safe rlhf
1.0.0
Beaver เป็นเฟรมเวิร์ก RLHF โอเพ่นซอร์สแบบโมดูลาร์สูงที่พัฒนาโดยทีม PKU-Alignment ที่มหาวิทยาลัยปักกิ่ง โดยมีจุดมุ่งหมายเพื่อให้ข้อมูลการฝึกอบรมและไปป์ไลน์โค้ดที่สามารถทำซ้ำได้สำหรับการวิจัยการจัดตำแหน่ง โดยเฉพาะอย่างยิ่งการวิจัย LLM การจัดตำแหน่งที่จำกัดผ่านวิธี Safe RLHF
คุณสมบัติที่สำคัญของบีเวอร์คือ:
2024/06/13 : เรามีความยินดีที่จะประกาศการเปิดซอร์สของชุดข้อมูล PKU-SafeRLHF เวอร์ชัน 1.0 ของเรา การเปิดตัวครั้งนี้ก้าวหน้าไปจากเวอร์ชันเบต้าเริ่มต้นโดยการรวมคำอธิบายประกอบร่วมระหว่างมนุษย์และ AI ขยายขอบเขตของหมวดหมู่อันตราย และแนะนำป้ายกำกับระดับความรุนแรงโดยละเอียด สำหรับรายละเอียดเพิ่มเติมและการเข้าถึง กรุณาเยี่ยมชมหน้าชุดข้อมูลของเราที่ ? ใบหน้ากอด: PKU-Alignment/PKU-SafeRLHF2024/01/16 : วิธีการของเรา Safe RLHF ได้รับการยอมรับจาก ICLR 2024 Spotlight2023/10/19 : เราได้เปิด ตัวรายงาน Safe RLHF เกี่ยวกับ arXiv โดยมีรายละเอียดเกี่ยวกับอัลกอริธึมการจัดตำแหน่งที่ปลอดภัยใหม่และการใช้งาน2023/07/10 : เรามีความยินดีที่จะประกาศให้ทราบว่าโมเดล Beaver-7B v1 / v2 / v3 แบบโอเพ่นซอร์สถือเป็นหลักชัยสำคัญของซีรีส์การฝึกอบรม Safe RLHF เสริมด้วย Reward Models v1 / v2 / v3 / unified ที่เกี่ยวข้อง และ แบบจำลองต้นทุน v1 / v2 / v3 / จุดตรวจแบบครบวงจรบน ? กอดหน้า.2023/07/10 : เราขยายชุดข้อมูลการตั้งค่าความปลอดภัยของโอเพ่นซอร์ส PKU-Alignment/PKU-SafeRLHF ซึ่งขณะนี้มีตัวอย่างมากกว่า 300,000 ตัวอย่าง (ดูส่วน PKU-SafeRLHF-ชุดข้อมูล)2023/07/05 : เราได้ปรับปรุงการรองรับโมเดลก่อนการฝึกอบรมภาษาจีน และรวมชุดข้อมูลภาษาจีนแบบโอเพ่นซอร์สเพิ่มเติม (ดูส่วนการสนับสนุนภาษาจีน (中文支持) และชุดข้อมูลที่กำหนดเอง (自定义数据集))2023/05/15 : การเปิดตัวไปป์ไลน์ Safe RLHF ครั้งแรก ผลการประเมิน และรหัสการฝึกอบรมการเรียนรู้แบบเสริมกำลังจากผลตอบรับของมนุษย์: การให้รางวัลสูงสุดผ่านการเรียนรู้ตามความชอบ
