาก 1 ถึง 10 การซื้อคืนนี้เป็นเอกสารที่มีชีวิตเกี่ยวกับการทดลองที่พยายามทำความเข้าใจและจับภาพ ขอบเขตที่ขรุขระ ของปัญหานี้ งานล่าสุดได้สร้าง ความสัมพันธ์ที่แข็งแกร่งระหว่าง MT-Bench และการตัดสินของมนุษย์ (Arena Elo) ซึ่งหมายความว่า LLM สามารถเป็นผู้ตัดสินได้ เกิดอะไรขึ้นที่นี่
ด้านล่างนี้คือรายละเอียดและผลลัพธ์ทั้งหมด
เนื่องจากข้อจำกัดด้านต้นทุน ในตอนแรกฉันจะมุ่งเน้นไปที่งานสะกด/สะกดผิดที่อธิบายไว้ในทวีต ฉันกังวลเล็กน้อยว่า X เชิงปริมาณของงานนี้จะทำให้ความเข้าใจในการทดลองนี้ปนเปื้อน แต่เราจะได้เห็นกัน ฉันยินดีกับการวิเคราะห์ปรากฏการณ์นี้อย่างครบถ้วนมากขึ้น ผลลัพธ์ของฉันควรจะต้องพิจารณาเพียงเล็กน้อยจากการทดลองที่มีข้อจำกัด
