datalens
1.0.0
นี่เป็นการทดลองส่วนตัวที่ใช้ LLM เพื่อจัดอันดับข้อมูลงานที่ไม่มีโครงสร้างตามเกณฑ์ที่ผู้ใช้กำหนด แพลตฟอร์มการค้นหางานแบบดั้งเดิมอาศัยระบบการกรองที่เข้มงวด แต่ผู้ใช้จำนวนมากขาดเกณฑ์ที่เป็นรูปธรรมดังกล่าว Datalens ช่วยให้คุณกำหนดการตั้งค่าของคุณในลักษณะที่เป็นธรรมชาติมากขึ้น จากนั้นให้คะแนนประกาศรับสมัครงานแต่ละรายการตามความเกี่ยวข้อง
เกณฑ์บางอย่างอาจมีความสำคัญมากกว่าเกณฑ์อื่นๆ ดังนั้น "เกณฑ์ที่ต้อง" จึงมีน้ำหนักมากกว่าเกณฑ์ปกติถึงสองเท่า
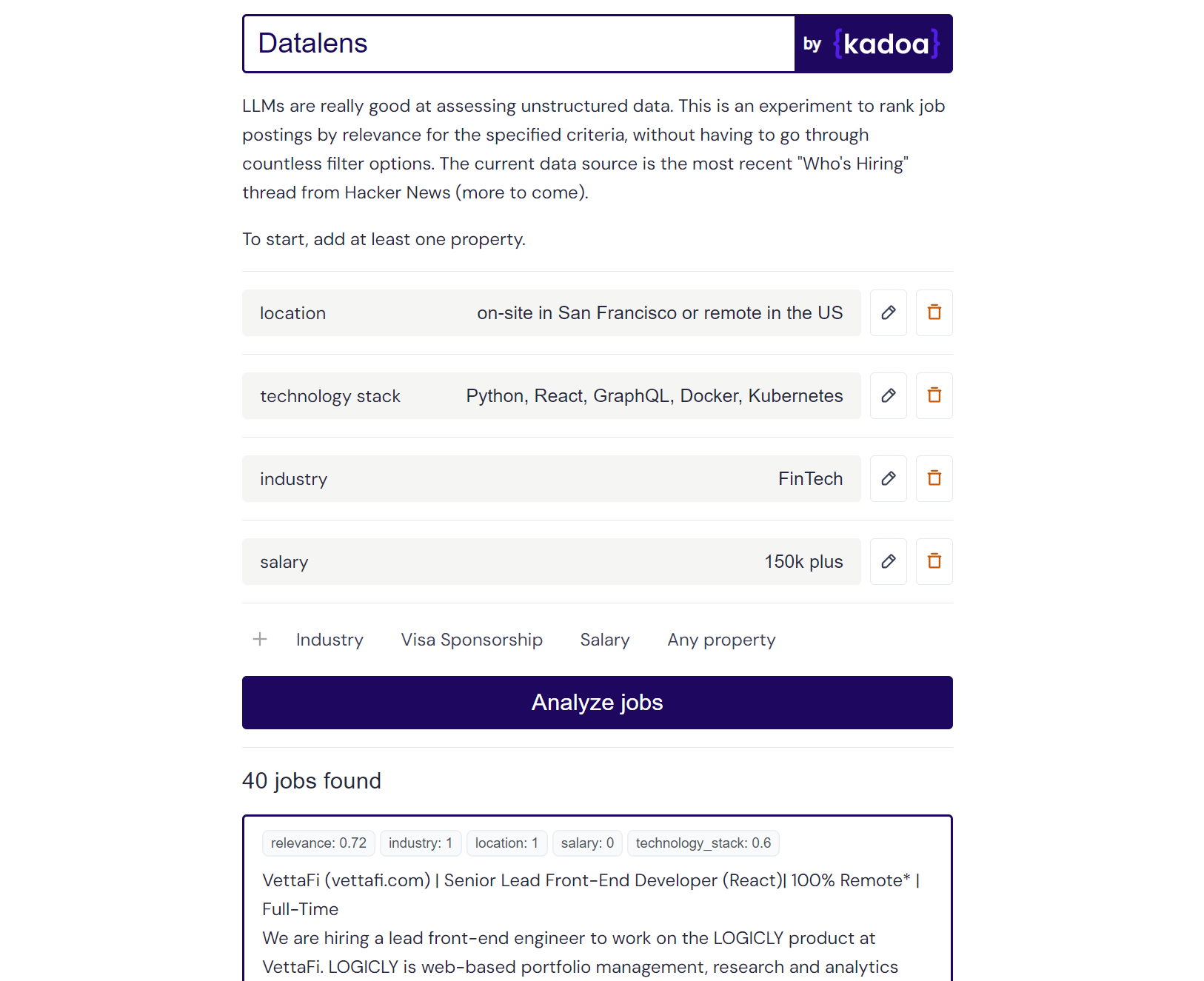
ผลลัพธ์ตัวอย่าง Claude-2:
Here are the scores for the provided job posting:
{
"location": 1.0,
"technology_stack": 0.8,
"industry": 0.0,
"salary": 0.0
}
Explanation:
- Location is a perfect match (1.0) as the role is in San Francisco which meets the "on-site in San Francisco or remote in the US" criteria.