การเรียนรู้การเสริมกำลังอย่างปลอดภัยจากผลตอบรับของมนุษย์: การเพิ่มรางวัลสูงสุดอย่างจำกัดผ่านการเรียนรู้ตามความชอบ
ที่ไหน
เป้าหมายสูงสุดคือการหาแบบจำลอง
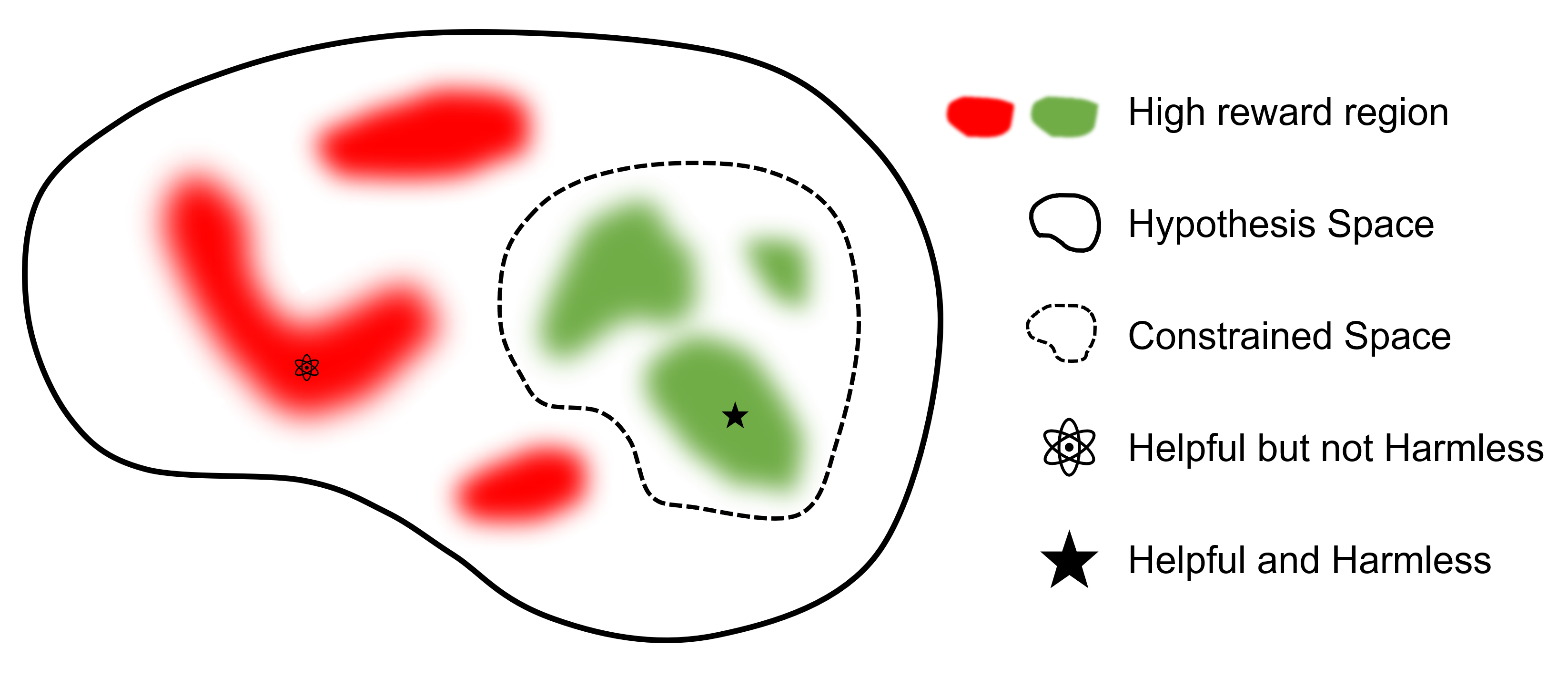
เมื่อเปรียบเทียบกับเฟรมเวิร์กอื่นๆ ที่รองรับ RLHF แล้ว safe-rlhf เป็นเฟรมเวิร์กแรกที่รองรับทุกขั้นตอนตั้งแต่ SFT ไปจนถึง RLHF และการประเมินผล นอกจากนี้ safe-rlhf ยังเป็นกรอบการทำงานแรกที่คำนึงถึงความปลอดภัยในช่วงระยะ RLHF มีการรับประกันทางทฤษฎีมากขึ้นสำหรับการค้นหาพารามิเตอร์ที่มีข้อจำกัดในพื้นที่นโยบาย
| เอสเอฟที | การฝึกอบรมแบบจำลองการตั้งค่า 1 | RLHF | ปลอดภัย RLHF | การสูญเสีย PTX | การประเมิน | แบ็กเอนด์ | |
|---|---|---|---|---|---|---|---|
| บีเวอร์ (ปลอดภัย-RLHF) | ดีพสปีด | ||||||
| trlX | 2 | เร่งความเร็ว / นีโม | |||||
| DeepSpeed-แชท | ดีพสปีด | ||||||
| ใหญ่โต-AI | ColossalAI | ||||||
| ฟาร์มอัลปาก้า | 3 | เร่งความเร็ว |
ชุดข้อมูล PKU-SafeRLHF เป็นชุดข้อมูลที่ติดป้ายกำกับโดยมนุษย์ซึ่งมีทั้งการตั้งค่าด้านประสิทธิภาพและความปลอดภัย รวมถึงข้อจำกัดในกว่าสิบมิติ เช่น การดูหมิ่น การผิดศีลธรรม อาชญากรรม การทำร้ายทางอารมณ์ และความเป็นส่วนตัว และอื่นๆ อีกมากมาย ข้อจำกัดเหล่านี้ได้รับการออกแบบสำหรับการจัดตำแหน่งค่าแบบละเอียดในเทคโนโลยี RLHF
เพื่ออำนวยความสะดวกในการปรับแต่งแบบหลายรอบ เราจะเผยแพร่น้ำหนักพารามิเตอร์เริ่มต้น ชุดข้อมูลที่จำเป็น และพารามิเตอร์การฝึกสำหรับแต่ละรอบ สิ่งนี้ทำให้มั่นใจได้ถึงความสามารถในการทำซ้ำในการวิจัยทางวิทยาศาสตร์และเชิงวิชาการ ชุดข้อมูลจะค่อยๆ เปิดตัวผ่านการอัปเดตแบบต่อเนื่อง
ชุดข้อมูลมีอยู่ใน Hugging Face: PKU-Alignment/PKU-SafeRLHF
PKU-SafeRLHF-10K เป็นชุดย่อยของ PKU-SafeRLHF ที่ประกอบด้วยข้อมูลการฝึก Safe RLHF รอบแรกพร้อมอินสแตนซ์ 10K รวมถึงการตั้งค่าด้านความปลอดภัย คุณสามารถค้นหาได้จาก Hugging Face: PKU-Alignment/PKU-SafeRLHF-10K