ฉันได้สร้างชุดข้อมูลการสะกดหรือสะกดผิดจากบทความของ Paul Graham โดยไม่แน่ใจว่าชื่อใดเหมาะสมกว่า ตัวเลือกนี้ส่วนใหญ่ไม่สะดวกเนื่องจากฉันเคยใช้ชุดข้อมูลมาก่อนเมื่อทดสอบแรงกดดันในหน้าต่างบริบท ฉันดึงบริบทจำนวน 3,000 คำออกจากบทความ และแทรกข้อผิดพลาดในการสะกดคำแบบสุ่มตามอัตราส่วนการสะกดผิดที่ต้องการ ในรหัสเทียม:
misspell_ratio
words = split context into words
misspell_count = calculate number of words to misspell based on ratio
FOR word = sample(words, misspell_count)
IF length(word) > 3
extract random character
ELSE:
add random character
END FOR
รหัสที่สมบูรณ์มีให้ใช้งานในรูปแบบสมุดบันทึก
ด้วยชุดข้อมูลที่สร้างขึ้น เราแจ้งให้ LLM ประเมินจำนวนคำที่สะกดผิดในบริบทโดยใช้เทมเพลตการให้คะแนนที่แตกต่างกัน เรากำลังใช้ API ต่อไปนี้
GPT-4: gpt-4-0125-preview
GPT-3.5: gpt-3.5-turbo-1106
ที่อุณหภูมิ = 0
การทดสอบ 1. ขอยืนยันว่า LLM ประสบปัญหาในการจัดการช่วงตัวเลขในการตั้งค่าแบบ Zero-shot เราแจ้ง GPT-3.5 และ GPT-4 ด้วยเทมเพลตการให้คะแนนที่เป็นตัวเลข ตั้งแต่คะแนน 0 ถึง 10 คะแนน
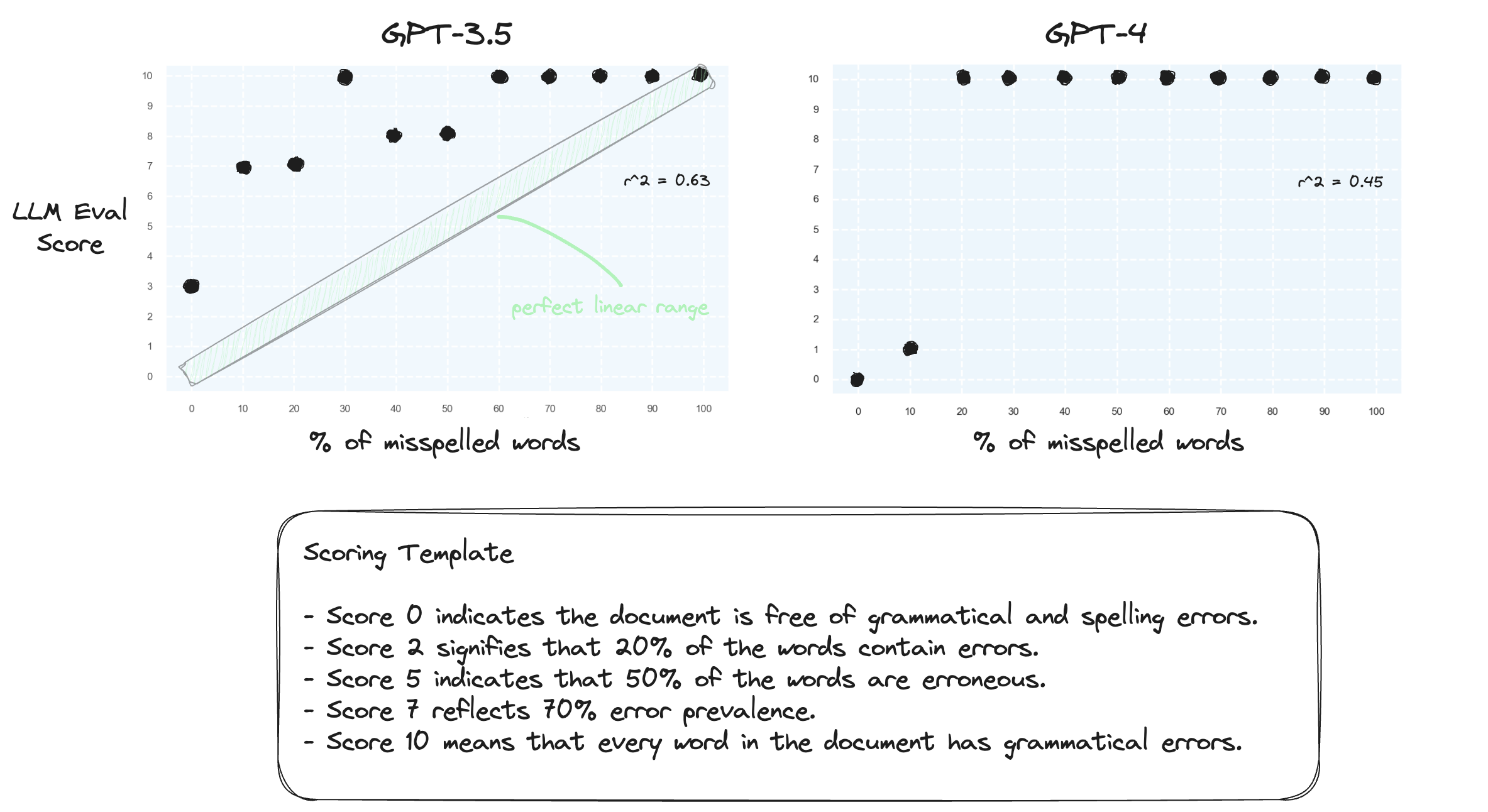
