Agent FLAN
1.0.0
- กอดใบหน้า] [? OpenXLab] [? กระดาษ] [ หน้าโครงการ]
โมเดลภาษาขนาดใหญ่แบบโอเพ่นซอร์ส (LLM) ประสบความสำเร็จอย่างมากในงาน NLP ต่างๆ อย่างไรก็ตาม ยังคงด้อยกว่าโมเดลที่ใช้ API มากเมื่อทำหน้าที่เป็นตัวแทน การบูรณาการความสามารถของตัวแทนเข้ากับ LLM ทั่วไปกลายเป็นปัญหาที่สำคัญและเร่งด่วนได้อย่างไร เอกสารนี้ให้ข้อสังเกตที่สำคัญสามประการในขั้นแรก: (1) คลังข้อมูลการฝึกอบรมตัวแทนปัจจุบันพัวพันกับทั้งรูปแบบต่อไปนี้และการให้เหตุผลของตัวแทน ซึ่งเปลี่ยนจากการกระจายข้อมูลก่อนการฝึกอบรมอย่างมีนัยสำคัญ (2) LLM แสดงความเร็วในการเรียนรู้ที่แตกต่างกันเกี่ยวกับความสามารถที่จำเป็นสำหรับงานตัวแทน และ (3) วิธีการปัจจุบันมีผลข้างเคียงเมื่อปรับปรุงความสามารถของตัวแทนด้วยการแนะนำภาพหลอน จากการค้นพบข้างต้น เราเสนอให้ Agent-FLAN ปรับแต่งโมเดลภาษาสำหรับตัวแทนอย่างมีประสิทธิภาพ ด้วยการแยกส่วนอย่างระมัดระวังและการออกแบบคลังข้อมูลการฝึกอบรมใหม่ Agent-FLAN ช่วยให้ Llama2-7B มีประสิทธิภาพเหนือกว่างานที่ดีที่สุดก่อนหน้านี้ถึง 3.5% ในชุดข้อมูลการประเมินตัวแทนต่างๆ ด้วยตัวอย่างเชิงลบที่สร้างขึ้นอย่างครอบคลุม Agent-FLAN ช่วยบรรเทาอาการประสาทหลอนได้อย่างมากโดยอิงตามเกณฑ์มาตรฐานการประเมินที่เรากำหนดไว้ นอกจากนี้ ยังปรับปรุงความสามารถตัวแทนของ LLM อย่างต่อเนื่องเมื่อปรับขนาดขนาดโมเดลในขณะที่เพิ่มความสามารถทั่วไปของ LLM เล็กน้อย
