Darwin
1.0.0
องค์กร: มหาวิทยาลัยนิวเซาธ์เวลส์ (UNSW) AI4Science & GreenDynamics AI
Darwin เป็นโครงการโอเพ่นซอร์สที่อุทิศตนเพื่อฝึกฝนและปรับแต่งแบบจำลอง LLaMA บนวรรณกรรมและชุดข้อมูลทางวิทยาศาสตร์ ได้รับการออกแบบมาโดยเฉพาะสำหรับขอบเขตทางวิทยาศาสตร์โดยเน้นในด้านวัสดุศาสตร์ เคมี และฟิสิกส์ ดาร์วินผสมผสานความรู้ทางวิทยาศาสตร์ที่มีโครงสร้างและไม่มีโครงสร้างเพื่อเพิ่มประสิทธิภาพของแบบจำลองภาษาในการวิจัยทางวิทยาศาสตร์
ประกาศการใช้งานและใบอนุญาต : ดาร์วินได้รับอนุญาตและมีไว้สำหรับการวิจัยเท่านั้น ชุดข้อมูลได้รับอนุญาตภายใต้ CC BY NC 4.0 ซึ่งอนุญาตให้ใช้ที่ไม่ใช่เชิงพาณิชย์ แบบจำลองที่ได้รับการฝึกโดยใช้ชุดข้อมูลนี้ไม่ควรใช้นอกวัตถุประสงค์การวิจัย ส่วนต่างของน้ำหนักยังอยู่ภายใต้ใบอนุญาต CC BY NC 4.0
[2024.11.20]
ความสำเร็จที่สำคัญ
ข้อมูลเชิงลึกด้านประสิทธิภาพของโมเดล
กลยุทธ์ข้อมูลและข้อมูลเชิงลึก
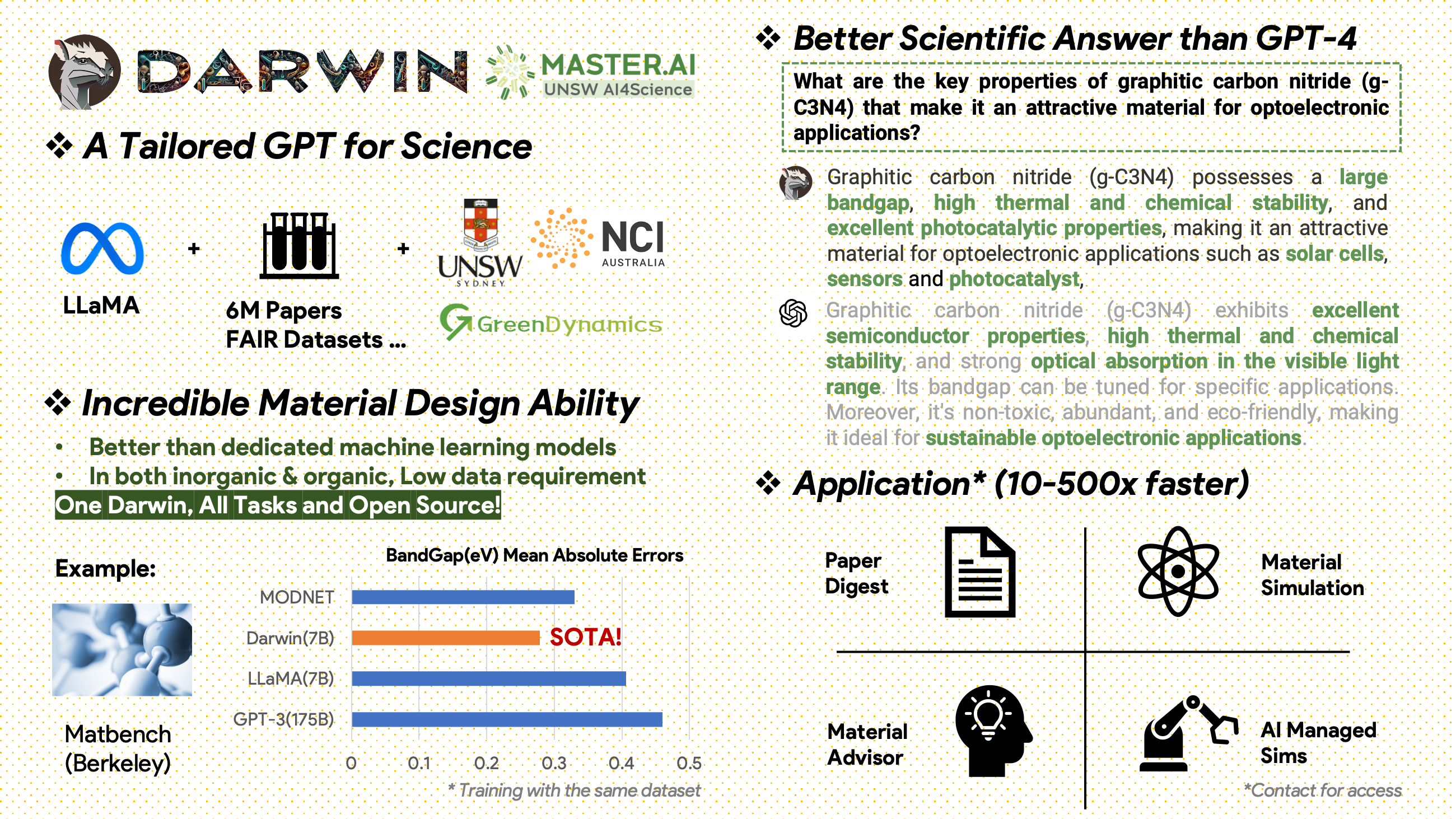
[2024.02.15] SOTA ใน MatBench โดย Material Projects: DARWIN เป็นแบบจำลอง SOTA ในงานทำนาย bandgap แบบทดลองและงานการจำแนกประเภทโลหะ ดีกว่า GPT3.5 ที่ปรับแต่งอย่างละเอียดและโมเดล ML เฉพาะ https://matbench.materialsproject.org/Leaderboards%20Per-Task/matbench_v0.1_matbench_expt_gap/
☆ [2023.09.15] มีเวอร์ชัน Google Colab: ลองใช้ DARWIN ของเรากับ Google Colab: inference.ipynb
ดาร์วินซึ่งใช้โมเดล 7B LLaMA ได้รับการฝึกอบรมเกี่ยวกับจุดข้อมูลตามคำสั่งมากกว่า 100,000 จุดที่สร้างโดย Darwin Scientific Instruction Generator (SIG) จากชุดข้อมูล FAIR ทางวิทยาศาสตร์ต่างๆ และคลังเอกสาร ด้วยการมุ่งเน้นไปที่ความถูกต้องตามข้อเท็จจริงของการตอบสนองของแบบจำลอง ดาร์วินแสดงให้เห็นถึงความก้าวหน้าครั้งสำคัญในการใช้ประโยชน์จากแบบจำลองภาษาขนาดใหญ่ (LLM) สำหรับการค้นพบทางวิทยาศาสตร์ การประเมินเบื้องต้นโดยมนุษย์ระบุว่า Darwin 7B มีประสิทธิภาพเหนือกว่า GPT-4 ในการถามตอบทางวิทยาศาสตร์ และ GPT-3 ที่ปรับแต่งมาอย่างดีในการแก้ปัญหาทางเคมี (เช่น gptChem)