เราจะค่อยๆ เปิดตัวชุดข้อมูล Safe-RLHF เต็มรูปแบบ ซึ่งรวมถึง คู่ ที่ติดป้ายกำกับโดยมนุษย์ 1 ล้านคู่ สำหรับการตั้งค่าที่เป็นประโยชน์และไม่เป็นอันตราย
Beaver เป็นโมเดลภาษาขนาดใหญ่ที่ใช้ LLaMA ซึ่งได้รับการฝึกฝนโดยใช้ safe-rlhf ได้รับการพัฒนาบนพื้นฐานของโมเดลอัลปาก้า โดยการรวบรวมข้อมูลความชอบของมนุษย์ที่เกี่ยวข้องกับความช่วยเหลือและความไม่เป็นอันตราย และใช้เทคนิค Safe RLHF ในการฝึกอบรม ในขณะที่ยังคงรักษาประสิทธิภาพที่เป็นประโยชน์ของ Alpaca เอาไว้ Beaver ก็ปรับปรุงความไม่เป็นอันตรายได้อย่างมาก
บีเว่อร์เป็นที่รู้จักในนาม "วิศวกรเขื่อนธรรมชาติ" เนื่องจากพวกมันเชี่ยวชาญในการใช้กิ่งก้าน พุ่มไม้ หิน และดินเพื่อสร้างเขื่อนและบ้านไม้เล็กๆ สร้างสภาพแวดล้อมพื้นที่ชุ่มน้ำที่เหมาะสมสำหรับสิ่งมีชีวิตอื่น ๆ ที่จะอาศัยอยู่ ทำให้พวกมันเป็นส่วนที่ขาดไม่ได้ของระบบนิเวศ . เพื่อให้มั่นใจในความปลอดภัยและความน่าเชื่อถือของโมเดลภาษาขนาดใหญ่ (LLM) ขณะเดียวกันก็รองรับค่านิยมที่หลากหลายสำหรับประชากรที่แตกต่างกัน ทีมงานมหาวิทยาลัยปักกิ่งได้ตั้งชื่อโมเดลโอเพ่นซอร์สว่า "บีเวอร์" และมีเป้าหมายที่จะสร้างเขื่อนสำหรับ LLM ผ่านค่าที่จำกัด เทคโนโลยีการจัดตำแหน่ง (CVA) เทคโนโลยีนี้ช่วยให้สามารถติดป้ายกำกับข้อมูลได้อย่างละเอียด และเมื่อรวมกับวิธีการเรียนรู้แบบเสริมความปลอดภัย จะช่วยลดอคติและการเลือกปฏิบัติของแบบจำลองได้อย่างมาก จึงช่วยเพิ่มความปลอดภัยของแบบจำลองได้ คล้ายคลึงกับบทบาทของบีเว่อร์ในระบบนิเวศ โมเดลบีเวอร์จะให้การสนับสนุนที่สำคัญสำหรับการพัฒนาแบบจำลองภาษาขนาดใหญ่ และมีส่วนสนับสนุนเชิงบวกต่อการพัฒนาเทคโนโลยีปัญญาประดิษฐ์ที่ยั่งยืน
ตามวิธีการประเมินของแบบจำลอง Vicuna เราใช้ GPT-4 เพื่อประเมินบีเวอร์ ผลการวิจัยพบว่า เมื่อเปรียบเทียบกับอัลปาก้า บีเวอร์มีการปรับปรุงที่สำคัญในด้านต่างๆ ที่เกี่ยวข้องกับความปลอดภัย
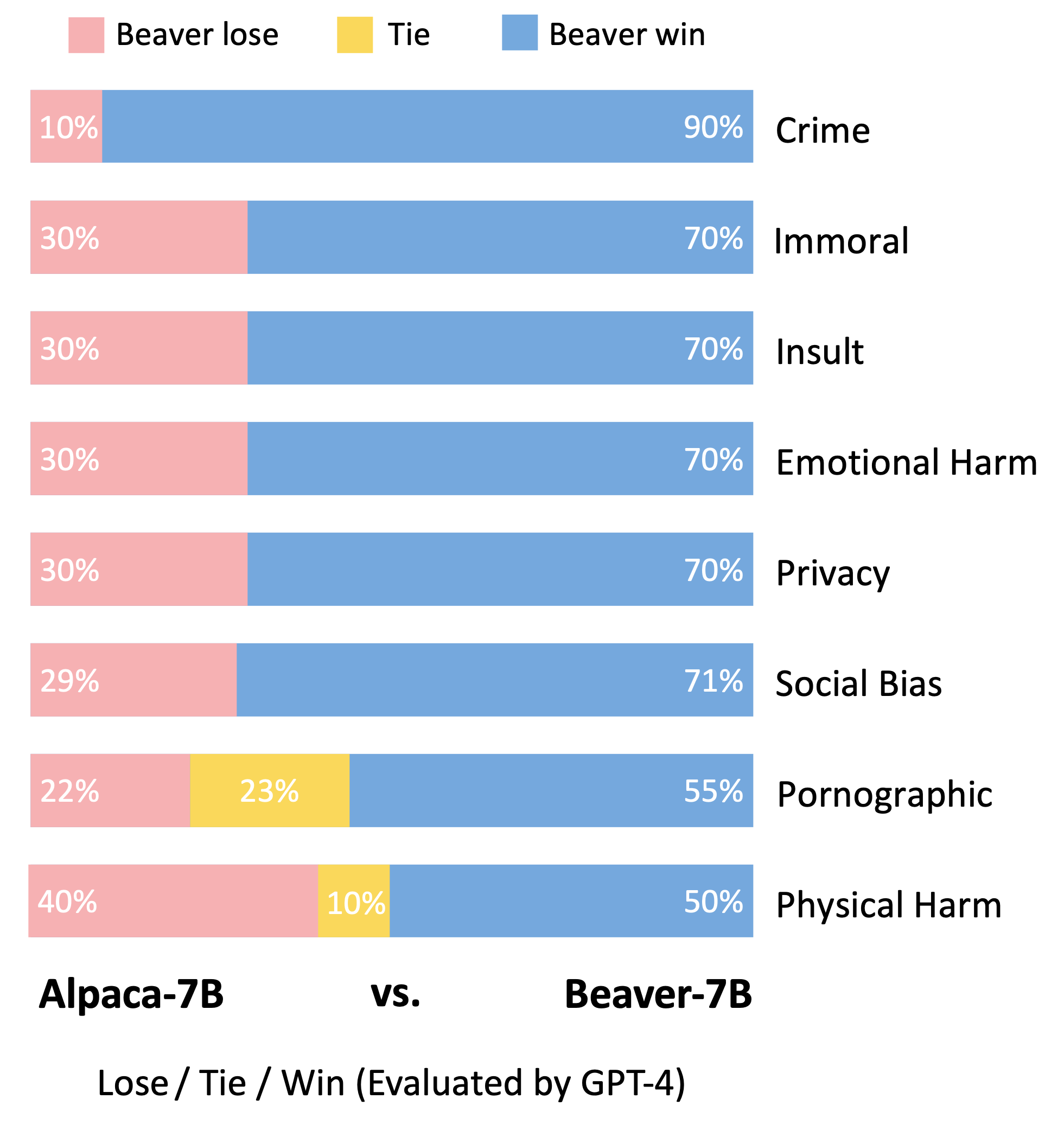
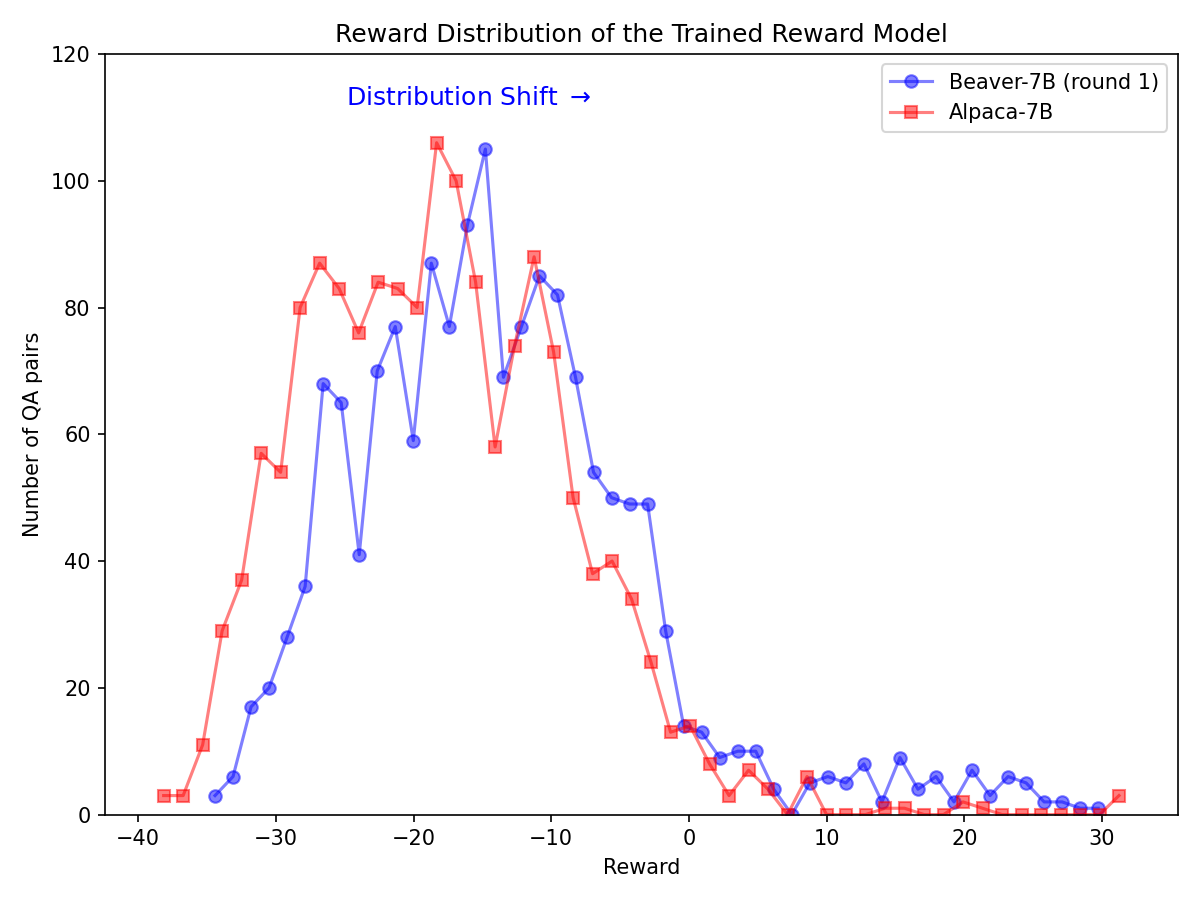
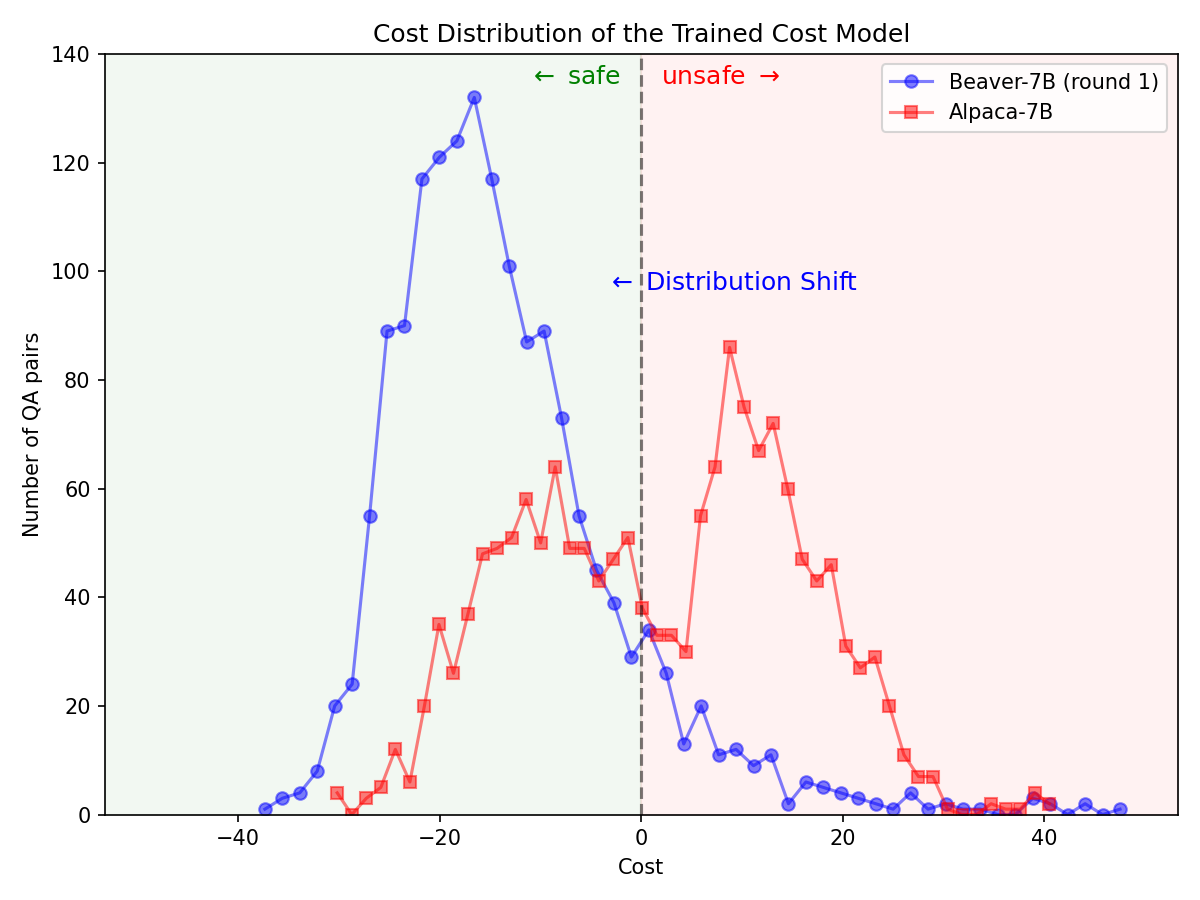