ซีรีส์ Agent-FLAN ได้รับการปรับแต่งอย่างละเอียดบน AgentInstruct และ Toolbench โดยการใช้ไปป์ไลน์การสร้างข้อมูลที่เสนอในกระดาษ Agent-FLAN ซึ่งมีความสามารถที่แข็งแกร่งในงานตัวแทนต่างๆ และการใช้เครื่องมือ~
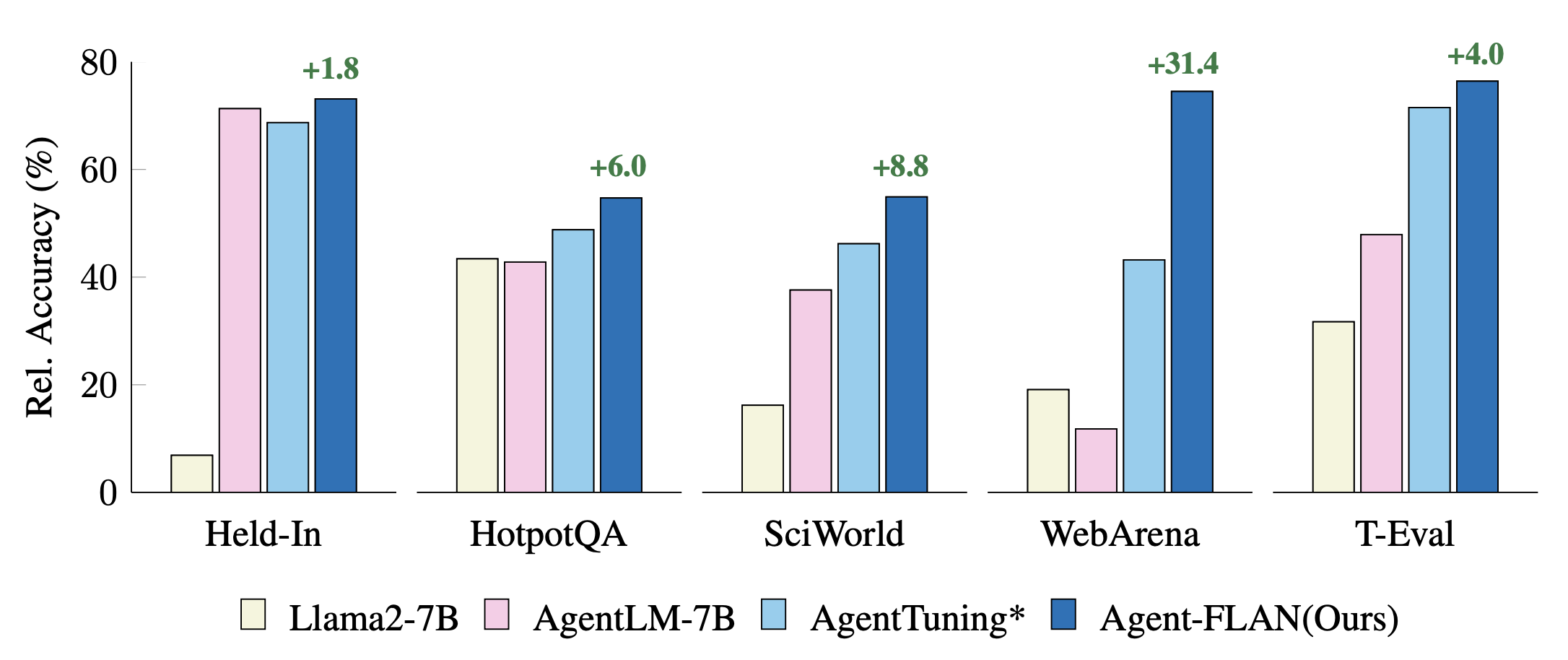
การเปรียบเทียบแนวทางการปรับแต่งเอเจนต์ล่าสุดกับงาน Held-In, Held-Out การแสดงจะถูกทำให้เป็นมาตรฐานด้วยผลลัพธ์ GPT-4 เพื่อการแสดงภาพที่ดีขึ้น * หมายถึงการดำเนินการใหม่ของเราเพื่อการเปรียบเทียบที่ยุติธรรม
Agent-FLAN สร้างขึ้นโดยการฝึกอบรมแบบผสมผสานบนชุดข้อมูล AgentInstruct, ToolBench และ ShareGPT จากซีรีส์ Llama2-chat
โมเดลดังกล่าวเป็นไปตามรูปแบบการสนทนาของ Llama-2-chat โดยมีโปรโตคอลเทมเพลตเป็น:
dict ( role = 'user' , begin = '<|Human|>െ' , end = ' n ' ),
dict ( role = 'system' , begin = '<|Human|>െ' , end = ' n ' ),
dict ( role = 'assistant' , begin = '<|Assistant|>െ' , end = 'ി n ' ),รุ่น 7B มีอยู่ในฮับรุ่น Huggingface และ OpenXLab
| แบบอย่าง | ฮักกิ้งเฟซ รีโป | OpenXLab Repo |
|---|---|---|