ตามที่คาดไว้ทั้งคู่ตัดสินผิดอย่างรุนแรง
การทดสอบ 2. จะเกิดอะไรขึ้นถ้าเรากลับช่วงการให้คะแนน? ตอนนี้ คะแนน 10 หมายถึงเอกสารที่สะกดถูกต้อง
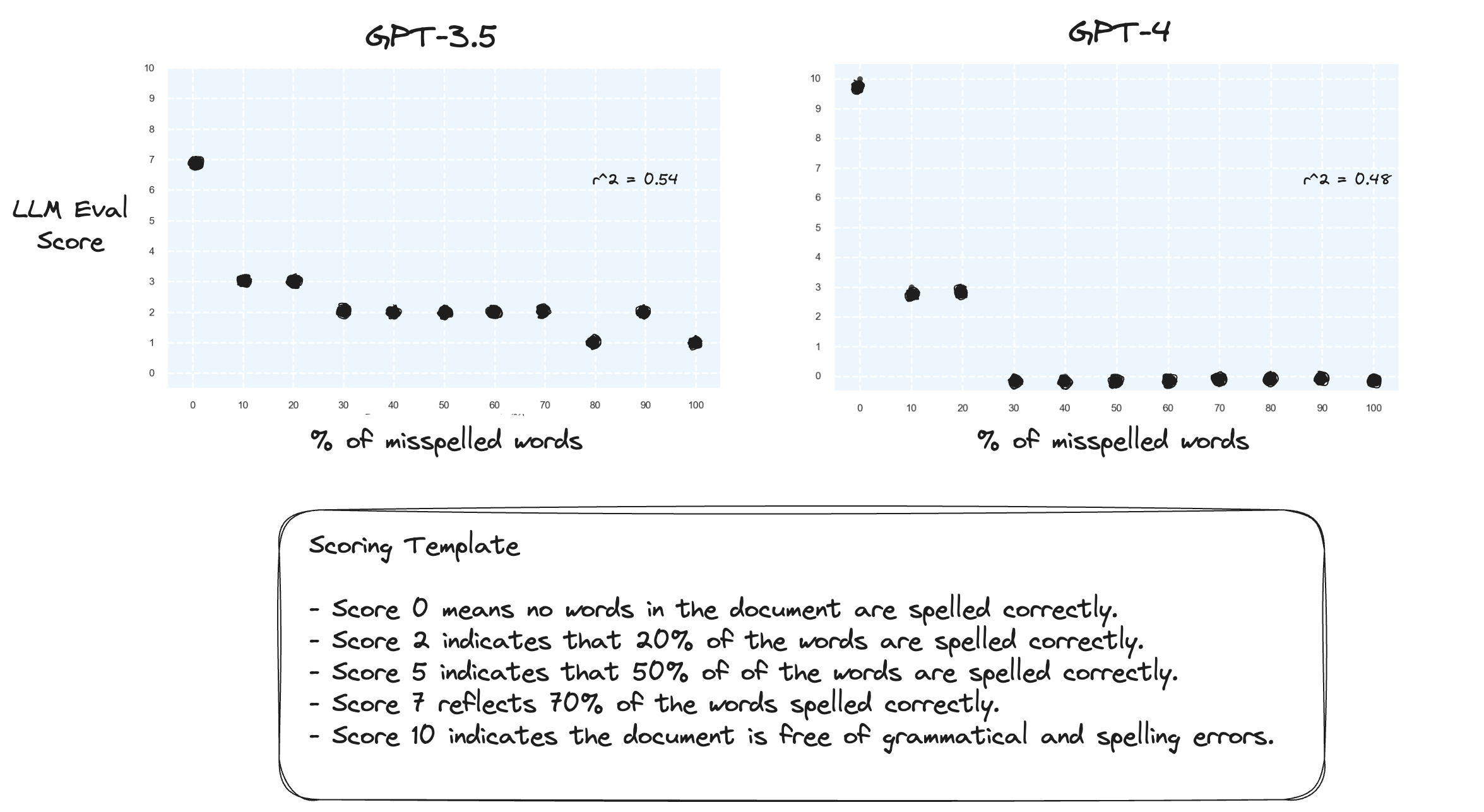
สิ่งนี้ดูเหมือนจะไม่สร้างความแตกต่างมากนัก
การทดสอบ 3. หากเราเชื่อสมมติฐานจาก Arize เราอาจเห็นการปรับปรุงหากเราหลีกเลี่ยงเกณฑ์การให้คะแนน และใช้ 'เกรดที่มีป้ายกำกับ' แทน ในกรณีนี้ ฉันตัดสินใจเลื่อนลงมาเป็นระดับการให้คะแนน 5 คะแนน
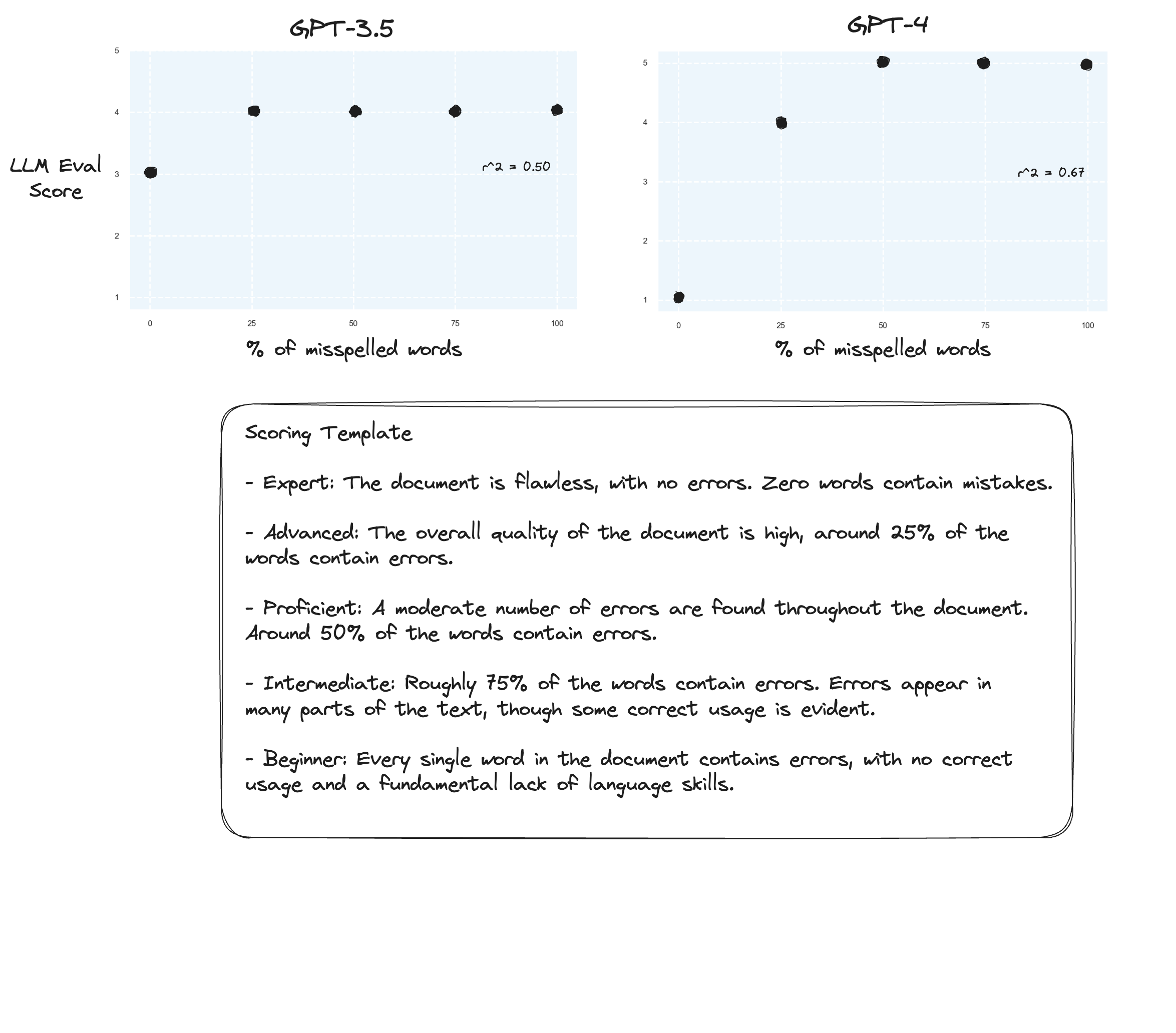
อาจมีการปรับปรุงเล็กน้อย? ยากที่จะพูดอย่างตรงไปตรงมา ฉันไม่ประทับใจ
การทดสอบ 4. แล้วห่วงโซ่แห่งความคิดแบบ Zero-shot ล่ะ?