เรากำลังพัฒนา Darwin อย่างแข็งขันสำหรับการทดลองโดเมนทางวิทยาศาสตร์ขั้นสูง และเรายังรวม Darwin เข้ากับ LangChain เพื่อแก้ปัญหางานทางวิทยาศาสตร์ที่ซับซ้อนมากขึ้น (เช่น ผู้ช่วยวิจัยส่วนตัวสำหรับคอมพิวเตอร์ส่วนบุคคล)
โปรดทราบว่าดาร์วินยังอยู่ระหว่างการพัฒนา และจำเป็นต้องแก้ไขข้อจำกัดหลายประการ สิ่งสำคัญที่สุดคือเรายังไม่ได้ปรับแต่งดาร์วินเพื่อความปลอดภัยสูงสุด เราขอแนะนำให้ผู้ใช้รายงานพฤติกรรมที่เกี่ยวข้องเพื่อช่วยปรับปรุงข้อควรพิจารณาด้านความปลอดภัยและจริยธรรมของโมเดล
ลิงค์สาธิต
ขั้นแรกให้ติดตั้งข้อกำหนด:
pip install -r requirements.txtดาวน์โหลดจุดตรวจของ Darwin-7B Weights จาก onedrive เมื่อคุณดาวน์โหลดโมเดลแล้ว คุณสามารถลองสาธิตของเราได้:
python inference.py < your path to darwin-7b >โปรดทราบว่าการอนุมานต้องใช้หน่วยความจำ GPU อย่างน้อย 10GB สำหรับ Darwin 7B
หากต้องการปรับแต่ง Darwin-7b ของเราเพิ่มเติมด้วยชุดข้อมูลต่างๆ ด้านล่างนี้คือคำสั่งที่ทำงานบนเครื่องที่มี GPU A100 80G 4 ตัว
torchrun --nproc_per_node=8 --master_port=1212 train.py
--model_name_or_path < your path to darwin-7b >
--data_path < your path to dataset >
--bf16 True
--output_dir < your output dir >
--num_train_epochs 3
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 Falseข้อมูลของเรามาจากสองแหล่งหลัก:
คลังข้อมูลวรรณกรรมดิบที่ประกอบด้วยเอกสาร 6.0 ล้านฉบับเกี่ยวกับวัสดุศาสตร์ เคมี และฟิสิกส์ ได้รับการตีพิมพ์หลังปี 2000 ผู้จัดพิมพ์ ได้แก่ ACS, RSC, Springer Nature, Wiley และ Elsevier เราขอขอบคุณพวกเขาสำหรับการสนับสนุนของพวกเขา
ชุดข้อมูล FAIR - เราได้รวบรวมข้อมูลจากชุดข้อมูล FAIR 16 ชุด
เราพัฒนา Darwin-SIG เพื่อสร้างคำแนะนำทางวิทยาศาสตร์ สามารถจดจำข้อความขนาดยาวจากวรรณกรรมฉบับเต็ม (เฉลี่ยประมาณ 5,000 คำ) และสร้างข้อมูลคำถามและคำตอบ (ถามตอบ) ตามคำสำคัญในวรรณกรรมทางวิทยาศาสตร์ (จาก web of science API)
หมายเหตุ: คุณสามารถใช้ GPT3.5 หรือ GPT-4 ในการสร้างได้เช่นกัน แต่ตัวเลือกเหล่านี้อาจมีค่าใช้จ่ายสูง
