reddit gpt summarizer
1.0.0
อัปเดตเป็น LiteLLM สำหรับตัวเชื่อมต่อที่เข้ากันได้กับ openai ทำให้เพิ่มการรองรับสำหรับรุ่นต่างๆ ได้ง่ายขึ้น ขณะนี้เรากำลังใช้ไฟล์ json รุ่นเดียวสำหรับการกำหนดค่าของเรา ตรวจสอบให้แน่ใจว่าคุณมีคีย์ API ที่เหมาะสมเพื่อใช้ Google Gemini AI Studio รองรับ GPT 4o, Sonnet 3.5
รองรับโมเดล Claude ใหม่ มีการปรับแต่งบางส่วนตลอด
Python อัปเดตเป็น 3.11 นอกจากนี้เรายังเพิ่มการรองรับ GPT-4 128k และ Claude 2.1 + Claude Instant v1.2 ตรวจสอบให้แน่ใจว่าได้อัปเดตการอ้างอิงของคุณตามนั้น
ดู: มานุษยวิทยา/ Claude 2
อัปเดตการพึ่งพาบางส่วนด้วย (Anthropic, OpenAI, PRAW, Streamlit)
ภาพรวมวิดีโออัปเดต @YouTube
บทความใหม่ @ การเขียนโปรแกรม/สื่อที่ดีกว่า: การแปลงการสรุป Reddit ด้วย Claude 100k และ GPT 16k
ขยายการตั้งค่าเพื่อใช้โมเดล Anthropic ยังเพิ่มการรองรับสำหรับโมเดลคำสั่ง OpenAI รุ่นเก่า ซึ่งส่วนใหญ่สร้างเอาต์พุตขยะ แต่มีประโยชน์ในการทดสอบ ดังที่กล่าวไว้ว่า Text Davinci 003 สร้างเอาต์พุตคุณภาพสูงสุดบางส่วนโดยอัตวิสัย โมเดล 100k ใหม่มักจะใช้เธรด Reddit ทั้งหมดโดยไม่มีการเรียกซ้ำ
อย่าลืมเพิ่มคีย์ Anthropic API ลงในไฟล์ .env ของคุณ (ANTHROPIC_API_KEY)
https://www.anthropic.com/index/100k-context-windows
หากคุณมีสิทธิ์เข้าถึง API คุณสามารถใช้หน้าต่างบริบทที่ยาวขึ้นได้ในวันนี้ ดูเอกสาร https://platform.openai.com/docs/models/gpt-4 ลงทะเบียนรอรายชื่อได้ที่นี่: https://openai.com/waitlist/gpt-4
บทความ @ การเขียนโปรแกรมที่ดีขึ้น/การสร้างสื่อกลาง Reddit Thread Summarizer ด้วย ChatGPT API
นี่คือตัวสรุปเธรด Reddit ที่ใช้ Python ซึ่งใช้ GPT-3 เพื่อสร้างบทสรุปความคิดเห็นของเธรด
สคริปต์นี้ใช้เพื่อสร้างบทสรุปของเธรด Reddit โดยใช้ OpenAI API เพื่อเติมข้อความให้สมบูรณ์ตามพรอมต์ที่มีการสรุปแบบเรียกซ้ำ เริ่มต้นด้วยการร้องขอไปยังเธรด Reddit ที่ระบุ แยกชื่อและข้อความของตัวเอง จากนั้นค้นหาความคิดเห็นทั้งหมดในเธรด
ความคิดเห็นเหล่านี้จะถูกต่อเข้าเป็นกลุ่มตามจำนวนโทเค็นที่ระบุ และสร้างบทสรุปสำหรับแต่ละกลุ่มโดยแจ้ง OpenAI API ด้วยข้อความของกลุ่ม รวมถึงชื่อเรื่องและข้อความของตัวเองของเธรด Reddit จากนั้นข้อมูลสรุปจะถูกบันทึกลงในไฟล์ในโฟลเดอร์ outputs ในไดเร็กทอรีการทำงานปัจจุบัน
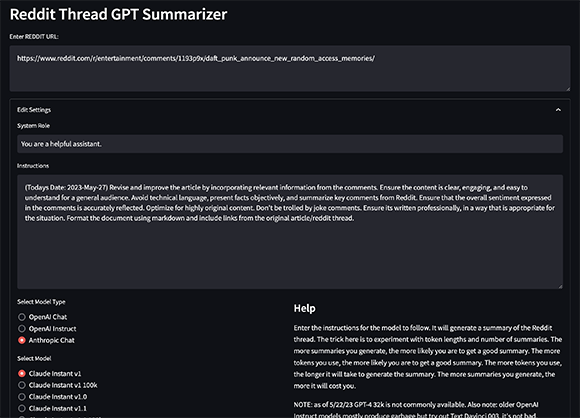
หากต้องการติดตั้งการพึ่งพา คุณสามารถใช้ poetry :