gpt-3.5 กลายเป็นคำพูดที่ไม่มีความหมายสำหรับสองข้อความแจ้ง ตามที่คาดไว้ gpt-4 จะเห็นการปรับปรุงเมื่อได้รับแจ้งให้คิดออกมาดังๆ สังเกตว่าการให้คะแนน 10 จะเกิดความลังเลใจมากเพียงใด
การทดสอบ 5. ตามที่ผู้เขียน Prometheus แนะนำ การแมปแต่ละคะแนนด้วยคำอธิบายของตัวเองอาจช่วยเพิ่มความสามารถของ LLM ในการให้คะแนนในช่วงตัวเลขทั้งหมด เมื่อรวมกับ CoT ผลลัพธ์ที่ได้คือ:

การปรับปรุงอย่างต่อเนื่องสำหรับ gpt-4 ยังลังเลใจมากที่จะกำหนดคะแนนขอบเขต 0 และ 10
การทดสอบ 6. หลังจากอ่านเพิ่มเติมเกี่ยวกับ MT Bench แล้ว ฉันตัดสินใจทดสอบแนวทางอื่น โดยใช้การเปรียบเทียบแบบคู่ แทนที่จะใช้การให้คะแนนแบบแยกส่วน ตอนนี้ โดยปกติจะต้องมีการเปรียบเทียบ O(n * log N) แต่เนื่องจากเรารู้ลำดับอยู่แล้ว ฉันคิดว่าเราจะทดสอบกรณีที่ยากที่สุด: เปรียบเทียบการสะกดผิด 0% กับการสะกดผิด 10%, 10% เทียบกับ 20% และอื่นๆ สำหรับการเปรียบเทียบทั้งหมด 10 รายการ โปรดสังเกตว่าฉันใช้ Zero-shot CoT เช่นกัน
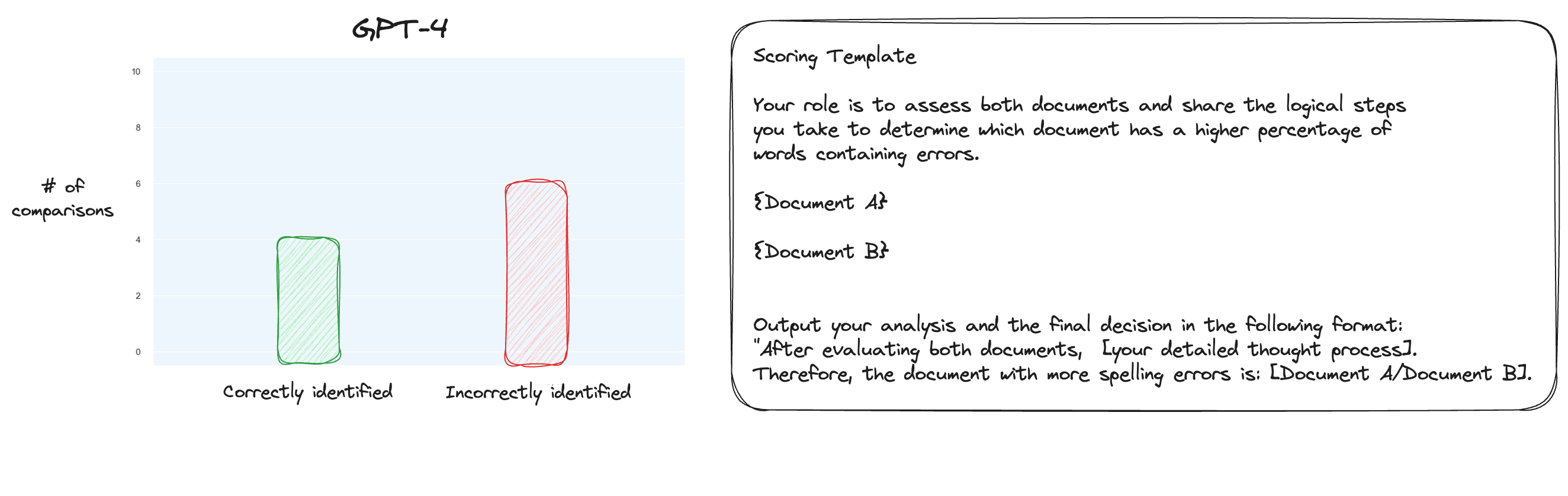
สมมติฐานของฉันคือ GPT-4 น่าจะทำได้ดีในสถานการณ์ที่ต้องเปรียบเทียบข้อความสองข้อความภายในหน้าต่างบริบท แต่ฉันคิดผิด ฉันแปลกใจที่สิ่งนี้ไม่ได้ปรับปรุงอะไรเลยจริงๆ แน่นอนว่านี่เป็นการเปรียบเทียบที่ยากที่สุดในบรรดาการเปรียบเทียบที่เป็นไปได้ แต่ทั้งหมดนี้ยังคงเป็นงานที่ตรงไปตรงมา บางทีแง่มุมเชิงปริมาณของงานนี้อาจเป็นเรื่องยากมากสำหรับ LLM อืม บางทีฉันอาจต้องหางานพรอกซีที่ดีกว่านี้...