การเปลี่ยนแปลงการกระจายสินค้าอย่างมีนัยสำคัญสำหรับการตั้งค่าด้านความปลอดภัยหลังจากใช้ไปป์ไลน์ Safe RLHF ในรุ่น Alpaca-7B
 |  |
โคลนซอร์สโค้ดจาก GitHub:
git clone https://github.com/PKU-Alignment/safe-rlhf.git
cd safe-rlhf Native Runner: ตั้งค่าสภาพแวดล้อม conda โดยใช้ conda / mamba :
conda env create --file conda-recipe.yaml # or `mamba env create --file conda-recipe.yaml`สิ่งนี้จะตั้งค่าการขึ้นต่อกันทั้งหมดโดยอัตโนมัติ
Containerized Runner: นอกเหนือจากการใช้เครื่องเนทีฟที่มีการแยก conda คุณยังสามารถใช้อิมเมจนักเทียบท่าเพื่อกำหนดค่าสภาพแวดล้อมได้อีกด้วย
ขั้นแรก โปรดปฏิบัติตาม NVIDIA Container Toolkit: คู่มือการติดตั้ง และ NVIDIA Docker: คู่มือการติดตั้ง เพื่อตั้งค่า nvidia-docker จากนั้นคุณสามารถเรียกใช้:
make docker-run คำสั่งนี้จะสร้างและเริ่มต้นคอนเทนเนอร์นักเทียบท่าที่ติดตั้งโดยมีการขึ้นต่อกันที่เหมาะสม เส้นทางโฮสต์ / จะถูกแมปกับ /host และไดเร็กทอรีการทำงานปัจจุบันจะถูกแมปกับ /workspace ภายในคอนเทนเนอร์
safe-rlhf รองรับไปป์ไลน์ที่สมบูรณ์ตั้งแต่ Supervised Fine-Tuning (SFT) ไปจนถึงการฝึกอบรมโมเดลที่ต้องการไปจนถึงการฝึกอบรมการจัดตำแหน่ง RLHF
conda activate safe-rlhf
export WANDB_API_KEY= " ... " # your W&B API key hereหรือ
make docker-run
export WANDB_API_KEY= " ... " # your W&B API key herebash scripts/sft.sh
--model_name_or_path < your-model-name-or-checkpoint-path >
--output_dir output/sftหมายเหตุ: คุณอาจต้องอัปเดตพารามิเตอร์บางตัวในสคริปต์ตามการตั้งค่าเครื่องของคุณ เช่น จำนวน GPU สำหรับการฝึก ขนาดแบตช์การฝึก ฯลฯ
bash scripts/reward-model.sh
--model_name_or_path output/sft
--output_dir output/rmbash scripts/cost-model.sh
--model_name_or_path output/sft
--output_dir output/cmbash scripts/ppo.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--output_dir output/ppobash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lagตัวอย่างคำสั่งในการรันไปป์ไลน์ทั้งหมดด้วย LLaMA-7B:
conda activate safe-rlhf
bash scripts/sft.sh --model_name_or_path ~ /models/llama-7b --output_dir output/sft
bash scripts/reward-model.sh --model_name_or_path output/sft --output_dir output/rm
bash scripts/cost-model.sh --model_name_or_path output/sft --output_dir output/cm
bash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lagกระบวนการฝึกอบรมทั้งหมดที่ระบุไว้ข้างต้นได้รับการทดสอบด้วย LLaMA-7B บนเซิร์ฟเวอร์คลาวด์ที่มี GPU NVIDIA A800-80GB จำนวน 8 ตัว
ผู้ใช้ที่มีทรัพยากรหน่วยความจำ GPU ไม่เพียงพอ สามารถเปิดใช้งาน DeepSpeed ZeRO-Offload เพื่อลดการใช้งานหน่วยความจำ GPU สูงสุดได้
สคริปต์การฝึกอบรมทั้งหมดสามารถส่งผ่านด้วยตัวเลือกพิเศษ --offload (ค่าเริ่มต้นคือ none เช่น ปิดการใช้งาน ZeRO-Offload) เพื่อถ่ายเทนเซอร์ (พารามิเตอร์และ/หรือสถานะเครื่องมือเพิ่มประสิทธิภาพ) ไปยัง CPU ตัวอย่างเช่น:
bash scripts/sft.sh
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft
--offload all # or `parameter` or `optimizer`สำหรับการตั้งค่าหลายโหนด ผู้ใช้สามารถดูเอกสารประกอบ DeepSpeed: การกำหนดค่าทรัพยากร (หลายโหนด) เพื่อดูรายละเอียดเพิ่มเติม นี่คือตัวอย่างเพื่อเริ่มกระบวนการฝึกอบรมบน 4 โหนด (แต่ละโหนดมี 8 GPU):
# myhostfile
worker-1 slots=8
worker-2 slots=8
worker-3 slots=8
worker-4 slots=8
จากนั้นเปิดสคริปต์การฝึกอบรมด้วย:
bash scripts/sft.sh
--hostfile myhostfile
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft safe-rlhf จัดเตรียมสิ่งที่เป็นนามธรรมเพื่อสร้างชุดข้อมูลสำหรับการปรับแต่งแบบละเอียดภายใต้การดูแล การฝึกโมเดลการกำหนดค่าตามความชอบ และขั้นตอนการฝึก RL ทั้งหมด
class RawSample ( TypedDict , total = False ):
"""Raw sample type.
For SupervisedDataset, should provide (input, answer) or (dialogue).