โปรดทราบว่าเราไม่สามารถแชร์ชุดข้อมูลการฝึกอบรมได้เนื่องจากข้อตกลงกับผู้เผยแพร่
โครงการนี้เป็นความพยายามร่วมกันโดยดังต่อไปนี้:
UNSW และ GreenDynamics: ตง Xie, Shaozhou Wang
UNSW: อิมราน ราซซัค, โคดี ฮวง
ศูนย์ USYD และ DARE: คลารา กราเซียน
กรีนไดนามิกส์: Yuwei Wan, Yixuan Liu
Bram Hoex และ Wenjie Zhang จาก UNSW Engineering ให้คำแนะนำแก่ทุกคน
หากคุณใช้ข้อมูลหรือโค้ดจากพื้นที่เก็บข้อมูลนี้ในงานของคุณ โปรดอ้างอิงตามนั้น
DAWRIN แบบจำลองภาษาขนาดใหญ่พื้นฐานและการปรับแต่งการสอนแบบกึ่งตนเองอย่างละเอียด
@misc{xie2023darwin,
title={DARWIN Series: Domain Specific Large Language Models for Natural Science},
author={Tong Xie and Yuwei Wan and Wei Huang and Zhenyu Yin and Yixuan Liu and Shaozhou Wang and Qingyuan Linghu and Chunyu Kit and Clara Grazian and Wenjie Zhang and Imran Razzak and Bram Hoex},
year={2023},
eprint={2308.13565},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
GPT-3 และ LLaMA ที่ได้รับการปรับแต่งอย่างละเอียดสำหรับการค้นพบวัสดุ (การฝึกอบรมงานเดี่ยว)
@article{xie2023large,
title={Large Language Models as Master Key: Unlocking the Secrets of Materials Science},
author={Xie, Tong and Wan, Yuwei and Zhou, Yufei and Huang, Wei and Liu, Yixuan and Linghu, Qingyuan and Wang, Shaozhou and Kit, Chunyu and Grazian, Clara and Zhang, Wenjie and others},
journal={Available at SSRN 4534137},
year={2023}
}
โครงการนี้ได้อ้างถึงโครงการโอเพ่นซอร์สต่อไปนี้:
ขอขอบคุณเป็นพิเศษสำหรับ NCI Australia สำหรับการสนับสนุน HPC
เราขยายทีมพัฒนาของดาร์วินอย่างต่อเนื่อง เข้าร่วมกับเราในการเดินทางที่น่าตื่นเต้นของการวิจัยทางวิทยาศาสตร์ที่ล้ำหน้าด้วย AI!
สำหรับตำแหน่งปริญญาเอกหรือ PostDoc โปรดติดต่อ [email protected] หรือ [email protected] เพื่อดูรายละเอียด
สำหรับตำแหน่งอื่นๆ กรุณาเยี่ยมชมที่ www.greendynamics.com.au