- Technology stack is a partial match (0.8) as Python, React, and Kubernetes are listed which meet some but not all of the specified technologies.
- Industry is no match (0.0) as the company is in the creative/AI space.
- Salary is no match (0.0) as the posting does not mention the salary range. However, the full compensation is variable. Assigned a score of 0.6.
คุณสามารถเพิ่มแหล่งข้อมูลงานใดก็ได้ที่คุณต้องการ ฉันได้กำหนดค่าไว้ล่วงหน้าด้วยเธรด "ใครกำลังจ้าง" ล่าสุดจาก Hacker News แต่คุณสามารถเพิ่มแหล่งที่มาของคุณเองได้
เพิ่มแหล่งงานใหม่โดยอัปเดต Sources_config.json ตัวอย่าง:
{
"name": "SourceName",
"endpoint": "API_ENDPOINT",
"handler": "handler_function_name",
"headers": {
"x-api-key": "YOUR_API_KEY"
}
}
ฉันใช้เครื่องมือของตัวเอง Kadoa เพื่อดึงข้อมูลงานจากหน้าเพจของบริษัท แต่คุณสามารถใช้วิธีการขูดแบบเดิมอื่นๆ ได้
นี่คือจุดสิ้นสุดสาธารณะบางส่วนที่พร้อมสำหรับการรับประกาศรับสมัครงานทั้งหมดจากบริษัทเหล่านี้ (อัพเดททุกวัน):
{
"name": "Anduril",
"endpoint": "https://services.kadoa.com/jobs/pages/64e74d936addab49669d6319?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "Tesla",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb63f6b91574b2149c0cae?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "SpaceX",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb5f1b7350bf774df35f7f?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
}
แจ้งให้เราทราบหากควรเพิ่มบริษัทอื่น ๆ เรายินดีให้คุณทดลองใช้ Kadoa ได้ด้วย
การให้คะแนนความเกี่ยวข้องทำงานได้ดีที่สุดกับ gpt-4-0613 ซึ่งส่งคืนคะแนนแบบละเอียดระหว่าง 0-1 claude-2 ก็ใช้งานได้ค่อนข้างดีเช่นกันหากคุณสามารถเข้าถึงได้ สามารถใช้ gpt-3.5-turbo-0613 ได้ แต่มักจะส่งคืนคะแนนไบนารีเป็น 0 หรือ 1 สำหรับเกณฑ์ โดยไม่มีความแตกต่างเล็กน้อยในการแยกแยะระหว่างการจับคู่บางส่วนและทั้งหมด
โมเดลเริ่มต้นคือ gpt-3.5-turbo-0613 ด้วยเหตุผลด้านต้นทุน คุณสามารถเปลี่ยนจาก GPT เป็น Claude ได้โดยแทนที่ use_claude ด้วย use_openai
การเรียกใช้สคริปต์นี้อย่างต่อเนื่องอาจส่งผลให้มีการใช้งาน API สูง ดังนั้นโปรดใช้ด้วยความรับผิดชอบ ฉันกำลังบันทึกค่าใช้จ่ายสำหรับการโทร GPT แต่ละครั้ง
ในการเรียกใช้แอป คุณต้องมี:
คัดลอกไฟล์ .env.example แล้วกรอกข้อมูล
เรียกใช้เซิร์ฟเวอร์ Flask:
cd server
cp .env.example .env
pip install -r requirements.txt
py main
นำทางไปยังไดเร็กทอรีไคลเอนต์และติดตั้งการพึ่งพาโหนด:
cd client
npm install
เรียกใช้ไคลเอ็นต์ Next.js:
cd client
npm run dev