poetry install คุณจะต้องระบุข้อมูลรับรอง OpenAI/Reddit/Anthropic API ด้วย สร้างไฟล์ .env และเพิ่มรายการต่อไปนี้:
OPENAI_ORG_ID = YOUR_ORG_ID
OPENAI_API_KEY = YOUR_API_KEY
REDDIT_CLIENT_ID = YOUR_CLIENT_ID
REDDIT_CLIENT_SECRET = YOUR_CLIENT_SECRET
REDDIT_USERNAME = YOUR_USERNAME
REDDIT_PASSWORD = YOUR_PASSWORD
REDDIT_USER_AGENT = linux:com.youragent.reddit-gpt-summarizer:v1.0.0 (by /u/yourusername)
ANTHROPIC_API_KEY = YOUR_ANTHROPIC_KEY หากต้องการติดตั้งการพึ่งพาการพัฒนา ให้รัน:
poetry install --extras dev
โปรเจ็กต์นี้ใช้ pytest สำหรับการทดสอบ และ mypy สำหรับการตรวจสอบประเภท
หากต้องการรันการทดสอบและการตรวจสอบประเภท ให้ใช้คำสั่งต่อไปนี้:
poetry run pytest
poetry run mypy .
โปรเจ็กต์นี้ยังใช้สีดำสำหรับการจัดรูปแบบโค้ด และ pylint สำหรับการเป็นขุย
หากต้องการจัดรูปแบบโค้ดและตรวจสอบข้อผิดพลาดของ Lining ให้ใช้คำสั่งต่อไปนี้:
poetry run black .
poetry run pylint .
หากต้องการเรียกใช้แอป ให้ใช้คำสั่งต่อไปนี้:
streamlit run app/main.pyนี่จะเป็นการเริ่มแอปพลิเคชันเว็บที่ให้คุณป้อน URL ของเธรด Reddit และสร้างข้อมูลสรุป แอปจะสร้างข้อความแจ้งสำหรับ GPT-3 โดยอัตโนมัติตามเนื้อหาของเธรด และสร้างข้อมูลสรุปตามข้อความแจ้งเหล่านั้น
คุณสามารถปรับแต่งลักษณะการทำงานของแอปได้โดยใช้ไฟล์ config.py มีตัวเลือกการกำหนดค่าต่อไปนี้:
ATTACH_DEBUGGER : ว่าจะแนบดีบักเกอร์กับแอปหรือไม่WAIT_FOR_CLIENT : ว่าจะรอให้ไคลเอนต์แนบก่อนเริ่มแอปหรือไม่DEFAULT_DEBUG_PORT : พอร์ตเริ่มต้นที่จะใช้สำหรับดีบักเกอร์DEBUGPY_HOST : โฮสต์ที่จะใช้สำหรับดีบักเกอร์DEFAULT_CHUNK_TOKEN_LENGTH : ความยาวเริ่มต้นของความคิดเห็นจำนวนหนึ่งDEFAULT_NUMBER_OF_SUMMARIES : จำนวนสรุปเริ่มต้นที่จะสร้างDEFAULT_MAX_TOKEN_LENGTH : ความยาวสูงสุดเริ่มต้นของสรุปLOG_FILE_PATH : เส้นทางไปยังไฟล์บันทึกLOG_COLORS : พจนานุกรมสีสำหรับบันทึกREDDIT_URL : URL ของเธรด Reddit ที่จะสรุปTODAYS_DATE : วันที่วันนี้LOG_NAME : ชื่อของไฟล์บันทึกAPP_TITLE : ชื่อของแอปMAX_BODY_TOKEN_SIZE : จำนวนโทเค็นสูงสุดสำหรับเนื้อหาความคิดเห็นDEFAULT_QUERY_TEXT : ข้อความเริ่มต้นที่จะใช้สำหรับพรอมต์ GPT-3HELP_TEXT : ข้อความที่จะแสดงเมื่อผู้ใช้วางเมาส์เหนือไอคอนวิธีใช้ หากคุณต้องการมีส่วนร่วมในโครงการนี้ โปรดสร้างคำขอดึง
โครงการนี้ได้รับอนุญาตภายใต้ใบอนุญาต MIT