For PreferenceDataset, should provide (input, answer, other_answer, better).
For SafetyPreferenceDataset, should provide (input, answer, other_answer, safer, is_safe, is_other_safe).
For PromptOnlyDataset, should provide (input).
"""
# Texts
input : NotRequired [ str ] # either `input` or `dialogue` should be provided
"""User input text."""
answer : NotRequired [ str ]
"""Assistant answer text."""
other_answer : NotRequired [ str ]
"""Other assistant answer text via resampling."""
dialogue : NotRequired [ list [ str ]] # either `input` or `dialogue` should be provided
"""Dialogue history."""
# Flags
better : NotRequired [ bool ]
"""Whether ``answer`` is better than ``other_answer``."""
safer : NotRequired [ bool ]
"""Whether ``answer`` is safer than ``other_answer``."""
is_safe : NotRequired [ bool ]
"""Whether ``answer`` is safe."""
is_other_safe : NotRequired [ bool ]
"""Whether ``other_answer`` is safe."""นี่คือตัวอย่างการใช้งานชุดข้อมูลที่กำหนดเอง (ดู safe_rlhf/datasets/raw สำหรับตัวอย่างเพิ่มเติม):
import argparse
from datasets import load_dataset
from safe_rlhf . datasets import RawDataset , RawSample , parse_dataset
class MyRawDataset ( RawDataset ):
NAME = 'my-dataset-name'
def __init__ ( self , path = None ) -> None :
# Load a dataset from Hugging Face
self . data = load_dataset ( path or 'my-organization/my-dataset' )[ 'train' ]
def __getitem__ ( self , index : int ) -> RawSample :
data = self . data [ index ]
# Construct a `RawSample` dictionary from your custom dataset item
return RawSample (
input = data [ 'col1' ],
answer = data [ 'col2' ],
other_answer = data [ 'col3' ],
better = float ( data [ 'col4' ]) > float ( data [ 'col5' ]),
...