(31/1) ฉันได้ดูข้อมูลภายในของ MT-Bench แล้ว และรู้สึกประหลาดใจมากที่พบว่าพวกเขาขอให้ GPT-4 ให้คะแนนผลลัพธ์ในระดับ 1-10 พวกเขามีตัวเลือกการให้คะแนนทางเลือกอื่น เช่น การเปรียบเทียบแบบคู่กับเส้นพื้นฐาน แต่ตัวเลือกที่แนะนำคือแบบตัวเลข พรอมต์การตัดสินก็ง่ายอย่างไม่คาดคิดเช่นกัน:
โปรดทำหน้าที่เป็นผู้ตัดสินที่เป็นกลางและประเมินคุณภาพของการตอบกลับที่ผู้ช่วย AI ให้ไว้สำหรับคำถามของผู้ใช้ที่แสดงด้านล่าง การประเมินของคุณควรพิจารณาปัจจัยต่างๆ เช่น ความช่วยเหลือ ความเกี่ยวข้อง ความถูกต้อง ความลึก ความคิดสร้างสรรค์ และระดับรายละเอียดของคำตอบ เริ่มต้นการประเมินของคุณโดยให้คำอธิบายสั้นๆ มีวัตถุประสงค์ให้ได้มากที่สุด หลังจากให้คำอธิบายแล้ว คุณต้องให้คะแนนคำตอบในระดับ 1 ถึง 10 โดยปฏิบัติตามรูปแบบนี้อย่างเคร่งครัด: [คะแนน] เช่น "คะแนน: 5" [คำถาม] {คำถาม} [จุดเริ่มต้นของคำตอบของผู้ช่วย] {answer} [จุดสิ้นสุดของคำตอบของผู้ช่วย]
หากมีใครเชื่อว่านี่คือทั้งหมดในการตัดสินใน MT-Bench ฉันก็เริ่มตั้งคำถามถึงการใช้งานการสะกดผิดเป็นงานพร็อกซี...
(2/2) ฉันกระตือรือร้นที่จะทำให้ GPT-4 ตัดสินข้อความที่สะกดผิดผ่านการเปรียบเทียบแบบคู่แทนที่จะเป็นการให้คะแนนแบบแยก นี่เป็นหนึ่งในวิธีการตัดสินทางเลือกสำหรับ MT Bench (แม้ว่าพวกเขาจะแนะนำให้แยกการให้คะแนน) และฉันสงสัยว่ามันเหมาะสมกว่าสำหรับงานนี้ ผลลัพธ์การแมป CoT + แบบเต็มมีการปรับปรุงอย่างแน่นอน แต่ฉันยังคงคิดว่ายังมีงานที่ต้องทำ ข้อเสียเปรียบของการให้คะแนนแบบคู่คือแน่นอนว่าคุณจะต้องมีการเรียก API มากขึ้นอย่างมากเพื่อสร้างการจัดอันดับทั้งหมด (ในทางปฏิบัติ)