| เอเจนต์-FLAN-7B | ลิงค์รุ่น | ลิงค์รุ่น |
ชุดข้อมูล Agent-FLAN ยังมีอยู่บนฮับชุดข้อมูล Huggingface อีกด้วย
| ชุดข้อมูล | ฮักกิ้งเฟซ รีโป |
|---|---|
| ตัวแทน-FLAN | ลิงค์ชุดข้อมูล |
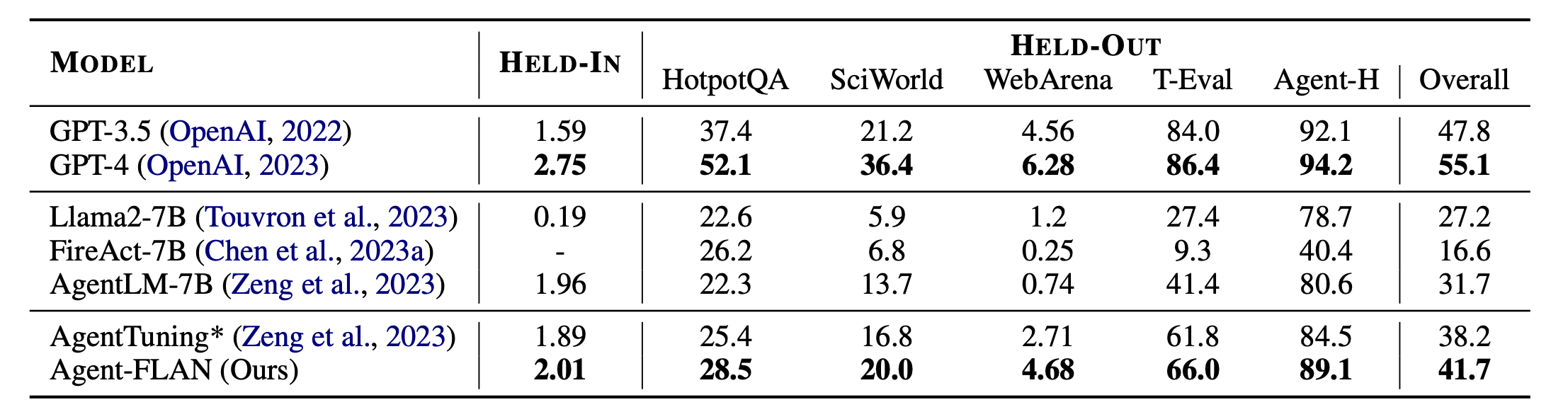
ผลลัพธ์หลักของ Agent-FLAN Agent-FLAN มีประสิทธิภาพเหนือกว่าแนวทางการปรับแต่งเอเจนต์ก่อนหน้านี้อย่างมาก โดยมีอัตรากำไรขั้นต้นที่มากทั้งงานที่ค้างอยู่และที่ค้างอยู่ * หมายถึงการใช้งานซ้ำของเราด้วยข้อมูลการฝึกอบรมที่เท่ากันเพื่อการเปรียบเทียบที่ยุติธรรม เนื่องจาก FireAct ไม่ได้ฝึกบนชุดข้อมูล AgentInstruct เราจึงละเว้นประสิทธิภาพของชุดข้อมูล HELD-IN ตัวหนา: ดีที่สุดในโมเดลที่ใช้ API และโอเพ่นซอร์ส
Agent-FLAN สร้างขึ้นด้วย Lagent และ T-Eval ขอบคุณสำหรับการทำงานที่ยอดเยี่ยมของพวกเขา!
หากคุณพบว่าโครงการนี้มีประโยชน์ในการวิจัยของคุณ โปรดพิจารณาอ้างอิง:
@article{chen2024agent,
title={Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models},
author={Chen, Zehui and Liu, Kuikun and Wang, Qiuchen and Zhang, Wenwei and Liu, Jiangning and Lin, Dahua and Chen, Kai and Zhao, Feng},
journal={arXiv preprint arXiv:2403.12881},
year={2024}
}
โครงการนี้เผยแพร่ภายใต้ลิขสิทธิ์ Apache 2.0