)
def __len__ ( self ) -> int :
return len ( self . data ) # dataset size
def parse_arguments ():
parser = argparse . ArgumentParser (...)
parser . add_argument (
'--datasets' ,
type = parse_dataset ,
nargs = '+' ,
metavar = 'DATASET[:PROPORTION[:PATH]]' ,
)
...
return parser . parse_args ()
def main ():
args = parse_arguments ()
...
if __name__ == '__main__' :
main ()จากนั้นคุณสามารถส่งชุดข้อมูลนี้ไปยังสคริปต์การฝึกอบรมได้ดังนี้:
python3 train.py --datasets my-dataset-name คุณยังอาจส่งชุดข้อมูลหลายชุดโดยสามารถเลือกสัดส่วนชุดข้อมูลเพิ่มเติมได้ (คั่นด้วยเครื่องหมายทวิภาค : ) ตัวอย่างเช่น:
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5ซึ่งจะใช้การแบ่งชุดข้อมูล Stanford Alpaca แบบสุ่ม 75% และชุดข้อมูลที่กำหนดเองของคุณ 50%
นอกจากนี้ อาร์กิวเมนต์ชุดข้อมูลยังสามารถตามด้วยพาธในเครื่อง (คั่นด้วยเครื่องหมายทวิภาค : ) หากคุณได้โคลนที่เก็บชุดข้อมูลจาก Hugging Face แล้ว
git lfs install
git clone https://huggingface.co/datasets/my-organization/my-dataset ~ /path/to/my-dataset/repository
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5: ~ /path/to/my-dataset/repositoryหมายเหตุ: ต้องนำเข้าคลาสชุดข้อมูลก่อนที่สคริปต์การฝึกอบรมจะเริ่มแยกวิเคราะห์อาร์กิวเมนต์บรรทัดคำสั่ง
python3 -m safe_rlhf.serve.cli --model_name_or_path output/sft # or output/ppo-lagpython3 -m safe_rlhf.serve.arena --red_corner_model_name_or_path output/sft --blue_corner_model_name_or_path output/ppo-lag
ไปป์ไลน์ Safe-RLHF ไม่เพียงแต่รองรับตระกูลโมเดล LLaMA เท่านั้น แต่ยังรองรับโมเดลที่ผ่านการฝึกอบรมล่วงหน้าอื่นๆ เช่น Baichuan, InternLM ฯลฯ ที่ให้การสนับสนุนภาษาจีนได้ดียิ่งขึ้น คุณเพียงแค่ต้องอัปเดตเส้นทางไปยังโมเดลที่ได้รับการฝึกอบรมล่วงหน้าในโค้ดการฝึกอบรมและการอนุมาน
Safe-RLHF 管道不仅仅支持 LLaMA 系列模型,它也支持其他一些对中文支持更好的预训练模型,例如 Baichuan 和 InternLM等。คุณ只需要在训练和推理的代码中更新预训练模型的路径即可。
# SFT training
bash scripts/sft.sh --model_name_or_path baichuan-inc/Baichuan-7B --output_dir output/baichuan-sft
# Inference
python3 -m safe_rlhf.serve.cli --model_name_or_path output/baichuan-sft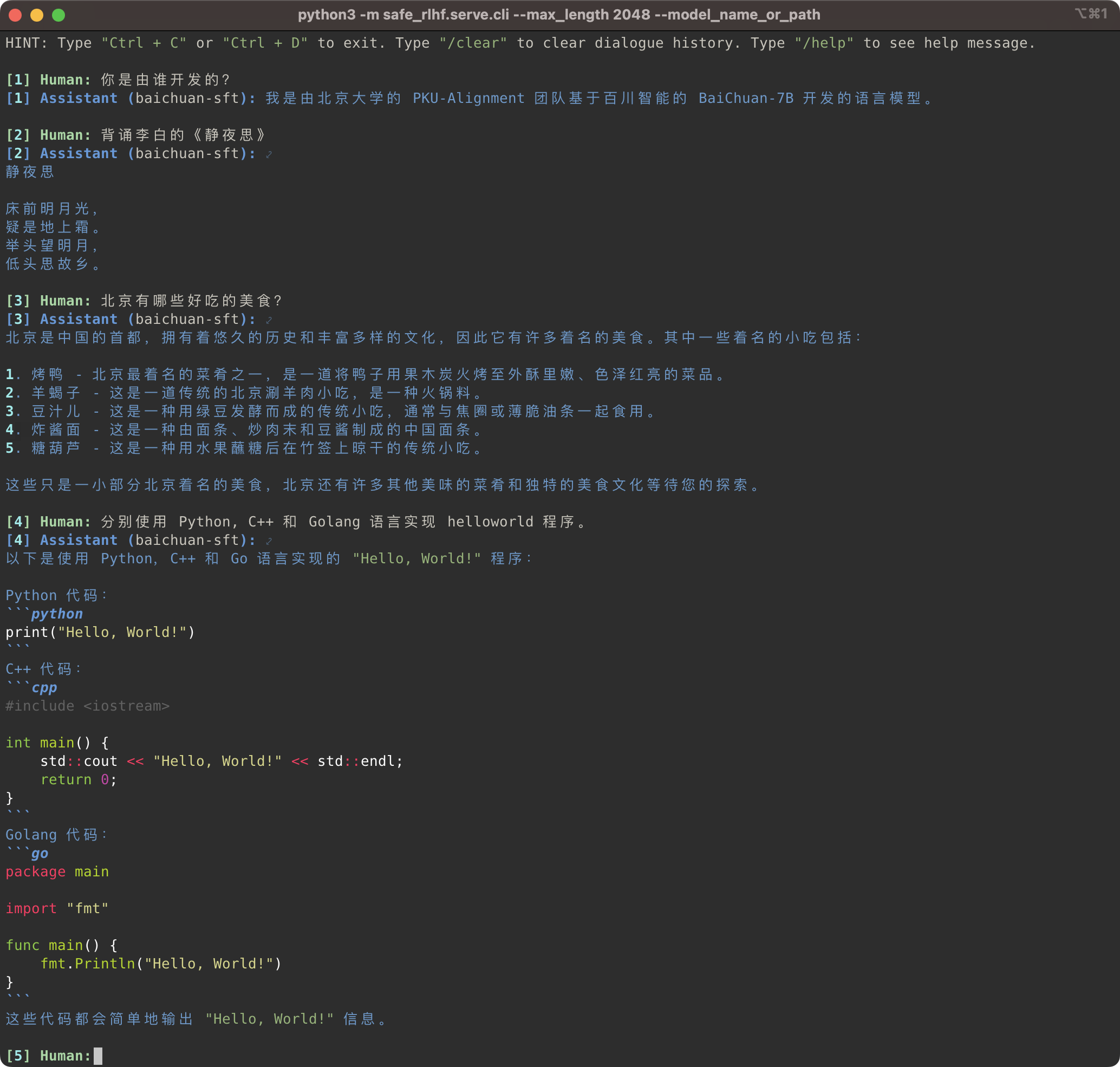
ในระหว่างนี้ เราได้เพิ่มการรองรับชุดข้อมูลจีน เช่น ซีรีส์ Firefly และ MOSS ให้กับชุดข้อมูลดิบของเรา คุณจะต้องเปลี่ยนเส้นทางชุดข้อมูลในรหัสการฝึกอบรมเพื่อใช้ชุดข้อมูลที่เกี่ยวข้องสำหรับการปรับแต่งโมเดลก่อนการฝึกอบรมภาษาจีน:
同时,我们也在 raw-datasets 中增加了支持一些中文数据集,例如 Firefly 和 MOSS系列等。在训练代码中更改数据集路径,你就可以使用相应的数据集来微调中文预训练模型:
# scripts/sft.sh
- --train_datasets alpaca
+ --train_datasets firefly สำหรับคำแนะนำเกี่ยวกับวิธีการเพิ่มชุดข้อมูลที่กำหนดเอง โปรดดูส่วนชุดข้อมูลที่กำหนดเอง
กำหนดเอง ชุดข้อมูลที่กำหนดเอง (自定义数据集)
scripts/arena-evaluation.sh
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lag
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/arena-evaluation # Install BIG-bench
git clone https://github.com/google/BIG-bench.git
(
cd BIG-bench
python3 setup.py sdist
python3 -m pip install -e .
)
# BIG-bench evaluation
python3 -m safe_rlhf.evaluate.bigbench
--model_name_or_path output/ppo-lag
--task_name < BIG-bench-task-name > # Install OpenAI Python API
pip3 install openai
export OPENAI_API_KEY= " ... " # your OpenAI API key here
# GPT-4 evaluation
python3 -m safe_rlhf.evaluate.gpt4
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lagหากคุณพบว่า Safe-RLHF มีประโยชน์หรือใช้ Safe-RLHF (โมเดล รหัส ชุดข้อมูล ฯลฯ) ในการวิจัยของคุณ โปรดพิจารณาอ้างอิงงานต่อไปนี้ในสิ่งพิมพ์ของคุณ
@inproceedings { safe-rlhf ,
title = { Safe RLHF: Safe Reinforcement Learning from Human Feedback } ,
author = { Josef Dai and Xuehai Pan and Ruiyang Sun and Jiaming Ji and Xinbo Xu and Mickel Liu and Yizhou Wang and Yaodong Yang } ,
booktitle = { The Twelfth International Conference on Learning Representations } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=TyFrPOKYXw }
}
@inproceedings { beavertails ,
title = { BeaverTails: Towards Improved Safety Alignment of {LLM} via a Human-Preference Dataset } ,
author = { Jiaming Ji and Mickel Liu and Juntao Dai and Xuehai Pan and Chi Zhang and Ce Bian and Boyuan Chen and Ruiyang Sun and Yizhou Wang and Yaodong Yang } ,
booktitle = { Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track } ,
year = { 2023 } ,
url = { https://openreview.net/forum?id=g0QovXbFw3 }
}นักเรียนทุกคนด้านล่างมีส่วนร่วมอย่างเท่าเทียมกัน และลำดับจะถูกกำหนดตามตัวอักษร:
ทั้งหมดได้รับคำแนะนำจาก Yizhou Wang และ Yaodong Yang รับทราบ: ขอขอบคุณคุณ Yi Qu ในการออกแบบโลโก้บีเวอร์
พื้นที่เก็บข้อมูลนี้ได้รับประโยชน์จาก LLaMA, Stanford Alpaca, DeepSpeed และ DeepSpeed-Chat ขอขอบคุณสำหรับงานที่ยอดเยี่ยมและความพยายามในการทำให้การวิจัย LLM เป็นประชาธิปไตย Safe-RLHF และทรัพย์สินที่เกี่ยวข้องถูกสร้างขึ้นและโอเพ่นซอร์สด้วยความรัก ?❤️
งานนี้ได้รับการสนับสนุนและได้รับทุนจากมหาวิทยาลัยปักกิ่ง
 |  |
Safe-RLHF เปิดตัวภายใต้ Apache License 2.0


